
2024年11月4日arXiv cs.CV发文量约85余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省36分钟浏览arXiv的时间。


特伦托大学, 奥卢大学, 新加坡国立大学的研究团队提出了一种基于扩散的人脸匿名化方法。该方法无需面部标记或面具,仅依赖于单一的重建损失,能够生成具有详细细粒度特征的图像,同时实现身份匿名化。
【Bohr精读】
https://j1q.cn/8mn3QNHs
【arXiv链接】
http://arxiv.org/abs/2411.00762v1
【代码地址】
https://github.com/hanweikung/face_anon_simple

谷歌研究和华盛顿大学的研究团队提出了Fashion-VDM,这是一个用于虚拟试穿的视频扩散模型。该模型采用基于扩散的架构进行视频虚拟试穿,使用无分类器的分割指导,以增加对条件输入的控制,并采用渐进式时间训练策略,用于单次通过生成64帧、512像素视频。
【Bohr精读】
https://j1q.cn/pqZFWQpy
【arXiv链接】
http://arxiv.org/abs/2411.00225v1
【代码地址】
https://johannakarras.github.io/Fashion-VDM
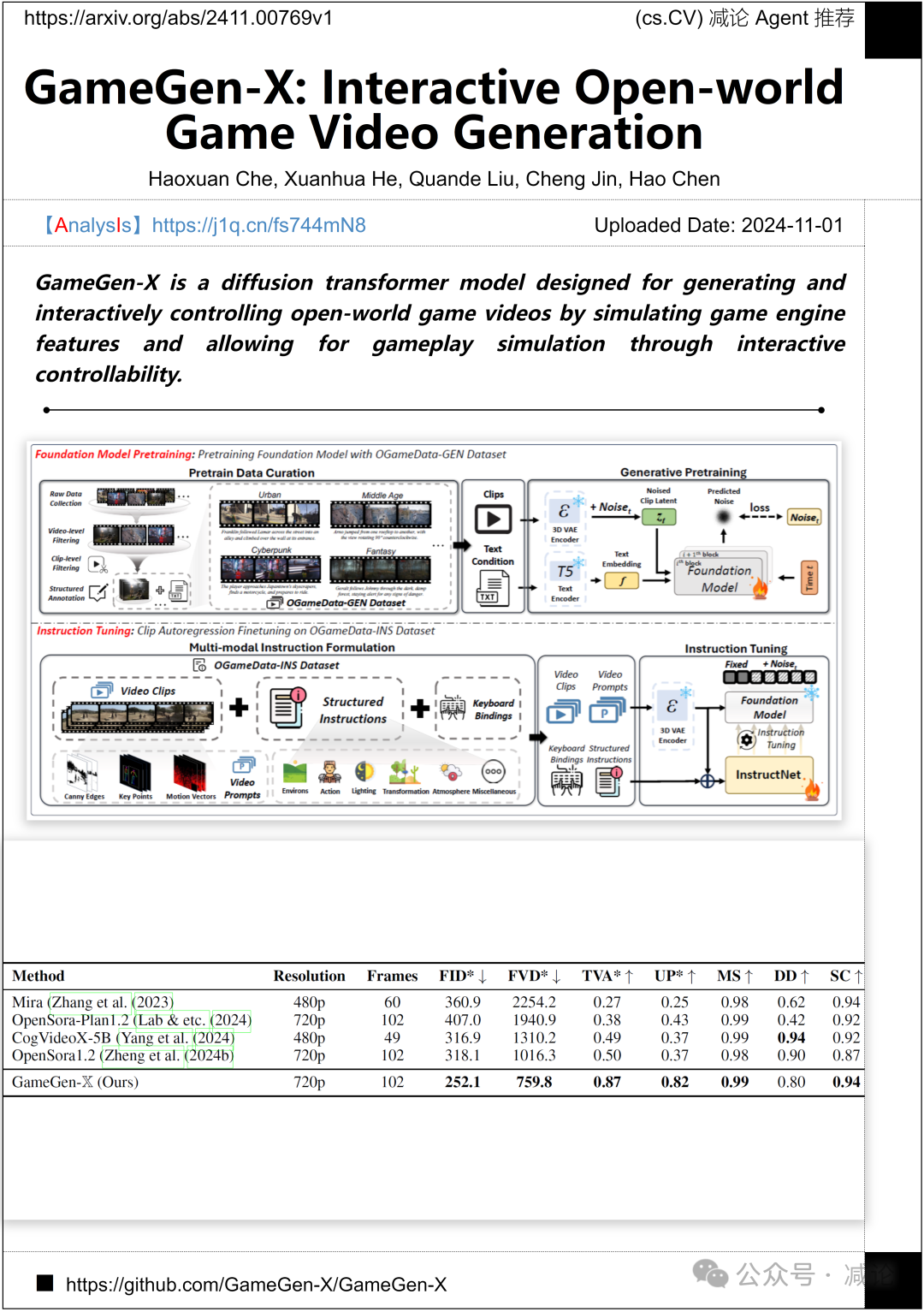
香港科技大學和中國科學技術大學的研究團隊提出了GameGen-X,這是一個擴散變壓器模型,旨在通過模擬遊戲引擎特性並允許通過交互控制進行遊戲模擬,生成和交互控制開放世界遊戲視頻。
【Bohr精读】
https://j1q.cn/fs744mN8
【arXiv链接】
http://arxiv.org/abs/2411.00769v1
【代码地址】
https://github.com/GameGen-X/GameGen-X
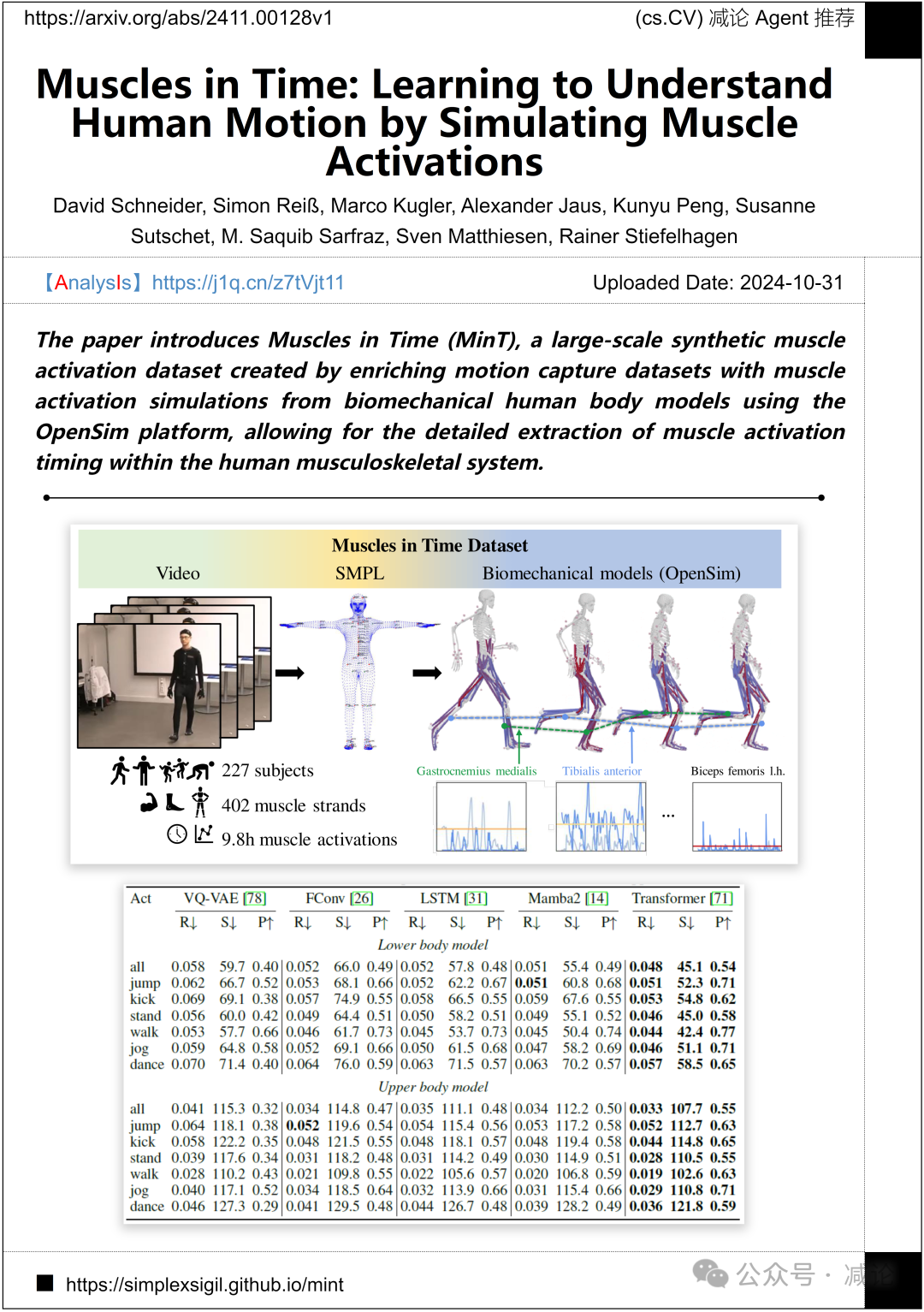
