
收录于话题
2024年12月5日arXiv cs.CV发文量约136余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省57分钟浏览arXiv的时间。


Meta、纽约大学和伯克利人工智能研究院联合提出了导航世界模型(NWM),一种可控视频生成模型。该模型采用条件扩散Transformer来预测未来的视觉观测,并能够基于过去的观测和导航动作,在熟悉和不熟悉的环境中规划导航轨迹。
【Bohr精读】
https://j1q.cn/yhWx4Gum
【arXiv链接】
http://arxiv.org/abs/2412.03572v1
【代码地址】
https://amirbar.net/nwm
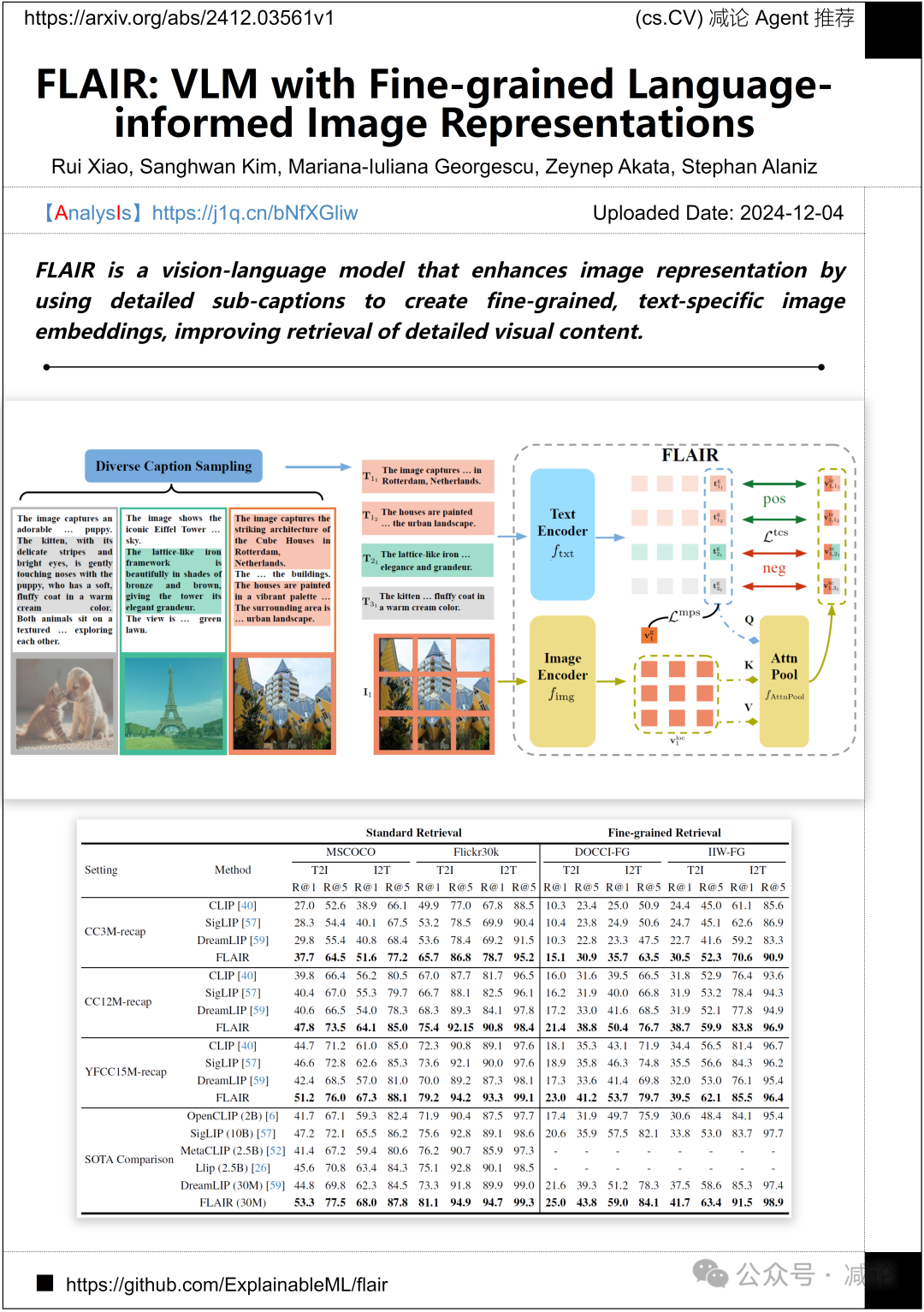
慕尼黑工业大学提出了FLAIR方法,一种视觉语言模型。FLAIR通过使用详细的子标题,创建了细粒度、特定于文本的图像嵌入,增强了图像表示,改善了对详细视觉内容的检索。
