收录于话题
1. 引言
时间序列数据广泛存在于各类数据源中,例如传感器、金融市场、人口统计、音频以及Uber出行数据等。时间序列的普遍性意味着需要开发强大的预测方法。然而,目前流行的机器学习算法在时间序列预测领域的表现并不如其在其他领域那样出色,主要原因有两个:
-
时间序列数据的自相关性:时间序列数据中引入的自相关性打破了机器学习算法对数据独立同分布的假设,这使得机器学习算法难以在时间序列预测领域超越纯粹的统计方法。
-
数据获取成本高:许多时间序列数据的获取成本高昂,甚至难以获得,例如一个国家的GDP或一家公司的销售数据,通常在给定时间内只有少量的观测数据。这限制了复杂模型的训练和应用。
M4 竞赛是 Spyros Makridakis 组织的三次竞赛的延续,旨在对不同类型时间序列的预测方法进行评估和比较。竞赛吸引了学术界和业界的广泛关注,并为评估各种预测方法的有效性提供了客观证据。M4 竞赛的主要目标是:
-
复现前三次竞赛的结果。
-
将竞赛范围扩展到以下两个方面:
-
将时间序列数量增加到 100,000 条。 -
将机器学习(神经网络)预测方法纳入竞赛。
竞赛结果表明,简单的模型(如指数平滑和 ARIMA)通常优于复杂的模型。然而,本届 M4 竞赛的冠军是 Slawek Smyl 提出的混合指数平滑-循环神经网络(ES-RNN)方法,该方法将指数平滑技术与循环神经网络(RNN)相结合,在 M4 竞赛中取得了显著的 9.4% 的 sMAPE 改进。
本文旨在开发一种快速、可访问且通用的最先进时间序列预测模型,具体工作包括:
-
加速模型训练:将 Smyl 的 C++ 实现移植到 PyTorch,并利用 PyTorch 的向量化特性和 GPU 加速,将训练速度提高了 322 倍。
-
提高模型可访问性:使用 Python 编写代码,使得该模型更容易被预测和机器学习社区使用。
-
