

Letta(原名 MemGPT )做了关于 AI Agents Stack 的研究报告。
本文来源于此。
原文地址:https://www.letta.com/blog/ai-agents-stack
了解 AI agent的格局
尽管我们看到了许多Agent栈和Agent市场图,但我们往往不同意它们的分类,并发现它们很少反映我们实际观察到开发者正在使用的。
在过去几个月里,Agent软件生态系统在内存、工具使用、安全执行和部署方面取得了显著进展,因此我们决定是时候分享我们自己的“Agent技术栈”了,这是基于我们在过去一年多从事开源 AI 工作以及 7 年多 AI 研究中的学习。


AI Agents Stack在 2024 年底,分为三个关键层:Agent托管/服务、Agent框架和 LLM 模型和存储。
从 LLMs 到 LLM Agent
2022 年和 2023 年,我们见证了LLM框架和 SDK 的兴起,如 LangChain(于 2022 年 10 月发布)和 LlamaIndex(于 2022 年 11 月发布)。同时,我们还看到了通过 API 消费LLMs的“标准”平台的建立,以及自我部署LLM推理(vLLM 和 Ollama)。
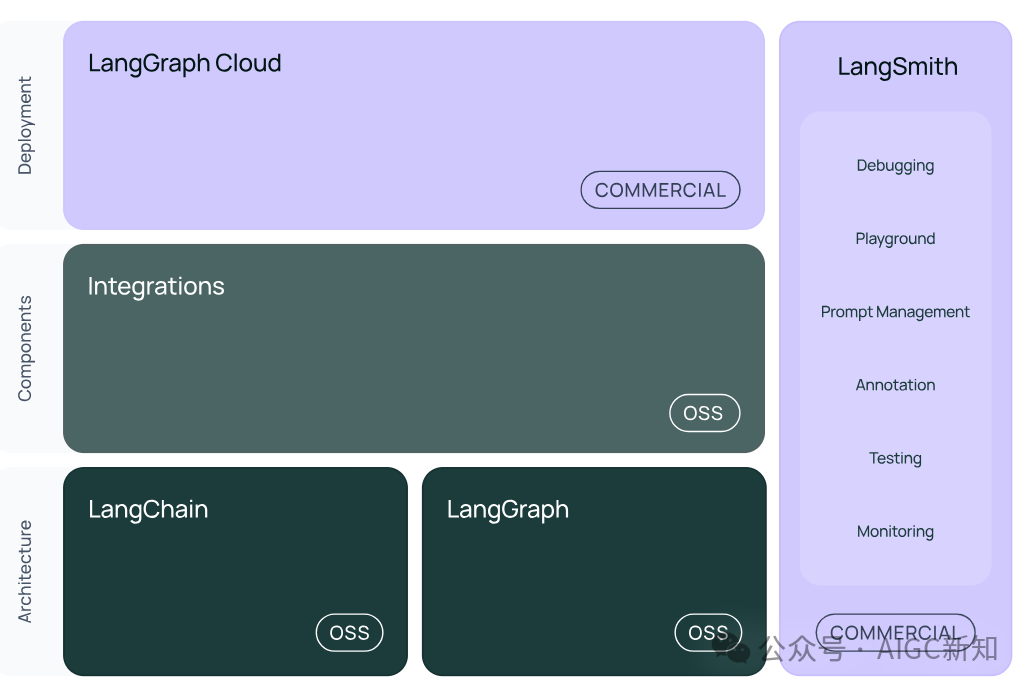
LangChain

LlamaIndex
2024 年,我们对 AI“智能体”的兴趣发生了巨大转变,更普遍的是复合系统。尽管“智能体”这个术语在 AI 领域已经存在了几十年(特别是强化学习),但在 ChatGPT 时代之后,“智能体”成为一个定义模糊的术语,通常指的是负责输出动作(工具调用)并在自主环境中运行的LLMs。
从LLM到智能体的工具使用、自主执行和所需内存的结合,促使开发了一个新的智能体堆栈。
为什么Agents Stack很独特?
Agent与基本LLM聊天机器人相比,是一个更具挑战性的工程难题,因为它们需要状态管理(保留消息/事件历史,存储长期记忆,在Agent循环中执行多个LLM调用)和工具执行(安全执行由LLM输出的动作并返回结果)。
因此,AI Agent的技术栈看起来与标准大语言模型技术栈非常不同。
让我们从底部的模型服务层开始,分解今天的 AI Agents 技术栈:
模型服务

