
本文提出了一种名为xLSTM-Mixer的新型多变量时间序列预测模型,该模型结合了线性预测和xLSTM模块,通过时间、联合和视图混合来捕捉复杂的时间依赖关系和变量间关系。
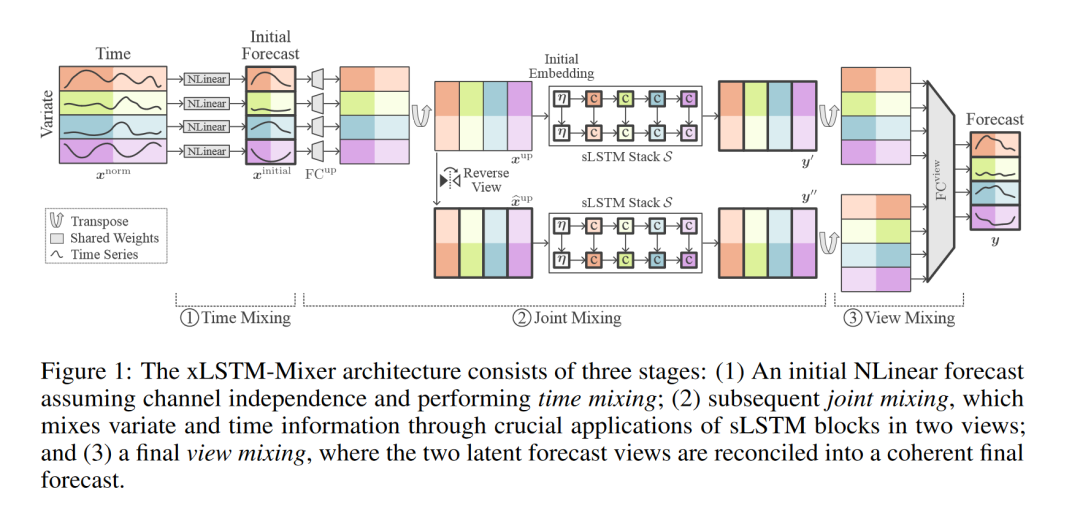

1. 引言
时间序列数据广泛存在于医疗、制造、交通、金融、音频处理和天气建模等多个关键领域。尽管时间序列预测在过去几十年取得了显著进展,但该领域仍远未得到解决。现有模型和方法组合的改进不断涌现,表明机器学习模型的预测质量仍有很大的提升空间。
传统的循环神经网络(RNNs)及其强大的后继者是基于深度学习的时间序列预测的自然选择。然而,大型Transformer模型在时间序列任务中的应用越来越广泛,包括预测。然而,它们通常需要大量的数据集才能成功训练,限制了它们的应用范围。此外,由于注意力机制的成本与变量数和时间步数的平方成正比,因此它们在处理长序列时效率低下。
近年来,递归模型和状态空间模型(SSMs)因其能够克服Transformer模型的局限性而重新受到关注。Beck等人(2024)通过借鉴应用于自然语言处理领域的Transformer模型的经验,提出了扩展长短期记忆(xLSTM)模型作为当前序列模型的可行替代方案。
本文提出了一种新的基于递归深度学习方法的时间序列预测方法——xLSTM-Mixer。该方法通过精心设计的时间、变量和多视图混合,增强了高度表达的xLSTM架构。这些操作通过权重共享来规范训练并限制模型参数,有效地提高了准确预测所需特征的学习。
2. 背景
2.1 符号
在多变量时间序列预测中,模型接收一个时间序列 X = (x1, …, xT) ∈ RVXT,其中包含 T 个时间步长,每个时间步长包含 V 个变量。预测器需要预测未来值 Y = (xT+1, …, xT+H) ∈ RV XH,直到范围 H。变量(也称为通道)可以是任何标量测量值,例如道路占用率或电厂的油温。假设测量是联合进行的,以便 T + H 个时间步长反映了规则采样的多变量信号。
2.2 扩展长短期记忆(xLSTM)
