
收录于话题

代码下载见星球,欢迎加入QuantML星球
本文介绍了一种基于生成对抗网络(GANs)的新方法——Fin-GAN,用于金融时间序列的预测和分类。该方法旨在提供概率预测,并超越传统点估计方法。Fin-GAN通过引入一种新的经济学驱动的损失函数,将GANs置于监督学习环境中,从而在金融应用中更适合分类任务。
1. 引言
时间序列预测一直是工业界和学术界关注的热点话题。在金融和经济领域,时间序列可以代表金融工具的价格、通货膨胀率以及其他关键宏观经济指标。交易策略基于对金融工具价格未来走势的预测,因此,时间序列预测和分类在金融环境中至关重要。传统方法主要依赖于点估计,无法提供概率预测或对目标变量未来分布形式的强假设,导致无法捕捉不确定性。
本文采用ForGAN架构,将GANs与循环神经网络(RNNs)结合,以生成概率预测。进一步引入了一种新的经济学驱动的损失函数,以提高夏普比率性能。该损失函数在生成器损失函数中加入了额外项,使其更适合金融应用中的分类任务。
2. 相关工作
时间序列建模一直是工业界和学术界的研究热点。近年来,机器学习的兴起导致其在时间序列建模中的应用越来越多。然而,将机器学习应用于金融领域的时间序列建模已有长期研究。
深度学习在金融领域的应用文献丰富。Guresen等人使用神经网络进行股票市场预测,而Sirignano和Cont利用LSTM论证了资产价格特征的普遍性。深度学习应用的一个特别感兴趣的领域是限价订单簿(LOB)建模。Sirignano引入了空间神经网络,旨在对限价订单簿的未来状态进行联合分布建模。Tsantekidis等人利用卷积神经网络进行高频、大规模数据中的股票价格走势预测,而Tsantekidis等人则使用循环神经网络方法解决相同问题。TransLOB Wallbridge和DeepLOB Zhang等人引入了更复杂的架构,具有高预测精度。Zhang和Zohren则超越了短期LOB预测,专注于多时间范围设置。Lucchese等人引入了deepVOL,旨在使用LOB的成交量表示来预测中间价格。Deep Hedging也在工业界和学术界引发了深度学习用于对冲的兴趣。
GANs已被用于投资组合分析、高频股票市场预测、金融交易策略的微调和校准等。QuantGAN、StockGAN、FINGAN和Buehler等人专注于生成合成金融时间序列。Li和Prenzel等人均采用GANs进行LOB中的订单流动态。GANs还用于金融市场中的异常(操纵)检测,并且通过GANs进行股票市场预测已与其他方法进行了探索和比较。
在适应时间序列的GANs方面,Yoon等人引入了TimeGAN,Xu等人提出了COT-GAN。TimeGAN利用嵌入和恢复网络将数据映射到高维潜在空间并返回。COT-GAN引入了一种基于正则化Sinkhorn距离的定制损失函数,该距离源自因果最优传输理论。然而,TimeGAN和COT-GAN都不是为预测任务量身定制的,主要用于数据增强。
本文重点关注Koochali等人的工作,他们引入了ForGAN,这是一种适合概率时间序列预测任务的条件GAN。该方法允许进行不确定性估计,这是传统时间序列预测方法无法提供的。
3. 生成对抗网络
生成对抗网络(GANs)由Goodfellow等人于2014年引入,目前在各种任务中处于最先进水平,最值得注意的是图像和视频生成。它们还广泛应用于科学、视频游戏、照片编辑、视频质量增强等领域。它们属于生成模型家族,其任务是生成来自未知数据分布的新样本。
3.1 经典GAN
经典GAN可以通过博弈论视角来理解。假设我们有两个玩家,生成器G和判别器D,互相进行游戏。G生成它认为看起来逼真的样本,而D则确定给它的样本是来自数据还是来自生成器。G的目标是学习如何让D相信它的输出是来自数据的,并生成尽可能逼真的样本。另一方面,D试图学习如何正确区分数据样本和来自生成器的样本。生成器G使用从判别器D接收到的反馈来改进生成的样本。在GANs中,生成器G和判别器D都是相对于其参数的可微函数,并且它们由神经网络表示。G被给予一些噪声作为输入,通常是高斯的,并返回生成的样本作为输出。D将G生成的样本或来自数据的真实样本作为输入,并输出其输入为真实的概率。GANs通过对抗过程进行训练,该过程包括同时训练两个不同的模型,一个生成器和一个判别器。在神经网络的情况下,这可以通过反向传播有效地实现。
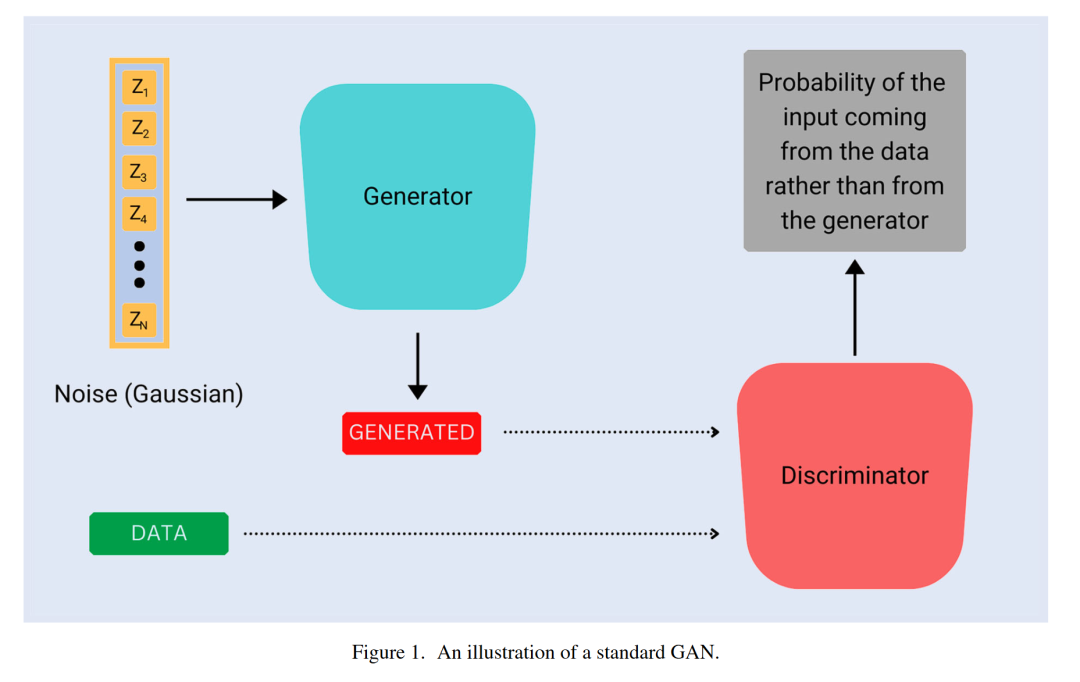
假设我们有一些数据x来自未知的概率分布Pdata,并且我们希望从Pdata生成更多样本。
定义3.1 生成器G(z; θg)是从潜在空间到数据空间的微分映射。它由一个神经网络表示,接受输入噪声z ~ Pz(z)。G的输出所属的概率分布表示为Pg。
注释3.1 通常,z是一个多元正态分布。
定义3.2 判别器D(x; θd)是从数据空间到(0, 1)的微分映射,由一个神经网络表示。D(x)表示网络估计的x来自Pdata而不是来自Pg的概率。
判别器D被训练以最大化正确标记来自Pdata和Pg的样本的概率。生成器G被训练以最小化D正确标记其输出为来自Pg的对数概率,或最大化判别器出错的概率。
两个网络都有各自的目标函数,它们旨在最小化。这两个网络只能更新自己的参数以最小化各自的目标函数,尽管每个网络的目标函数都依赖于另一个网络的参数。在执行优化时,它们需要保持另一个网络的参数固定。通常,判别器采用的目标函数是交叉熵损失。
定义3.3 判别器的目标函数J(D)(θd, θg)定义为
J(D)(θd, θg) = ?Epdata [log[D(x; θd)]] ? Epz [log[1 ? D(G(z; θg); θd)]].
通过这个判别器的目标函数和J(G) = ?J(D)作为生成器的目标函数,学习零和游戏可以最小化Pdata和Pg之间的Jensen-Shannon散度。如果两个策略可以在函数空间中进行更新,游戏将收敛到纳什均衡,这在实践中通常不是这样,正如Goodfellow(2017)所论证的。当收敛发生时,判别器将所有输出视为同样可能来自Pdata或Pg,因此其输出将收敛到1/2。然而,Goodfellow等人(2014)和Goodfellow(2017)认为应该优先考虑最大化交叉熵损失而不是优化零和游戏。这种方法对应于生成器最小化判别器出错的概率对数。也就是说,生成器试图从判别器获得尽可能高的分数。
定义3.4 生成器的交叉熵损失J(G)(θd, θg)定义为
J(G)(θd, θg) = ?Epz [log[D(G(z; θg); θd)]].
Goodfellow等人(2014)进一步论证了使用生成器的交叉熵损失,即最大化log[D(G(z; θg); θd)],是因为零和损失可能无法为G提供足够大的梯度以使其能够很好地学习。在训练初期,G的样本很容易被识别为不是来自数据的,D可以强烈地将其分类为如此,使得log[1 ? D(G(z; θg); θd)]饱和。这使得G更难学习。将目标改为最大化log[D(G(z; θg); θd)]会导致D和G的动力学达到相同的平衡点,同时允许更大的梯度,使得生成器G能够学习更多。通常,判别器会训练得更多,每个生成器更新执行k次判别器更新。然而,Goodfellow(2017)认为应该使用k = 1。标准GAN的图示可以在图1中找到。
训练GAN时出现的主要问题是模式崩溃,也称为“模式崩溃”情景。它可以是完全的和部分的。当它发生时,无论噪声如何,生成器都会产生相同的输出(全模式崩溃),或者所有输出都有相似的图案(部分模式崩溃)。Durall等人(2021)认为模式崩溃与生成器转向尖锐局部最小值有关。当生成器开始生成相似的输出,并且由于可能收敛到局部最小值,判别器无法识别它们是来自生成器时,生成器会从判别器获得高评分。这可能导致弱梯度和对生成器网络的几乎没有更新,最终可能导致模式崩溃。
值得注意的是,保持生成器和判别器的平衡至关重要。当判别器压倒生成器时,这一点尤为重要。当判别器过于成功时,生成器无法从接收到的反馈中学习太多,因为梯度很弱。
总的来说,GANs非常难以训练(Arjovsky和Bottou 2017),因此自然要考虑改变训练目标。各种目标已被证明表现良好(Huszr 2015),包括所有f-散度(Nowozin等人 2016)。然而,最常用的GAN变体不是标准的交叉熵或零和GAN,而是Wasserstein GAN(W-GAN),由Arjovsky等人(2017)引入。它最小化了Pg和Pdata之间的Wasserstein-1距离。通常,Wasserstein GANs与梯度惩罚(Gulrajani等人 2017)更受欢迎,因为它们软化了Lipschitz约束。这种方法在判别器的训练目标中加入了梯度惩罚。
3.2 条件GAN
条件生成对抗网络是标准GAN的自然扩展,最初在最初的GAN论文中提到(Goodfellow等人 2014),并由Mirza和Osindero(2014)首次探索。我们假设数据x来自条件分布Pdata(x|condition),给定某个确定的条件,而不是所有数据样本来自相同的底层分布。在这种情况下,相同的原则适用。架构中的唯一区别是生成器和判别器都接收到进一步确定的信息(条件)以及标准输入。当这个条件是一个标签时,它通常被编码为一个独热向量。判别器/批评者也接收到相同的条件。条件GAN的图示可以在图2中找到。
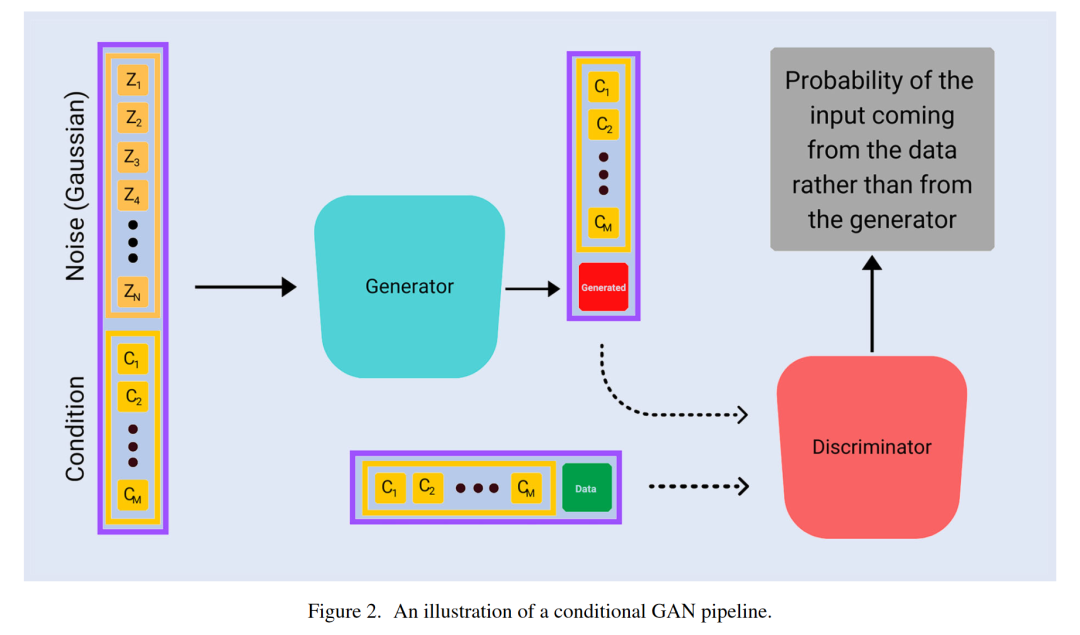
作为一个直观的例子,我们可能旨在生成猫和狗的照片。我们有可用的猫和狗的标签作为独热向量。生成器将接收噪声和一个标签(例如猫)作为输入,并输出它认为的猫的照片。判别器将接收来自原始数据的猫的照片,以及生成器网络生成的猫的照片,两者都带有标签,表明照片应该是猫的照片。然后,判别器将对来自真实数据的猫的照片和来自生成器的猫的照片提供反馈,并学习。
3.3 ForGAN
ForGAN是一种条件GAN,其架构非常适合时间序列的概率预测,由Koochali等人(2019)引入。想法是使用条件GAN对给定序列的前L个值,Xt, Xt-1, …, Xt-(L-1),我们表示为X(L),进行xt+1的概率预测。这与标准点估计相比,可以利用更多的信息,并使该方法易于获得不确定性估计。
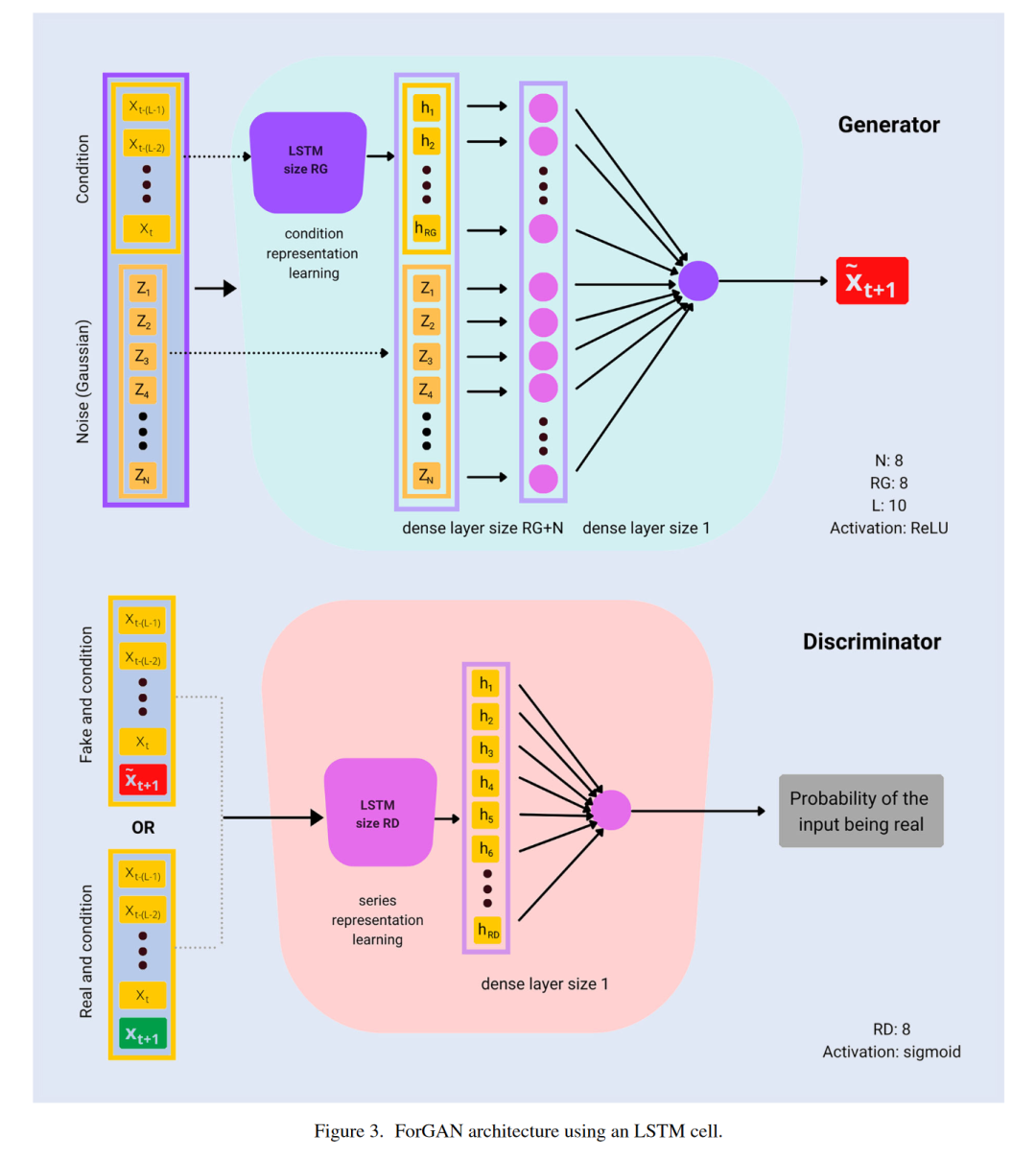
为了利用时间序列结构,生成器和判别器首先将它们的输入通过一个循环神经网络层。ForGAN架构包括门控循环单元(GRU)(Cho等人 2014)或长短期记忆(LSTM)单元(Hochreiter和Schmidhuber 1997),具体取决于数据。在我们的工作中,我们选择使用LSTM单元,因为其在金融领域的普遍性。类似的架构已经成功用于股票市场预测任务,例如,Zhang等人(2019a)。图3显示了使用LSTM单元的ForGAN架构的图示。
4. 性能指标