AI Agent的核心是LLM。要使用LLM,模型需要通过推理引擎提供服务,通常运行在付费 API 服务之后。
OpenAI 和 Anthropic 在基于闭源 API 的模型推理提供商中处于领先地位,拥有私有前沿模型。
Together.AI、Fireworks 和 Groq 是流行的选项,它们在付费 API 后面提供开源权重模型(例如 Llama 3)。
在本地模型推理提供商中,我们最常见的是 vLLM 在基于生产级 GPU 的服务负载中领先。SGLang 是一个新兴项目,拥有类似的开发者群体。
在AI agent爱好者中,Ollama 和 LM Studio 是在自己的计算机上运行模型(例如 M 系列苹果 MacBook)的两个流行选择。
存储

存储是状态化Agent的基本构建块 – Agent由持久状态定义,如他们的对话历史、记忆以及他们用于 RAG 的外部数据源。
Chroma、Weaviate、Pinecone、Qdrant 和 Milvus 等向量数据库在存储Agent的“外部记忆”方面很受欢迎,允许Agent利用数据源和对话历史,这些数据源和对话历史太大,无法放入上下文窗口。
自 80 年代以来一直存在的传统数据库 Postgres,现在也通过 pgvector 扩展支持向量搜索。
基于 Postgres 的公司,如 Neon(无服务器 Postgres)和 Supabase,也提供基于嵌入的搜索和存储服务,以供Agent使用。
工具和库

标准 AI 聊天机器人和 AI Agent之间的主要区别之一是Agent能够调用“工具”(或“函数”)。在大多数情况下,这种行为的机制是通过LLM生成结构化输出(例如 JSON 对象),该输出指定要调用的函数和提供的参数。
Agent工具执行的一个常见混淆点是工具执行不是由LLM提供者本身完成的——提供者只选择要调用的工具以及提供的参数。支持任意工具或任意参数传递给工具的Agent服务必须使用沙箱(例如 Modal、E2B)来确保安全执行。
Agent通过 OpenAI 定义的 JSON 模式调用工具 – 这意味着Agent和工具可以在不同的框架之间实现兼容。Letta Agent可以调用 LangChain、CrewAI 和 Composio 工具,因为它们都由相同的模式定义。
因此,一个针对常用工具的工具提供商生态系统正在不断发展。
- Composio 是一个流行的通用工具库,它还负责管理授权。
- Browserbase 是浏览器的专用工具示例,而 Exa 提供了搜索网络的专用工具。
随着更多Agent的构建,我们预计工具生态系统将增长,并也为Agent提供现有新功能,如身份验证和访问控制。
Agent 框架

Agent框架协调LLM个调用并管理Agent状态。
不同的框架将针对以下方面有不同的设计:
- Agent状态管理
大多数框架都引入了“序列化”状态的概念,允许通过将序列化状态(例如 JSON、字节)保存到文件中,在稍后时间将Agent加载回相同的脚本中——这包括会话历史、Agent记忆和执行阶段等状态。
在 Letta 中,由于所有状态都由数据库支持(例如消息表、Agent状态表、内存块表),因此没有“序列化”的概念,因为Agent状态始终是持久化的。这使得可以轻松查询Agent状态(例如,按日期查找过去的消息)。
状态如何表示和管理决定了Agent应用将如何随着更长的会话历史或更多Agent数量的增加而扩展,以及状态如何灵活地随时间访问或修改。
- Agent上下文窗口的结构
每次调用LLM时,框架会将Agent的状态“编译”到上下文窗口中。
不同的框架将以不同的方式将数据放入上下文窗口(例如,指令、消息缓冲区等),这可能会影响性能。我们建议选择一个使上下文窗口透明的框架,因为这是您最终控制Agent行为的方式。
- 跨Agent通信(即多Agent)
Llama Index 通过消息队列让Agent进行通信,而 CrewAI 和 AutoGen 则具有显式的多Agent抽象器。
Letta 和 LangGraph 都支持Agent直接相互调用,这允许Agent之间进行集中式(通过管理Agent)和分布式通信。
大多数框架现在都支持多Agent和单Agent,因为一个设计良好的单Agent系统应该使得跨Agent协作易于实现。
- 内存方法
LLMs 的基本限制在于其有限的上下文窗口,这需要技术来管理随时间变化的内存。
一些框架内置了内存管理,而其他框架则要求开发者自行管理内存。CrewAI 和 AutoGen 仅依赖于基于 RAG 的内存,而 phidata 和 Letta 使用了额外的技术,如自编辑内存(来自 MemGPT)和递归摘要。
Letta Agent自动附带一套内存管理工具,允许Agent通过文本或数据搜索之前的消息,编写记忆,并编辑Agent自己的上下文窗口(更多信息请在此处阅读)。
- 支持开源模型
模型提供商实际上在幕后做了很多技巧来让LLMs以正确的格式生成文本(例如,用于工具调用)
例如,当它们没有生成适当的工具参数时重新采样LLM的输出,或者在提示中添加提示(例如,“请输出 JSON”)。支持开源模型需要框架处理这些挑战,因此一些限制只支持主要模型提供商。
今天构建智能体时,选择合适的框架取决于您的应用,例如您是否在构建对话智能体或工作流,您是否希望将智能体作为笔记本或服务运行,以及您对开放权重模型支持的要求。
我们预计在框架的部署工作流程中,不同框架之间将出现重大差异,其中关于状态/内存管理和工具执行的设计选择将变得更加重要。
Agent托管和Agent服务