Beck等人(2024)提出了由两个构建块组成的 xLSTM 架构,即 sLSTM 和 mLSTM 模块。为了在每个步骤和整个计算序列中利用 xLSTM 的全部表达能力,我们采用了一堆 sLSTM 块,而没有 mLSTM 块。后者由于其对序列元素的独立处理,不适合联合混合,因为它无法直接学习它们之间的任何关系。
2.3 时间序列模型中的通道独立性和混合
许多研究已经探讨了联合学习时间和变量维度的表示是否有益。直观地说,因为联合混合的表达能力更严格,人们可能认为它应该始终受到青睐。实际上,许多方法(例如 Temporal Convolutional Networks (TCN)、N-BEATS、N-HiTS 和许多 Transformer 模型,包括 Temporal Fusion Transformer (TFT)、Autoformer 和 FEDFormer)都使用了联合混合。
然而,独立处理输入数据的切片假设对时间或变量位置的不变性,并作为过度拟合的强大正则化,类似于 CNN 中的核。
3. xLSTM-Mixer
本章详细介绍了xLSTM-Mixer模型的架构和工作原理,该模型旨在通过混合时间序列数据的不同方面来实现准确的多变量时间序列预测。
3.1 关键组件1:归一化和初始线性预测
归一化已成为现代深度学习架构中的一个基本组成部分。对于时间序列预测,可逆实例归一化(RevIN)是一种提高预测性能的通用方法。RevIN通过使用每个时间序列实例的均值和方差进行归一化,并通过可学习的标量进行缩放和偏移,从而对每个时间序列实例进行归一化。
xLSTM-Mixer采用RevIN作为其归一化方法,并将其应用于整个流程的最后,以获得最终预测。在xLSTM-Mixer中,典型的混合架构中的跳过连接由RevIN、NLinear预测中的归一化以及每个sLSTM块内的完整跳过连接所取代。
研究表明,配备适当归一化方案的简单线性模型本身已经是相当不错的长期预测器。我们的观察证实了这一发现。因此,我们首先通过计算以下公式,分别处理每个变量:
ginitial = NLinear(xnorm) = FC(xnorm - xpmm) + ITnorm
其中,FC(.)表示带有偏置项的全连接线性层。跨变量共享此模型可以限制参数数量,而权重绑定作为一种有用的正则化手段。我们将对初始预测的质量进行进一步的调查。
