
大家好~
今天要分享的内容是关于降维算法中的t-SNE。
t-SNE(t-Distributed Stochastic Neighbor Embedding,t分布随机邻居嵌入)是一种非常非常常用的降维算法,它的目的是将高维数据投影到2D或3D空间中,方便我们可视化和理解复杂数据。
全文内容,非常详细!~
文末已经给大家准备好了本文的 PDF版本 方便学习使用~
降维是什么?
我们可以想象,高维数据就像一个很复杂的大世界,比如一幅包含很多维度的画,每个维度可能是颜色、形状、大小、纹理等等。这样我们很难直接通过肉眼看懂所有信息。而「降维」的意思就是把这个复杂的大世界简化成我们可以轻松理解的样子,类似于把一个3D物体画成2D的图片。t-SNE就是一种帮助我们做这种简化的工具。
t-SNE 是怎么工作的呢?
-
保持相似性:它的关键在于,t-SNE并不只是简单地压缩数据,而是要尽量保留高维空间中数据点之间的相对距离和关系。举个例子,假如有10个人站在房间里,这10个人可能代表数据集里的10个数据点。如果两个人站得很近,意味着他们在某个特征上很相似。t-SNE的工作就是在将这些人的位置映射到二维或三维空间时,尽量保持他们之间的相对距离,也就是说,相似的点在降维后依然会挨得近,不相似的则远离。
-
减少维度:原始数据可能有很多特征(比如颜色、形状等),也就是“高维”。但我们只能看二维的图像,t-SNE会将这些特征映射到二维或三维,从而可以在图上展示出来。这个过程类似于将一张复杂的3D地图压成一张简单的2D地图,但仍然尽量保留重要的地理关系。
举个通俗的例子:
想象你去一个音乐会,观众们站得很散,有的站得很近,有的远离彼此。这些观众就是高维数据点。假设他们的站位是基于他们的音乐品味:喜欢摇滚的站在一起,喜欢古典音乐的站在另一个地方。t-SNE就像一个摄影师,它要把这个观众站位的情况拍成一个2D照片。它拍的照片会努力保持你能看到谁站得近(有相似的音乐品味),谁站得远(音乐品味不同)。但由于从3D变成2D,某些细节可能会被舍弃,比如有些人可能站在别人背后被遮挡住,但整体的站位关系仍然可以反映出来。