大多数当前Agent框架都是为那些仅存在于编写它们的 Python 脚本或 Jupyter 笔记本中的Agent而设计的。
我们相信Agent的未来是将Agent视为部署到本地或云基础设施上的服务,通过 REST API 进行访问。就像 OpenAI 的 ChatCompletion API 成为与LLM服务交互的行业标准一样,我们预计最终会有一个赢家出现,成为Agent API。但还没有……
部署Agent作为服务比部署LLMs作为服务要复杂得多,因为涉及到状态管理和安全工具执行的问题。
工具及其所需的依赖和环境需求必须明确存储在数据库中,因为运行它们的环境需要由服务重新创建(当你的工具和Agent在同一个脚本中运行时,这不是一个问题)。
应用程序可能需要运行数百万个Agent,每个Agent都会积累越来越多的对话历史。当从原型设计过渡到生产时,不可避免地Agent状态必须经过数据规范化过程,Agent交互必须由 REST API 定义。
今天,这个过程通常由开发人员编写自己的 FastAPI 和数据库代码来完成,但我们预计随着Agent的成熟,这种功能将更多地嵌入到框架中。
主动代理旨在构建一个完全主动的代理,能够预测用户需求并主动提供帮助和提出行动建议,无需用户明确请求。我们通过开发数据收集和生成管道,构建自动评估器和在生成数据中训练代理来实现这一点。目前,我们提供了整个收集和生成管道、数据集、相应的评估脚本以及用于微调LLM以实现主动代理的提示。
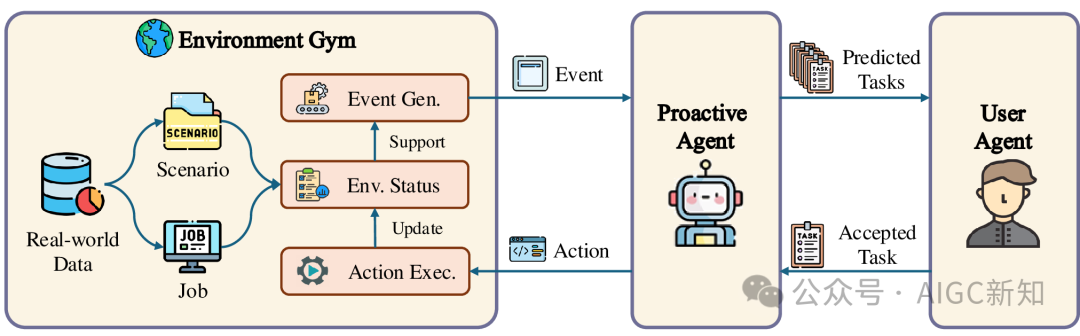
图1:数据生成流程概述以日常生活为例,这个流程包括初始场景和作业设置、事件生成、主动预测、用户判断、动作执行等模块。
功能:
- 环境感知:我们提供通过 Activity Watcher 收集环境场景和用户活动的脚本,并根据模型自动推荐任务。
- 辅助标注:我们提供了一个平台来标注主动代理生成的响应,这是一种将结果与人工标注者对齐的好方法。
- 动态生成:我们提供动态管道以生成新数据,用户的反馈可能会影响后续事件。
- 建设管道:我们提供了一个由环境Gym、主动代理和奖励模型组成的生成管道,其中我们的奖励模型在测试集上达到了 0.918 F1 分数。