有多种方法可以衡量模型性能。根据应用情况,并非所有性能指标都同样重要。为了将一种方法与另一种方法进行比较,重要的是了解我们最关心的数据的哪些属性,以便能够构建适当的性能指标。
4.1 GANs的标准方法
衡量GANs的性能非常困难,因为我们通常不知道真实数据来自什么分布。通常,当处理图像、视频或声音时,有许多人类注释者来对生成的和真实的样本提供反馈。或者,可以使用初始得分(Salimans等人,2016)。它基于给定标签的条件数据分布与边际标签分布之间的Kullback-Leibler散度。这个得分还考虑了生成样本的多样性。不幸的是,上述方法都不能应用于我们的设置。
4.2 时间序列的标准方法
传统上,当手头的任务是时间序列预测时,人们会选择均方误差(MSE)、均方根误差(RMSE)和平均绝对误差(MAE)等性能指标。
为了定义MAE和RMSE,假设我们希望估计的真实值是x,而我们的预测是x。这可以是给定单个噪声样本的GAN输出,或者是给定相应条件的生成分布的均值或众数。然后,平均绝对误差和均方根误差定义为:
MAE(x, x) = (1/n) * Σ |xi – xi|, i=1到n
RMSE(x, x) = sqrt((1/n) * Σ (xi – xi)^2), i=1到n
4.3 金融数据,预测收益
由于我们处理的是金融数据,MAE和RMSE并不像在传统时间序列设置中那样具有代表性。在金融环境中进行预测通常是为了确定交易的方向(即是买入还是卖出资产),这为考虑基于损益(PnL)的指标提供了动力。虽然MAE和RMSE都可能非常低,但仍然有可能错误分类基础资产价格大幅波动的方向/方向性,导致严重的PnL损失。因此,我们将PnL作为我们的主要性能指标之一。在每个时间点,我们都会对(ETF超额)收益时间序列的真实值进行预测,并根据我们的预测进行交易。如果我们对ETF超额收益的预测为正,我们就会做多股票并做空相应的ETF。相反,如果它是负的,我们就会进行相反的交易。这一系列交易会产生一个PnL的时间序列。为了最小化风险并最大化利润,人们的目标是PnL时间序列为正,并且方差较低。PnL系列平均值越大,我们的策略的盈利能力就越高。PnL系列的方差越低,与策略相关的风险就越低。总的来说,这导致我们采用年化夏普比率作为我们的主要性能指标。我们注意到,这也是投资组合经理通常用来评估其策略的风险调整后表现的指标。
接下来,我们在使用的数据的上下文中定义上述术语。当考虑股票时,我们处理的是市场超额收益,而对于ETF,我们使用原始收益。假设资产A在时间t的价格为SA,那么它在时间t + 1的收益定义为:
SA(t+1) = log(SA(t+1) / SA(t))
如果资产A所属的行业有相应的ETF I,其在时间t的收益为rI,那么资产A在时间t的超额收益定义为:
rA(t) = rA(t) – rI(t)
如果我们预期A的收益高于I,那么我们就做多一股股票A并做空一股ETF I。我们对相反的情况也做类似的处理。因此,如果我们对rA(t+1)的预测是fA(t+1),那么这个策略的PnL(在时间t + 1)是:
PnL(t+1) = sign(fA(t+1)) * rA(t)
其中我们使用符号函数的左连续版本:
sign(x) = 1 如果 x ≥ 0, -1 如果 x < 0
为了简化分析和比较,我们考虑以基点为单位的PnL,并通过除以总交易次数来归一化。在我们的设置中,交易次数是验证/测试集的大小。如果我们有n个我们希望预测的rA值,表示为rA(1), …, rA(n),我们考虑每次交易的PnL(以基点为单位),为了简单起见,我们将其称为pPnL。正式地,这相当于:
pPnL = (1/n) * Σ sign(rA(i)) * rA(i), i=1到n
我们注意到,(8)式定义的pPnL没有考虑到预测符号的不确定性,只考虑了点估计。
由于我们可以获得完整的概率预测,我们理想上会对我们更有信心的回报给予更大的权重,而对那些我们不太确定的回报给予更小的权重。因此,我们通过为相同的条件取B = 1000个不同的噪声样本,估计(ETF超额)收益预测为正和负的概率。这两个概率估计分别表示为Pu和Pd,更准确地定义为:
Pu = (1/B) * Σ [1 如果 ref(z(j)) ≥ 0, 0 如果 ref(z(j)) < 0], j=1到B
Pd = (1/B) * Σ [1 如果 ref(z(j)) < 0, 0 如果 ref(z(j)) ≥ 0], j=1到B
其中ref(z(j))是生成器在给定时间序列rA(-L)的前L个值和噪声z(j)的情况下给出的输出。我们现在可以定义一个替代的PnL,我们可以将其构建为一个加权策略的PnL,该策略考虑了我们在预测符号上的确定性,如下:
wPnL(j) = 10000 * (Pu – Pd) * rA(j)
这个策略对应于做多Pu * 10000 * rA(j)股股票和做空Pd * 10000 * rA(j)股ETF,或者做空Pu * 10000 * rA(j)股股票和做多Pd * 10000 * rA(j)股ETF。这是等效策略的PnL,包括在不同的噪声样本中,根据适当条件对生成器的每个输出进行平均下注。因此,我们对更高的不确定性惩罚更多,如果我们不太确定结果,我们就会获得显著更低的潜在损失。
请注意,我们将PnL乘以10,000,以便获得以基点为单位的PnL值。此外,我们考虑的是每日数据,我们每天有两组回报(开盘到收盘和收盘到开盘),这促使我们考虑每日PnL:
wPnL'(i) = wPnL(2i) + wPnL(2i+1), i=1, …, 5
我们学习的分布越对称,wPnL就越接近于零。我们使用上面介绍的加权策略来计算年化夏普比率,我们将其用作我们的主要性能指标:
SRw = sqrt(252) * wPnL / sqrt((1/n) * Σ (wPnL(i) – wPnL)^2), i=1到n
当处理仅提供点估计的模型时,我们无法使用加权策略,因此我们改为考虑:
PnL'(i) = 10000 * (sign(rA(2i)) * rA(2i) + sign(rA(2i+1)) * rA(2i+1)), i=1到n
以及相应的年化夏普比率:
SRm = sqrt(252) * PnLm / sqrt((1/n) * Σ (PnL(i) – PnLm)^2), i=1到n
其中PnLm是PnL'(i)的平均值。
5. Fin-GAN损失函数
我们工作的主要贡献在于为生成器引入了一种新的经济学驱动的损失函数,将GANs置于监督学习环境中。这种方法使我们能够超越传统上用于点预测的方法,转向概率预测,提供不确定性估计。此外,我们根据预测的符号来评估性能,这意味着我们对分类感兴趣,我们的损失函数更适合。
5.1 动机
GANs的主要目的是创建模仿真实数据的合成样本。然而,一个重要的问题是,我们希望通过模拟来重现真实数据的哪些属性。在我们的案例中,它是预测的符号。我们更感兴趣的是正确分类收益/超额收益,特别是当价格变动的幅度很大时,而不是产生接近实际值的预测。动机是,人们可能会产生一个接近时间序列实际值的预测,但符号相反。在金融时间序列预测中,在最重要的时候正确估计符号通常比预测接近实际值更重要。我们的目标是为生成器提供更多信息,使其更好地复制数据的符号,这是任务的关键组成部分。使用新的损失函数项的主要原因和好处可以总结如下:将生成的条件分布转移到正确的方向,使GANs更适合分类任务,提供有效的正则化,帮助生成器学习更多,特别是在梯度较弱的情况下,帮助避免模式崩溃;通过使生成器损失表面更加复杂,生成器可能会收敛到尖锐的局部最小值。
我们已经看到了几个不同损失函数的例子,以及它们带来的好处。最值得注意的是,W-GAN-GP(Gulrajani等人 2017)在判别器损失中添加了一个额外项作为强制Lipschitz约束的一种方式。在生成器中添加损失项不太常见,但在Bhatia等人(2021)最近的工作中用于生成极端样本,以及在VOLGAN(Vuletic和Cont 2023)中用于模拟无套利隐含波动率表面。其他定制的损失函数在金融领域也被证明是有用的,例如Tail-GAN(Cont等人 2022),它侧重于估计投资组合尾部风险。
5.2 新的损失函数
假设我们的GAN旨在预测Xi,其中i = 1, …, nbatch。对于每个xi,给定一个噪声样本z和由时间序列x的前L个值组成的条件,生成器的输出是:
xi = G(z, x ;- )
让x = (x(1), …, x(nbatch))和x = (x(1), …, x(nbatch))是x的预测。我们定义了三个损失函数项,即PnL、MSE和基于夏普比率的损失函数项,我们使用它们来训练生成器。
5.2.1 PnL项
包含生成器训练目标(最大化)的损失函数项的第一个也是最明显的选择是PnL。然而,符号函数是不可微的,使得无法执行反向传播。为了缓解这个问题,我们提出了一个对pPnL的平滑近似,我们将其表示为PnL*,定义为:
PnL*(x, x) = (1/nbatch) * Σ PnL*(xi, xi), i=1到nbatch
其中PnL*是特定预测的PnL的平滑近似:
PnL*(xi, xi) = tanh(ktanh * tanh(xi – xi))
tanh(x)定义为:
tanh(x) = (exp(x) – exp(-x)) / (exp(x) + exp(-x))
超参数ktanh控制我们近似的准确性。由于超额收益的值通常很小,ktanh的值应该足够大以获得良好的近似,但同时又足够小以获得生成器可以学习的强梯度。请注意,在PnL项的表达式中,我们考虑的是每次交易的PnL。这不是每天平均的PnL,因为训练数据集在每个纪元开始时被洗牌。我们使用ktanh = 100。
5.2.2 MSE项
尽管我们主要对预测的符号感兴趣,但我们也希望x接近Xi。为了强制执行这一点,我们在训练目标中添加了一个MSE项:
MSE(x, x) = (1/nbatch) * Σ (xi – xi)^2, i=1到nbatch
5.2.3 夏普比率项
由于我们的主要性能指标是年化夏普比率,我们引入了基于SR的损失函数项供生成器最大化。然而,由于计算成本过高,我们没有在训练期间实施加权策略,而是使用点估计,给定每个条件窗口一个噪声样本。我们没有将交易配对成两个,因为训练集中的连续数据点不一定以原始顺序出现,因为洗牌。随机选择小批量,或者等效地在每个纪元开始时洗牌训练数据集是非常重要的,以便随机梯度下降能够收敛。因此,我们定义生成器在训练期间要最大化的夏普比率项,表示为SR*:
SR*(x, x) = (1/nbatch) * Σ PnL*(xi, xi) / sqrt((1/nbatch) * Σ (PnL*(xi, xi) – (1/nbatch) * Σ PnL*(xi, xi))^2), i=1到nbatch
5.2.4 标准差(PnL系列)项
最大化夏普比率意味着最大化PnL并最小化PnLs的标准差。因此,自然会考虑一个标准差项,我们将其定义为:
STD(x, x) = sqrt((1/nbatch) * Σ (PnL*(xi, xi) – (1/nbatch) * Σ PnL*(xi, xi))^2), i=1到nbatch
由于上述定义的损失项指的是近似PnLs的标准差,因此只有在包含PnL项的情况下才应将其包含在训练目标中,这是由于层次原则。SR项和与STD项结合的PnL传达了相同的信息,因此不应同时使用这三个。然而,尽管最大化SR的目标与同时最大化PnL*和最小化STD相同,但梯度范数是不同的,这可能导致训练期间的行为不同。
5.2.5 生成器的经济学驱动损失函数
最后,我们将上述所有损失函数项(方程(16)、(19)和(20))整合在一起,并得出生成器的Fin-GAN损失:
LG(x, x) = J(G)(x, x) – αPnL*(x, x) + βMSE(x, x) – γSR*(x, x) + δSTD(x, x)
其中J(G)是标准GAN损失之一(零和、交叉熵或Wasserstein),超参数α、β、γ是非负的。判别器的损失仍然是J(D)。在先前的数值实验中,Wasserstein损失遭受了爆炸,因此我们选择使用二元交叉熵损失作为J(G)。我们的目标是最小化经典的生成器损失函数(J(G)),最大化基于PnL的损失函数项,最小化MSE项,并最大化基于SR的损失函数项,或联合最大化PnL并最小化STD项。我们研究的损失函数组合是PnL、PnL&STD、PnL*&MSE、PnL&SR、PnL&MSE&STD、PnL&MSE&SR、SR、SR*&MSE、MSE、仅BCE。标准差项指的是PnL项,因此由于层次原则,只有在包含PnL项的情况下才包括它。当涉及到Fin-GAN时,需要包括一个经济学驱动的损失项,因此对于Fin-GAN,我们只考虑以下选项:PnL、PnL&STD、PnL*&MSE、PnL*&SR、PnL&MSE&STD、PnL*&MSE&SR、SR、SR*&MSE。换句话说,我们对α、β、γ、δ施加以下条件:
max(α, γ, δ) > 0(至少包括一个除MSE之外的附加项)。
如果β > 0,则max(α, γ, δ) > 0(如果包括MSE项,则包括另一个项)。
如果δ > 0,则δ > 0(仅当包括PnL*项时才包括STD项)。
min(γ, δ) = 0(SR*和STD项永远不会同时包括)。
我们将使用ForGAN架构和由上述方程(22)以及规则定义的损失函数的GANs称为Fin-GANs。
5.2.6 梯度范数匹配
为了避免超参数调整以找到α、β、γ、δ,我们使用类似于Vuletic和Cont(2023)的方法,将所有项视为同等重要。也就是说,我们首先仅使用J(G)训练网络,但我们计算方程(22)中所有项相对于生成器θg参数的梯度范数。然后,我们将α、β、γ、δ设置为观察到的比率的均值(或如果它们未包含在目标中,则为零)。然后,我们使用计算出的α、β、γ、δ值使用可能的组合训练网络。然后,通过在验证集上评估夏普比率来确定新项的最终组合。进一步的训练细节在第6节中解释,Fin-GAN算法在算法1中给出。
5.3 Fin-GAN损失函数的优势和挑战
新的损失函数项确实改变了生成的分布,有助于避免模式崩溃,并提高了夏普比率性能,我们在广泛的数值实验中证明了这一点。包含新的损失函数项引入了四个新的超参数需要调整,使得优化成为一个更具挑战性的问题。然而,梯度范数匹配方法缓解了这个问题。

此外,损失表面变得更加复杂,增加了收敛挑战。在最初的数值实验中,当探索更广泛的超参数α、β、γ、δ时,MSE和夏普比率项似乎鼓励生成器产生非常狭窄的分布。尚不清楚为什么具有高γ系数的夏普比率项会导致模式崩溃,因为它鼓励PnLs具有低标准差,而不是生成的样本。然而,包含基于PnL的项有助于缓解模式崩溃问题,这与收敛到尖锐局部最小值有关(Durall等人 2021)。PnL项帮助生成器逃离损失表面的这些区域。
当使用梯度范数匹配来调整超参数α、β、γ、δ时,无论网络权重的初始化如何,Fin-GAN中都没有模式崩溃。然而,我们注意到,使用Xavier初始化(Glorot和Bengio 2010)而不是He初始化(He等人 2015)有助于减少ForGAN中模式崩溃的迭代次数。使用He初始化,这种情况在67%的案例中发生。利用正常的Xavier初始化解决了这个问题。
经典的生成器损失项,即从判别器接收到的反馈,允许学习条件概率分布,而不仅仅是点预测。
剩余的损失函数项促进了符号一致性(由PnL和夏普比率项强制执行),同时又试图保持接近实际值(MSE)。
如果超参数α、β、γ、δ太大,判别器的反馈就变得微不足道,我们转向标准的监督学习设置,使用仅生成器模型。另一方面,如果α、β、γ、δ太小,我们就没有向生成器提供任何额外的信息,因此仍然处于经典的GAN设置中。通过新的损失函数项传达的关于数据的额外信息在来自判别器/批评者反馈的弱梯度的情况下尤其有价值,因为生成器在这种情况下仍然可以取得进展。这最终导致了对数据在价格方向性运动方面的更好分类,即正确分类未来时间序列值的符号,以及对运动方向的 uncertainty estimates。梯度范数匹配程序确保所有损失项都被视为同等重要,并且相应的超参数既不太大,也不太小。
6. 数据描述和实施考虑
在本节中,我们概述了我们使用的数据集的主要特征,并进一步描述了ForGAN架构。接下来,我们讨论训练设置,包括超参数选择以及优化。最后,我们展示了Fin-GAN模型的一般行为,这在数值实验中反复出现。
6.1 数据描述
我们考虑从Wharton Research Data Services的CRSP中提取的每日股票ETF超额收益和每日原始ETF收益。感兴趣的时间范围是2000年1月-2021年12月。所有时间序列都有相同的训练-验证-测试分割,即80-10-10。也就是说,训练期为2000年1月3日-2017年8月9日,验证期为2017年8月10日-2019年10月22日,测试期为2019年10月23日-2021年12月31日。这三个时间段从经济角度来看非常不同,重要的是要注意测试数据包括Covid-19大流行的开始,使得问题更具挑战性。我们依次考虑开盘到收盘和收盘到开盘的回报,并将每一个称为一个时间单位。换句话说,一个输入时间序列交替出现日间开盘到收盘和隔夜收盘到开盘的回报。滑动窗口是一个时间单位,条件窗口是十个时间单位(对应于五天的回报,即一个完整的交易周),预测窗口是一个时间单位。
价格通过除以提供的累积调整因子(cfacpr)进行调整,回报被限制在15%,以减轻潜在异常值的影响。为了预处理数据,我们首先创建一个由连续收盘到开盘和开盘到收盘回报组成的时间序列,然后按时间顺序将数据分成三个不重叠的较短时间序列(训练-验证-测试),我们适当地进一步处理这三个结果的时间序列。在这个在这个阶段,我们为三个数据集中的每一个创建了一个矩阵;每个这样的矩阵包含11列,前10列对应于条件窗口(x1, …, x10),最后一列是目标(x11)。一个时间单位的滑动窗口意味着列j中的第k个值是列j-1中的第k+1个值。
我们考虑九个行业中22只不同股票的ETF超额回报,以及九个行业ETF的原始回报。所有股票都是当前标准普尔500指数的成员。股票代码及其行业成员资格如表1所示。
6.2 ForGAN架构
对于单只股票/ETF的数值实验,使用了经典的ForGAN架构,利用LSTM单元,如图3所示。由于使用的数据集规模较小,相应的层维度和噪声维度都设置为8。生成器使用ReLU作为激活函数,而判别器使用sigmoid。
6.3 训练
为了避免进一步的超参数调整,整个过程中使用的优化器是RMSProp(Hinton等人,2012),并且权重使用正常的Xavier初始化(Glorot和Bengio,2010)。判别器/批评者和生成器使用交替方向方法进行训练,每个生成器更新进行一次判别器更新。我们使用参考批量归一化,从训练数据中选取前100个样本作为参考批量,以避免预测性。小批量大小也设置为100。两个网络的学习率都设置为0.0001。我们从开始训练25个周期,仅使用BCE损失来实现梯度范数匹配,并找到α、β、γ、δ系数。然后,我们通过每种合适的损失组合训练100个周期,从生成器和判别器中分支出来。在训练阶段结束时,我们在验证集上计算夏普比率,并选择损失函数组合以及最大化它的优化生成器。由于验证和测试的经济周期不同,网络在测试集上表现良好并不一定被选中。然而,这种方法允许我们在危机期间确保良好的表现。代码在PyTorch中实现。Fin-GAN算法在算法1中总结。
注释6.1:人们可以通过在验证集上评估夏普比率,并选择最大化它的超参数/架构,来探索更广泛范围的超参数α、β、γ、δ,学习率lrg、lra,隐藏维度RG、RD,噪声维度N,以及完全不同的架构。
6.4 梯度稳定性
在加入额外的损失函数项之前,我们首先调查训练期间梯度范数的行为,以检查梯度消失和爆炸。我们训练ForGAN,使用RMSProp(Hinton等人,2012)对BCE损失进行更新,训练25个周期,这是用于梯度范数匹配的时间段。在图4中,我们展示了每个项(方程(22))的样本梯度范数。本例中使用的数据是PFE的每日超额股票回报时间序列。我们观察到,没有消失或爆炸现象,梯度范数在相似的尺度上。对于我们实验中使用的其他股票代码也是如此。
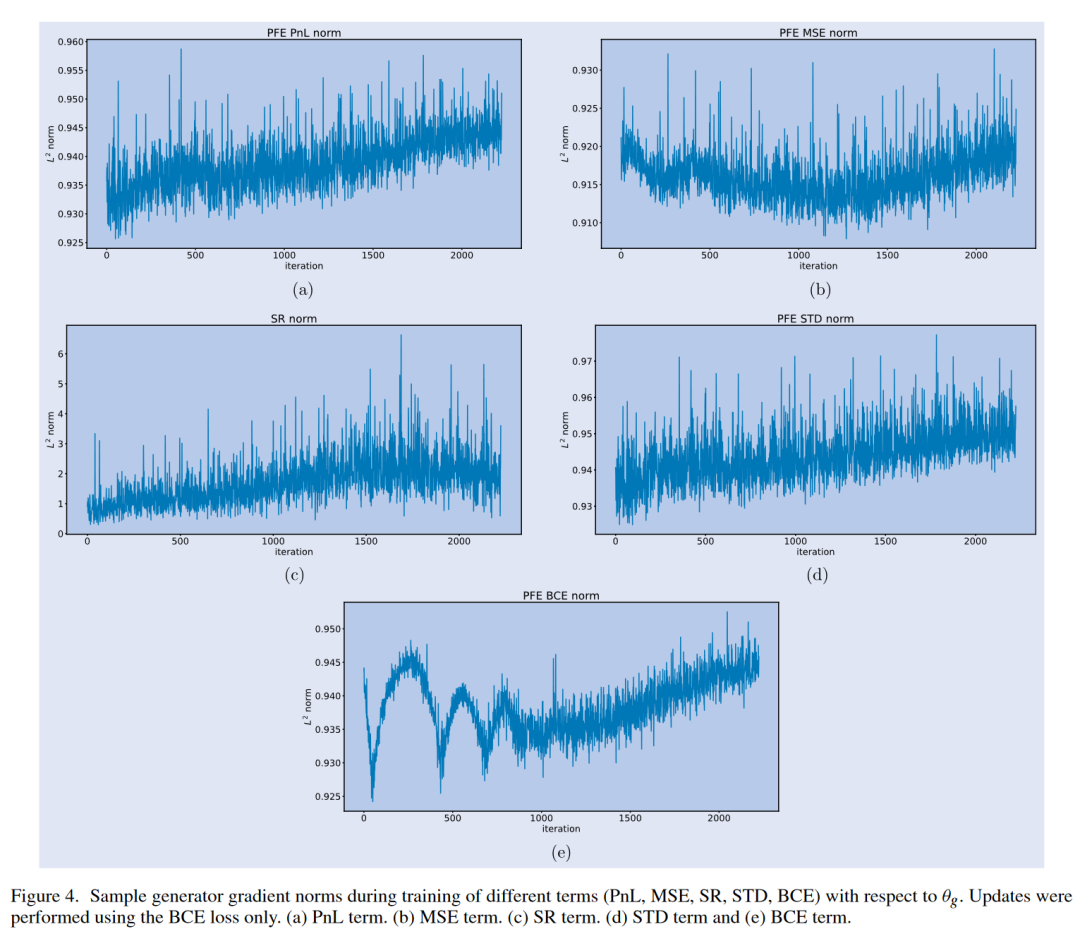
6.5 模式崩溃
由于我们考虑的是时间序列数据,我们识别出两种不同类型的模式崩溃,分布模式崩溃和均值模式崩溃,每种都可以是完全的或部分的。分布模式崩溃指的是给定条件的生成分布的崩溃,均值模式崩溃指的是所有条件下生成分布的均值的分布的崩溃。
当完全均值和完全分布模式崩溃同时发生时,这是一个主要问题,因为这导致只有一个点估计。为了简化我们设置中的模式崩溃概念,我们认为如果特定条件(时间点)的样本外生成场景,即生成的均值的时序,标准差低于阈值ε,我们将其设置为0.0002,则模式崩溃发生。使用Xavier初始化网络权重(Glorot和Bengio,2010)有助于缓解ForGAN的模式崩溃。Fin-GAN损失函数的额外项已被证明具有有效的正则化,因为在任何实验中都没有模式崩溃,无论网络是按照Xavier还是He初始化(He等人,2015)进行初始化的。重要的是要注意,当使用He初始化时,ForGAN在67%的模拟中遭受了某种类型的模式崩溃。此外,在最初的数值实验(考虑STD项之前)中,使用了更广泛的超参数范围而不是执行梯度匹配,我们注意到,具有高β和γ的MSE和SR项可能会导致模式崩溃。然而,包含PnL项将解决这个问题。MSE项旁边的高超参数导致模式崩溃的后果并不令人惊讶,因为MSE项鼓励生成的值接近目标。夏普比率项虽然促进了小标准差,但并没有促进预测的狭窄分布,而是PnLs。
6.6 生成分布
