
承接Part I: 增强深度学习模型评估以进行股市预测–Part I
训练和测试模型
我们使用自定义验证指标训练TFT模型。
步骤1:训练过程
from neuralforecast.models import TFT
from neuralforecast import NeuralForecast
from neuralforecast.losses.pytorch import HuberMQLoss
from pandas.tseries.offsets import CustomBusinessDay
from pytorch_lightning.loggers.tensorboard import TensorBoardLogger
from pytorch_lightning.callbacks import ModelCheckpoint, EarlyStopping
from tensorboard.backend.event_processing import event_accumulator
import os
import numpy as np
def create_custom_trading_days(start_date: str, end_date: str, market: str = "NYSE") -> CustomBusinessDay:
market_dates = obtain_market_dates(start_date, end_date, market)
trading_days = pd.DatetimeIndex(market_dates.index)
all_dates = pd.date_range(start=start_date, end=end_date, freq='B')
return CustomBusinessDay(holidays=all_dates.difference(trading_days))
def create_callbacks():
callbacks_list = []
for callback_name, params in config['other_parameters']['callbacks'].items():
if callback_name == 'EarlyStopping':
early_stopping = EarlyStopping(monitor=params['monitor'], patience=params['patience'], verbose=params['verbose'], mode=params['mode'])
callbacks_list.append(early_stopping)
if callback_name == 'ModelCheckPoint':
model_checkpoint = ModelCheckpoint(monitor=params['monitor'], mode=params['mode'], save_top_k=params['save_top_k'], verbose=params['verbose'])
callbacks_list.append(model_checkpoint)
return callbacks_list
def save_metrics_from_tensorboard(logger_dir):
metrics_dict = {}
os.makedirs(f'custom_validation_metric/tensorboard', exist_ok=True)
for event_file in os.listdir(logger_dir):
if not event_file.startswith('events.out.tfevents'):
continue
full_path = os.path.join(logger_dir, event_file)
ea = event_accumulator.EventAccumulator(full_path)
ea.Reload()
for tag in ea.Tags()['scalars']:
metrics_dict[tag] = ea.Scalars(tag)
for metric, scalars in metrics_dict.items():
plt.figure(figsize=(10, 5))
if metric == 'train_loss_step':
steps = [scalar.step for scalar in scalars]
else:
steps = list(range(len(scalars)))
