
论文标题:BPQP: A Differentiable Convex Optimization Framework for Efficient End-to-End Learning
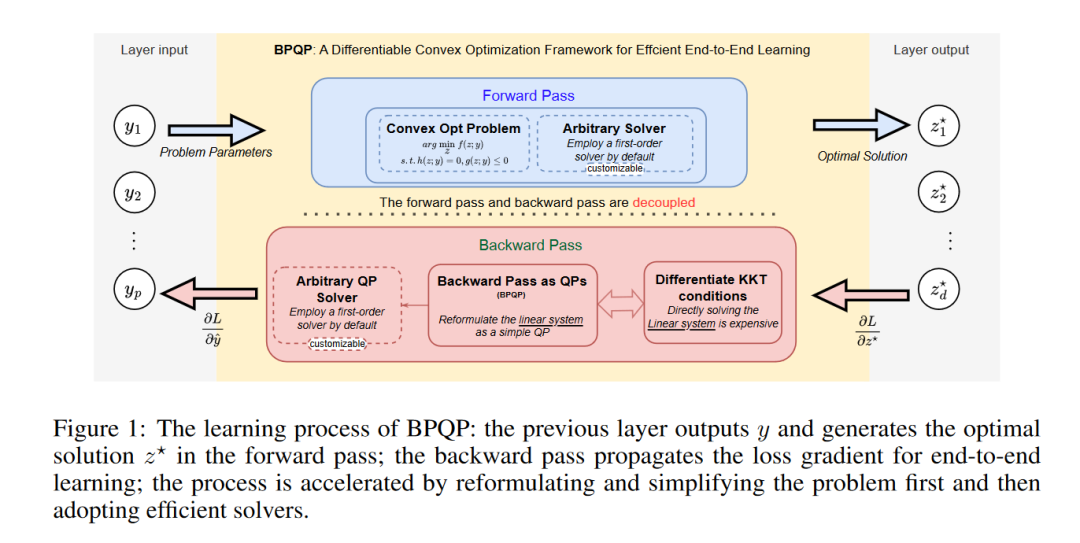
本文来自UC Berkekey, 南开大学以及微软亚研院,文章介绍了一种名为 Backward Pass as a Quadratic Programming (BPQP) 的新型可微分凸优化框架,该框架旨在提高端到端学习任务中凸优化层的计算效率。
1. 引言
近年来,深度神经网络被广泛应用于数据驱动的决策问题,为端到端学习任务生成最终决策。除了显式的前向函数外,网络中的某些层可能表现出隐式输出的行为,例如数学优化问题的解,这些层被称为可微分优化层。这些层将输入映射到最优解,可以引入领域特定知识、物理结构和先验等有用的归纳偏差,从而实现更准确和可靠的决策。这种方法已被整合到深度声明式网络中,并在能源最小化和预测-优化等应用中被证明是有效的。

优化问题通常缺乏通用解析解,因此需要更复杂的方法来计算相关参数的梯度。这些方法可以分为显式展开和隐式方法两大类:
-
显式方法 通过展开优化过程的迭代,将决策变量的最终迭代结果作为优化问题的代理解,构建从参数到代理参数的显式计算图,然后计算相关梯度。这类方法通常适用于无约束优化,直接应用于约束优化计算成本较高,因为需要将决策变量投影到可行域内。 -
隐式方法 利用隐函数定理将决策变量与其他参数关联起来。这些方法将定理应用于凸优化的 KKT 条件。特定性问题驱动的方法通常针对凸优化中的特定问题(如二次规划)进行优化,具有良好的效率,但缺乏通用性。而通用性方法虽然提供了更通用的梯度推导方案,但在反向传播过程中效率低下。
为了在凸优化层中实现快速、可处理的微分,并进一步增强端到端学习范式的能力,本文提出了一种通用的、一阶可微分的凸优化框架 BPQP。该框架的核心思想是:
-
将反向传播过程简化为二次规划问题。具体来说,BPQP 通过利用 Karush-Kuhn-Tucker (KKT) 矩阵的结构特性,将反向传播过程重新表述为一个简化的、分离的二次规划问题。这使得前向和反向传播过程分离,并允许使用任何最先进的求解器(包括默认的一阶优化算法 ADMM)来计算反向传播梯度。 -
提高梯度计算效率。BPQP 显著提高了整体计算时间,与其他可微分优化层相比,在线性规划、二次规划和二阶锥规划等任务上的执行速度提高了数倍甚至数十倍。
BPQP 的主要优势包括:
-
新颖的反向传播重新表述: 将反向传播过程与凸优化层的前向传播过程分离,并将反向传播过程重新表述为一个简单的二次规划问题,避免了对涉及 KKT 矩阵的线性系统的求解。 -