图5显示了使用不同的Fin-GAN损失函数项组合进行训练时生成的分布样本。所有显示的分布都是使用相同的训练数据(PFE的超额回报)和测试集中的相同条件(它们有相同的目标)生成的。在整个数值实验中,仅使用BCE损失进行训练会产生更对称的分布,而包含的Fin-GAN损失函数项将有助于转移预测分布。我们还调查了生成的均值,并将它们与目标在图6中的真实分布进行了比较。我们注意到,在这个特定的例子中,PnL和STD组合的行为类似于单独的SR项。这并不令人惊讶,因为两者传达了相同的信息,尽管它们的梯度不同。这两个选项在这个例子中都有最大的分布转移效果。我们注意到,除了带有STD的PnL和SR损失项外,所有生成的均值都类似于真实的目标分布。此外,包含MSE项促使均值的分布更接近于真实回报的分布。
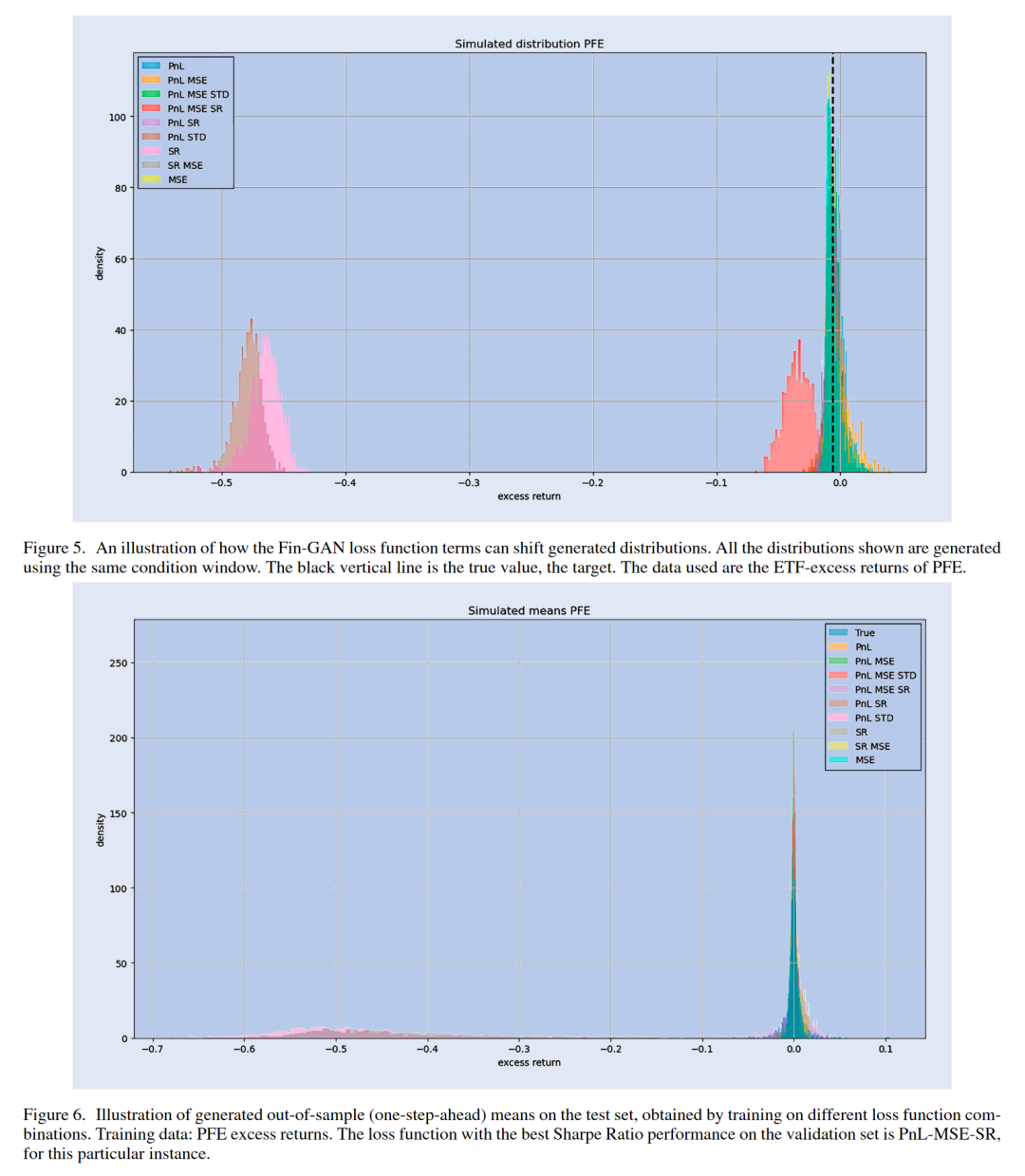
图5使我们能够说明GANs由于不确定性估计而能够采用的加权策略。在这个特定的预测中,SR以及PnL和STD将导致做多ETF和做空股票,权重为1,而PnL、MSE和SR组合将有一个类似但权重略低的交易,其他组合将由于对预测符号的不确定性而导致非常小的交易。尽管我们在图5和图6中只考虑了Fin-GAN损失项,但重要的是要注意,BCE损失与添加了MSE项的BCE损失之间的平均相关性为99.7%。
我们观察到,在损失项的组合上进行训练是有益的,因为它们能够产生生成的分布的转移并避免模式崩溃。联合利用Fin-GAN损失函数项的好处得到了夏普比率性能的支撑,我们将在第8节中进行分析。
重要的是要强调,在验证阶段选择的作为最优的配置将因实例而异。图5和图6是使用不同目标进行训练所获得的分布结果的示例。
7. 基线算法
除了标准的ForGAN(使用BCE损失训练的ForGAN架构的GAN),我们将我们的Fin-GAN模型与更标准的监督学习方法进行时间序列预测:ARIMA和LSTM。为了完整性,并为了证明手头的任务并非微不足道,我们进一步包括了长期策略的PnL和夏普比率值,其中每个观测的预测符号为+1。所有比较都有与Fin-GAN实验中使用的相同的训练-验证-测试分割。
7.1 ARIMA
我们首先回顾自回归综合移动平均(ARIMA),这是一个非常经典的时间序列模型(Tsay,2005)。ARIMA(p,d,q)中的参数p、d、q分别对应于自回归、差分和移动平均部分。差分系数d表示我们需要对初始时间序列进行差分的次数,以便达到一个没有单位根的时间序列X。为了确定d,我们执行增广Dickey-Fuller(ADF)检验。在我们的案例中,所有时间序列的p值都小于10^-6,表明平稳性。这并不令人惊讶,因为我们处理的是回报和超额回报,它们已经是差分对数价格时间序列。因此,在我们的设置中,我们始终设置d = 0,因此使用ARMA(p,q)模型,其形式为:
X(t) = φ1X(t-1) + … + φpX(t-p) + θ1ε(t-1) + … + θqε(t-q) + ε(t)
其中ε1, …, εt是白噪声项,θi是移动平均参数,φj是自回归参数。为了确定最合适的p和q,我们绘制了自相关(ACF)和偏自相关(PACF),它们表明p, q ∈ {0, 1, 2}。我们拟合ARMA(p,q)与(p,q) ∈ {(1,0), (1,1), (2,0), (2,1), (2,2)},并选择具有最低Akaike信息准则(AIC)的模型。
7.2 LSTM
长短期记忆网络,或LSTM(Hochreiter和Schmidhuber,1997),属于循环神经网络类。它们有助于解决梯度消失/爆炸问题,并且特别适合处理时间序列。在每个时间t,有输入x(t),前一个细胞状态c(t-1)和前一个隐藏状态h(t-1)(前一个LSTM输出)。然后,这些由遗忘门、输入门和输出门处理,以便创建新的细胞状态c(t)和新的隐藏状态,即输出h(t)。
对于训练,我们使用与Fin-GAN相同的设置。也就是说,我们使用RMSProp作为选择的优化器,训练125个周期。我们现在处于回归设置中,因此LSTM被训练以最小化MSE损失。速率再次为0.0001。
7.2.1 LSTM-Fin
我们还在适当的(基线)MSE损失、PnL、SR和STD损失项的组合上训练LSTM,以便与Fin-GAN进行更好的比较。我们使用与Fin-GAN设置中相同的方法,也执行梯度范数匹配以确定与新包含的损失项相对应的超参数值。也就是说,我们考虑损失函数(24),包括和排除PnL、SR和STD损失项,通过与Fin-GAN相同的规则,确定超参数α、γ、δ的值,使用相同的梯度范数匹配程序,并通过在验证集上评估夏普比率来确定最终用于测试的损失函数组合。
LFin(x, x) = MSE(x, x) – αPnL*(x, x) – γSR*(x, x) + δSTD(x, x).
7.3 长期策略
我们还评论了做多股票和做空ETF(对于股票数据)以及仅做多ETF(对于ETF数据)结果,这对应于始终预测每个观测的符号为+1。
8. 数值实验
在本节中,我们首先考虑单只股票设置。也就是说,我们在特定股票/ETF的ETF超额回报/原始回报上训练Fin-GAN和基线。然后,我们以Sirignano和Cont(2019)的精神,探索普遍性的概念,在三组不同的股票上。我们将数据池化在单只股票设置中使用的股票代码上,并训练Fin-GAN,就像数据来自同一来源一样。我们在属于同一行业(消费品)的股票上重复这种方法,包括和不包括在训练阶段使用的XLP原始回报。在普遍设置中,我们进一步调查了Fin-GAN在训练阶段模型未见过的股票上的表现。
8.1 单只股票和ETF设置
我们首先检查所考虑模型的汇总性能:Fin-GAN、ForGAN(通过BCE损失训练)、LSTM、LSTM-Fin、ARIMA和长期策略。感兴趣的统计数据是年化夏普比率、平均每日PnL、MAE和RMSE。所有统计数据通过计算在数值实验中使用的31个数据集(22只股票和9只ETF)上的平均值和中位数来汇总。此外,我们通过首先将宇宙中所有股票代码的每日PnL相加,然后计算结果每日PnL时间序列的夏普比率来报告投资组合夏普比率。这些汇总统计数据如表2所示。
我们注意到,Fin-GAN实现了最高的平均、中位数和投资组合夏普比率,其次是LSTM。Fin-GAN实现的中位数夏普比率接近LSTM的两倍。此外,我们注意到,尽管使用Fin-GAN方法时夏普比率最高,但LSTM实现了最高的平均PnL,ARIMA实现了最高的中位数PnL。这完全展示了与Fin-GAN相比,其他模型生成的PnL的方差显著减少和更高的一致性。这也是由于与其他策略相比,交易规模较小,这是由于能够利用不确定性估计并实施加权策略。我们强调新的损失函数项对性能的积极影响,这通过Fin-GAN实现的平均、中位数和投资组合夏普比率显著高于仅使用BCE损失训练的ForGAN来证明。
股票和ETF上模型性能指标的汇总
指标
Fin-GAN
ForGAN
LSTM
LSTM-Fin
ARIMA
长期策略
平均夏普比率
0.540
0.033
0.467
0.341
0.206
0.182
中位数夏普比率
0.413
-0.092
0.214
0.170
0.204
0.194
投资组合夏普比率
2.107
0.172
2.087
0.942
0.612
0.618
平均PnL
2.978
0.254
4.123
2.361
2.059
2.350
中位数PnL
1.890
-0.673
1.959
1.735
2.245
1.975
平均MAE
0.044
0.052
0.007
0.007
0.007
中位数MAE
0.008
0.009
0.007
0.007
0.007
平均RMSE
0.049
0.056
0.012
0.012
0.012
中位数RMSE
0.012
0.014
0.011
0.011
0.011
我们进一步注意到,ARIMA在RMSE方面表现最佳,并实现了最佳的MAE平均值,而LSTM实现了最低的中位数MAE。我们还注意到,非GAN模型在其MAE和RMSE汇总统计数据上处于相同的尺度,而GAN模型的平均MAE和RMSE显著更高。然而,中位数与其他模型处于相似的尺度,并且当从ForGAN转移到Fin-GAN时,误差减少。在图9和图8中分别调查RMSE和MAE时,我们发现Fin-GAN实现如此高的平均MAE和RMSE的主要原因是IBM的表现。然而,在这种情况下,Fin-GAN实现了比其他模型更高的夏普比率(图10)和PnL(图11)。类似地,尽管ARIMA实现了接近实际值的数值,但当基础资产的波动较大时,它在真实线的另一侧实现,导致较低的PnL和较低的夏普比率。我们注意到,非深度学习方法(ARIMA和长期策略)实现的汇总统计数据相似,并且它们比以传统方式训练的ForGAN表现更好。长期策略列表明,考虑到在Covid-19大流行期间科技行业股票持续增加的情况下,只有XLK的夏普比率超过1,这并非出乎意料。此外,在GAN设置中,经济驱动的损失函数项的积极影响在LSTM的情况下并不明显。
上述实验表明,Fin-GAN方法在平均情况下优于ForGAN、LSTM、ARIMA和长期策略基线。我们现在进一步调查夏普比率在单个股票代码级别的行为。模型和股票代码的年化夏普比率性能如图10所示。我们观察到,Fin-GAN模型优于所有其他基线,能够实现非常有竞争力的夏普比率,特别是考虑到我们处理的是单工具投资组合。Fin-GAN实现的夏普比率比LSTM更稳定,唯一夏普比率低于-1的股票代码是XLY(消费品)。这并不令人惊讶,因为这个行业ETF在Covid-19大流行初期出现了崩溃,并且在用于验证的时间段内持续增长。在LSTM实现夏普比率超过1或2的数据集上,Fin-GAN也是如此,实现类似的夏普比率,或者在CL的情况下更高。总的来说,我们观察到使用Fin-GAN与使用其他方法相比,在夏普比率性能方面有明显的优势。Fin-GAN按股票代码分解的累积PnL性能如图12所示。我们注意到,Covid大流行对不同股票的影响不同,2020年3月至6月的表现是实现PnL波动的主要原因。
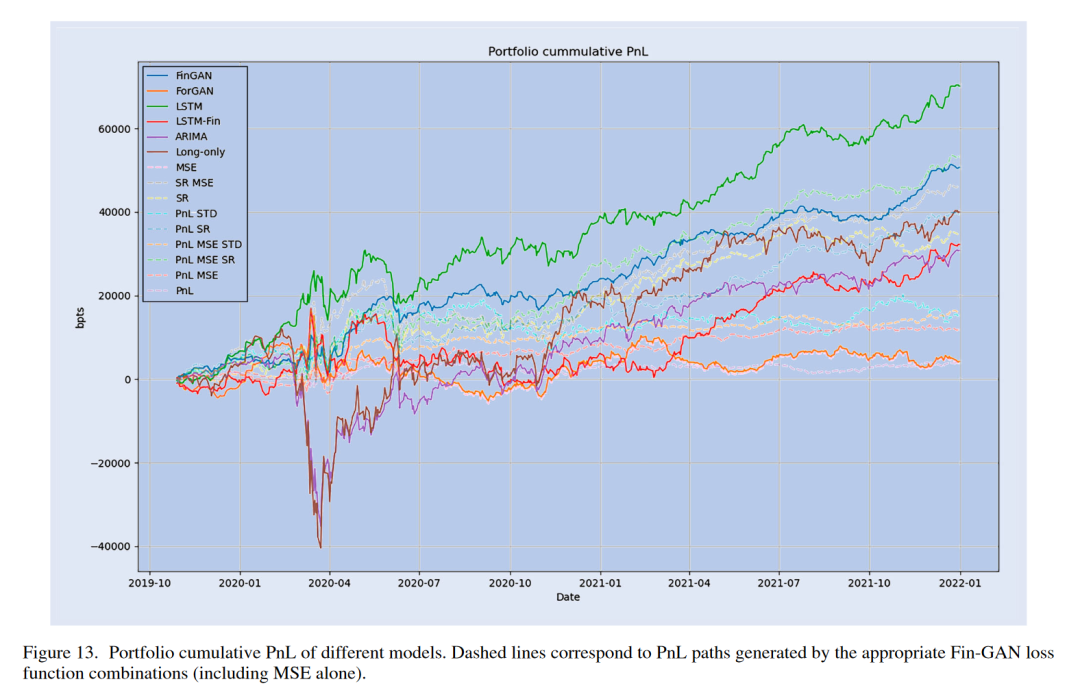
就整体表现而言,Fin-GAN和LSTM优于所有其他考虑的方法。相应投资组合的累积PnL图如图13所示。深度学习模型从Covid-19冲击中恢复得比ARIMA和长期策略快得多,我们注意到生成的PnL中的大部分波动源于大流行。在图13中,我们显示了通过不同的Fin-GAN损失组合实现的累积PnL,包括仅使用MSE和BCE项的组合,其平均与ForGAN的相关性为99.7%。很明显,通过使用验证,而不是从一开始就对每个数据集使用相同的损失组合,整体性能得到了提高。LSTM的投资组合PnL更高,但路径波动更大,特别是在2020年3月至2020年6月期间,导致夏普比率低于Fin-GAN。
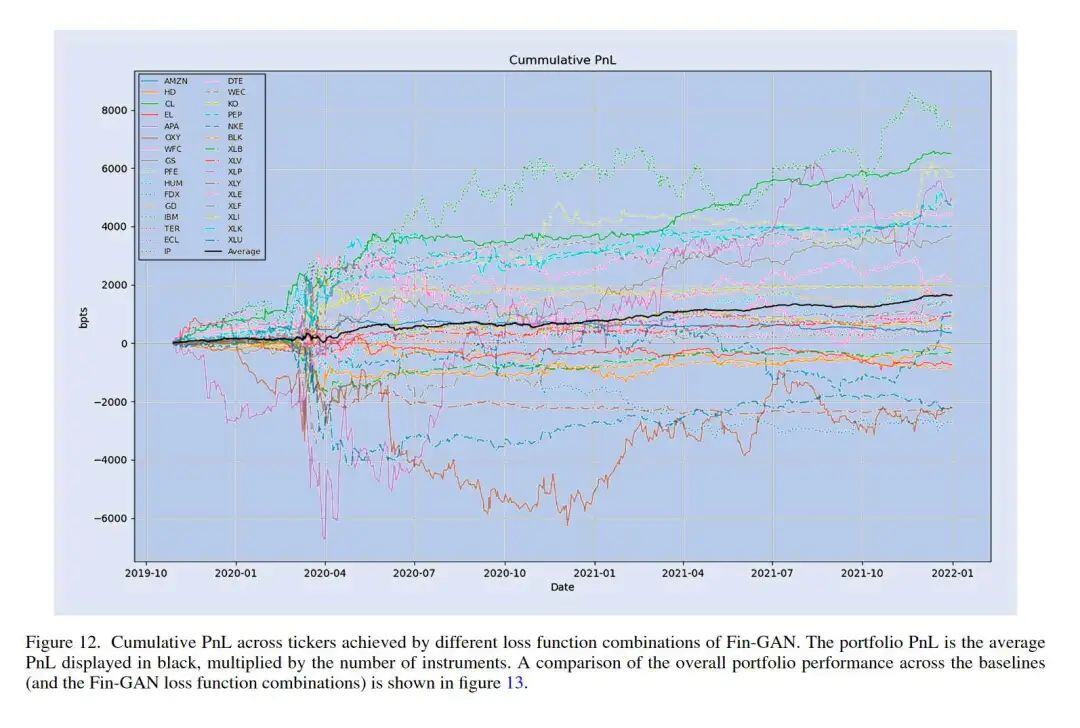
