



编辑|星奈
媒体|AI大模型工场
国产视频大模型Vidu重磅发布1.5新版本(www.vidu.studio),全新上线「多主体一致性」功能,首个突破了涵盖人物、物体、环境等融合的多主体一致性能力!

早在9号,Vidu就在官方账号上预热了此次发布,同步放出一段案例,案例中上传一张 黑人男子照片、铠甲图、城市街景,Vidu1.5 便将这三者元素完美的融合到一个视频中,实现“男子穿着铠甲走在街道”上的画面。从效果看,Vidu 1.5 赋予了视频模型前所未有的控制能力,通过图片输入来实现精准控制和编辑!

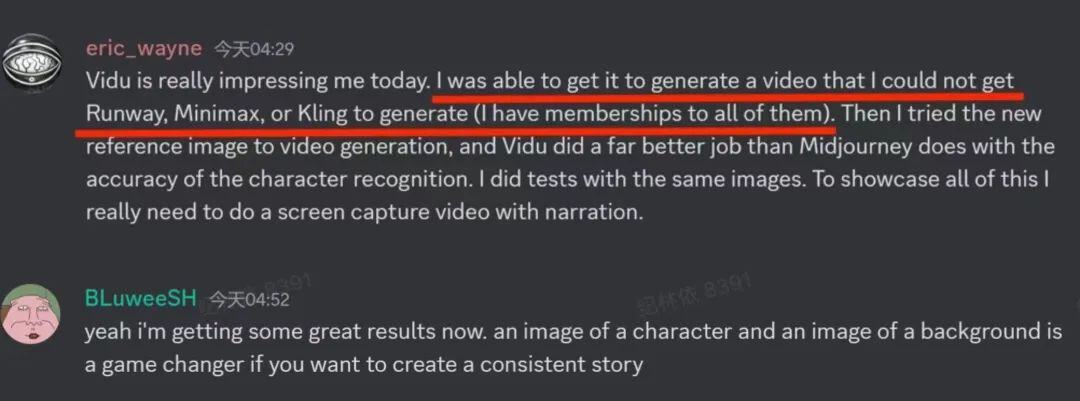
更有海外用户更是直呼“改变了游戏规则”,未来“只要上传一张角色图+一张环境图”就可以创作连续的视频故事。

地表最强!「多主体一致性」难题被攻克
特别是在处理包含多个角色或物体的场景时,现有模型还无法做到对多个主体同时进行控制,例如,主体间的特征容易产生混淆,主体间的互动也难以保持自然连贯。
不过,这一“世纪难题”如今被国产视频模型攻克了!
国产视频模型Vidu上新1.5版本,全新上线「多图参考」功能,通过上传一至三张参考图,实现对单主体100%的精确控制,同时实现多主体交互控制、主体与场景融合控制,能够无缝集成人物、道具和场景。
Vidu自最初上线以来,就一直致力于解决视频模型中「一致性」的核心难题:早在7月底全球上线的时候,Vidu 就推出「角色一致性」功能,用户可上传自定义的角色图,然后指定该角色在任意场景中做出任意动作;在9月初,Vidu全球首发了「主体参照」功能,允许用户上传任意主体的一张图片,通过描述词任意切换场景。这次 Vidu 1.5 则是进一步深化了在「一致性」方面的领先布局和深厚优势。
对于单主体而言,通过上传特定主体的不同角度或不同景别下的图片,Vidu 1.5 能实现100%精准控制。
一是对复杂主体的精准控制:无论是细节丰富的角色还是复杂的物体,Vidu 1.5都能保证主体形象在不同角度下的高度一致,整体形象始终如一。
比如下面的复古美女,造型极具复杂度,但无论在何种景别、视角下,甚至是特写镜头中,角色的形象都能始终保持高度一致。通常视频模型在生成侧面、背面等刁钻视角的画面时,往往靠模型“自行脑补”,这过程中就容易出现各种不满足用户预期的画面,Vidu 1.5完全避免了这一问题,能够保证不同视角下主体信息的准确。


除了能实现对单主体的精确控制,可在Vidu1.5的「多图参考」中选择上传多个主体,可以均是人物角色,也可以是人物+道具物体等,以实现多主体的一致性控制。
比如我们让小李子和宋小宝握个手

双角色主体
描述词:两个人在握手
除了控制双角色主体外,三角色主体,甚至指定主体和场景图,Vidu1.5都能轻松实现。
例如,我们让马斯克穿上东北大花袄骑着电动车在游乐园逛。

描述词:男人穿着花袄在游乐园骑电动车
也可以让宋小宝穿着东北大花袄在比萨斜塔前打卡。

双主体(角色+道具)+场景
终结LoRA炼丹时代!仅靠三张图稳定输出
所谓LoRA(Low-Rank Adaptation)方案,即在预训练模型的基础上,用特定主体的多段视频进行微调,让模型理解该主体的特征,从而能生成该主体在不同角度、光线和场景下的形象,保证其在若干次不同生成时的一致性。
简单理解,比如我创作了一只卡通狗的形象,想生成连续一致的视频画面,但模型在预训练过程中并没有学习过该形象,所以需要拿卡通狗的多段视频,让模型进一步训练,让模型认识这只卡通狗长什么样,从而能够生成。
但这里的问题是,通常LoRA需要20~100段的视频,数据构造繁琐,且需要一定的训练时间,通常需要数个小时甚至更久的时间,成本为单次视频生成的成百上千倍。
另外LoRA微调模型容易产生过拟合,即在理解主体特征的同时,也会遗忘大量原先的知识。这导致对于动态的表情或肢体动作的变化,很难有效控制,所以生成的视频容易产生僵硬或不自然的效果,以及在复杂动作或大幅度变换时,微调模型无法很好地捕捉细节,导致主体特征不够精准。
所以LoRA主要适用于大多数简单情形下的主体一致性需求,但对于高复杂的主体或问题场景,需要更多的微调数据和更复杂的模型微调策略。


■ 商汤日日新、腾讯,昆仑万维 ▍ 金融大模型案例
■ 盘古大模型,中国电信,医联 ▍医疗大模型案例
■阅文大模型,腾讯音乐大模型 ▍ 文娱大模型案例
■知乎,360大模型,火山引擎 ▍ 教育大模型案例
■ 网易,金山办公大模型 ▍ 更多行业大模型案例
上次介绍中国AI大模型平台排行榜 | 10月

本文由大模型领域垂直媒体「AI大模型工场」
原创出品,未经许可,请勿转载。
/
欢迎提供新的大模型商业化落地思路