if metric == 'valid_loss' or metric == 'ptl/val_loss':
values = [scalar.value for scalar in scalars]
steps, values = zip(*[(step, value) for step, value in zip(steps, values) if not np.isinf(value)])
else:
values = [scalar.value for scalar in scalars]
plt.plot(steps, values, label=metric)
plt.xlabel('Steps' if metric == 'train_loss_step' else 'Epoch')
plt.ylabel('Value')
plt.title(metric)
plt.legend(loc='upper right')
plt.savefig(f"custom_validation_metric/tensorboard/{metric.replace('/', '_')}.png")
plt.close()
keys_to_remove = {'loss'}
hyper_params = config['TFT_parameters']
other_param = config['other_parameters']
hyper_to_keep = {key: value for key, value in hyper_params.items() if key not in keys_to_remove}
logger = Tensor```python
BoardLogger('custom_validation_metric')
logger_dir = logger.log_dir
callbacks = create_callbacks()
nf = NeuralForecast(models=[TFT(loss=HuberMQLoss(quantiles=other_param['quantiles']),
valid_loss=RiskReturn(),
**hyper_to_keep,
futr_exog_list=futr_list,
hist_exog_list=hist_list,
logger=logger,
callbacks=callbacks,
enable_model_summary=True,
enable_checkpointing=True,
enable_progress_bar=True)],
freq=create_custom_trading_days(start_date=config['start_date'],
end_date=config['end_date']))
val_size = int(len(neuralforecast_train_df) * config['val_proportion_size'])
nf.fit(df=neuralforecast_train_df,
val_size=val_size,
use_init_models=True)
save_metrics_from_tensorboard(logger_dir)
NeuralForecast构建在PyTorch Lightning之上,PyTorch Lightning是PyTorch的包装器。因此,它允许我们传递额外的参数,如使用PyTorch Lightning定义的logger和callbacks。
我们使用HuberMQLoss()作为训练损失,并指定分位数quantile。RiskReturn()通过验证损失参数传递。

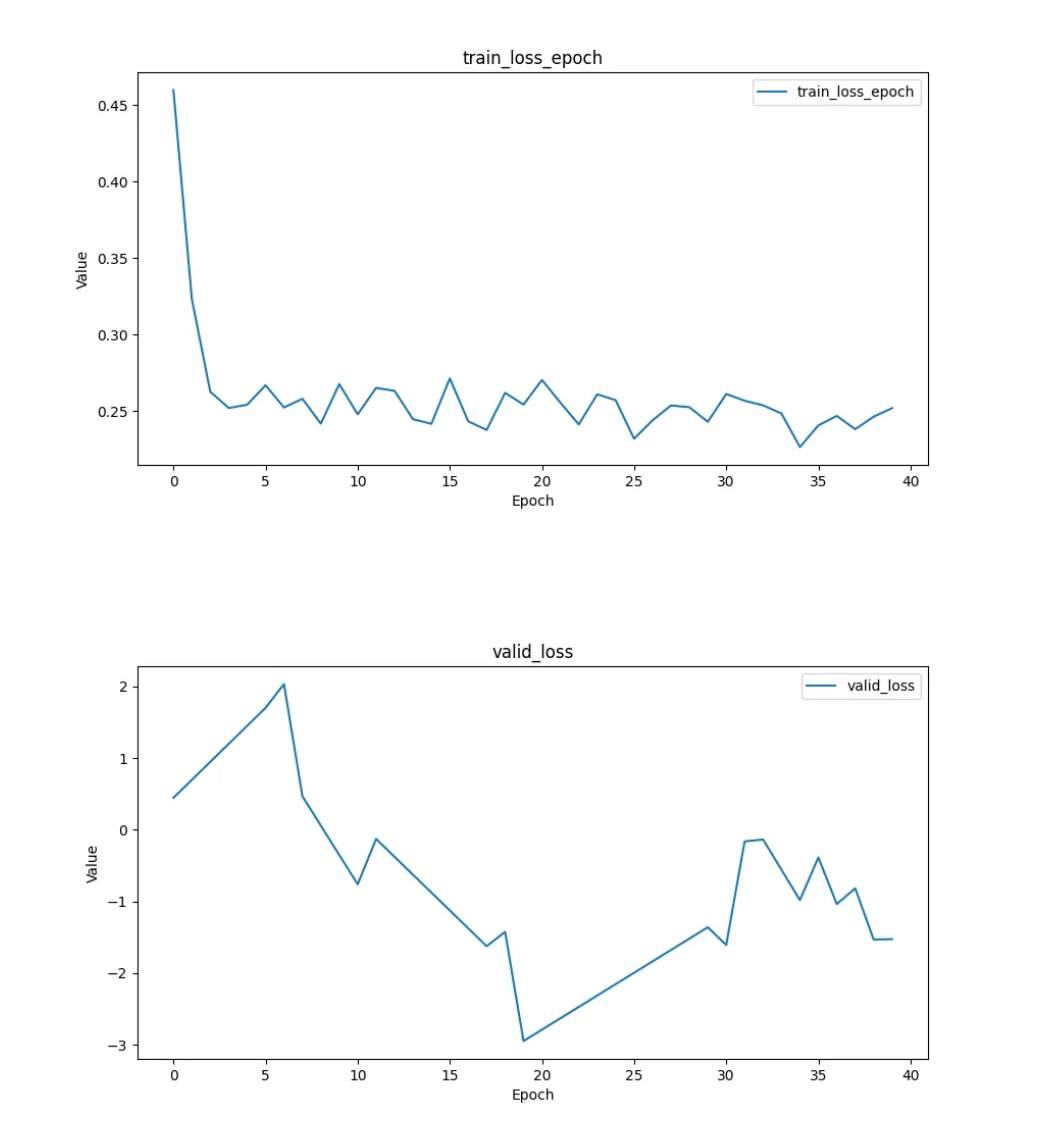
create_custom_trading_days()函数确保模型只考虑交易日。交易日与pandas频率中的商业频率B或每日频率D不同。create_callbacks()函数使用适当的参数值设置回调。save_metrics_from_tensorboard()函数从TensorBoard事件日志中提取每个周期的训练和验证损失值,并将它们保存为图像。
步骤2:测试过程
让我们看看我们的模型在样本外数据上的表现。
import torch
import json
def predict():
test_size = len(neuralforecast_test_df)
y_hat_test = pd.DataFrame()
current_train_data = neuralforecast_train_df.copy()