关于图11中显示的平均每日PnL表现,我们注意到ARIMA和长期策略倾向于产生相同量级的平均每日PnL,而LSTM平均实现最高的PnL。然而,LSTM实现的PnL在不同股票代码之间波动很大。GAN方法实现的平均每日PnL的标准差(Fin-GAN为4.85,ForGAN为4.00)远低于LSTM(7.48)、LSTM-Fin(7.53)、ARIMA(6.26)和长期策略(5.97),展示了能够利用不确定性估计来开发具有动态规模的加权策略的好处。
接下来,我们评论Fin-GAN性能中选择的损失函数组合的分解。如图5所示,利用引入的损失函数项一起使用是有益的,既可以转移分布目的,实现对数据分布的更好近似,也可以缓解模式崩溃。我们注意到,包含MSE项是非常突出的,有趣的是,PnL和夏普比率组合从未被选中。最常见的选择是带有MSE的夏普比率,占29%的案例。
我们比较了不同Fin-GAN损失函数组合在测试集上的夏普比率性能,并在图14中显示了结果。由于验证集和测试集之间的差异,有时在验证阶段会选择次优的损失函数组合。然而,我们注意到,为了选择包含在训练目标中的哪些项而进行的验证提高了模型的夏普比率性能。
如前所述,SR和PnL和STD(PnL&STD)项的组合传达了相同的信息,但具有不同的梯度,并可能导致不同的预测。因此,我们调查了通过不同损失项组合获得的样本外PnL(测试集)的平均Pearson相关性。包含MSE项的组合与相应的包含MSE项的组合之间存在高度相关性,这并不令人惊讶。
一个重要的发现是,MSE项与BCE损失之间的平均相关性为99.7%,这意味着通过二元交叉熵损失训练的ForGAN已经旨在产生接近实际值的输出。这种行为可以通过数据和手头任务的结构来简单解释:由于每个条件都有一个真实的目标,即经验条件分布是点质量Pdata(Xt+1|x)=δ(x+1)如果L足够大。因此,接近目标的预测值会从判别器获得高分,鼓励在经典GAN设置中模式崩溃。这进一步支持了使用ForGAN作为基线的决定,其适合概率预测,以及将其定制为金融设置的需要。
8.2 普遍性
我们以Sirignano和Cont(2019)的精神测试我们方法的普遍性。然而,由于计算成本,我们只能对一小部分股票和ETF进行数值实验,即之前使用的31只。我们不尝试从跨资产相关性中学习,而是单独考虑每个时间序列。也就是说,我们采用单资产模型,我们将所有31只股票代码的数据组合(池化)。我们测试模型在所有用于训练和四只额外未见过的股票上的表现。训练、验证和测试集的时间段以及Fin-GAN方法保持不变。普遍性模型的夏普比率性能的汇总如图16中的热图所示。单只股票列指的是单只股票模型仅在特定股票代码上训练时实现的最高夏普比率。股票代码CCL、EBAY、TROW和CERN在训练阶段未被模型看到。我们注意到,即使在未见过的股票上也能实现有竞争力的夏普比率。例如,在THROW数据上实现的夏普比率通常超过1,尽管普遍模型从未见过EBAY数据。图16表明,一些包含在普遍模型训练中的股票从与其他股票的池化训练中受益,但不是全部。这在XLY中最为明显,其中实现的夏普比率要么显著不那么负,要么甚至是正的。整体表现没有增加可能是由于我们的股票宇宙较小,并且没有强烈的相关性。人们会期望,当股票属于同一行业时,跨资产相互作用提供的信息更多。
我们使用消费品(XLP)行业的股票重复相同的分析。我们进行了一组包含XLP数据(原始回报)在训练数据中的数值实验,以及另一组不包含XLP数据的实验。不包含XLP数据的夏普比率性能如图17中的热图所示,而包含XLP数据的相同性能如图18所示。模型未见过的股票是SYY和TSN。与之前讨论的普遍模型类似,在未见过的数据上实现的夏普比率可以非常有竞争力,例如TSN。当包含XLP数据时,验证选择的模型是PnL & SR,在测试集上实现了良好的整体投资组合SR 1.43。尽管并非所有股票都有正的夏普比率,但这种组合实现了良好甚至非常好的SR,包括在未见过的TSN数据上1.55的夏普比率。一个重要的观察是,在这种情况下,XLP数据的夏普比率是1.11,而单只股票设置中是0.393。其他ETF也可能从与其成分股一起训练中受益。当从用于训练的股票池中移除XLP数据时,选择的模型是SR。投资组合夏普比率降至1.18,但仍然具有竞争力。通过比较图17和图18中的热图,我们得出结论,在Fin-GAN的训练过程中包含ETF数据是有明显好处的,但对于ForGAN则不然。与XLP数据一起训练导致比没有它的模型更稳定的夏普比率。
9. 结论和未来展望
我们已经展示了GANs可以成功应用于金融数据环境中的概率时间序列预测,其中预测的方向性(符号)在大型价格跳跃之前尤为重要。我们引入了一种新的经济学驱动的生成器损失函数,它包括适当加权的损益(PnL)、PnL的标准差、MSE和基于夏普比率的损失函数项,使GANs更适合分类任务,并将其置于监督学习环境中。
在一套全面的数值实验中,我们将我们的方法与标准GAN模型、LSTM、ARIMA和长期策略进行了比较,并证明了我们的模型在实现的夏普比率方面具有优越的性能。
此外,我们在三种设置中考虑了普遍模型:汇集来自不同行业和行业ETF的股票数据,考虑一个包含行业ETF在训练数据中的行业,以及在训练阶段排除行业ETF。即使股票宇宙很小,我们注意到即使在未见过的股票上也能实现良好的性能。此外,当行业ETF包含在训练数据中时,单一行业设置中的性能有所提高。
本文的Fin-GAN方法被证明能够显著提高夏普比率性能,转移生成的分布,以及帮助缓解模式崩溃问题,后者是许多基于GAN的方法中的标准挑战。
代码下载见星球,欢迎加入QuantML星球
本文介绍了一种基于生成对抗网络(GANs)的新方法——Fin-GAN,用于金融时间序列的预测和分类。该方法旨在提供概率预测,并超越传统点估计方法。Fin-GAN通过引入一种新的经济学驱动的损失函数,将GANs置于监督学习环境中,从而在金融应用中更适合分类任务。
1. 引言
时间序列预测一直是工业界和学术界关注的热点话题。在金融和经济领域,时间序列可以代表金融工具的价格、通货膨胀率以及其他关键宏观经济指标。交易策略基于对金融工具价格未来走势的预测,因此,时间序列预测和分类在金融环境中至关重要。传统方法主要依赖于点估计,无法提供概率预测或对目标变量未来分布形式的强假设,导致无法捕捉不确定性。
本文采用ForGAN架构,将GANs与循环神经网络(RNNs)结合,以生成概率预测。进一步引入了一种新的经济学驱动的损失函数,以提高夏普比率性能。该损失函数在生成器损失函数中加入了额外项,使其更适合金融应用中的分类任务。
2. 相关工作
时间序列建模一直是工业界和学术界的研究热点。近年来,机器学习的兴起导致其在时间序列建模中的应用越来越多。然而,将机器学习应用于金融领域的时间序列建模已有长期研究。
深度学习在金融领域的应用文献丰富。Guresen等人使用神经网络进行股票市场预测,而Sirignano和Cont利用LSTM论证了资产价格特征的普遍性。深度学习应用的一个特别感兴趣的领域是限价订单簿(LOB)建模。Sirignano引入了空间神经网络,旨在对限价订单簿的未来状态进行联合分布建模。Tsantekidis等人利用卷积神经网络进行高频、大规模数据中的股票价格走势预测,而Tsantekidis等人则使用循环神经网络方法解决相同问题。TransLOB Wallbridge和DeepLOB Zhang等人引入了更复杂的架构,具有高预测精度。Zhang和Zohren则超越了短期LOB预测,专注于多时间范围设置。Lucchese等人引入了deepVOL,旨在使用LOB的成交量表示来预测中间价格。Deep Hedging也在工业界和学术界引发了深度学习用于对冲的兴趣。
GANs已被用于投资组合分析、高频股票市场预测、金融交易策略的微调和校准等。QuantGAN、StockGAN、FINGAN和Buehler等人专注于生成合成金融时间序列。Li和Prenzel等人均采用GANs进行LOB中的订单流动态。GANs还用于金融市场中的异常(操纵)检测,并且通过GANs进行股票市场预测已与其他方法进行了探索和比较。
在适应时间序列的GANs方面,Yoon等人引入了TimeGAN,Xu等人提出了COT-GAN。TimeGAN利用嵌入和恢复网络将数据映射到高维潜在空间并返回。COT-GAN引入了一种基于正则化Sinkhorn距离的定制损失函数,该距离源自因果最优传输理论。然而,TimeGAN和COT-GAN都不是为预测任务量身定制的,主要用于数据增强。
本文重点关注Koochali等人的工作,他们引入了ForGAN,这是一种适合概率时间序列预测任务的条件GAN。该方法允许进行不确定性估计,这是传统时间序列预测方法无法提供的。
3. 生成对抗网络
生成对抗网络(GANs)由Goodfellow等人于2014年引入,目前在各种任务中处于最先进水平,最值得注意的是图像和视频生成。它们还广泛应用于科学、视频游戏、照片编辑、视频质量增强等领域。它们属于生成模型家族,其任务是生成来自未知数据分布的新样本。
3.1 经典GAN
经典GAN可以通过博弈论视角来理解。假设我们有两个玩家,生成器G和判别器D,互相进行游戏。G生成它认为看起来逼真的样本,而D则确定给它的样本是来自数据还是来自生成器。G的目标是学习如何让D相信它的输出是来自数据的,并生成尽可能逼真的样本。另一方面,D试图学习如何正确区分数据样本和来自生成器的样本。生成器G使用从判别器D接收到的反馈来改进生成的样本。在GANs中,生成器G和判别器D都是相对于其参数的可微函数,并且它们由神经网络表示。G被给予一些噪声作为输入,通常是高斯的,并返回生成的样本作为输出。D将G生成的样本或来自数据的真实样本作为输入,并输出其输入为真实的概率。GANs通过对抗过程进行训练,该过程包括同时训练两个不同的模型,一个生成器和一个判别器。在神经网络的情况下,这可以通过反向传播有效地实现。
假设我们有一些数据x来自未知的概率分布Pdata,并且我们希望从Pdata生成更多样本。
定义3.1 生成器G(z; θg)是从潜在空间到数据空间的微分映射。它由一个神经网络表示,接受输入噪声z ~ Pz(z)。G的输出所属的概率分布表示为Pg。
注释3.1 通常,z是一个多元正态分布。
定义3.2 判别器D(x; θd)是从数据空间到(0, 1)的微分映射,由一个神经网络表示。D(x)表示网络估计的x来自Pdata而不是来自Pg的概率。
判别器D被训练以最大化正确标记来自Pdata和Pg的样本的概率。生成器G被训练以最小化D正确标记其输出为来自Pg的对数概率,或最大化判别器出错的概率。
两个网络都有各自的目标函数,它们旨在最小化。这两个网络只能更新自己的参数以最小化各自的目标函数,尽管每个网络的目标函数都依赖于另一个网络的参数。在执行优化时,它们需要保持另一个网络的参数固定。通常,判别器采用的目标函数是交叉熵损失。
定义3.3 判别器的目标函数J(D)(θd, θg)定义为
J(D)(θd, θg) = ?Epdata [log[D(x; θd)]] ? Epz [log[1 ? D(G(z; θg); θd)]].