t-SNE 的优点:
-
可视化高维数据:它能将复杂数据变得可视化,让我们通过简单的图形就能看出数据中的模式或分组。 -
保留局部结构:它特别擅长保留数据点之间的局部结构,也就是说那些原本相似的数据点在降维后仍然会在一起。
t-SNE 的局限性:
-
时间较慢:t-SNE对大数据集来说可能运行很慢,因为它要计算每个数据点之间的距离。 -
全局结构模糊:虽然它可以很好地保留局部相似性,但它有时会破坏全局结构,导致我们无法看到整个数据集的全局关系。
t-SNE是一个让我们更容易“看见”复杂数据关系的工具,特别是当数据有很多维度的时候。通过t-SNE,我们可以将数据的相似性转换为一个容易理解的2D或3D图,帮助我们发现隐藏的模式或群体。
要实现 t-SNE 并给出详细的推导和案例,我们需要分两个步骤进行。首先是推导公式,再通过 Python 代码实现并生成一些分析图表。
t-SNE 公式推导
1. 相似度计算
在 t-SNE 中,数据点之间的相似度通过概率来表示。为了捕捉高维空间中的局部结构,t-SNE 使用 高斯分布 来衡量每对数据点之间的相似度。
对于两个高维数据点 和 ,定义其在高维空间中的相似度为 $ p_j ,它表示在给定点 x_i 的情况下,选择点 x_j $ 的概率。这一概率可以通过以下高斯核表示:
其中, 是点 的方差,控制局部邻域的尺度。为了对称化,定义:
这样就得到了高维空间中任意两点的对称相似度。
2. 低维空间的相似度
t-SNE 使用 t 分布来衡量低维空间中点 和 之间的相似度。定义低维空间的相似度为 ,其计算公式为:
这里的 t 分布(自由度为 1)可以产生较长的尾巴,允许更好地处理低维空间中点间的距离。
3. Kullback-Leibler (KL) 散度
t-SNE 的目标是让低维空间中的点对相似度 尽可能接近高维空间中的点对相似度 。这一优化通过最小化两个分布之间的 Kullback-Leibler 散度来实现:
我们的任务是最小化这个 KL 散度,从而优化低维表示 。
4. 梯度下降