test_ftr = neuralforecast_test_df.reset_index(drop=True)
y_hat = nf.predict(current_train_data, futr_df=test_ftr)
y_hat_test = pd.concat([y_hat_test, y_hat.iloc[[-1]]])
for i in range(test_size - 1):
combined_data = pd.concat([current_train_data, neuralforecast_test_df.iloc[[i]]])
y_hat = nf.predict(combined_data, futr_df=test_ftr)
y_hat_test = pd.concat([y_hat_test, y_hat.iloc[[-1]]])
current_train_data = combined_data
y_hat_test.reset_index(drop=True, inplace=True)
all_columns_except_ds = [col for col in y_hat_test.columns if col not in 'ds']
median_column = [col for col in y_hat_test.columns if '-median' in col][0]
quantile_cols = [col for col in y_hat_test.columns if col not in [median_column, 'ds']]
return y_hat_test, all_columns_except_ds, median_column, quantile_cols
y_hat_test, all_columns_except_ds, median_column, quantile_cols = predict()
我们没有直接使用NeuralForecast的预测函数,因为NeuralForecast不支持对每个数据点进行n步预测。这种限制意味着我们必须一个接一个地进行预测(y_hat_test)。对于希望根据今天的数据知道明天回报的交易者来说,这是必要的。
def calculate_metric():
torch_target = torch.tensor(neuralforecast_test_df['y'].to_numpy(), dtype=torch.float32).unsqueeze(-1)
torch_predicted = torch.tensor(y_hat_test[all_columns_except_ds].to_numpy(), dtype=torch.float32)
metric_calc = MetricCalculation()
metric_calc.calculate_daily_returns(y=torch_target, y_hat=torch_predicted, lower_quantile=1, upper_quantile=3)
metrics = metric_calc.get_risk_rewards(is_checking_nb_trades=False)
return torch_target, metrics
torch_target, metrics = calculate_metric()
使用之前相同的函数get_risk_rewards,我们计算年化回报率、风险回报率和在测试期间执行的交易次数。
def print_metrics():
aggregate_metrics = {"annualized_return": metrics['annualized_return'].item(),
"actual_annualized_return": actual_annualized_return,
"return_on_risk": metrics['return_on_risk'].item(),
"actual_return_on_risk": actual_return_on_risk,
"nb_of_trades": metrics["nb_of_trades"],
'first_last_ds': (first_date, last_date)}
print(f'n{json.dumps(aggregate_metrics, indent=4)}n')
first_date = (neuralforecast_test_df['ds'].iloc[0]).strftime("%Y-%m-%d")