增强模型通用性:利用 PyTorch 库中丰富的架构,可以更容易地将 ES-RNN 模型应用于非 M4 时间序列数据。
2. 相关工作
时间序列分析领域自 20 世纪 50 年代以来,并没有偏离统计学的理论基础。经典的模型包括 ARIMA 方法和指数平滑方法。近年来,随着深度学习的发展,研究人员开始将深度神经网络(DNN)架构应用于时间序列预测。
一些研究工作包括:
-
注意力机制:Qin 等人开发了一种双阶段注意力机制,用于提高预测算法的性能。
-
残差 LSTM 和扩张 LSTM:一些研究人员将计算机视觉领域的经验应用于时间序列预测,例如 Kim 等人提出的残差 LSTM 和 Chang 等人提出的扩张 LSTM。
-
预训练权重:Malhotra 等人利用大量时间序列数据开发了预训练权重,这不仅提高了模型的泛化能力,还使得 DNN 可以应用于训练样本相对较少的环境。
M4 竞赛的结果表明,简单的模型通常优于复杂的模型,但 Slawek Smyl 提出的 ES-RNN 方法取得了显著的进步,该方法将指数平滑技术与 RNN 相结合。
3. 模型描述
本文的主要贡献是提出了一种新的 ES-RNN 实现方法。为了实现快速、可访问和通用的预测引擎,本文对 Smyl 在 M4 竞赛中的 C++ 实现进行了重新设计,以适应 GPU 计算。
3.1 ES-RNN 模型概述
ES-RNN 模型结合了经典的状态空间预测模型和现代 RNN 的优势,其核心思想是:
-
利用指数平滑进行预处理:对时间序列数据进行指数平滑处理,提取趋势和季节性信息。
-
利用 LSTM 网络更新参数:使用 LSTM 网络对 Holt-Winters 模型的每个时间序列参数进行更新。
具体来说,ES-RNN 模型分为两个主要层:
3.1.1 预处理层
预处理层使用具有乘法季节性和趋势的 Holt-Winters 指数平滑方法对时间序列数据进行预处理,其公式如下:
其中,( l ) 是水平状态变量,( b ) 是趋势状态变量,( s ) 是乘法季节性系数,( alpha ), ( beta ) 和 ( gamma ) 是介于 0 和 1 之间的平滑系数,( h ) 是预测步长。
Smyl 等人使用固定大小的输入和输出窗口,输出窗口由预测范围定义,而输入窗口则根据经验确定。
3.1.2 深度学习层
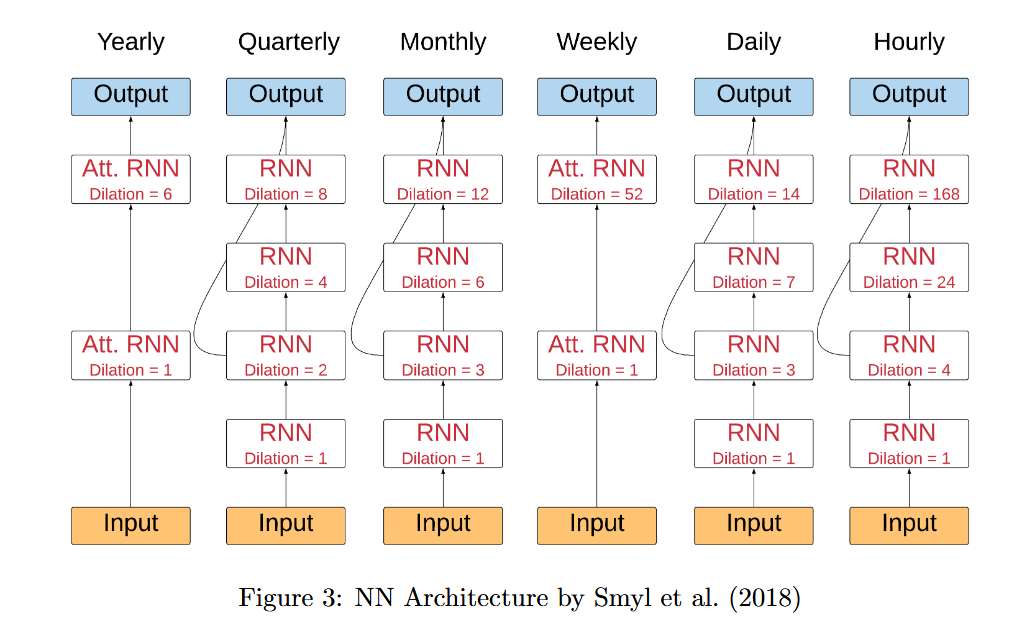
深度学习层使用 LSTM 网络,其架构如图 1 所示:
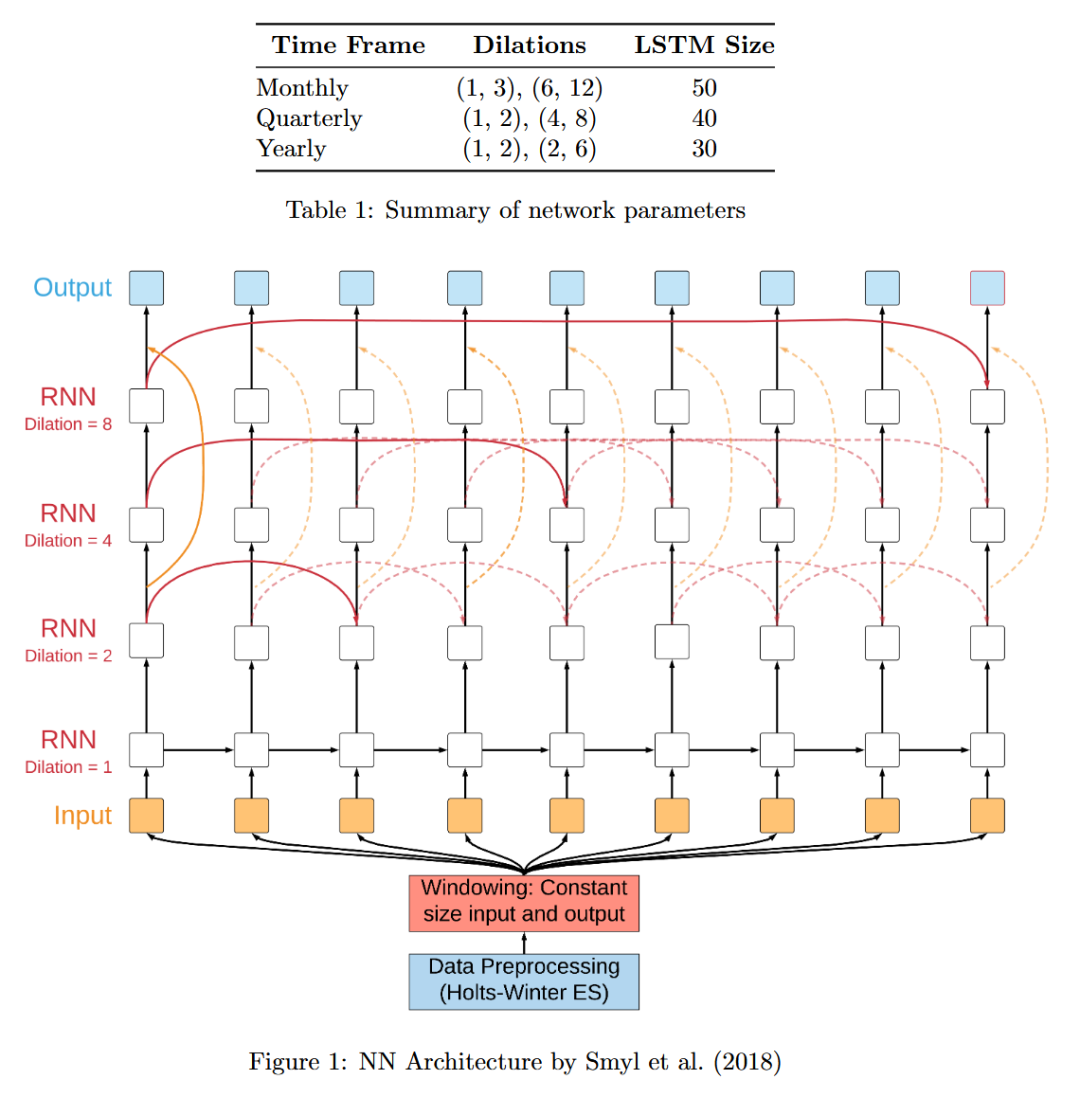

该架构主要包含以下特点:
-
扩张 LSTM 网络: 与传统的 LSTM 网络相比,扩张 LSTM 网络具有更高的计算效率和更强的记忆能力。其基本思想是在 LSTM 层之间引入扩张率,使得网络可以更有效地捕捉时间序列数据的长期依赖性。
-
残差连接: 残差连接可以稳定网络的训练过程。
-
线性输出层: 将 RNN 输出转换为标准化和去季节化的数据格式。
需要注意的是,RNN 和经典的 Holt-Winters 参数是联合训练的,Smyl 等人提出的模型的核心优势在于对每个时间序列的 Holt-Winters 参数和通用的 RNN 参数进行协同训练。
3.2 网络训练
该混合模型的训练过程与大多数神经网络训练不同:
-
初始化参数: 为了获得水平和季节性系数的初始估计值,使用经典的 Holt-Winters 方程 1 和 3 进行计算。对于数据集中包含 N 个时间序列的模型,将存储 N * (2 + S) 个 Holt-Winters 参数,其中 S 是季节性长度,因为每个时间序列都有其自己的水平和季节性平滑参数以及初始季节性值。
-
批量训练: 与 Smyl 等人在 CPU 上的实现不同,PyTorch 和 TensorFlow 等动态 GPU 计算框架支持批量训练。在图 1 中,最左侧输入框的输入可以看作是一个矩阵,其大小为批量大小 x 批次中最长输入窗口长度。
3.3 网络测试