卡尔斯鲁厄理工学院,梅赛德斯–奔驰科技创新团队介绍了Muscles in Time(MinT)方法。该方法是一个大规模的合成肌肉激活数据集,通过在OpenSim平台上利用生物力学人体模型从运动捕捉数据集中丰富的肌肉激活模拟创建而成,允许详细提取人类肌肉骨骼系统内的肌肉激活时机。
【Bohr精读】
https://j1q.cn/z7tVjt11
【arXiv链接】
http://arxiv.org/abs/2411.00128v1
【代码地址】
https://simplexsigil.github.io/mint

EPFL和Ant Group的研究团队介绍了一种自集成高斯点阵(SE-GS)方法,通过训练一个由高斯参数空间中多样化时间样本引导的Σ模型来增强稀疏训练视图的新视图合成,这些样本是通过扰动基于动态更新的伪视图渲染缓冲区的不确定性计算的?模型生成的。这一方法是在Swiss Data Science Center的支持下开发的。
【Bohr精读】
https://j1q.cn/PS0zV2su
【arXiv链接】
http://arxiv.org/abs/2411.00144v1
【代码地址】
https://github.com/sailor-z/SE-GS
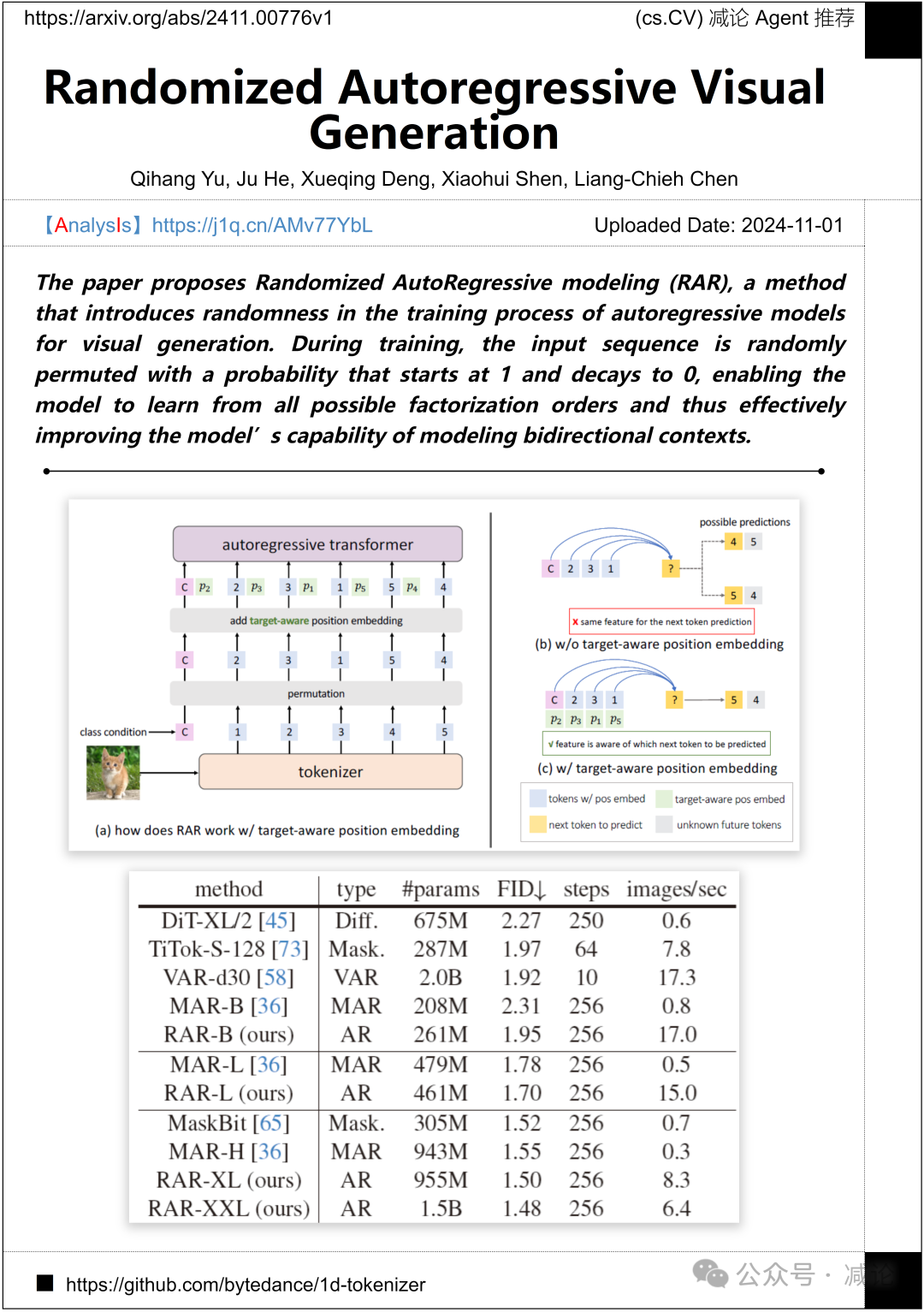
字节跳动团队提出了随机自回归建模(RAR)方法,这是一种在视觉生成的自回归模型训练过程中引入随机性的方法。训练过程中,输入序列以开始为1并衰减至0的概率被随机置换,使模型能够从所有可能的因子分解顺序中学习,从而有效地提高了模型建模双向上下文的能力。
【Bohr精读】
https://j1q.cn/AMv77YbL
【arXiv链接】
http://arxiv.org/abs/2411.00776v1
【代码地址】
https://github.com/bytedance/1d-tokenizer
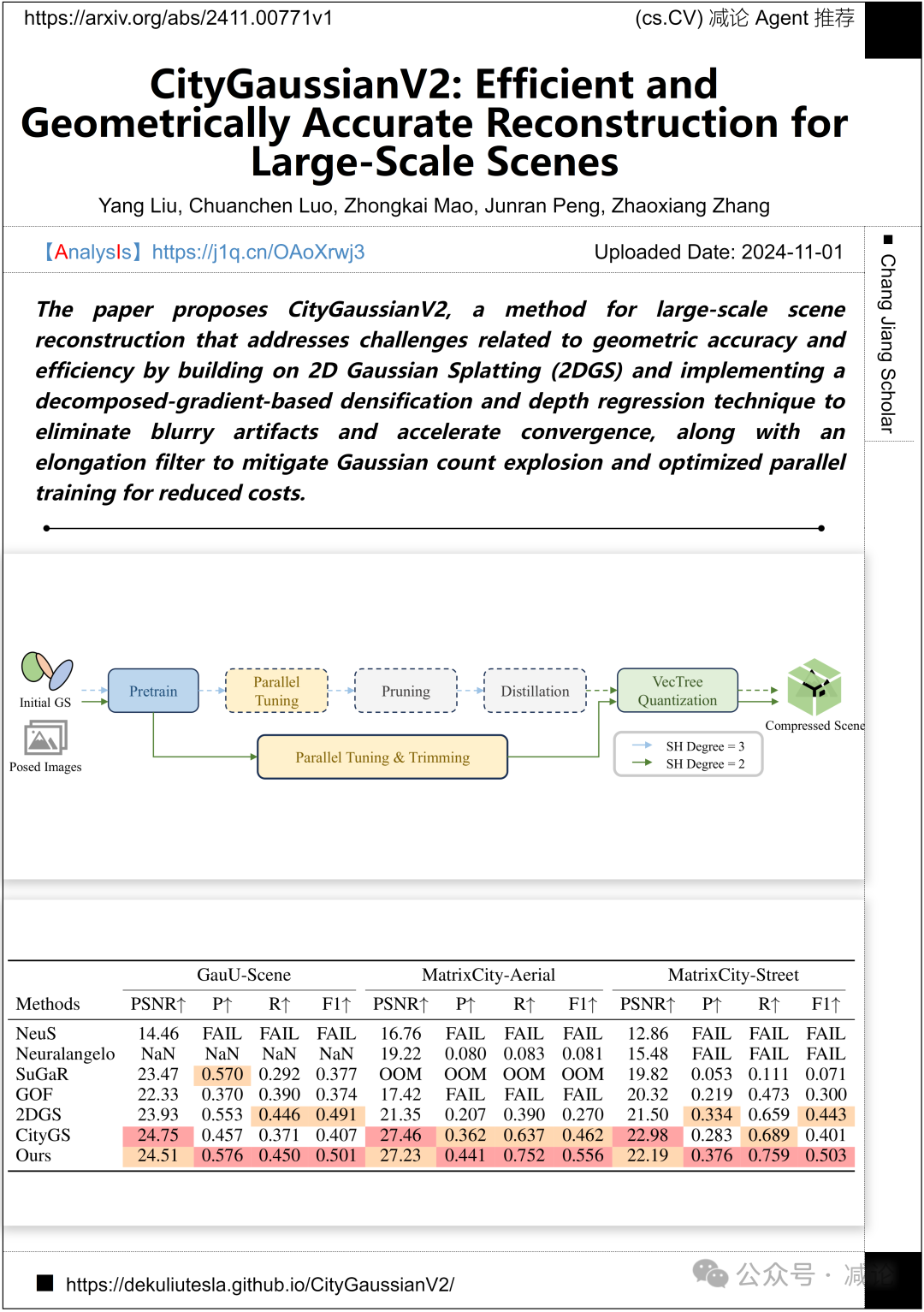
中国科学院自动化研究所、山东大学、北京科技大学提出了CityGaussianV2,这是一种用于大规模场景重建的方法。该方法通过基于2D高斯喷洒(2DGS)构建并实施分解梯度密集化和深度回归技术,以消除模糊伪影并加速收敛。同时,采用延伸滤波器来减轻高斯计数爆炸,并进行优化的并行训练以降低成本。
