
??大家好!欢迎来到创意Ai实验室公众号。感谢大家的支持与鼓励。在AIGC探索道路上,我将与你一路同行。喜欢就星标关注创意Ai实验室公众号文末扫码加入交流群或前往我的个人网站.

SOLAMI的核心特点
-
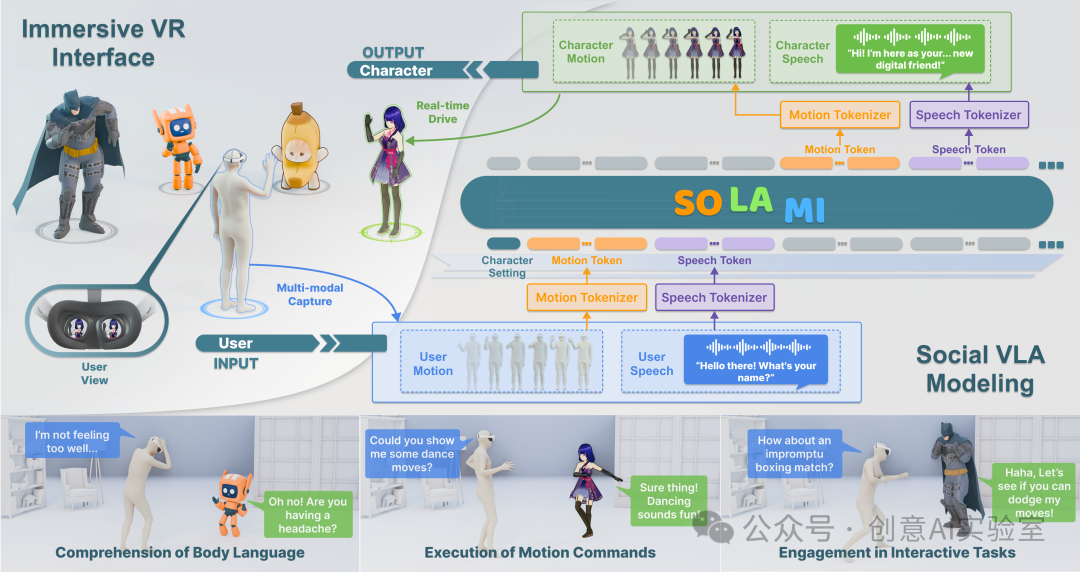
社会VLA架构: SOLAMI提出了一个统一的社会VLA框架,能够基于用户的多模态输入(语音和动作)生成多模态响应(语音和动作),驱动角色进行社交互动。
-
交互式多模态数据: 为了解决数据稀缺问题,SOLAMI团队介绍了SynMSI,这是一个通过自动流程仅使用现有动作数据集生成的合成多模态社交互动数据集。
-
沉浸式VR界面: SOLAMI开发了一个VR界面,使用户能够沉浸式地与这些角色进行互动,这些角色由各种架构驱动。
SOLAMI的技术实现
-
运动表示: SOLAMI直接对SMPL-X的兼容性建模人体姿势作为SMPL-X关节旋转,而不是关键点位置,以便于动画角色的下游工作。
-
运动标记化: 运动标记化采用Vector Quantized Variational Autoencoders (VQ-VAE)结构,学习运动的离散表示,使LLM能够理解文本-运动连接。
-
语音标记化: 语音标记化利用SpeechTokenizer,它分离语音中的语义和声学信息,允许我们使用语义标记作为输入到LLM,减少推理成本。
-
多模态多轮互动: 用户与角色的互动被格式化为多轮对话方式,SOLAMI模型根据之前的对话内容和角色设置自回归地生成语音和动作响应。
SOLAMI的应用前景
-
社交互动: SOLAMI可以用于模拟社交互动,提供更加自然和精确的角色响应,无论是在语音还是动作上,都能符合用户的期望,并具有更低的延迟。
-
教育培训: 在教育领域,SOLAMI可以创建模拟环境,提供安全的学习平台,用于技能培训和紧急情况演练。
-
娱乐和游戏: SOLAMI可以为游戏和娱乐行业提供新的互动方式,增强用户体验。
结论