为了生成网络的输出,将 LSTM 的输出通过一个具有 TanH 激活函数和非线性层,最后通过一个线性层得到预测结果。该输出是去季节化和标准化的,与真实数据不同。为了对输出进行重新季节化和去标准化,使用 Holt-Winters 方程和每个时间序列的参数估计值来获得所需的输出。
3.4 损失函数
为了计算损失,首先对输出进行去填充和掩码处理,因为这些损失值不包含在计算中。M4 竞赛中使用的指标是对称平均绝对百分比误差 (sMAPE) 和平均绝对比例误差 (MASE)。由于这些指标是不可微的,因此使用了一种称为 Pin-ball 损失的代理损失函数。
4. 数据描述
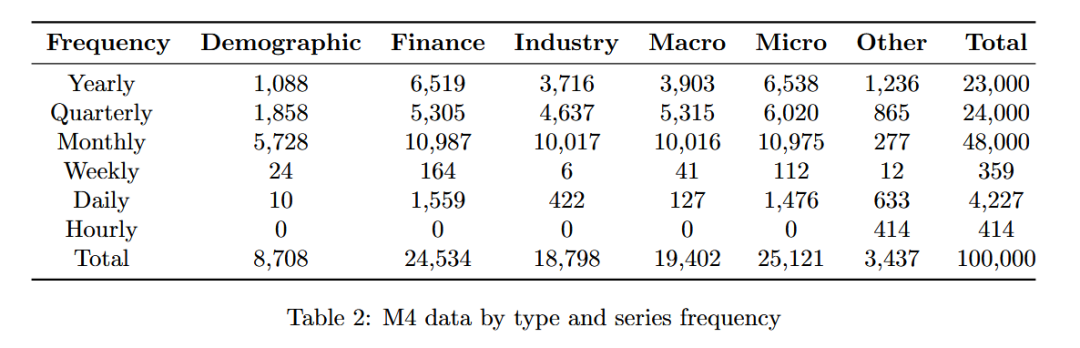
M4 竞赛数据包含 100,000 条时间序列,包括年度、季度、月份、周度、天和小时数据。此外,数据集是从真实数据中采样的,类别包括人口统计、金融、工业、宏观经济、微观经济和其它。
数据集具有以下两个显著特点:
-
数据是纯单变量的: 除了广泛的采样类别之外,系列之间没有保证的联系。观测数据之间缺乏时间或其他联系,这使得复杂方法的预测挑战更加困难,因为样本本身就是信号的唯 一表示。
-
每个系列的长度是可变的: 每个系列的长度不仅可变,而且有时对于输出预测范围来说非常短。
5. 数据准备
5.1 验证数据集
在时间序列分析中,预测被定义为给定系列数据的最可能输出。这意味着为了最大限度地利用训练数据,必须将数据的后半部分用于保留验证。从训练集的末尾提取最后 OutputSize 个时间步长来创建验证集。
5.2 系列长度均衡
M4 数据集中的系列长度是可变的。为了简化向量化实现,通过频率将所有系列均衡为固定长度,并忽略所有低于该特定长度的系列。
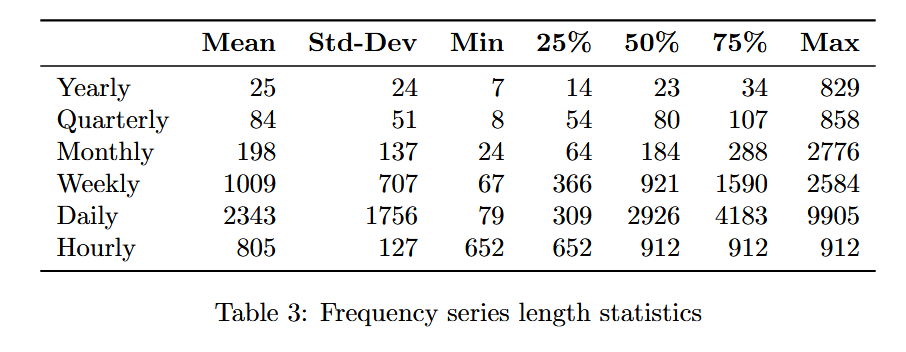
