上午社群内大佬先发了这条消息,下午陆续在其他群看到了转发。还在验证时间的准确度,但其他内容与最早8月听到的几乎一致。
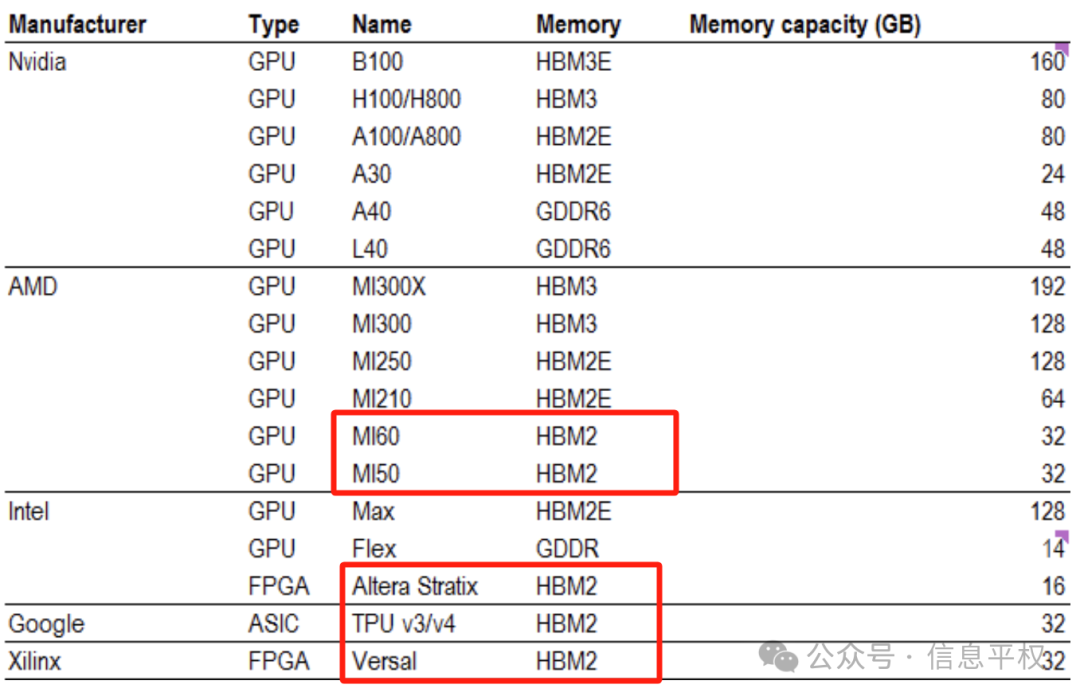
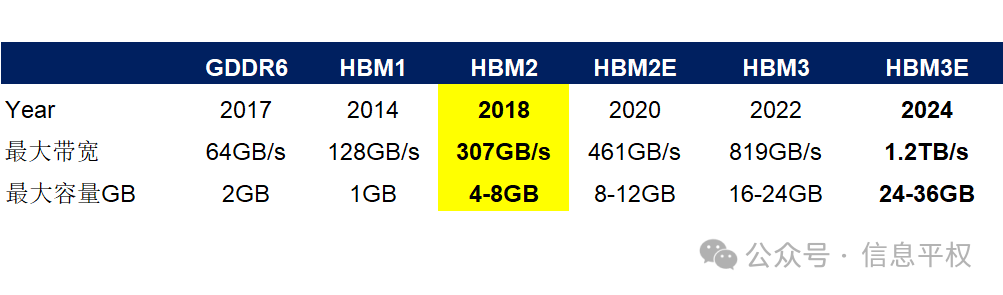
HBM2什么水平?如下,2018年的古老技术,带宽大概是目前海外最新代次HBM3E的1/4,单颗最大容量大概1/5,这还没考虑HBM3E下一步可以搞到16层去…

考古一下,哪些芯片用过HBM2?都TM停产了…什么谷歌TPU v3/v4,Intel Gaudi一代,AMD的MI50/60,可能你听都没听过
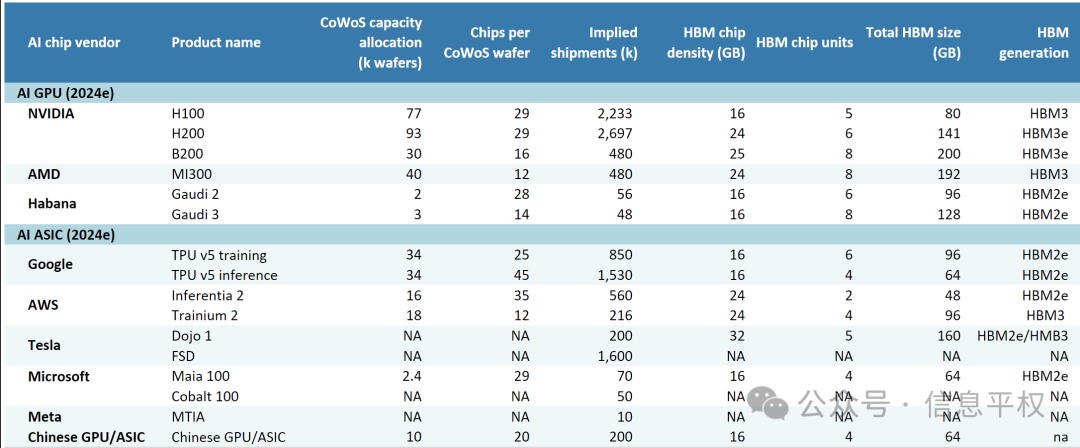
而目前市场上还在卖的主流加速卡,最低配也是HBM2e
目前主流的国产AI加速卡,的确都处于HBM2、HBM2e,比如耳熟能详的9XX就是2e,某5XX也是2e,某C5XX也是2e。因此一刀切到HBM2e多少是有点准。