【Bohr精读】
https://j1q.cn/OAoXrwj3
【arXiv链接】
http://arxiv.org/abs/2411.00771v1
【代码地址】
https://dekuliutesla.github.io/CityGaussianV2/

卢森堡大学的研究团队提出了一种动态加权知识蒸馏(KD)框架,用于卫星载荷地球观测图像分类。他们利用EfficientViT和MobileViT作为教师模型来训练轻量级学生模型ResNet8和ResNet16,实现超过90%的准确率、精确度和召回率,同时显著降低计算复杂性和资源需求。
【Bohr精读】
https://j1q.cn/7lJaVJJR
【arXiv链接】
http://arxiv.org/abs/2411.00209v1
【代码地址】
https://github.com/ltdung/SnT-SENTRY
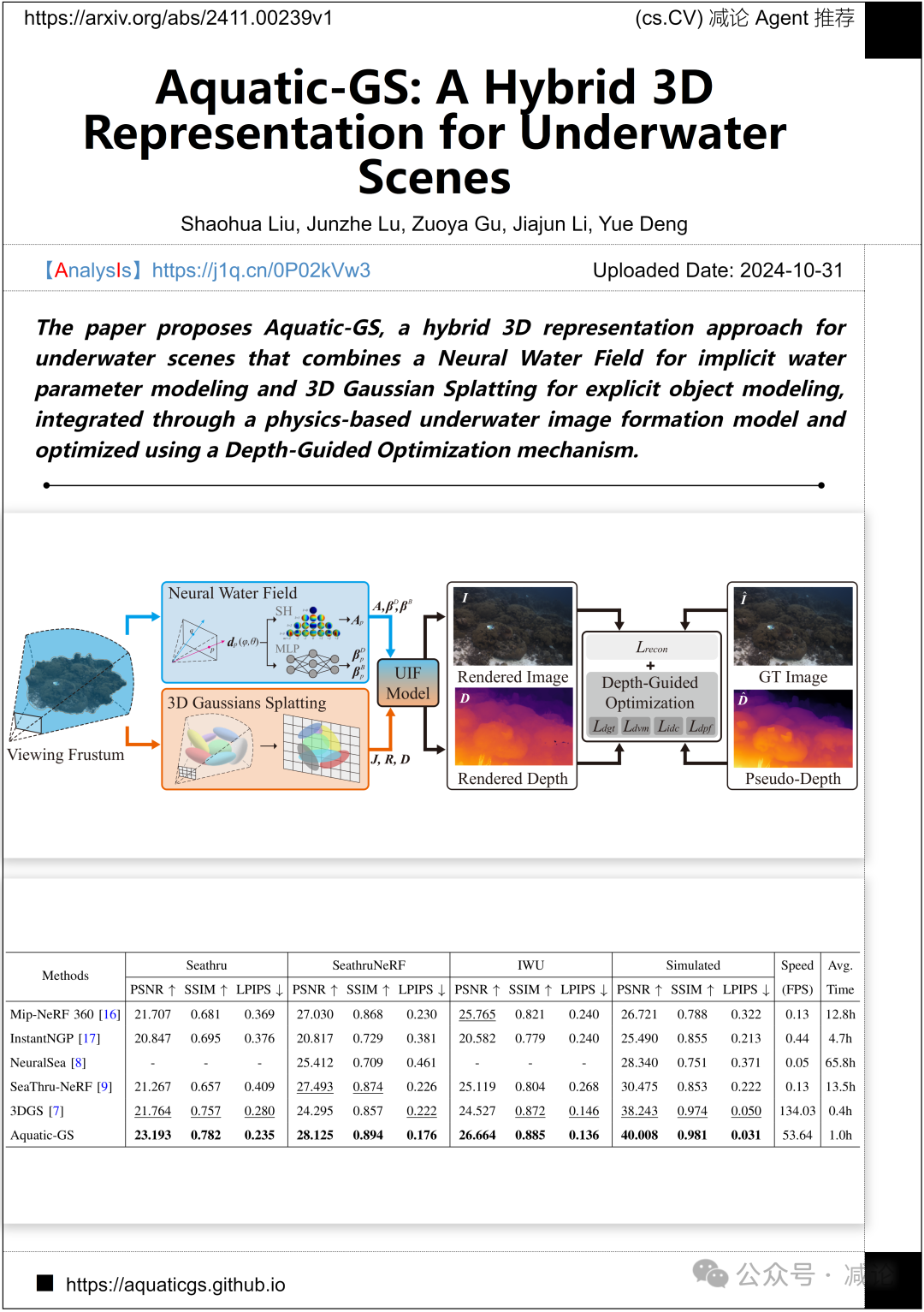
北京航空航天大学 Aquatic-GS 团队提出了 Aquatic-GS 方法,一种混合的三维表示方法,用于水下场景。该方法结合了神经水场用于隐式水参数建模和三维高斯飞溅用于显式对象建模,通过基于物理的水下图像形成模型进行集成,并使用深度引导优化机制进行优化。
【Bohr精读】
https://j1q.cn/0P02kVw3
【arXiv链接】
http://arxiv.org/abs/2411.00239v1
【代码地址】
https://aquaticgs.github.io
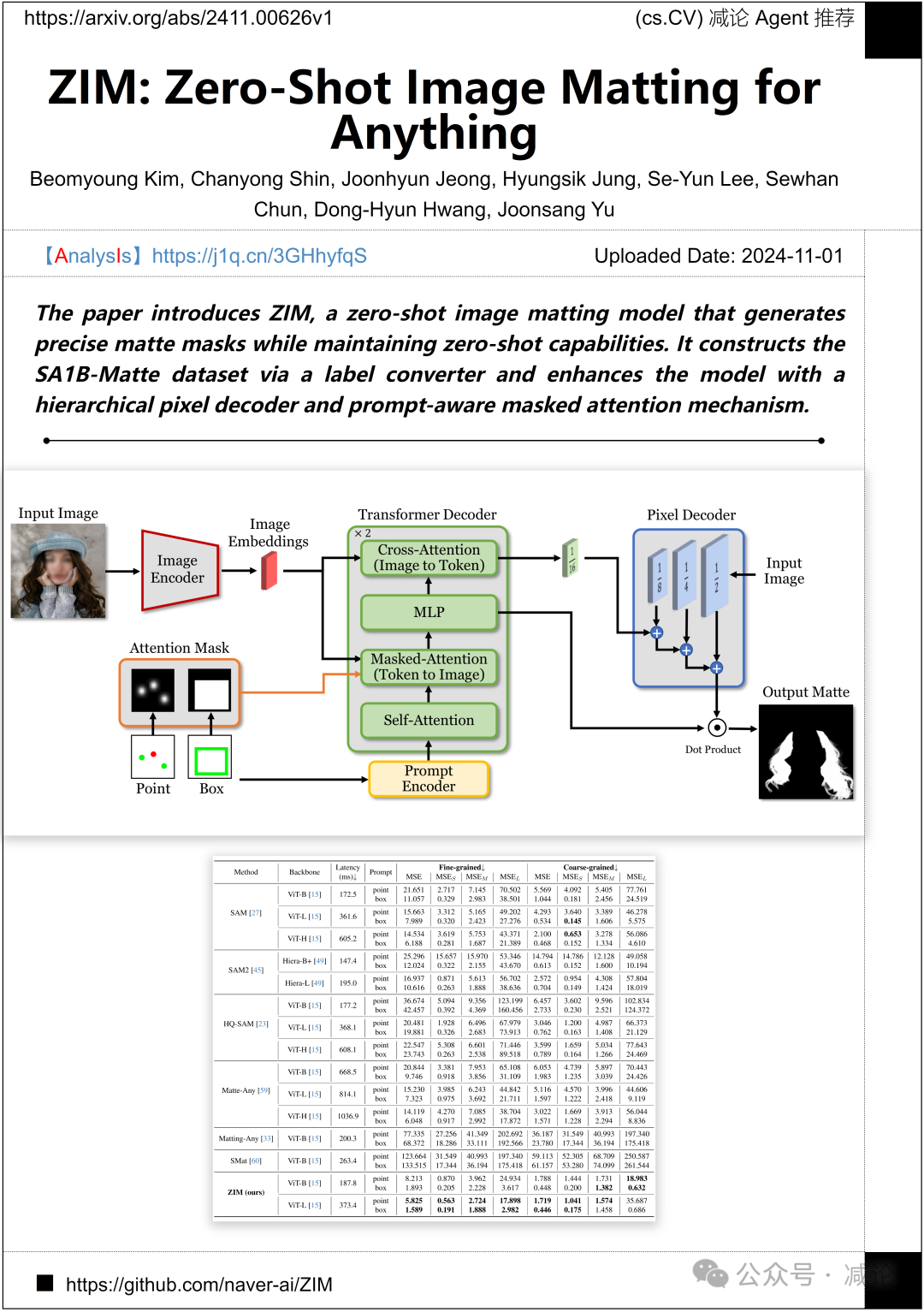
NAVER云,ImageVision团队 提出了ZIM,一种零样本图像抠图模型,能够生成精确的抠图遮罩并保持零样本能力。他们通过标签转换器构建了SA1B-Matte数据集,并通过分层像素解码器和提示感知掩码注意机制增强了模型。
【Bohr精读】
https://j1q.cn/3GHhyfqS