高效的梯度计算: 在大规模数据集上,BPQP 的计算效率显著优于现有方法。 -
灵活的求解器选择: BPQP 可以容纳任何通用凸优化求解器来集成可微分层进行端到端训练。
2. 相关工作
显式方法 主要通过展开优化过程的迭代来解决优化问题。这类方法通常需要将决策变量投影到可行域内,计算成本较高。Alt-Diff 是一种新颖的展开解决方案,它将约束与优化分离,显著降低了计算成本。
隐式方法 利用隐函数定理来关联决策变量与其他参数。
-
OptNet 提出了一种可微分的批量 GPU 二次规划求解器,并开发了 ADMM 层来简化反向传播过程。 -
Diffcp 通过对同质自对偶嵌入的残差映射进行隐式微分来计算凸锥规划的导数。 -
CVXPY 采用类似的方法,并通过 SCS 计算梯度。 -
JaxOpt 提出了一种简单的方法,在任何现有求解器之上添加隐式微分。
BPQP 基于隐式方法,通过将反向传播过程重新表述为一个简化的、分离的二次规划问题来提高效率。
3. 背景
3.1 可微分凸优化层
可微分凸优化层将输入 y ∈ R^p 映射到输出 z* ∈ R^d,输出 z* 是以下凸优化问题的解:
z*(y) = arg min f_y(z)
s.t. h_y(z) = 0, g_y(z) ≤ 0
其中,y 是目标函数和约束的参数向量,z 是优化变量,f、g 和 h 分别是凸函数和仿射函数。
参数向量 y 的梯度可以通过链式法则与隐函数定理 (IFT) 相结合来计算。在深度学习架构中,优化层与显式层一起整合到一个端到端的框架中。给定全局损失函数 L,损失函数对 y 的导数可以表示为:
?L/?y = (?L/?z*) (?z*/?y)
其中,?L/?z* 可以通过应用于显式层的传统自动微分技术轻松获得。然而,计算 ?z*/?y,即隐式优化层的梯度,会遇到挑战。
将优化层视为隐函数 F(z*, y) = 0,OptNet 等研究利用 IFT 对凸优化问题的 KKT 条件进行推导。
隐函数定理 (IFT):
?z*/?y = - [J_F(z)]^{-1} J_F(y)
其中,J_F(z) 和 J_F(y) 分别是 F 关于 z 和 y 的雅可比矩阵。
需要注意的是,对 KKT 条件进行微分需要计算前向传播中的最优值 z*,并在反向传播中解决涉及雅可比矩阵的线性系统。这两个阶段(前向和反向)计算量都很大,尤其是对于大规模问题。
3.2 通过 KKT 条件进行微分
为了更有效地对 KKT 条件进行微分,CvxpyLayer 采用 LSQR 技术来加速稀疏优化问题的隐式微分。然而,该方法对于非稀疏的一般情况可能效率不高。