确定均衡系列长度的一个重要因素是权衡设置最小长度过高导致删除过多系列与设置最小长度过低导致删除过多系列历史记录之间的关系。因此,绘制了所有频率系列长度的直方图,以了解按频率划分的最佳阈值。
均衡频率内系列长度后,完整的数据集如下:
其中,( C ) 是最小长度阈值。
5.3 数据窗口化
在将数据传递到第 2 节中定义的第 2 层 RNN 层之前,对数据集进行窗口化处理,并使用第 3.1 节中定义的 ES 层的输出进行归一化和去季节化。
除了输入窗口之外,还将时间序列类别的一热表示连接起来。
6. 结果
自从第一次 M 竞赛以来,简单的模型(如指数平滑 (ES) 和 ARIMA)一直优于更复杂的模型,包括机器学习模型。这些类型的模型也是 M4 竞赛的基准: Makridakis 等人将简单、Holt 和 Damped ES 模型的简单平均值命名为 Comb。Comb 模型是一个难以超越的基准,在 M4 竞赛中排名第 19 位。此外,Hyndman 在 M4 竞赛中的第二佳提交作品是一个元学习器,它基于 R forecast 包例程对经典统计模型选择进行集成,包括自动 ARIMA、自动 ES、Theta、Naive、Seasonal Naive、Random Walk、TBATS 以及一个浅层 MLP。
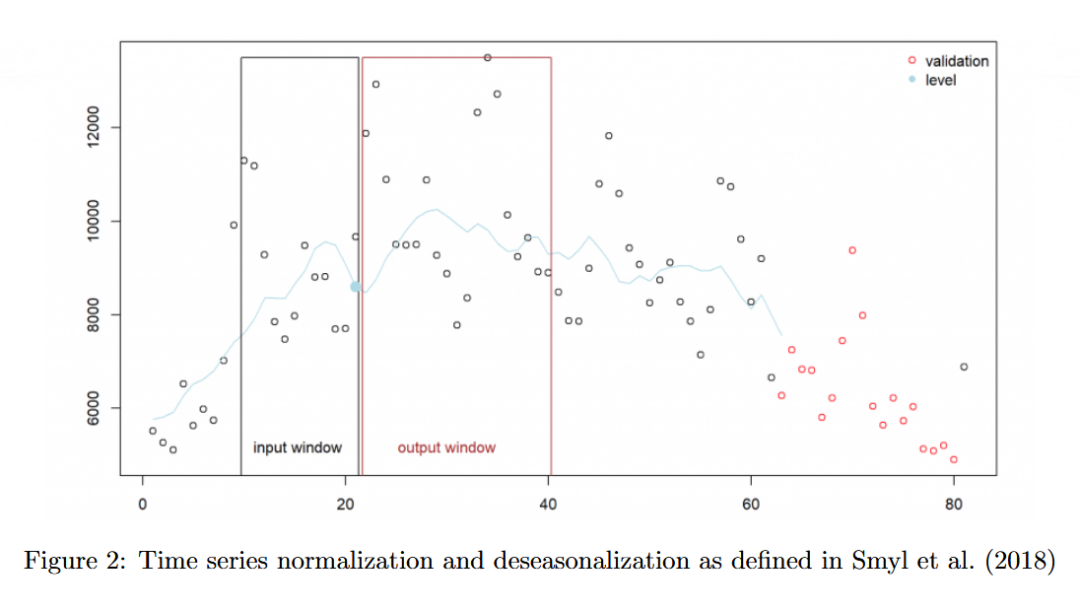
表 4 显示了 Smyl 等人提出的 ES-RNN 模型、Hyndman 的模型以及我们在 GPU 上实现的 Smyl 等人提出的 ES-RNN 模型的比较结果。此外,表 5 显示了我们在 GPU 上的实现运行时间以及 Smyl 等人在 CPU 上的运行时间。
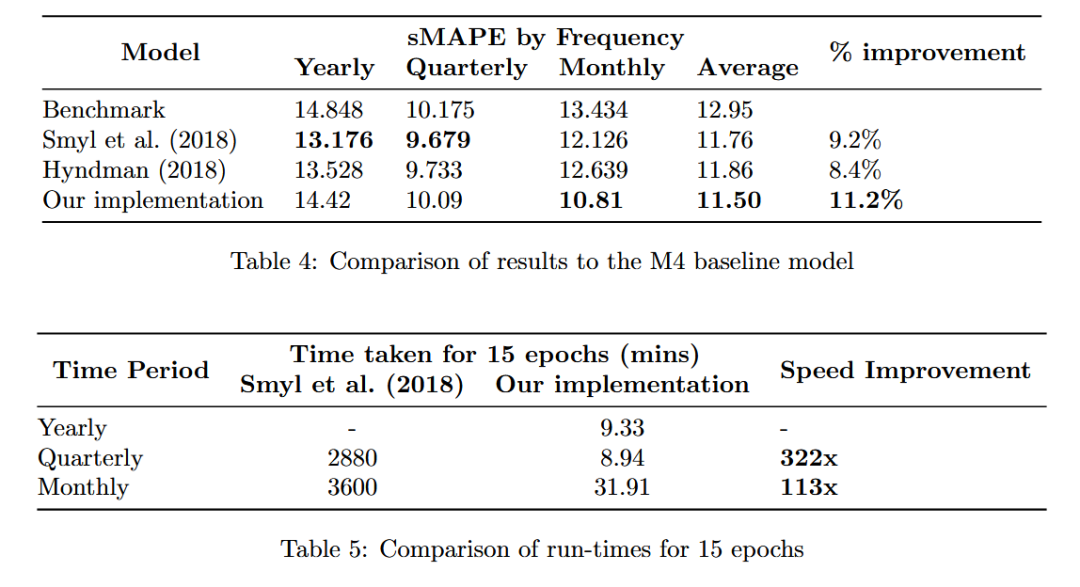
表 6 详细列出了我们的实现在六种不同数据类别中每个频率(以及相应的模型)实现的 sMAPE。
| 数据类别 | 年份 | 季度 | 月份 |
|---|---|---|---|