3.2 关键组件2:sLSTM改进
虽然NLinear预测初步捕获了历史和未来时间步之间的基本模式,但其质量本身不足以满足当今具有挑战性的多变量时间序列数据集的需求。因此,我们使用强大的sLSTM块对其进行改进。
作为第一步,至关重要的是增加数据的嵌入维度,以提供足够的潜在维度D供sLSTM单元使用:
xUP = FCUP(ginitial)
这种预上投影类似于在SSM中通常执行的操作。我们跨变量共享FCUP以执行类似于初始预测的时间混合。请注意,此步骤不会保持嵌入标记维度内的时序顺序,而是将其嵌入到更高的潜在维度中。
sLSTM块堆栈S(.)将xUP从定义的Eq. 1到8转换为最终的隐藏状态。递归模型按变量顺序遍历数据,即每个标记代表来自单个变量的所有时间步长。sLSTM块学习隐藏在数据中沿时间和变量维度的复杂非线性关系。隐藏状态的混合仍然限于连续维度的块,有助于高效的学习和推理,同时允许在递归处理期间进行有效的跨变量交互。
遍历变量具有线性运行时间扩展的优势,即在参数数量恒定的情况下,变量数量呈线性扩展。然而,它也带来了可能固定次优变量顺序的成本。虽然这在经验上不是一个显著的限制,但我们将其留作未来工作的研究内容。除了大的嵌入维度外,我们还观察到高数量的头对于有效的预测至关重要。
sLSTM单元的第一个隐藏状态ht-1必须在处理每个标记序列之前进行初始化。扩展这些块的初始描述,我们建议学习一个单一的初始嵌入标记n ∈ RD,该标记被添加到每个编码的时间序列xUP中。这些初始嵌入借鉴了大型语言模型中的最新进展,其中可学习的“软提示”标记用于调节模型并提高其生成连贯输出的能力。这些标记使模型能够根据特定数据集特征调整其初始内存表示,并与时间和变量数据动态交互。软提示可以通过反向传播轻松优化,并且开销很小。
3.3 关键组件3:多视图混合
为了进一步规范sLSTM的训练,我们计算原始嵌入x”P和反转嵌入x”U的预测,其中潜在维度的顺序(包括n的表示)被反转。在共享权重的同时学习两个视图的预测有助于学习更好的表示。众所周知,这种多任务学习设置有利于训练。最终预测是通过两个连接预测的线性投影FCview获得的,再次按变量计算。具体来说,我们计算:
norm = FCview(y', y")
其中,y’ = S(x”P)且y” = S(x”U)。
在去归一化协调后的预测后,获得最终预测:
y = RevIN-1(ynorm)
4.实验评估
本章旨在评估xLSTM-Mixer的预测能力,提供对其性能的全面了解。为此,我们进行了一系列实验,重点关注长期预测,并遵循Das等人(2023年)和Chen等人(2023c)的工作。此外,我们还进行了广泛的模型分析,包括消融研究以识别xLSTM-Mixer各个组件的贡献,对初始嵌入标记的检查,超参数敏感性分析,以及对其鲁棒性的研究。

数据集: 我们遵循Wu等人(2021年)和Zhou等人(2021年)建立的基准程序,以确保最佳的向后和未来可比性。我们使用的数据集总结在表1中。
训练:我们遵循预测文献中的标准做法,使用均方误差(MSE)和平均绝对误差(MAE)来评估长期预测。基于我们的实验,我们使用MAE作为训练损失函数,因为它产生了最佳结果。为了在特征之间保持一致性,对数据集进行了标准化。有关超参数选择、指标和实现的更多详细信息,请参见附录A.1。
基线模型:我们将xLSTM-Mixer与以下模型进行了比较:
-
循环模型:xLSTMTime(Alharthi & Mahmood, 2024)和LSTM(Hochreiter & Schmidhuber, 1997) -
基于多层感知器(MLP)的模型:TimeMixer(Wang et al., 2024a)、TSMixer(Chen et al., 2023c)、DLinear(Zeng et al., 2023)和TiDE(Das et al., 2023) -
基于Transformer的模型:PatchTST(Nie et al., 2023)、iTransformer(Liu et al., 2023)、FEDFormer(Zhou et al., 2022)和Autoformer(Wu et al., 2021) -
卷积架构:MICN(Wang et al., 2022)和TimesNet(Wu et al., 2022)
4.1 长期时间序列预测