本文旨在开发一种新方法,以提高微分过程的计算速度,特别是对于一般的大规模凸优化问题。
4. 方法
4.1 反向传播作为二次规划
BPQP 将反向传播过程重新表述为一个二次规划问题。具体来说,给定一个一般的二次规划问题:
minimize -P'z + q'z
s.t. A'z = b', G'z ≤ c', z ∈ Z
其中,z ∈ R^d,P’ ∈ S^d,q’ ∈ R^d,A’ ∈ R^{m×d},b’ ∈ R^m,G’ ∈ R^{n×d},c’ ∈ R^n。
其 KKT 条件为:
P' G'(z')^T A'(z')^T 0 0
G'(z') D(c') 0 0 0
A'(z') 0 0 0 0
0 0 0 -D(c') 0
0 0 0 0 0
BPQP 将上述 KKT 条件与公式 (3) 进行比较,并得出以下定理:
定理 1: 假设定义 1 中的凸优化问题不是原始不可行的,并且相应的雅可比向量 V_yL 存在,则 V_yL 由以下等式约束二次规划问题的最优解 [z, λ, ν] 给出:
minimize -P'z + q'z
s.t. A'z = b', G'z = c'
其中,P’ = P(z*, v*, λ*),A’ = A(z*),G’ = G(z*),[-q’, c’, b’] = [-?L/?z*, 0, 0]。
BPQP 的关键思想是 IFT 的线性要求 KKT 矩阵左乘齐次线性偏导数变量。定理 1 强调了一种特殊情况,即在最优点(满足 KKT 条件)处考虑梯度。
时间复杂度: 解决此类二次规划问题的时间复杂度为 O(N^3),与直接求解线性系统公式 (3) 相同。但是,将问题重新表述为二次规划可以提供可以利用的结构,例如稀疏矩阵、解决方案优化、主动集和一阶方法等。
4.2 使用 OSQP 高效解决反向传播问题
BPQP 采用 OSQP 作为求解器,OSQP 包含稀疏矩阵方法,并使用一阶 ADMM 方法来解决二次规划问题。
OSQP 在每次迭代中,从向量的初始化点 z^(0) ∈ R^d,λ^(0) ∈ R^m 和 ν^(0) ∈ R^n 出发,迭代计算第 k+1 次迭代的值:
(P + σI) A diag(ρ)^{-1} A^T z^(k+1) ν^(k+1)
λ^(k) - diag(ρ)^{-1}ν^(k) A z^(k) - q
然后执行以下更新:
λ^(k+1) = λ^(k) + diag(ρ)^{-1}(ν^(k+1) - ν^(k))
ν^(k+1) = ν^(k) + diag(ρ)(A z^(k+1) - b)
当原始残差向量和原始对偶残差向量在第 k 次迭代后足够小时,z^(k+1)、λ^(k+1) 和 ν^(k+1) 收敛到精确解 z、λ 和 ν*。