| 人口统计 | 11.61 | 10.78 | 6.31 |
| 金融 | 15.86 | 10.74 | 11.58 |
| 工业 | 19.57 | 7.44 | 12.38 |
| 宏观经济 | 15.69 | 9.57 | 12.45 |
| 微观经济 | 11.35 | 11.63 | 9.94 |
| 其它 | 14.33 | 7.87 | 12.51 |
| 总计 | 14.42 | 10.10 | 10.81 |
7. 讨论
本项目最重要的成果是速度的提升。我们观察到,与 CPU 方法相比,我们的 GPU 实现在季度数据集上的运行速度提高了 322 倍。这种加速是由向量化实现驱动的,它支持批量处理和并行化。
与 Smyl 等人的实现相比,本文的实现在月度数据上的表现优于原始模型和基准。这可能是由于以下两个原因:
-
原始实现的较长的训练时间可能使得参数空间的迭代成本过高。
-
第 5.2 节中讨论的系列长度均衡可能在某些情况下简化了问题,而在另一些情况下省略了较难、较短的序列。
总体而言,由于月度数据集的改进,本文的实现具有最低的加权 sMAPE 分数。
本论文的实现在大多数频率上与 M4 实现接近。然而,Smyl 等人在年度数据集上取得的分数差异较大,这可能是由于原始作者在残差和扩张 LSTM 之上使用了注意力 LSTM,而本文当前实现不包括这一点。此外,Smyl 等人没有对年度数据使用任何季节性参数,而本文的实现并非设计用于处理这种情况。
论文及代码已整理至QuantML星球,QuantML星球内有各类丰富的量化资源,包括上百篇量化论文代码,QuantML-Qlib框架,研报复现项目等,星球群内有许多大佬,包括量化私募创始人,公募jjjl,券商研究员,顶会论文作者,github千星项目作者等,星球人数已经500+,欢迎加入交流
我们的愿景是搭建最全面的量化知识库,无论你希望查找任何量化资料,都能够高效的查找到相关的论文代码以及复现结果,期待您的加入。