管道包括:
(1)环境Gym:该组件模拟指定背景设置内的事件和示例事件,为主动代理提供交互沙盒。
它有两个关键功能:
- 事件生成:创建针对特定场景的潜在环境事件序列;
- 状态维护:更新和在生成新用户活动或代理在任务执行期间执行操作时维护环境的状态。
(2)主动代理:该组件负责根据从事件历史中推断出的用户需求,预测用户可能分配给代理的任务。它还与工具交互以完成用户分配的特定任务。
(3)用户代理:该组件根据预定义的用户特征模拟用户的活动和响应。它决定是否接受和执行代理提出的任务。
论文链接: https://arxiv.org/abs/2410.12361
GitHub 地址:https://github.com/thunlp/ProactiveAgent
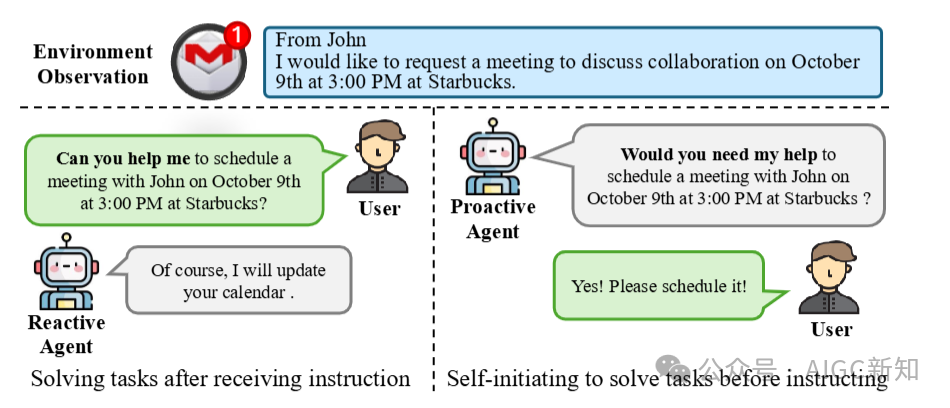
图2:两类人机交互的智能体系统对比反应式智能体被动接收用户查询,然后生成响应,主动式智能体根据环境观察推断任务,并据此提出可能的协助请求。
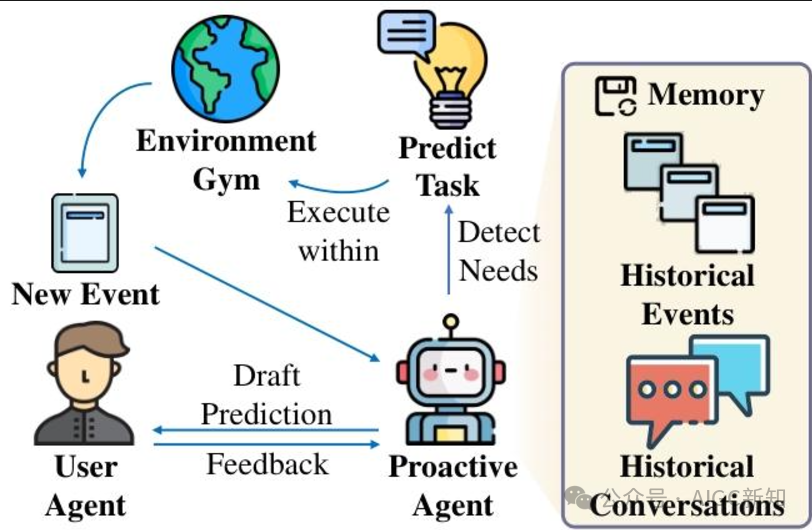
图3:主动代理框架的概述。代理监视新事件并更新其内存以预测潜在任务。
【我是谁】
绛烨,enfp/infp,AI科技自媒体博主,公众号“AIGC新知”主理人(目前粉丝量10000+)
运营了多个AI相关社群(教育、法律、智能硬件等)、知识星球(AI、AI小红书)等。
此外,是24届AI春晚统筹兼创作者,25年AI春晚商务兼统筹。
主业在一家教育公司做AI产品运营兼agent开发。
【我能提供】
(1)公众号文章合作,可友情or付费or资源置换
(2)社群相关资源
(3)AI头部KOL资源
(4)教育/agent开发等方面讨论交流
【我需要】
(1)AI教育相关认知/资源
(2)AI agent开发定制,课程培训合作等。
(3)商务合作可直接联系,期待多多交流,共同进步
加我探讨交流。
知识星球沉淀了很多AI的掘金素材集,欢迎加入!

如果觉得不错,欢迎点赞、在看、转发,您的转发和支持是我不懈创作的动力~
如果想第一时间收到推送,可以给我个星标?~
谢谢你挤出时间看我的文章推送,一眼万年,不胜感激。