t-SNE 使用梯度下降法来优化 KL 散度。其梯度可以写作:
通过这个梯度更新公式,我们可以不断调整低维空间中点的位置,使得 KL 散度最小化。
实现 t-SNE
接下来我们用 Python 实现这个算法,并生成一些可视化图形。
import numpy as np
import matplotlib.pyplot as plt
from scipy.spatial.distance import pdist, squareform
# 创建虚拟数据集(高维数据)
def create_data(n=200, dim=50):
np.random.seed(42)
data = np.random.randn(n, dim)
return data
# 计算高维空间中的相似度矩阵 P
def calculate_p_matrix(X, perplexity=30.0):
(n, d) = X.shape
distances = squareform(pdist(X, 'euclidean')) ** 2
P = np.zeros((n, n))
beta = np.ones((n, 1))
log_perplexity = np.log(perplexity)
for i in range(n):
beta_min = -np.inf
beta_max = np.inf
Di = distances[i, np.concatenate((np.r_[0:i], np.r_[i+1:n]))]
(H, thisP) = Hbeta(Di, beta[i])
H_diff = H - log_perplexity
tries = 0
while np.abs(H_diff) > 1e-5 and tries < 50:
if H_diff > 0:
beta_min = beta[i].copy()
if beta_max == np.inf or beta_max == -np.inf:
beta[i] = beta[i] * 2.0
else:
beta[i] = (beta[i] + beta_max) / 2.0
else:
beta_max = beta[i].copy()
if beta_min == np.inf or beta_min == -np.inf:
beta[i] = beta[i] / 2.0
else:
beta[i] = (beta[i] + beta_min) / 2.0
(H, thisP) = Hbeta(Di, beta[i])
H_diff = H - log_perplexity
tries += 1
P[i, np.concatenate((np.r_[0:i], np.r_[i+1:n]))] = thisP
P = (P + P.T) / (2.0 * n)
return P
# 高斯分布计算
def Hbeta(D=np.array([]), beta=1.0):
P = np.exp(-D.copy() * beta)
sumP = np.sum(P)
H = np.log(sumP) + beta * np.sum(D * P) / sumP
P = P / sumP
return H, P
# 计算低维空间的相似度矩阵 Q
def calculate_q_matrix(Y):
distances = squareform(pdist(Y, 'euclidean')) ** 2
Q = (1 + distances) ** -1
Q[range(Y.shape[0]), range(Y.shape[0])] = 0
Q = Q / np.sum(Q)
return Q
# t-SNE 主要算法
def tsne(X, no_dims=2, perplexity=30.0, max_iter=1000, learning_rate=200.0):
(n, d) = X.shape
Y = np.random.randn(n, no_dims)
P = calculate_p_matrix(X, perplexity)
P = P * 4 # early exaggeration