通过这个判别器的目标函数和J(G) = ?J(D)作为生成器的目标函数,学习零和游戏可以最小化Pdata和Pg之间的Jensen-Shannon散度。如果两个策略可以在函数空间中进行更新,游戏将收敛到纳什均衡,这在实践中通常不是这样,正如Goodfellow(2017)所论证的。当收敛发生时,判别器将所有输出视为同样可能来自Pdata或Pg,因此其输出将收敛到1/2。然而,Goodfellow等人(2014)和Goodfellow(2017)认为应该优先考虑最大化交叉熵损失而不是优化零和游戏。这种方法对应于生成器最小化判别器出错的概率对数。也就是说,生成器试图从判别器获得尽可能高的分数。
定义3.4 生成器的交叉熵损失J(G)(θd, θg)定义为
J(G)(θd, θg) = ?Epz [log[D(G(z; θg); θd)]].
Goodfellow等人(2014)进一步论证了使用生成器的交叉熵损失,即最大化log[D(G(z; θg); θd)],是因为零和损失可能无法为G提供足够大的梯度以使其能够很好地学习。在训练初期,G的样本很容易被识别为不是来自数据的,D可以强烈地将其分类为如此,使得log[1 ? D(G(z; θg); θd)]饱和。这使得G更难学习。将目标改为最大化log[D(G(z; θg); θd)]会导致D和G的动力学达到相同的平衡点,同时允许更大的梯度,使得生成器G能够学习更多。通常,判别器会训练得更多,每个生成器更新执行k次判别器更新。然而,Goodfellow(2017)认为应该使用k = 1。标准GAN的图示可以在图1中找到。
训练GAN时出现的主要问题是模式崩溃,也称为“模式崩溃”情景。它可以是完全的和部分的。当它发生时,无论噪声如何,生成器都会产生相同的输出(全模式崩溃),或者所有输出都有相似的图案(部分模式崩溃)。Durall等人(2021)认为模式崩溃与生成器转向尖锐局部最小值有关。当生成器开始生成相似的输出,并且由于可能收敛到局部最小值,判别器无法识别它们是来自生成器时,生成器会从判别器获得高评分。这可能导致弱梯度和对生成器网络的几乎没有更新,最终可能导致模式崩溃。
值得注意的是,保持生成器和判别器的平衡至关重要。当判别器压倒生成器时,这一点尤为重要。当判别器过于成功时,生成器无法从接收到的反馈中学习太多,因为梯度很弱。
总的来说,GANs非常难以训练(Arjovsky和Bottou 2017),因此自然要考虑改变训练目标。各种目标已被证明表现良好(Huszr 2015),包括所有f-散度(Nowozin等人 2016)。然而,最常用的GAN变体不是标准的交叉熵或零和GAN,而是Wasserstein GAN(W-GAN),由Arjovsky等人(2017)引入。它最小化了Pg和Pdata之间的Wasserstein-1距离。通常,Wasserstein GANs与梯度惩罚(Gulrajani等人 2017)更受欢迎,因为它们软化了Lipschitz约束。这种方法在判别器的训练目标中加入了梯度惩罚。
3.2 条件GAN
条件生成对抗网络是标准GAN的自然扩展,最初在最初的GAN论文中提到(Goodfellow等人 2014),并由Mirza和Osindero(2014)首次探索。我们假设数据x来自条件分布Pdata(x|condition),给定某个确定的条件,而不是所有数据样本来自相同的底层分布。在这种情况下,相同的原则适用。架构中的唯一区别是生成器和判别器都接收到进一步确定的信息(条件)以及标准输入。当这个条件是一个标签时,它通常被编码为一个独热向量。判别器/批评者也接收到相同的条件。条件GAN的图示可以在图2中找到。
作为一个直观的例子,我们可能旨在生成猫和狗的照片。我们有可用的猫和狗的标签作为独热向量。生成器将接收噪声和一个标签(例如猫)作为输入,并输出它认为的猫的照片。判别器将接收来自原始数据的猫的照片,以及生成器网络生成的猫的照片,两者都带有标签,表明照片应该是猫的照片。然后,判别器将对来自真实数据的猫的照片和来自生成器的猫的照片提供反馈,并学习。
3.3 ForGAN
ForGAN是一种条件GAN,其架构非常适合时间序列的概率预测,由Koochali等人(2019)引入。想法是使用条件GAN对给定序列的前L个值,Xt, Xt-1, …, Xt-(L-1),我们表示为X(L),进行xt+1的概率预测。这与标准点估计相比,可以利用更多的信息,并使该方法易于获得不确定性估计。
为了利用时间序列结构,生成器和判别器首先将它们的输入通过一个循环神经网络层。ForGAN架构包括门控循环单元(GRU)(Cho等人 2014)或长短期记忆(LSTM)单元(Hochreiter和Schmidhuber 1997),具体取决于数据。在我们的工作中,我们选择使用LSTM单元,因为其在金融领域的普遍性。类似的架构已经成功用于股票市场预测任务,例如,Zhang等人(2019a)。图3显示了使用LSTM单元的ForGAN架构的图示。
4. 性能指标
有多种方法可以衡量模型性能。根据应用情况,并非所有性能指标都同样重要。为了将一种方法与另一种方法进行比较,重要的是了解我们最关心的数据的哪些属性,以便能够构建适当的性能指标。
4.1 GANs的标准方法
衡量GANs的性能非常困难,因为我们通常不知道真实数据来自什么分布。通常,当处理图像、视频或声音时,有许多人类注释者来对生成的和真实的样本提供反馈。或者,可以使用初始得分(Salimans等人,2016)。它基于给定标签的条件数据分布与边际标签分布之间的Kullback-Leibler散度。这个得分还考虑了生成样本的多样性。不幸的是,上述方法都不能应用于我们的设置。
4.2 时间序列的标准方法
传统上,当手头的任务是时间序列预测时,人们会选择均方误差(MSE)、均方根误差(RMSE)和平均绝对误差(MAE)等性能指标。
为了定义MAE和RMSE,假设我们希望估计的真实值是x,而我们的预测是x。这可以是给定单个噪声样本的GAN输出,或者是给定相应条件的生成分布的均值或众数。然后,平均绝对误差和均方根误差定义为:
MAE(x, x) = (1/n) * Σ |xi – xi|, i=1到n
RMSE(x, x) = sqrt((1/n) * Σ (xi – xi)^2), i=1到n
4.3 金融数据,预测收益
由于我们处理的是金融数据,MAE和RMSE并不像在传统时间序列设置中那样具有代表性。在金融环境中进行预测通常是为了确定交易的方向(即是买入还是卖出资产),这为考虑基于损益(PnL)的指标提供了动力。虽然MAE和RMSE都可能非常低,但仍然有可能错误分类基础资产价格大幅波动的方向/方向性,导致严重的PnL损失。因此,我们将PnL作为我们的主要性能指标之一。在每个时间点,我们都会对(ETF超额)收益时间序列的真实值进行预测,并根据我们的预测进行交易。如果我们对ETF超额收益的预测为正,我们就会做多股票并做空相应的ETF。相反,如果它是负的,我们就会进行相反的交易。这一系列交易会产生一个PnL的时间序列。为了最小化风险并最大化利润,人们的目标是PnL时间序列为正,并且方差较低。PnL系列平均值越大,我们的策略的盈利能力就越高。PnL系列的方差越低,与策略相关的风险就越低。总的来说,这导致我们采用年化夏普比率作为我们的主要性能指标。我们注意到,这也是投资组合经理通常用来评估其策略的风险调整后表现的指标。
接下来,我们在使用的数据的上下文中定义上述术语。当考虑股票时,我们处理的是市场超额收益,而对于ETF,我们使用原始收益。假设资产A在时间t的价格为SA,那么它在时间t + 1的收益定义为:
SA(t+1) = log(SA(t+1) / SA(t))
如果资产A所属的行业有相应的ETF I,其在时间t的收益为rI,那么资产A在时间t的超额收益定义为:
rA(t) = rA(t) – rI(t)
如果我们预期A的收益高于I,那么我们就做多一股股票A并做空一股ETF I。我们对相反的情况也做类似的处理。因此,如果我们对rA(t+1)的预测是fA(t+1),那么这个策略的PnL(在时间t + 1)是:
PnL(t+1) = sign(fA(t+1)) * rA(t)
其中我们使用符号函数的左连续版本:
sign(x) = 1 如果 x ≥ 0, -1 如果 x < 0
为了简化分析和比较,我们考虑以基点为单位的PnL,并通过除以总交易次数来归一化。在我们的设置中,交易次数是验证/测试集的大小。如果我们有n个我们希望预测的rA值,表示为rA(1), …, rA(n),我们考虑每次交易的PnL(以基点为单位),为了简单起见,我们将其称为pPnL。正式地,这相当于:
pPnL = (1/n) * Σ sign(rA(i)) * rA(i), i=1到n
我们注意到,(8)式定义的pPnL没有考虑到预测符号的不确定性,只考虑了点估计。
由于我们可以获得完整的概率预测,我们理想上会对我们更有信心的回报给予更大的权重,而对那些我们不太确定的回报给予更小的权重。因此,我们通过为相同的条件取B = 1000个不同的噪声样本,估计(ETF超额)收益预测为正和负的概率。这两个概率估计分别表示为Pu和Pd,更准确地定义为:
Pu = (1/B) * Σ [1 如果 ref(z(j)) ≥ 0, 0 如果 ref(z(j)) < 0], j=1到B
Pd = (1/B) * Σ [1 如果 ref(z(j)) < 0, 0 如果 ref(z(j)) ≥ 0], j=1到B
其中ref(z(j))是生成器在给定时间序列rA(-L)的前L个值和噪声z(j)的情况下给出的输出。我们现在可以定义一个替代的PnL,我们可以将其构建为一个加权策略的PnL,该策略考虑了我们在预测符号上的确定性,如下:
wPnL(j) = 10000 * (Pu – Pd) * rA(j)
这个策略对应于做多Pu * 10000 * rA(j)股股票和做空Pd * 10000 * rA(j)股ETF,或者做空Pu * 10000 * rA(j)股股票和做多Pd * 10000 * rA(j)股ETF。这是等效策略的PnL,包括在不同的噪声样本中,根据适当条件对生成器的每个输出进行平均下注。因此,我们对更高的不确定性惩罚更多,如果我们不太确定结果,我们就会获得显著更低的潜在损失。
请注意,我们将PnL乘以10,000,以便获得以基点为单位的PnL值。此外,我们考虑的是每日数据,我们每天有两组回报(开盘到收盘和收盘到开盘),这促使我们考虑每日PnL:
wPnL'(i) = wPnL(2i) + wPnL(2i+1), i=1, …, 5
我们学习的分布越对称,wPnL就越接近于零。我们使用上面介绍的加权策略来计算年化夏普比率,我们将其用作我们的主要性能指标:
SRw = sqrt(252) * wPnL / sqrt((1/n) * Σ (wPnL(i) – wPnL)^2), i=1到n
当处理仅提供点估计的模型时,我们无法使用加权策略,因此我们改为考虑:
PnL'(i) = 10000 * (sign(rA(2i)) * rA(2i) + sign(rA(2i+1)) * rA(2i+1)), i=1到n
以及相应的年化夏普比率:
SRm = sqrt(252) * PnLm / sqrt((1/n) * Σ (PnL(i) – PnLm)^2), i=1到n
其中PnLm是PnL'(i)的平均值。
5. Fin-GAN损失函数
我们工作的主要贡献在于为生成器引入了一种新的经济学驱动的损失函数,将GANs置于监督学习环境中。这种方法使我们能够超越传统上用于点预测的方法,转向概率预测,提供不确定性估计。此外,我们根据预测的符号来评估性能,这意味着我们对分类感兴趣,我们的损失函数更适合。
5.1 动机
GANs的主要目的是创建模仿真实数据的合成样本。然而,一个重要的问题是,我们希望通过模拟来重现真实数据的哪些属性。在我们的案例中,它是预测的符号。我们更感兴趣的是正确分类收益/超额收益,特别是当价格变动的幅度很大时,而不是产生接近实际值的预测。动机是,人们可能会产生一个接近时间序列实际值的预测,但符号相反。在金融时间序列预测中,在最重要的时候正确估计符号通常比预测接近实际值更重要。我们的目标是为生成器提供更多信息,使其更好地复制数据的符号,这是任务的关键组成部分。使用新的损失函数项的主要原因和好处可以总结如下:将生成的条件分布转移到正确的方向,使GANs更适合分类任务,提供有效的正则化,帮助生成器学习更多,特别是在梯度较弱的情况下,帮助避免模式崩溃;通过使生成器损失表面更加复杂,生成器可能会收敛到尖锐的局部最小值。
我们已经看到了几个不同损失函数的例子,以及它们带来的好处。最值得注意的是,W-GAN-GP(Gulrajani等人 2017)在判别器损失中添加了一个额外项作为强制Lipschitz约束的一种方式。在生成器中添加损失项不太常见,但在Bhatia等人(2021)最近的工作中用于生成极端样本,以及在VOLGAN(Vuletic和Cont 2023)中用于模拟无套利隐含波动率表面。其他定制的损失函数在金融领域也被证明是有用的,例如Tail-GAN(Cont等人 2022),它侧重于估计投资组合尾部风险。
5.2 新的损失函数
假设我们的GAN旨在预测Xi,其中i = 1, …, nbatch。对于每个xi,给定一个噪声样本z和由时间序列x的前L个值组成的条件,生成器的输出是:
xi = G(z, x ;- )
让x = (x(1), …, x(nbatch))和x = (x(1), …, x(nbatch))是x的预测。我们定义了三个损失函数项,即PnL、MSE和基于夏普比率的损失函数项,我们使用它们来训练生成器。
5.2.1 PnL项
包含生成器训练目标(最大化)的损失函数项的第一个也是最明显的选择是PnL。然而,符号函数是不可微的,使得无法执行反向传播。为了缓解这个问题,我们提出了一个对pPnL的平滑近似,我们将其表示为PnL*,定义为:
PnL*(x, x) = (1/nbatch) * Σ PnL*(xi, xi), i=1到nbatch
其中PnL*是特定预测的PnL的平滑近似:
PnL*(xi, xi) = tanh(ktanh * tanh(xi – xi))
tanh(x)定义为:
tanh(x) = (exp(x) – exp(-x)) / (exp(x) + exp(-x))
超参数ktanh控制我们近似的准确性。由于超额收益的值通常很小,ktanh的值应该足够大以获得良好的近似,但同时又足够小以获得生成器可以学习的强梯度。请注意,在PnL项的表达式中,我们考虑的是每次交易的PnL。这不是每天平均的PnL,因为训练数据集在每个纪元开始时被洗牌。我们使用ktanh = 100。
5.2.2 MSE项
尽管我们主要对预测的符号感兴趣,但我们也希望x接近Xi。为了强制执行这一点,我们在训练目标中添加了一个MSE项:
MSE(x, x) = (1/nbatch) * Σ (xi – xi)^2, i=1到nbatch
5.2.3 夏普比率项
由于我们的主要性能指标是年化夏普比率,我们引入了基于SR的损失函数项供生成器最大化。然而,由于计算成本过高,我们没有在训练期间实施加权策略,而是使用点估计,给定每个条件窗口一个噪声样本。我们没有将交易配对成两个,因为训练集中的连续数据点不一定以原始顺序出现,因为洗牌。随机选择小批量,或者等效地在每个纪元开始时洗牌训练数据集是非常重要的,以便随机梯度下降能够收敛。因此,我们定义生成器在训练期间要最大化的夏普比率项,表示为SR*:
SR*(x, x) = (1/nbatch) * Σ PnL*(xi, xi) / sqrt((1/nbatch) * Σ (PnL*(xi, xi) – (1/nbatch) * Σ PnL*(xi, xi))^2), i=1到nbatch