last_date = (neuralforecast_test_df['ds'].iloc[-1]).strftime("%Y-%m-%d")
nb_days = len(neuralforecast_test_df)
spy_data = pd.read_csv('custom_validation_metric/SPY.csv')
first_value = spy_data.loc[spy_data['ds'] == first_date, 'open'].iloc[0]
last_value = spy_data.loc[spy_data['ds'] == last_date, 'close'].iloc[0]
actual_annualized_return = (last_value / first_value) ** (252 / nb_days) - 1
std_daily_return = neuralforecast_test_df['y'].std()
actual_annualized_risk = std_daily_return * (252 ** 0.5)
actual_return_on_risk = actual_annualized_return / actual_annualized_risk
print_metrics()
为了进行比较,我们在同一时期计算了实际年化回报率和实际风险回报率。这是通过实施买入并持有策略,然后计算年化每日标准差来实现的。
最后,我们打印指标。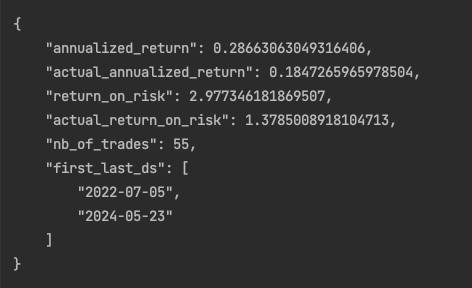
def plot_predictions():
plt.figure(figsize=(10, 6))
plt.plot(neuralforecast_test_df['ds'], neuralforecast_test_df['y'], color='black', label='Actual')
plt.plot(y_hat_test['ds'], y_hat_test[median_column], label='Predicted', color='blue')
plt.fill_between(y_hat_test['ds'], y_hat_test[quantile_cols[0]], y_hat_test[quantile_cols[-1]], color='gray', alpha=0.5)
plt.xlabel('Date')
plt.ylabel('Output')
plt.title('Actual vs Predicted Values over time')
plt.legend()
plt.savefig(os.path.join(f'custom_validation_metric', 'actual_vs_predicted_test.png'))
plt.close()
plot_predictions()
我们生成一个图表,将实际值(黑线)与预测的中值(蓝线)进行比较。它还以灰色阴影区域表示0.05和0.95分位数之间的区域,代表90%的预测区间。这种可视化使我们能够看到测试集中的预测值与实际值的吻合程度。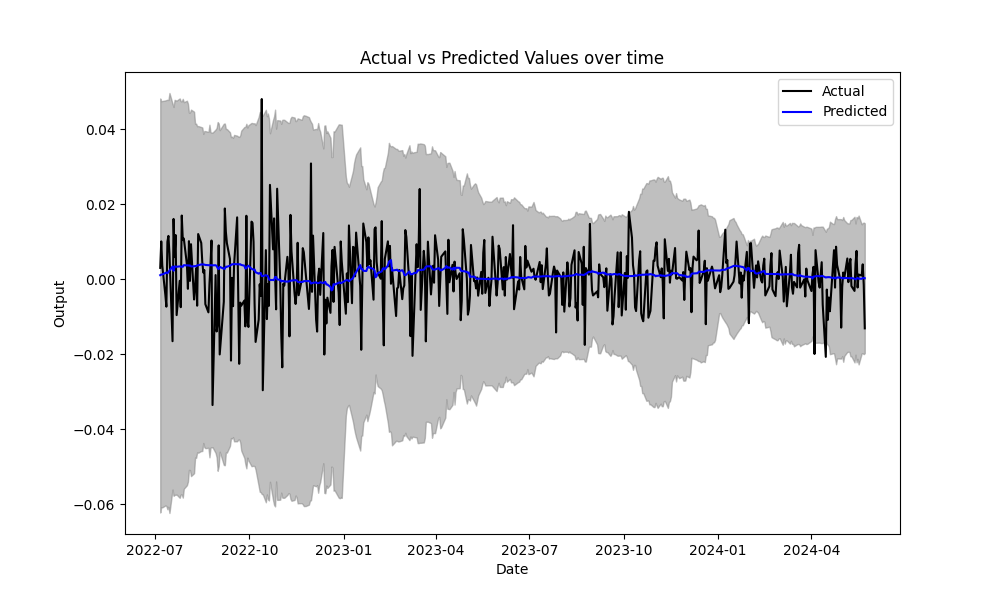
解释结果
我们的策略结果良好,年化回报率为28.66%,风险回报率为2.97。这一表现超过了同期标准普尔500指数的买入并持有策略,该策略的年化回报率为18.47%,风险回报率为1.37。这是我们自定义验证指标的第一个好结果。
然而,有重要的考虑因素:在测试期间,我们仅在476个交易日执行了55笔交易。图表显示,模型没有很好地捕捉到潜在的市场模式。它表现得更像是一个n天移动平均线。0.05和0.95分位数之间的范围比实际的90%置信区间更宽。在第一年,预测的分位数超过了0.03和-0.03,捕捉到了超过90%的实际值。模型在短短20个周期内迅速收敛,表明模型可能缺乏复杂性。
这些观察结果表明,模型过于简单,可能是由于特征不足或超参数值过小,例如隐藏层大小过小。为了增加交易次数并提高性能,我们可以考虑开发一个多变量时间序列模型。额外的证券不应该与SPY过于相关,例如债券或商品,其相关系数在-0.5到0.5之间。这种方法可以帮助我们捕捉潜在的市场模式。
结束语
在本文中,我们看到像均方根误差(RMSE)和均方误差(MSE)这样的标准验证指标对于深度学习模型中的股票市场预测来说并不是最好的。为了解决这个问题,我们提供了一个逐步指南,用于实施和训练一个具有自定义验证指标的深度学习模型,以做出更好的交易决策。即使这种方法有潜力,但结果并不确定。为了改进这种方法,增加更多特征,使用多变量时间序列数据,可能会有所帮助。