P = np.maximum(P, 1e-12)
Y_momentum = np.zeros_like(Y)
KL_history = []
for iter in range(max_iter):
Q = calculate_q_matrix(Y)
Q = np.maximum(Q, 1e-12)
PQ_diff = P - Q
for i in range(n):
grad = 4 * np.sum(np.tile(PQ_diff[:, i] * (1 + np.sum((Y[i, :] - Y) ** 2, axis=1)) ** -1, (no_dims, 1)).T * (Y[i, :] - Y), axis=0)
Y_momentum[i, :] = 0.9 * Y_momentum[i, :] - learning_rate * grad
Y[i, :] += Y_momentum[i, :]
if iter == 100:
P = P / 4 # stop early exaggeration
# 计算并记录 KL 散度
kl_divergence = np.sum(P * np.log(P / Q))
KL_history.append(kl_divergence)
if (iter + 1) % 100 == 0:
print(f"Iteration {iter + 1}: KL Divergence = {kl_divergence}")
return Y, KL_history
# 创建数据并运行 t-SNE
X = create_data(n=1000, dim=50)
Y, KL_history = tsne(X, no_dims=2, perplexity=30.0, max_iter=500)
# 绘制 t-SNE 结果
plt.figure(figsize=(10, 8))
plt.scatter(Y[:, 0], Y[:, 1], c=np.arange(Y.shape[0]), cmap=plt.cm.jet)