5.2.4 标准差(PnL系列)项
最大化夏普比率意味着最大化PnL并最小化PnLs的标准差。因此,自然会考虑一个标准差项,我们将其定义为:
STD(x, x) = sqrt((1/nbatch) * Σ (PnL*(xi, xi) – (1/nbatch) * Σ PnL*(xi, xi))^2), i=1到nbatch
由于上述定义的损失项指的是近似PnLs的标准差,因此只有在包含PnL项的情况下才应将其包含在训练目标中,这是由于层次原则。SR项和与STD项结合的PnL传达了相同的信息,因此不应同时使用这三个。然而,尽管最大化SR的目标与同时最大化PnL*和最小化STD相同,但梯度范数是不同的,这可能导致训练期间的行为不同。
5.2.5 生成器的经济学驱动损失函数
最后,我们将上述所有损失函数项(方程(16)、(19)和(20))整合在一起,并得出生成器的Fin-GAN损失:
LG(x, x) = J(G)(x, x) – αPnL*(x, x) + βMSE(x, x) – γSR*(x, x) + δSTD(x, x)
其中J(G)是标准GAN损失之一(零和、交叉熵或Wasserstein),超参数α、β、γ是非负的。判别器的损失仍然是J(D)。在先前的数值实验中,Wasserstein损失遭受了爆炸,因此我们选择使用二元交叉熵损失作为J(G)。我们的目标是最小化经典的生成器损失函数(J(G)),最大化基于PnL的损失函数项,最小化MSE项,并最大化基于SR的损失函数项,或联合最大化PnL并最小化STD项。我们研究的损失函数组合是PnL、PnL&STD、PnL*&MSE、PnL&SR、PnL&MSE&STD、PnL&MSE&SR、SR、SR*&MSE、MSE、仅BCE。标准差项指的是PnL项,因此由于层次原则,只有在包含PnL项的情况下才包括它。当涉及到Fin-GAN时,需要包括一个经济学驱动的损失项,因此对于Fin-GAN,我们只考虑以下选项:PnL、PnL&STD、PnL*&MSE、PnL*&SR、PnL&MSE&STD、PnL*&MSE&SR、SR、SR*&MSE。换句话说,我们对α、β、γ、δ施加以下条件:
max(α, γ, δ) > 0(至少包括一个除MSE之外的附加项)。
如果β > 0,则max(α, γ, δ) > 0(如果包括MSE项,则包括另一个项)。
如果δ > 0,则δ > 0(仅当包括PnL*项时才包括STD项)。
min(γ, δ) = 0(SR*和STD项永远不会同时包括)。
我们将使用ForGAN架构和由上述方程(22)以及规则定义的损失函数的GANs称为Fin-GANs。
5.2.6 梯度范数匹配
为了避免超参数调整以找到α、β、γ、δ,我们使用类似于Vuletic和Cont(2023)的方法,将所有项视为同等重要。也就是说,我们首先仅使用J(G)训练网络,但我们计算方程(22)中所有项相对于生成器θg参数的梯度范数。然后,我们将α、β、γ、δ设置为观察到的比率的均值(或如果它们未包含在目标中,则为零)。然后,我们使用计算出的α、β、γ、δ值使用可能的组合训练网络。然后,通过在验证集上评估夏普比率来确定新项的最终组合。进一步的训练细节在第6节中解释,Fin-GAN算法在算法1中给出。
5.3 Fin-GAN损失函数的优势和挑战
新的损失函数项确实改变了生成的分布,有助于避免模式崩溃,并提高了夏普比率性能,我们在广泛的数值实验中证明了这一点。包含新的损失函数项引入了四个新的超参数需要调整,使得优化成为一个更具挑战性的问题。然而,梯度范数匹配方法缓解了这个问题。
此外,损失表面变得更加复杂,增加了收敛挑战。在最初的数值实验中,当探索更广泛的超参数α、β、γ、δ时,MSE和夏普比率项似乎鼓励生成器产生非常狭窄的分布。尚不清楚为什么具有高γ系数的夏普比率项会导致模式崩溃,因为它鼓励PnLs具有低标准差,而不是生成的样本。然而,包含基于PnL的项有助于缓解模式崩溃问题,这与收敛到尖锐局部最小值有关(Durall等人 2021)。PnL项帮助生成器逃离损失表面的这些区域。
当使用梯度范数匹配来调整超参数α、β、γ、δ时,无论网络权重的初始化如何,Fin-GAN中都没有模式崩溃。然而,我们注意到,使用Xavier初始化(Glorot和Bengio 2010)而不是He初始化(He等人 2015)有助于减少ForGAN中模式崩溃的迭代次数。使用He初始化,这种情况在67%的案例中发生。利用正常的Xavier初始化解决了这个问题。
经典的生成器损失项,即从判别器接收到的反馈,允许学习条件概率分布,而不仅仅是点预测。
剩余的损失函数项促进了符号一致性(由PnL和夏普比率项强制执行),同时又试图保持接近实际值(MSE)。
如果超参数α、β、γ、δ太大,判别器的反馈就变得微不足道,我们转向标准的监督学习设置,使用仅生成器模型。另一方面,如果α、β、γ、δ太小,我们就没有向生成器提供任何额外的信息,因此仍然处于经典的GAN设置中。通过新的损失函数项传达的关于数据的额外信息在来自判别器/批评者反馈的弱梯度的情况下尤其有价值,因为生成器在这种情况下仍然可以取得进展。这最终导致了对数据在价格方向性运动方面的更好分类,即正确分类未来时间序列值的符号,以及对运动方向的 uncertainty estimates。梯度范数匹配程序确保所有损失项都被视为同等重要,并且相应的超参数既不太大,也不太小。
6. 数据描述和实施考虑
在本节中,我们概述了我们使用的数据集的主要特征,并进一步描述了ForGAN架构。接下来,我们讨论训练设置,包括超参数选择以及优化。最后,我们展示了Fin-GAN模型的一般行为,这在数值实验中反复出现。
6.1 数据描述
我们考虑从Wharton Research Data Services的CRSP中提取的每日股票ETF超额收益和每日原始ETF收益。感兴趣的时间范围是2000年1月-2021年12月。所有时间序列都有相同的训练-验证-测试分割,即80-10-10。也就是说,训练期为2000年1月3日-2017年8月9日,验证期为2017年8月10日-2019年10月22日,测试期为2019年10月23日-2021年12月31日。这三个时间段从经济角度来看非常不同,重要的是要注意测试数据包括Covid-19大流行的开始,使得问题更具挑战性。我们依次考虑开盘到收盘和收盘到开盘的回报,并将每一个称为一个时间单位。换句话说,一个输入时间序列交替出现日间开盘到收盘和隔夜收盘到开盘的回报。滑动窗口是一个时间单位,条件窗口是十个时间单位(对应于五天的回报,即一个完整的交易周),预测窗口是一个时间单位。
价格通过除以提供的累积调整因子(cfacpr)进行调整,回报被限制在15%,以减轻潜在异常值的影响。为了预处理数据,我们首先创建一个由连续收盘到开盘和开盘到收盘回报组成的时间序列,然后按时间顺序将数据分成三个不重叠的较短时间序列(训练-验证-测试),我们适当地进一步处理这三个结果的时间序列。在这个在这个阶段,我们为三个数据集中的每一个创建了一个矩阵;每个这样的矩阵包含11列,前10列对应于条件窗口(x1, …, x10),最后一列是目标(x11)。一个时间单位的滑动窗口意味着列j中的第k个值是列j-1中的第k+1个值。
我们考虑九个行业中22只不同股票的ETF超额回报,以及九个行业ETF的原始回报。所有股票都是当前标准普尔500指数的成员。股票代码及其行业成员资格如表1所示。
6.2 ForGAN架构
对于单只股票/ETF的数值实验,使用了经典的ForGAN架构,利用LSTM单元,如图3所示。由于使用的数据集规模较小,相应的层维度和噪声维度都设置为8。生成器使用ReLU作为激活函数,而判别器使用sigmoid。
6.3 训练
为了避免进一步的超参数调整,整个过程中使用的优化器是RMSProp(Hinton等人,2012),并且权重使用正常的Xavier初始化(Glorot和Bengio,2010)。判别器/批评者和生成器使用交替方向方法进行训练,每个生成器更新进行一次判别器更新。我们使用参考批量归一化,从训练数据中选取前100个样本作为参考批量,以避免预测性。小批量大小也设置为100。两个网络的学习率都设置为0.0001。我们从开始训练25个周期,仅使用BCE损失来实现梯度范数匹配,并找到α、β、γ、δ系数。然后,我们通过每种合适的损失组合训练100个周期,从生成器和判别器中分支出来。在训练阶段结束时,我们在验证集上计算夏普比率,并选择损失函数组合以及最大化它的优化生成器。由于验证和测试的经济周期不同,网络在测试集上表现良好并不一定被选中。然而,这种方法允许我们在危机期间确保良好的表现。代码在PyTorch中实现。Fin-GAN算法在算法1中总结。
注释6.1:人们可以通过在验证集上评估夏普比率,并选择最大化它的超参数/架构,来探索更广泛范围的超参数α、β、γ、δ,学习率lrg、lra,隐藏维度RG、RD,噪声维度N,以及完全不同的架构。
6.4 梯度稳定性
在加入额外的损失函数项之前,我们首先调查训练期间梯度范数的行为,以检查梯度消失和爆炸。我们训练ForGAN,使用RMSProp(Hinton等人,2012)对BCE损失进行更新,训练25个周期,这是用于梯度范数匹配的时间段。在图4中,我们展示了每个项(方程(22))的样本梯度范数。本例中使用的数据是PFE的每日超额股票回报时间序列。我们观察到,没有消失或爆炸现象,梯度范数在相似的尺度上。对于我们实验中使用的其他股票代码也是如此。
6.5 模式崩溃
由于我们考虑的是时间序列数据,我们识别出两种不同类型的模式崩溃,分布模式崩溃和均值模式崩溃,每种都可以是完全的或部分的。分布模式崩溃指的是给定条件的生成分布的崩溃,均值模式崩溃指的是所有条件下生成分布的均值的分布的崩溃。
当完全均值和完全分布模式崩溃同时发生时,这是一个主要问题,因为这导致只有一个点估计。为了简化我们设置中的模式崩溃概念,我们认为如果特定条件(时间点)的样本外生成场景,即生成的均值的时序,标准差低于阈值ε,我们将其设置为0.0002,则模式崩溃发生。使用Xavier初始化网络权重(Glorot和Bengio,2010)有助于缓解ForGAN的模式崩溃。Fin-GAN损失函数的额外项已被证明具有有效的正则化,因为在任何实验中都没有模式崩溃,无论网络是按照Xavier还是He初始化(He等人,2015)进行初始化的。重要的是要注意,当使用He初始化时,ForGAN在67%的模拟中遭受了某种类型的模式崩溃。此外,在最初的数值实验(考虑STD项之前)中,使用了更广泛的超参数范围而不是执行梯度匹配,我们注意到,具有高β和γ的MSE和SR项可能会导致模式崩溃。然而,包含PnL项将解决这个问题。MSE项旁边的高超参数导致模式崩溃的后果并不令人惊讶,因为MSE项鼓励生成的值接近目标。夏普比率项虽然促进了小标准差,但并没有促进预测的狭窄分布,而是PnLs。
6.6 生成分布
图5显示了使用不同的Fin-GAN损失函数项组合进行训练时生成的分布样本。所有显示的分布都是使用相同的训练数据(PFE的超额回报)和测试集中的相同条件(它们有相同的目标)生成的。在整个数值实验中,仅使用BCE损失进行训练会产生更对称的分布,而包含的Fin-GAN损失函数项将有助于转移预测分布。我们还调查了生成的均值,并将它们与目标在图6中的真实分布进行了比较。我们注意到,在这个特定的例子中,PnL和STD组合的行为类似于单独的SR项。这并不令人惊讶,因为两者传达了相同的信息,尽管它们的梯度不同。这两个选项在这个例子中都有最大的分布转移效果。我们注意到,除了带有STD的PnL和SR损失项外,所有生成的均值都类似于真实的目标分布。此外,包含MSE项促使均值的分布更接近于真实回报的分布。
图5使我们能够说明GANs由于不确定性估计而能够采用的加权策略。在这个特定的预测中,SR以及PnL和STD将导致做多ETF和做空股票,权重为1,而PnL、MSE和SR组合将有一个类似但权重略低的交易,其他组合将由于对预测符号的不确定性而导致非常小的交易。尽管我们在图5和图6中只考虑了Fin-GAN损失项,但重要的是要注意,BCE损失与添加了MSE项的BCE损失之间的平均相关性为99.7%。
我们观察到,在损失项的组合上进行训练是有益的,因为它们能够产生生成的分布的转移并避免模式崩溃。联合利用Fin-GAN损失函数项的好处得到了夏普比率性能的支撑,我们将在第8节中进行分析。
重要的是要强调,在验证阶段选择的作为最优的配置将因实例而异。图5和图6是使用不同目标进行训练所获得的分布结果的示例。
7. 基线算法
除了标准的ForGAN(使用BCE损失训练的ForGAN架构的GAN),我们将我们的Fin-GAN模型与更标准的监督学习方法进行时间序列预测:ARIMA和LSTM。为了完整性,并为了证明手头的任务并非微不足道,我们进一步包括了长期策略的PnL和夏普比率值,其中每个观测的预测符号为+1。所有比较都有与Fin-GAN实验中使用的相同的训练-验证-测试分割。
7.1 ARIMA
我们首先回顾自回归综合移动平均(ARIMA),这是一个非常经典的时间序列模型(Tsay,2005)。ARIMA(p,d,q)中的参数p、d、q分别对应于自回归、差分和移动平均部分。差分系数d表示我们需要对初始时间序列进行差分的次数,以便达到一个没有单位根的时间序列X。为了确定d,我们执行增广Dickey-Fuller(ADF)检验。在我们的案例中,所有时间序列的p值都小于10^-6,表明平稳性。这并不令人惊讶,因为我们处理的是回报和超额回报,它们已经是差分对数价格时间序列。因此,在我们的设置中,我们始终设置d = 0,因此使用ARMA(p,q)模型,其形式为:
X(t) = φ1X(t-1) + … + φpX(t-p) + θ1ε(t-1) + … + θqε(t-q) + ε(t)
其中ε1, …, εt是白噪声项,θi是移动平均参数,φj是自回归参数。为了确定最合适的p和q,我们绘制了自相关(ACF)和偏自相关(PACF),它们表明p, q ∈ {0, 1, 2}。我们拟合ARMA(p,q)与(p,q) ∈ {(1,0), (1,1), (2,0), (2,1), (2,2)},并选择具有最低Akaike信息准则(AIC)的模型。
7.2 LSTM
长短期记忆网络,或LSTM(Hochreiter和Schmidhuber,1997),属于循环神经网络类。它们有助于解决梯度消失/爆炸问题,并且特别适合处理时间序列。在每个时间t,有输入x(t),前一个细胞状态c(t-1)和前一个隐藏状态h(t-1)(前一个LSTM输出)。然后,这些由遗忘门、输入门和输出门处理,以便创建新的细胞状态c(t)和新的隐藏状态,即输出h(t)。
对于训练,我们使用与Fin-GAN相同的设置。也就是说,我们使用RMSProp作为选择的优化器,训练125个周期。我们现在处于回归设置中,因此LSTM被训练以最小化MSE损失。速率再次为0.0001。
7.2.1 LSTM-Fin
我们还在适当的(基线)MSE损失、PnL、SR和STD损失项的组合上训练LSTM,以便与Fin-GAN进行更好的比较。我们使用与Fin-GAN设置中相同的方法,也执行梯度范数匹配以确定与新包含的损失项相对应的超参数值。也就是说,我们考虑损失函数(24),包括和排除PnL、SR和STD损失项,通过与Fin-GAN相同的规则,确定超参数α、γ、δ的值,使用相同的梯度范数匹配程序,并通过在验证集上评估夏普比率来确定最终用于测试的损失函数组合。
LFin(x, x) = MSE(x, x) – αPnL*(x, x) – γSR*(x, x) + δSTD(x, x).