BPQP 采用 ADMM 过程来解决 KKT 矩阵,并获得候选解,然后通过迭代求解以下方程来恢复精确解:
(K + ΔK)Δt^k = g - Kt^k
其中,t^(k+1) = t^k + Δt^k,该过程在实践中可以快速收敛到 t。
4.3 示例:可微分的二次规划和二阶锥规划
BPQP 为可微分的二次规划 (QP) 和二阶锥规划 (SOCP) 提供解决方案。以下将详细介绍如何应用 BPQP 来解决这两类问题。
4.3.1 可微分的二次规划
考虑以下标准的二次规划问题:
其中,,,,,,。
BPQP 的目标是计算损失函数对参数的梯度。根据定理 1,BPQP 将反向传播问题重新表述为以下等式约束的二次规划问题:
其中,,,,。
该二次规划问题的最优解可以用于计算损失函数对各个参数的梯度:
4.3.2 可微分的二阶锥规划
BPQP 还可以用于解决可微分的二阶锥规划问题,例如鲁棒线性规划问题:
其中,,,。
BPQP 计算损失函数对参数的梯度:
其中,是对应于第个约束的拉格朗日乘子,可以通过解决以下等式约束的二次规划问题来获得:
5. 实验
本文通过实验验证了 BPQP 的有效性和优越性。
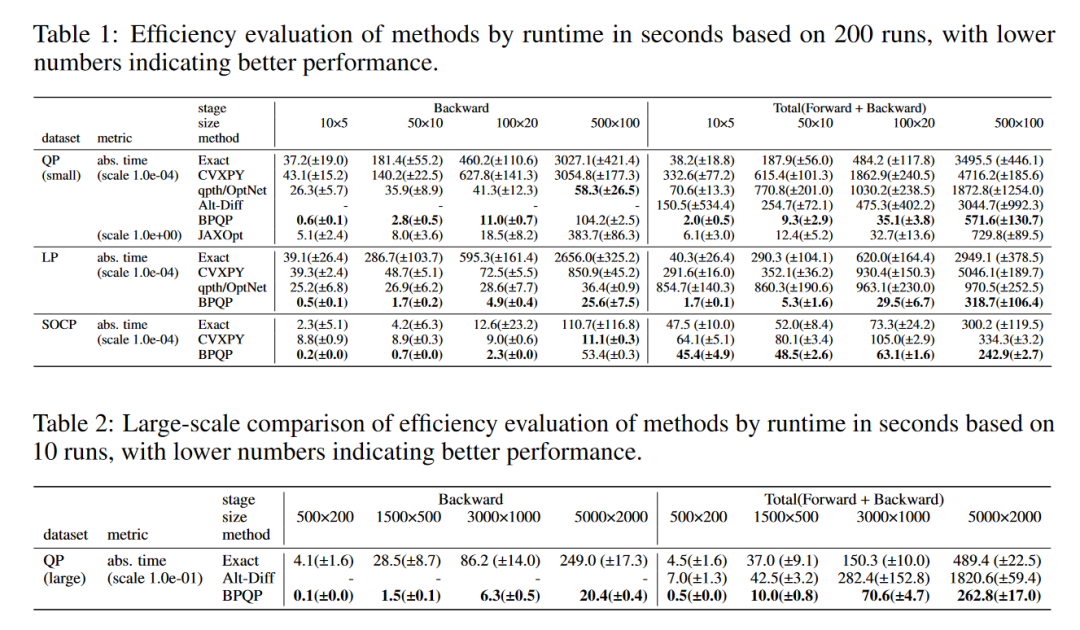
5.1 模拟大规模约束优化
在模拟实验中,本文生成了不同规模的二次规划 (QP)、线性规划 (LP) 和二阶锥规划 (SOCP) 数据集。
数据集生成方法:
-
QP 数据集: 矩阵通过生成,其中是随机生成的密集矩阵,。向量和也随机生成。 -
LP 数据集: 与 QP 数据集类似,但目标函数中添加了项,以确保最优解关于参数可微,。 -
SOCP 数据集: 考虑的特殊情况,即,并随机生成向量。
比较方法:
-
CVXPY: 通用的可微分凸优化求解器,采用 SCS 求解器来加速梯度计算。 -
qpth/OptNet: GPU 加速的可微分优化器,OptNet 是将 qpth 作为内部优化器的可微分神经网络层。 -
BPQP: 本文提出的方法,前向和反向传播过程分离,采用 OSQP 作为前向传播求解器,反向传播过程重新表述为等式约束的二次规划问题,并使用 OSQP 求解。 -
Exact: 与 BPQP 使用相同的前向传播求解器,但反向传播过程直接求解线性系统,不进行问题重新表述。 -
JAXOpt: 开源优化包,支持硬件加速、可缓存训练和可微分反向传播。 -
Alt-Diff: 专门解决精确解和参数梯度的二次规划问题的 ADMM 方法。
实验结果:
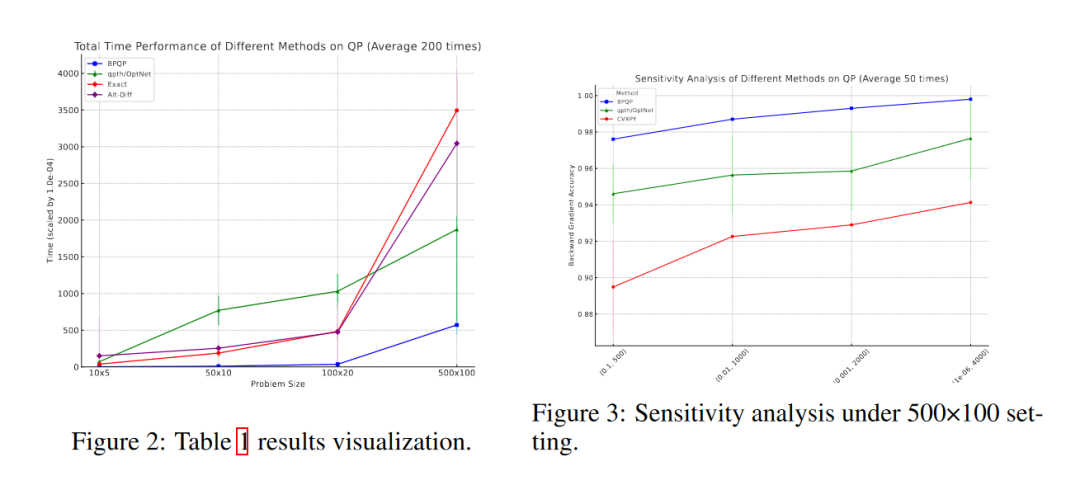