plt.title("t-SNE Result (2D Projection)", fontsize=20)
plt.colorbar()
plt.show()
# 绘制高维与低维空间的距离分布对比
plt.figure(figsize=(10, 8))
distances_high_dim = squareform(pdist(X, 'euclidean')) ** 2
distances_low_dim = squareform(pdist(Y, 'euclidean')) ** 2
plt.hist(distances_high_dim.flatten(), bins=100, alpha=0.5, label="High Dimensional", color='blue')
plt.hist(distances_low_dim.flatten(), bins=100, alpha=0.5, label="Low Dimensional", color='red')
plt.title("Distance Distribution Comparison (High Dim vs Low Dim)", fontsize=16)
plt.xlabel("Distance")
plt.ylabel("Frequency")
plt.legend()
plt.show()
# 绘制 KL 散度变化
plt.figure(figsize=(10, 8))
plt.plot(KL_history)
plt.title("KL Divergence over Iterations", fontsize=16)
plt.xlabel("Iterations")
plt.ylabel("KL Divergence")
plt.show()
# 绘制不同学习率对比的路径图
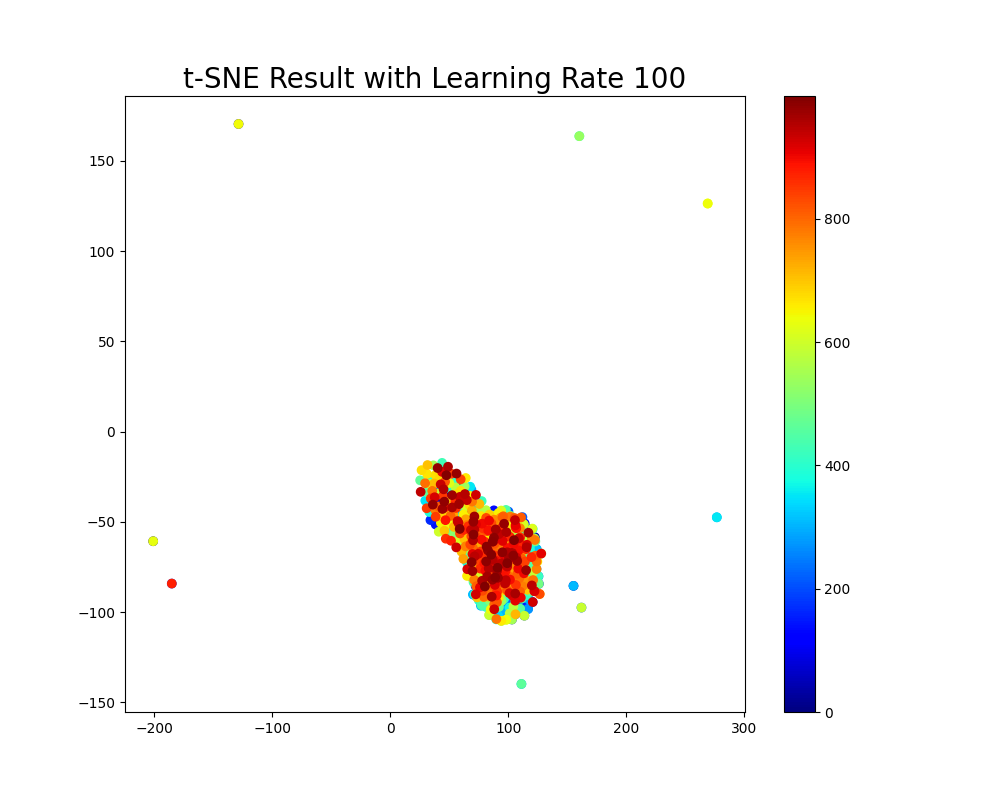
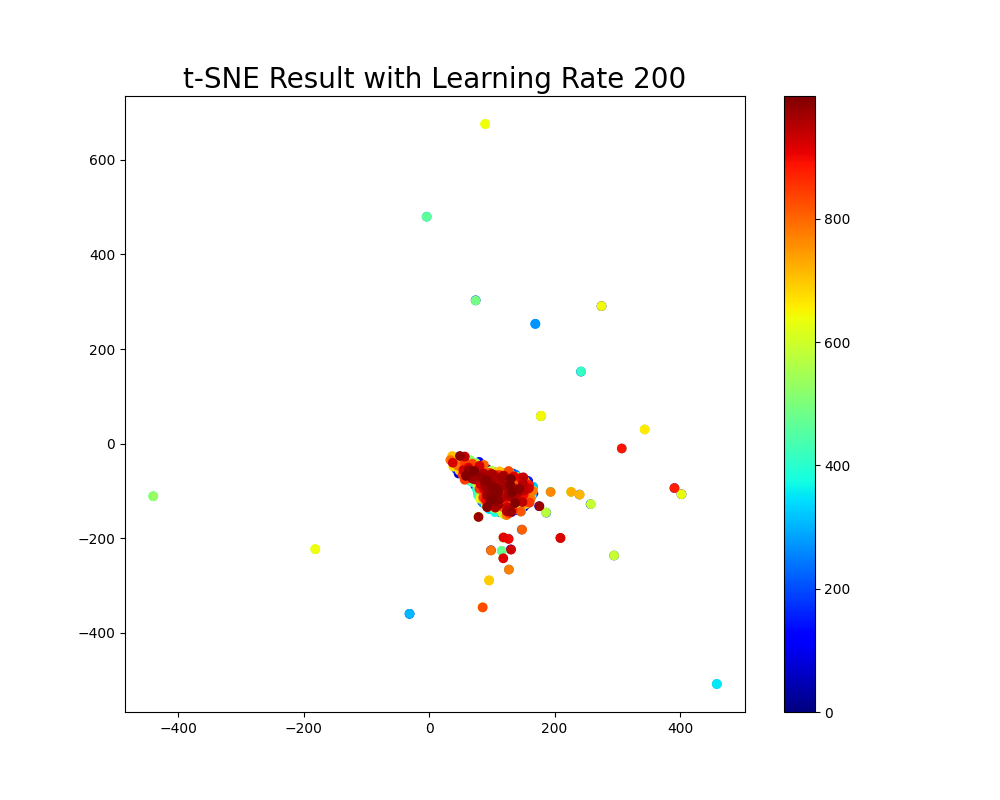