7.3 长期策略
我们还评论了做多股票和做空ETF(对于股票数据)以及仅做多ETF(对于ETF数据)结果,这对应于始终预测每个观测的符号为+1。
8. 数值实验
在本节中,我们首先考虑单只股票设置。也就是说,我们在特定股票/ETF的ETF超额回报/原始回报上训练Fin-GAN和基线。然后,我们以Sirignano和Cont(2019)的精神,探索普遍性的概念,在三组不同的股票上。我们将数据池化在单只股票设置中使用的股票代码上,并训练Fin-GAN,就像数据来自同一来源一样。我们在属于同一行业(消费品)的股票上重复这种方法,包括和不包括在训练阶段使用的XLP原始回报。在普遍设置中,我们进一步调查了Fin-GAN在训练阶段模型未见过的股票上的表现。
8.1 单只股票和ETF设置
我们首先检查所考虑模型的汇总性能:Fin-GAN、ForGAN(通过BCE损失训练)、LSTM、LSTM-Fin、ARIMA和长期策略。感兴趣的统计数据是年化夏普比率、平均每日PnL、MAE和RMSE。所有统计数据通过计算在数值实验中使用的31个数据集(22只股票和9只ETF)上的平均值和中位数来汇总。此外,我们通过首先将宇宙中所有股票代码的每日PnL相加,然后计算结果每日PnL时间序列的夏普比率来报告投资组合夏普比率。这些汇总统计数据如表2所示。
我们注意到,Fin-GAN实现了最高的平均、中位数和投资组合夏普比率,其次是LSTM。Fin-GAN实现的中位数夏普比率接近LSTM的两倍。此外,我们注意到,尽管使用Fin-GAN方法时夏普比率最高,但LSTM实现了最高的平均PnL,ARIMA实现了最高的中位数PnL。这完全展示了与Fin-GAN相比,其他模型生成的PnL的方差显著减少和更高的一致性。这也是由于与其他策略相比,交易规模较小,这是由于能够利用不确定性估计并实施加权策略。我们强调新的损失函数项对性能的积极影响,这通过Fin-GAN实现的平均、中位数和投资组合夏普比率显著高于仅使用BCE损失训练的ForGAN来证明。
股票和ETF上模型性能指标的汇总
| 指标 | Fin-GAN | ForGAN | LSTM | LSTM-Fin | ARIMA | 长期策略 |
|---|---|---|---|---|---|---|
| 平均夏普比率 | 0.540 | 0.033 | 0.467 | 0.341 | 0.206 | 0.182 |
| 中位数夏普比率 | 0.413 | -0.092 | 0.214 | 0.170 | 0.204 | 0.194 |
| 投资组合夏普比率 | 2.107 | 0.172 | 2.087 | 0.942 | 0.612 | 0.618 |
| 平均PnL | 2.978 | 0.254 | 4.123 | 2.361 | 2.059 | 2.350 |
| 中位数PnL | 1.890 | -0.673 | 1.959 | 1.735 | 2.245 | 1.975 |
| 平均MAE | 0.044 | 0.052 | 0.007 | 0.007 | 0.007 | |
| 中位数MAE | 0.008 | 0.009 | 0.007 | 0.007 | 0.007 | |
| 平均RMSE | 0.049 | 0.056 | 0.012 | 0.012 | 0.012 | |
| 中位数RMSE | 0.012 | 0.014 | 0.011 | 0.011 | 0.011 |
我们进一步注意到,ARIMA在RMSE方面表现最佳,并实现了最佳的MAE平均值,而LSTM实现了最低的中位数MAE。我们还注意到,非GAN模型在其MAE和RMSE汇总统计数据上处于相同的尺度,而GAN模型的平均MAE和RMSE显著更高。然而,中位数与其他模型处于相似的尺度,并且当从ForGAN转移到Fin-GAN时,误差减少。在图9和图8中分别调查RMSE和MAE时,我们发现Fin-GAN实现如此高的平均MAE和RMSE的主要原因是IBM的表现。然而,在这种情况下,Fin-GAN实现了比其他模型更高的夏普比率(图10)和PnL(图11)。类似地,尽管ARIMA实现了接近实际值的数值,但当基础资产的波动较大时,它在真实线的另一侧实现,导致较低的PnL和较低的夏普比率。我们注意到,非深度学习方法(ARIMA和长期策略)实现的汇总统计数据相似,并且它们比以传统方式训练的ForGAN表现更好。长期策略列表明,考虑到在Covid-19大流行期间科技行业股票持续增加的情况下,只有XLK的夏普比率超过1,这并非出乎意料。此外,在GAN设置中,经济驱动的损失函数项的积极影响在LSTM的情况下并不明显。
上述实验表明,Fin-GAN方法在平均情况下优于ForGAN、LSTM、ARIMA和长期策略基线。我们现在进一步调查夏普比率在单个股票代码级别的行为。模型和股票代码的年化夏普比率性能如图10所示。我们观察到,Fin-GAN模型优于所有其他基线,能够实现非常有竞争力的夏普比率,特别是考虑到我们处理的是单工具投资组合。Fin-GAN实现的夏普比率比LSTM更稳定,唯一夏普比率低于-1的股票代码是XLY(消费品)。这并不令人惊讶,因为这个行业ETF在Covid-19大流行初期出现了崩溃,并且在用于验证的时间段内持续增长。在LSTM实现夏普比率超过1或2的数据集上,Fin-GAN也是如此,实现类似的夏普比率,或者在CL的情况下更高。总的来说,我们观察到使用Fin-GAN与使用其他方法相比,在夏普比率性能方面有明显的优势。Fin-GAN按股票代码分解的累积PnL性能如图12所示。我们注意到,Covid大流行对不同股票的影响不同,2020年3月至6月的表现是实现PnL波动的主要原因。
就整体表现而言,Fin-GAN和LSTM优于所有其他考虑的方法。相应投资组合的累积PnL图如图13所示。深度学习模型从Covid-19冲击中恢复得比ARIMA和长期策略快得多,我们注意到生成的PnL中的大部分波动源于大流行。在图13中,我们显示了通过不同的Fin-GAN损失组合实现的累积PnL,包括仅使用MSE和BCE项的组合,其平均与ForGAN的相关性为99.7%。很明显,通过使用验证,而不是从一开始就对每个数据集使用相同的损失组合,整体性能得到了提高。LSTM的投资组合PnL更高,但路径波动更大,特别是在2020年3月至2020年6月期间,导致夏普比率低于Fin-GAN。
关于图11中显示的平均每日PnL表现,我们注意到ARIMA和长期策略倾向于产生相同量级的平均每日PnL,而LSTM平均实现最高的PnL。然而,LSTM实现的PnL在不同股票代码之间波动很大。GAN方法实现的平均每日PnL的标准差(Fin-GAN为4.85,ForGAN为4.00)远低于LSTM(7.48)、LSTM-Fin(7.53)、ARIMA(6.26)和长期策略(5.97),展示了能够利用不确定性估计来开发具有动态规模的加权策略的好处。
接下来,我们评论Fin-GAN性能中选择的损失函数组合的分解。如图5所示,利用引入的损失函数项一起使用是有益的,既可以转移分布目的,实现对数据分布的更好近似,也可以缓解模式崩溃。我们注意到,包含MSE项是非常突出的,有趣的是,PnL和夏普比率组合从未被选中。最常见的选择是带有MSE的夏普比率,占29%的案例。
我们比较了不同Fin-GAN损失函数组合在测试集上的夏普比率性能,并在图14中显示了结果。由于验证集和测试集之间的差异,有时在验证阶段会选择次优的损失函数组合。然而,我们注意到,为了选择包含在训练目标中的哪些项而进行的验证提高了模型的夏普比率性能。
如前所述,SR和PnL和STD(PnL&STD)项的组合传达了相同的信息,但具有不同的梯度,并可能导致不同的预测。因此,我们调查了通过不同损失项组合获得的样本外PnL(测试集)的平均Pearson相关性。包含MSE项的组合与相应的包含MSE项的组合之间存在高度相关性,这并不令人惊讶。
一个重要的发现是,MSE项与BCE损失之间的平均相关性为99.7%,这意味着通过二元交叉熵损失训练的ForGAN已经旨在产生接近实际值的输出。这种行为可以通过数据和手头任务的结构来简单解释:由于每个条件都有一个真实的目标,即经验条件分布是点质量Pdata(Xt+1|x)=δ(x+1)如果L足够大。因此,接近目标的预测值会从判别器获得高分,鼓励在经典GAN设置中模式崩溃。这进一步支持了使用ForGAN作为基线的决定,其适合概率预测,以及将其定制为金融设置的需要。
8.2 普遍性
我们以Sirignano和Cont(2019)的精神测试我们方法的普遍性。然而,由于计算成本,我们只能对一小部分股票和ETF进行数值实验,即之前使用的31只。我们不尝试从跨资产相关性中学习,而是单独考虑每个时间序列。也就是说,我们采用单资产模型,我们将所有31只股票代码的数据组合(池化)。我们测试模型在所有用于训练和四只额外未见过的股票上的表现。训练、验证和测试集的时间段以及Fin-GAN方法保持不变。普遍性模型的夏普比率性能的汇总如图16中的热图所示。单只股票列指的是单只股票模型仅在特定股票代码上训练时实现的最高夏普比率。股票代码CCL、EBAY、TROW和CERN在训练阶段未被模型看到。我们注意到,即使在未见过的股票上也能实现有竞争力的夏普比率。例如,在THROW数据上实现的夏普比率通常超过1,尽管普遍模型从未见过EBAY数据。图16表明,一些包含在普遍模型训练中的股票从与其他股票的池化训练中受益,但不是全部。这在XLY中最为明显,其中实现的夏普比率要么显著不那么负,要么甚至是正的。整体表现没有增加可能是由于我们的股票宇宙较小,并且没有强烈的相关性。人们会期望,当股票属于同一行业时,跨资产相互作用提供的信息更多。
我们使用消费品(XLP)行业的股票重复相同的分析。我们进行了一组包含XLP数据(原始回报)在训练数据中的数值实验,以及另一组不包含XLP数据的实验。不包含XLP数据的夏普比率性能如图17中的热图所示,而包含XLP数据的相同性能如图18所示。模型未见过的股票是SYY和TSN。与之前讨论的普遍模型类似,在未见过的数据上实现的夏普比率可以非常有竞争力,例如TSN。当包含XLP数据时,验证选择的模型是PnL & SR,在测试集上实现了良好的整体投资组合SR 1.43。尽管并非所有股票都有正的夏普比率,但这种组合实现了良好甚至非常好的SR,包括在未见过的TSN数据上1.55的夏普比率。一个重要的观察是,在这种情况下,XLP数据的夏普比率是1.11,而单只股票设置中是0.393。其他ETF也可能从与其成分股一起训练中受益。当从用于训练的股票池中移除XLP数据时,选择的模型是SR。投资组合夏普比率降至1.18,但仍然具有竞争力。通过比较图17和图18中的热图,我们得出结论,在Fin-GAN的训练过程中包含ETF数据是有明显好处的,但对于ForGAN则不然。与XLP数据一起训练导致比没有它的模型更稳定的夏普比率。
9. 结论和未来展望
我们已经展示了GANs可以成功应用于金融数据环境中的概率时间序列预测,其中预测的方向性(符号)在大型价格跳跃之前尤为重要。我们引入了一种新的经济学驱动的生成器损失函数,它包括适当加权的损益(PnL)、PnL的标准差、MSE和基于夏普比率的损失函数项,使GANs更适合分类任务,并将其置于监督学习环境中。
在一套全面的数值实验中,我们将我们的方法与标准GAN模型、LSTM、ARIMA和长期策略进行了比较,并证明了我们的模型在实现的夏普比率方面具有优越的性能。
此外,我们在三种设置中考虑了普遍模型:汇集来自不同行业和行业ETF的股票数据,考虑一个包含行业ETF在训练数据中的行业,以及在训练阶段排除行业ETF。即使股票宇宙很小,我们注意到即使在未见过的股票上也能实现良好的性能。此外,当行业ETF包含在训练数据中时,单一行业设置中的性能有所提高。
本文的Fin-GAN方法被证明能够显著提高夏普比率性能,转移生成的分布,以及帮助缓解模式崩溃问题,后者是许多基于GAN的方法中的标准挑战。
代码下载见星球,QuantML星球内有各类丰富的量化资源,包括数百篇论文代码,QuantML-Qlib框架,研报复现,研报分享项目等,星球群内有许多大佬,包括量化私募创始人,公募jjjl,券商研究员,顶会论文作者,github千星项目作者等,星球人数已经500+,欢迎加入交流
我们的愿景是搭建最全面的量化知识库,无论你希望查找任何量化资料,都能够高效的查找到相关的论文代码以及复现结果,期待您的加入。