【arXiv链接】
http://arxiv.org/abs/2411.00626v1
【代码地址】
https://github.com/naver-ai/ZIM
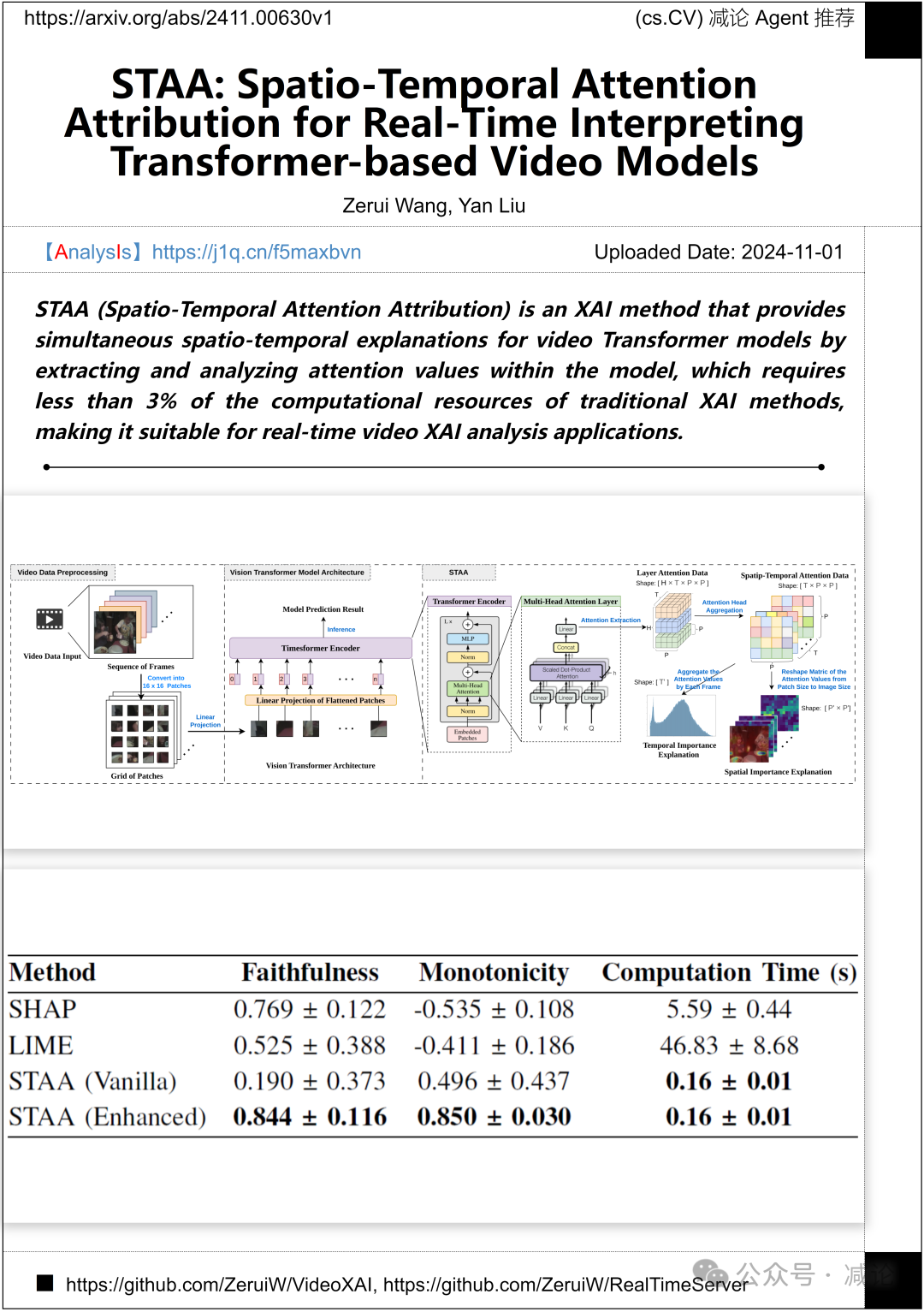
加州大学洛杉矶分校的研究团队提出了STAA(时空注意力归因)方法,通过提取和分析模型内的注意力值,为视频Transformer模型提供同时的时空解释。这一方法仅需传统XAI方法计算资源的不到3%,适用于实时视频XAI分析应用。
【Bohr精读】
https://j1q.cn/f5maxbvn
【arXiv链接】
http://arxiv.org/abs/2411.00630v1
【代码地址】
https://github.com/ZeruiW/VideoXAI, https://github.com/ZeruiW/RealTimeServer
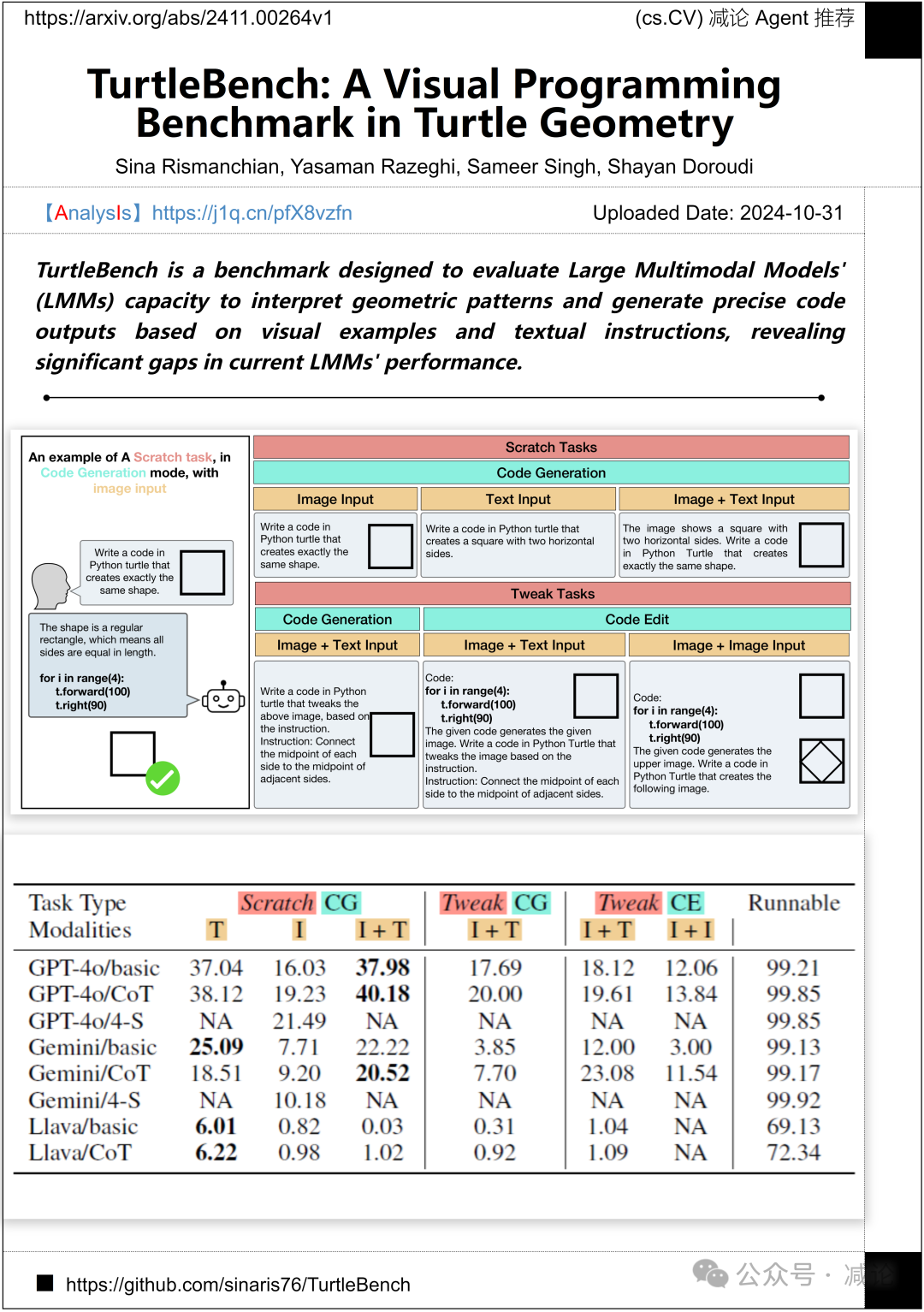
加州大学欧文分校的研究团队提出了TurtleBench基准测试,旨在评估大型多模态模型(LMMs)解释几何图案和生成精确代码输出的能力,基于视觉示例和文本说明,揭示当前LMMs性能中的重大差距。
【Bohr精读】
https://j1q.cn/pfX8vzfn
【arXiv链接】
http://arxiv.org/abs/2411.00264v1
【代码地址】
https://github.com/sinaris76/TurtleBench

伯恩茅斯大学,上海交通大学,拉筆大學的研究团队提出了PCoTTA框架,这是一个用于多任务点云理解中的持续测试时间适应的方法。该框架引入了自动原型混合、高斯散射特征移位和对比原型排斥,以动态地使模型适应不断变化的目标领域,同时减轻灾难性遗忘和错误累积。
【Bohr精读】
https://j1q.cn/CLBMuSa1
【arXiv链接】
http://arxiv.org/abs/2411.00632v1
【代码地址】
https://github.com/Jinec98/PCoTTA