我们展示了xLSTM-Mixer与先前模型的性能比较。如表2所示,xLSTM-Mixer在广泛的基准测试中始终提供高度准确的预测。它在28个案例中有18个案例的MSE最佳,以及在28个案例中有22个案例的MAE最佳,证明了其在长期预测方面的优越性能。特别是,xLSTM-Mixer表现出卓越的预测精度,这从其在所有数据集上的强大MAE性能中得到了证明。值得注意的是,在Weather数据集上,xLSTM-Mixer将MAE降低了2%(与xLSTMTime相比)和4.6%(与TimeMixer相比)。同样,在ETTm1数据集上,xLSTM-Mixer在MAE上优于TimeMixer 2.4%,并且与xLSTMTime相比具有强大的竞争优势。尽管在处理异常值方面,xLSTM-Mixer在Traffic和ETTh2数据集上的表现略逊一筹,但它仍然具有很强的竞争力,并且优于大多数基线模型。这表明,尽管存在这些少数情况,xLSTM-Mixer仍然可以在长期预测中始终提供最先进的性能。图2展示了几个基线模型的定性检查,包括在sLSTM改进之前提取的初始预测。在这个比较中,回溯窗口和预测范围都固定在96。
4.2 模型分析
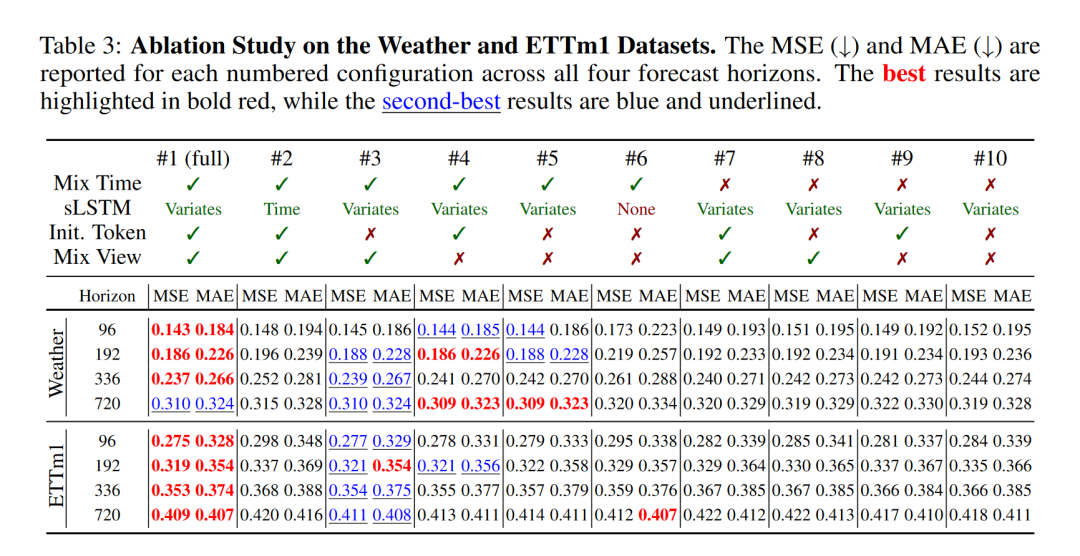
消融研究:为了评估xLSTM-Mixer中每个组件对其整体预测性能的贡献,我们进行了一项广泛的消融研究。结果表明,所有组件都对xLSTM-Mixer的有效性做出了贡献,完整配置产生了最佳结果。此外,我们确定sLSTM块和时间混合是确保跨数据集和预测范围高准确性的关键组件。
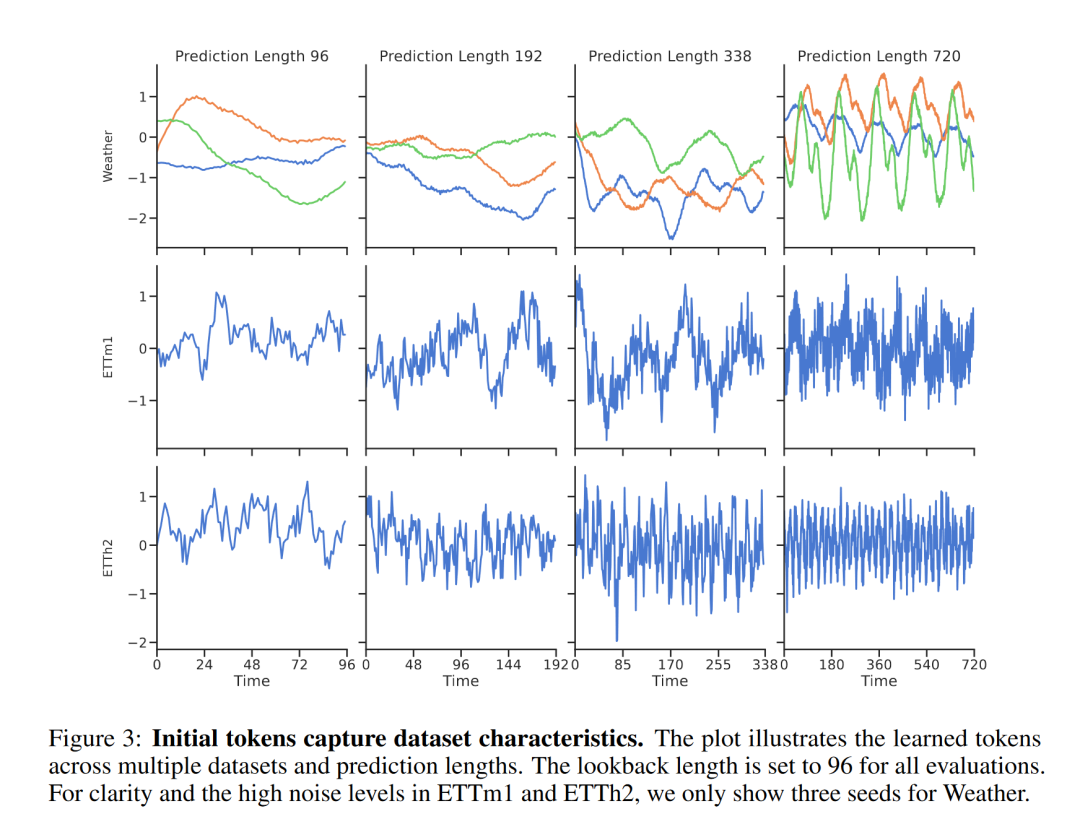
初始标记嵌入:我们定性地检查了多个数据集上初始标记嵌入n的解码,以进一步了解和解释xLSTM-Mixer学习的初始化。n被转换为预测y,通过sLSTM堆栈S并应用多视图混合。FCView的输出结果可以解释为用于初始化sLSTM块的条件预测。图3显示了在Weather、ETTm1和ETTh2数据集上,初始标记嵌入在不同预测范围内的学习模式。随着预测范围的增加,我们观察到更长的时间跨度,最终揭示了潜在的季节性模式和相应的数据集动态。