实验结果表明,与现有方法相比,BPQP 在总时间上实现了数十倍甚至数千倍的加速。图 2 展示了 QP 数据集上的总时间性能,图 3 展示了 QP 数据集上不同方法的敏感性分析。

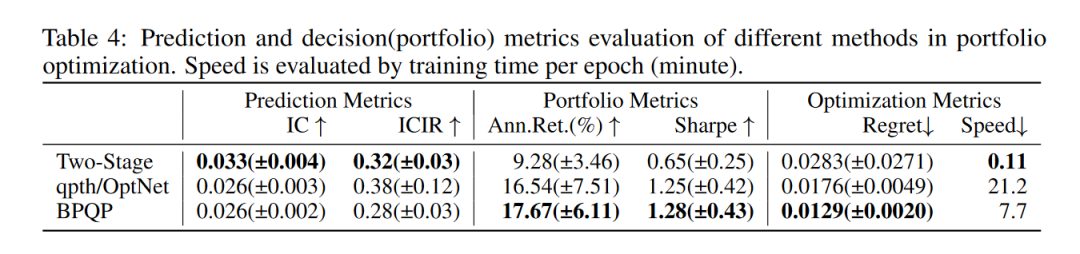
5.2 真实世界端到端投资组合优化
投资组合优化是金融领域资产配置的核心问题,其目标是构建和平衡投资组合,以实现收益最大化、风险最小化。
模型:
本文采用均值-方差优化 (MVO) 模型:
其中,是投资组合权重,是预期收益,是风险规避系数,是协方差矩阵。
BPQP 应用于 MVO 模型的前向传播过程,并计算损失函数对参数的梯度。
基准模型:
-
Two-Stage: 分别训练预测模型和优化模型。 -
qpth/OptNet: 与 BPQP 类似,但反向传播过程采用 OptNet。
数据集:
数据集来自 Qlib,包含 158 个序列,每个序列包含 2008 年至 2020 年间每天的 OHLC 技术特征。
评价指标:
-
预测指标: 信息系数 (IC) 和信息系数比率 (ICIR)。 -
投资组合指标: 年化收益率 (Ann.Ret.) 和夏普比率 (Sharpe)。 -
优化指标: 每轮训练时间 (分钟)。
实验结果:
实验结果表明,BPQP 在投资组合指标上优于 Two-Stage 和 qpth/OptNet,并且在训练时间上比 qpth/OptNet 快 2.75 倍。
6. 进一步讨论
BPQP 还可以应用于非凸优化问题。
当解决非凸优化问题时,可能会遇到以下两个挑战:
-
解决方案只是局部最小值。 -
解决方案只是局部最小值附近的近似解。
如果在前向传播中采用有效的非凸方法 (例如改进的 SVRG),BPQP 仍然可以将反向传播过程重新表述为二次规划问题。这是因为 BPQP 的推导和理论分析同样适用于非凸场景。
BPQP 允许推导出保持 KKT 范数的梯度,这意味着当 KKT 范数较小时,BPQP 可以推导出高质量的梯度。因此,当非凸求解器在前向传播中成功获得接近甚至达到局部或全局最小值的解时,BPQP 仍然可以有效地计算行为良好的梯度。
此外,许多非凸问题可以转化为凸问题,这使得 BPQP 的应用范围更加广泛。
7. 结论
本文介绍了一种用于高效端到端学习的可微分凸优化框架 BPQP。BPQP 将反向传播过程重新表述为一个简化的、分离的二次规划问题,显著降低了前向和反向传播的计算成本。实验结果表明,BPQP 在计算效率方面优于现有方法。
BPQP 的优势在于:
-
保持了精确梯度的计算能力。 -
提高了计算效率,适用于大规模数据集。 -
提供了灵活的求解器选择。
(论文及代码见星球)