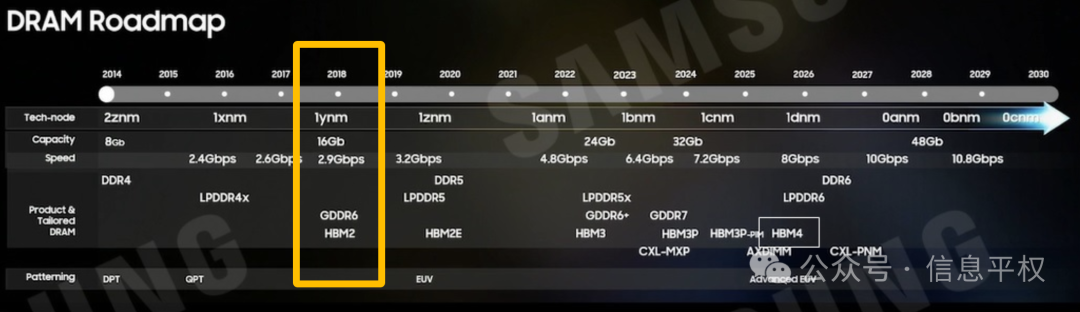
与此同时,国内…也是2e,但量很有限。按照某家的路线图可以清楚看到,目前我们的DRAM被卡在1x和1y之间,其实1ynm DRAM也就支持HBM2
如果真的只能用HBM2,对加速卡最终的影响有多大?我们1年前算过H20和910B的对比,但那个是按照卡间互联带宽。其实这两个“带宽”是一脉相承的,访存带宽和卡间互联带宽是要“匹配”的,因此计算单卡差距还不够,一旦算集群互联后的性能差距,可能是显存带宽差距的“平方”(非常粗的估计)。比如HBM2和HBM3E的带宽差距是4倍的话,集群的性能差距可能是16倍(其实一点不夸张)。简单来说,基本没法用了。比如H20即便继续阉割,只要还有HBM3,那依然保持优势。
当然了,这都是理论推演,谁说禁了就只能用HBM2…
以上涉及到的报告资料都已经在星球了,后续也请专业的嘉宾老师详细解读下目前HBM这件事后面如何推演