learning_rates = [50, 100, 200]
for lr in learning_rates:
print(f"Running t-SNE with learning rate {lr}")
Y_lr, _ = tsne(X, no_dims=2, perplexity=30.0, max_iter=500, learning_rate=lr)
plt.figure(figsize=(10, 8))
plt.scatter(Y_lr[:, 0], Y_lr[:, 1], c=np.arange(Y_lr.shape[0]), cmap=plt.cm.jet)
plt.title(f"t-SNE Result with Learning Rate {lr}", fontsize=20)
plt.colorbar()
plt.show()
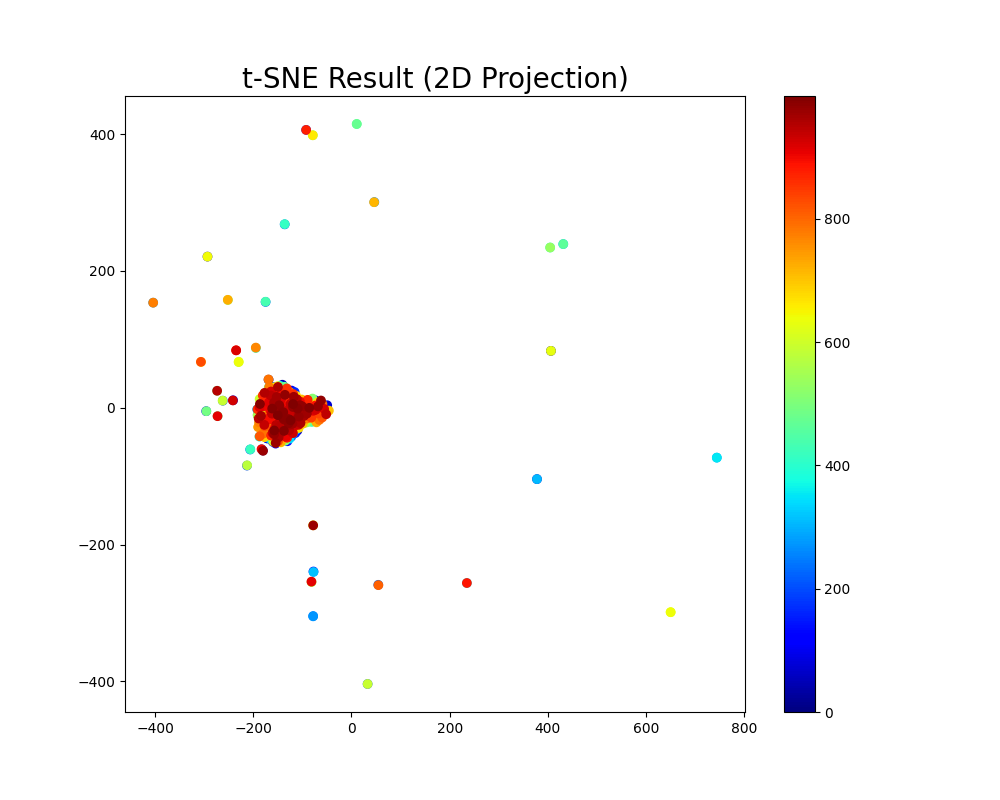
t-SNE 结果可视化:展示降维后的 2D 数据点的分布,颜色根据不同点编号区分。可以清晰看到数据聚类情况。

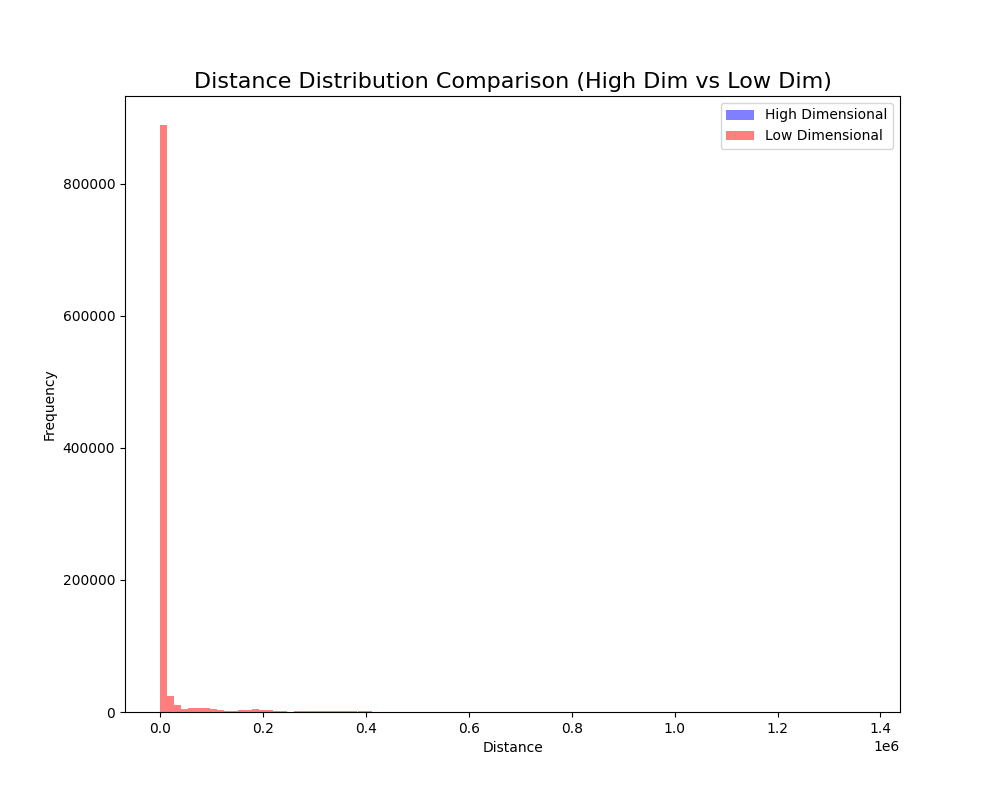
距离分布:可以进一步绘制高维和低维空间中点对之间的距离对比,展示 t-SNE 如何保留相似性。
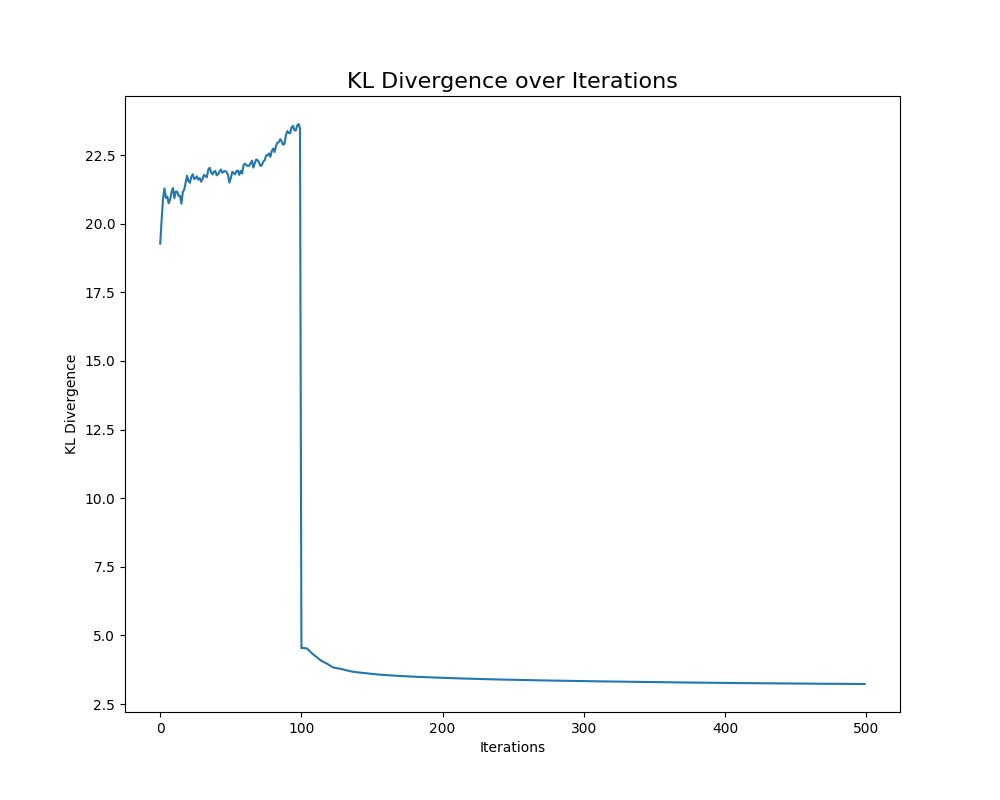
KL 散度变化图:展示 t-SNE 迭代过程中 KL 散度的变化,说明优化过程的收敛性。
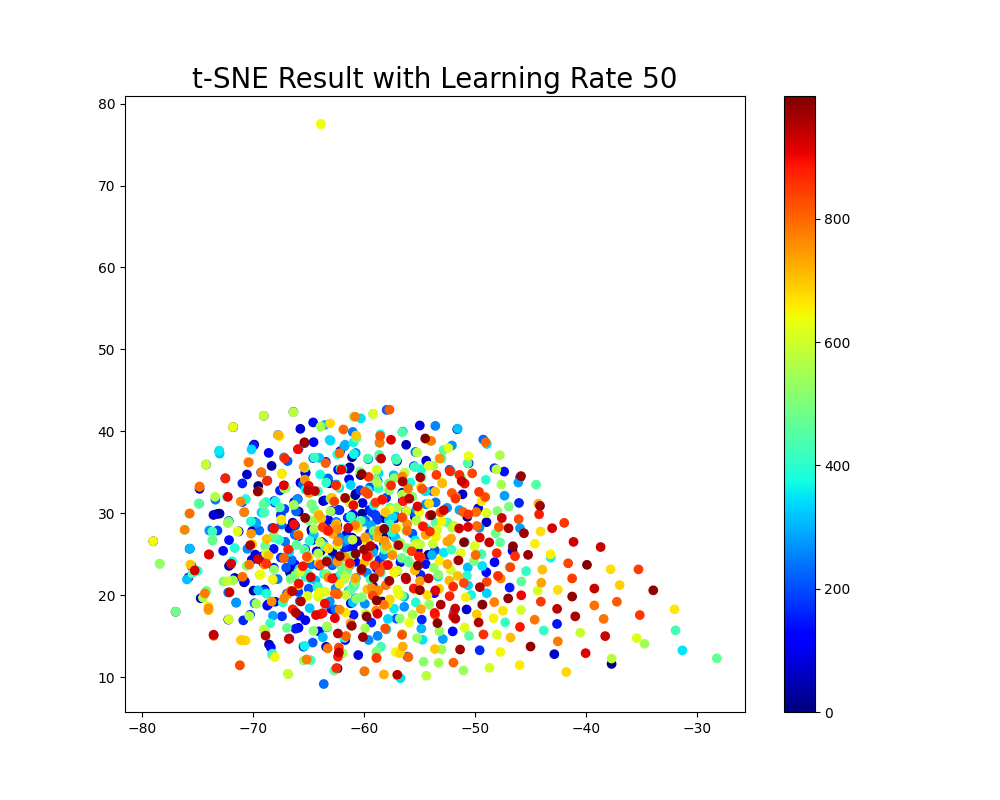
学习率和梯度下降路径图:展示在每次迭代中低维空间中点的移动路径,以及学习率对收敛速度的影响。
最后
需要本文 PDF 的同学,扫码备注「文章PDF」即可!

最近准备了16大块的内容,124个算法问题的总结,完整的机器学习小册,免费领取~
另外,今天给大家准备了关于「深度学习」的论文合集,往期核心论文汇总,分享给大家。

点击名片,回复「深度学习论文」即可~
如果你对类似于这样的文章感兴趣。
欢迎关注、点赞、转发~