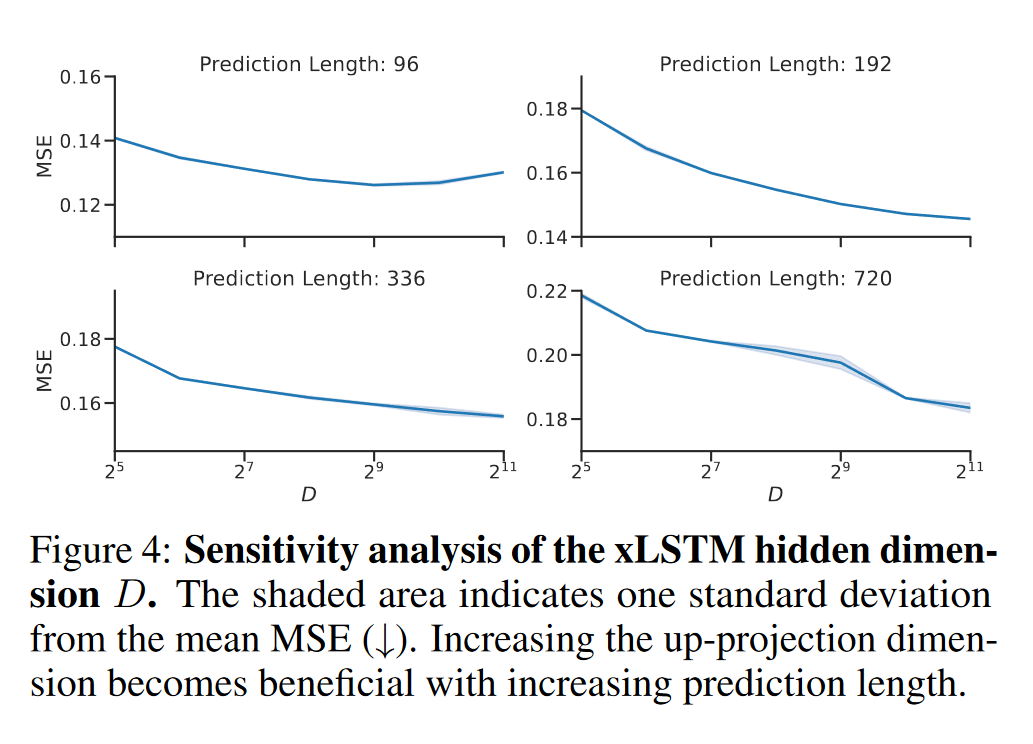
对xLSTM隐藏维度的敏感性:在图4中,我们可视化了xLSTM-Mixer在电力数据集上的性能,随着通过FCUP实现的sLSTM嵌入(隐藏)维度的增加。结果表明,更大的隐藏维度始终增强了模型的性能,特别是在较长的预测范围内。这表明更大的嵌入维度使xLSTM-Mixer能够更好地捕捉时间序列数据在更长范围内的更高复杂性,从而提高了预测精度。
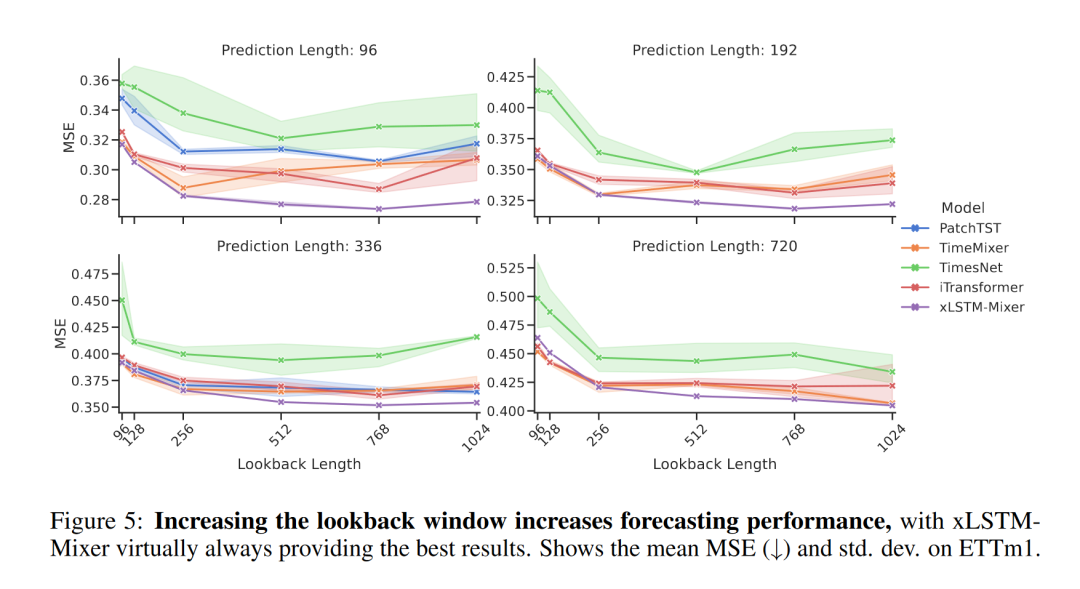
对回溯长度的鲁棒性:图5展示了xLSTM-Mixer在不同回溯长度和预测范围内的性能。我们观察到,xLSTM-Mixer可以有效地利用比基线模型更长的回溯窗口,尤其是在与基于Transformer的模型进行比较时。这种优势源于xLSTM-Mixer避免了自注意力,使其能够有效地处理扩展的回溯长度。此外,xLSTM-Mixer表现出稳定且一致的性能,方差低。这些结果证实了增加回溯长度可以提高预测精度,并增强鲁棒性,特别是在较长的预测范围内。
5. 相关工作
5.1 时间序列预测
从早期的统计方法(如 ARIMA)到基于深度学习的当代模型,时间序列预测研究经历了漫长的发展历程。四种主要的架构家族占据了中心地位:基于递归、卷积、多层感知器(MLP)和 Transformer 的模型。
5.2 用于时间序列的 xLSTM 模型
Alharthi 和 Mahmood(2024)已经对将 xLSTM 应用于时间序列进行了一些初步实验,他们提出了 xLSTMTime 模型。虽然它展示了有希望的预测性能,但这些初步调查并未超过更强的近期模型,例如 TimeMixer,并且报告的性能难以再现。
6. 结论
本文介绍了 xLSTM-Mixer,这是一种将线性预测与使用 xLSTM 块进行进一步改进相结合的方法。我们的架构有效地整合了时间、联合和视图混合,以捕捉复杂的依赖关系。在长期预测中,xLSTM-Mixer 始终实现了最先进的性能,在 56 个案例中有 41 个案例优于先前的方法。此外,我们详细的模型分析提供了有关每个组件贡献的宝贵见解,并证明了其对不同超参数设置的鲁棒性。