【Bohr精读】
https://j1q.cn/bNfXGliw
【arXiv链接】
http://arxiv.org/abs/2412.03561v1
【代码地址】
https://github.com/ExplainableML/flair
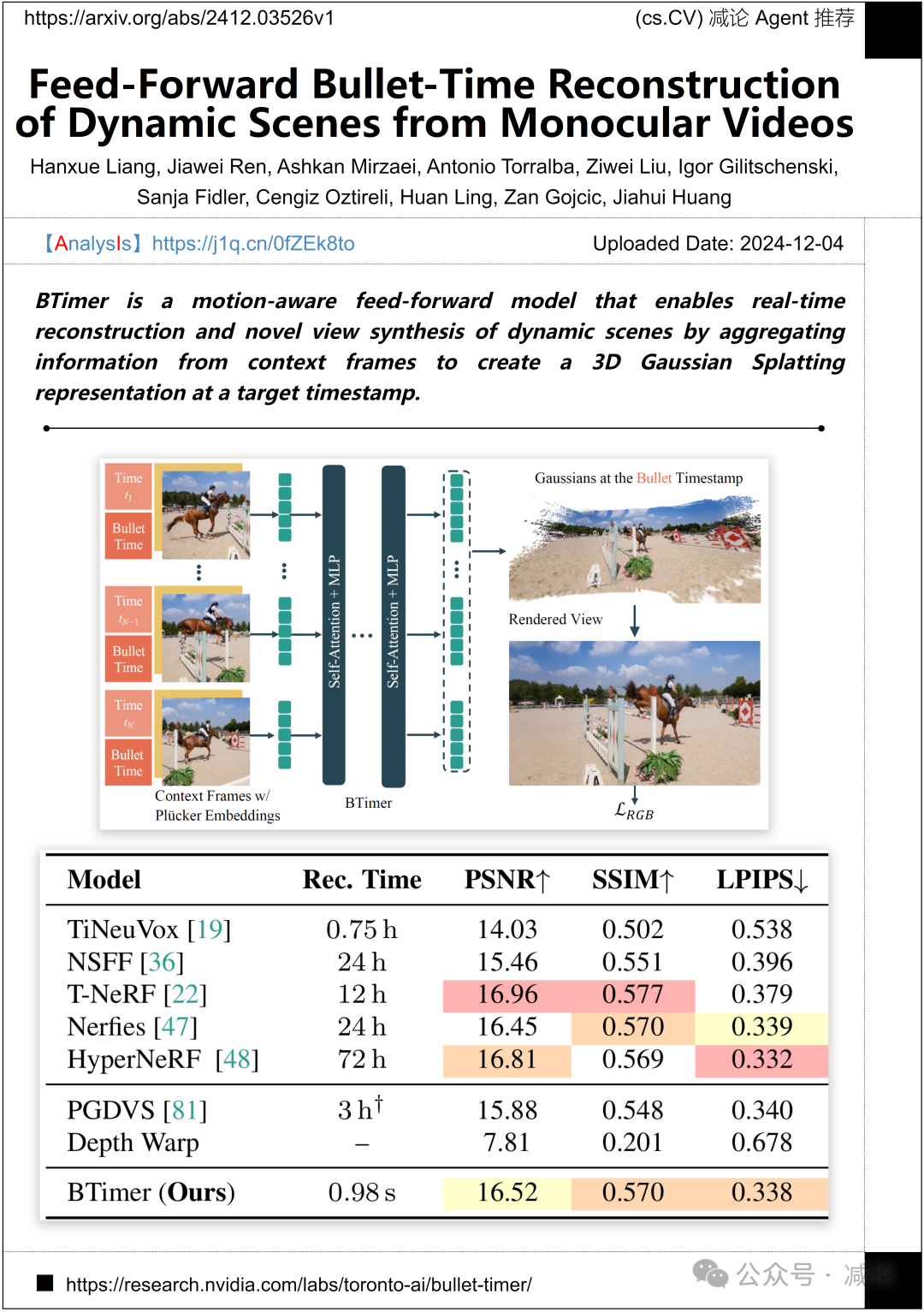
英伟达与南洋理工大学提出了BTimer,一种运动感知前馈模型。BTimer通过聚合上下文帧信息,在目标时间点生成3D高斯喷溅表示,实现动态场景的实时重建和新视角合成。该方法为动态场景处理提供了新的思路。
【Bohr精读】
https://j1q.cn/0fZEk8to
【arXiv链接】
http://arxiv.org/abs/2412.03526v1
【代码地址】
https://research.nvidia.com/labs/toronto-ai/bullet-timer/
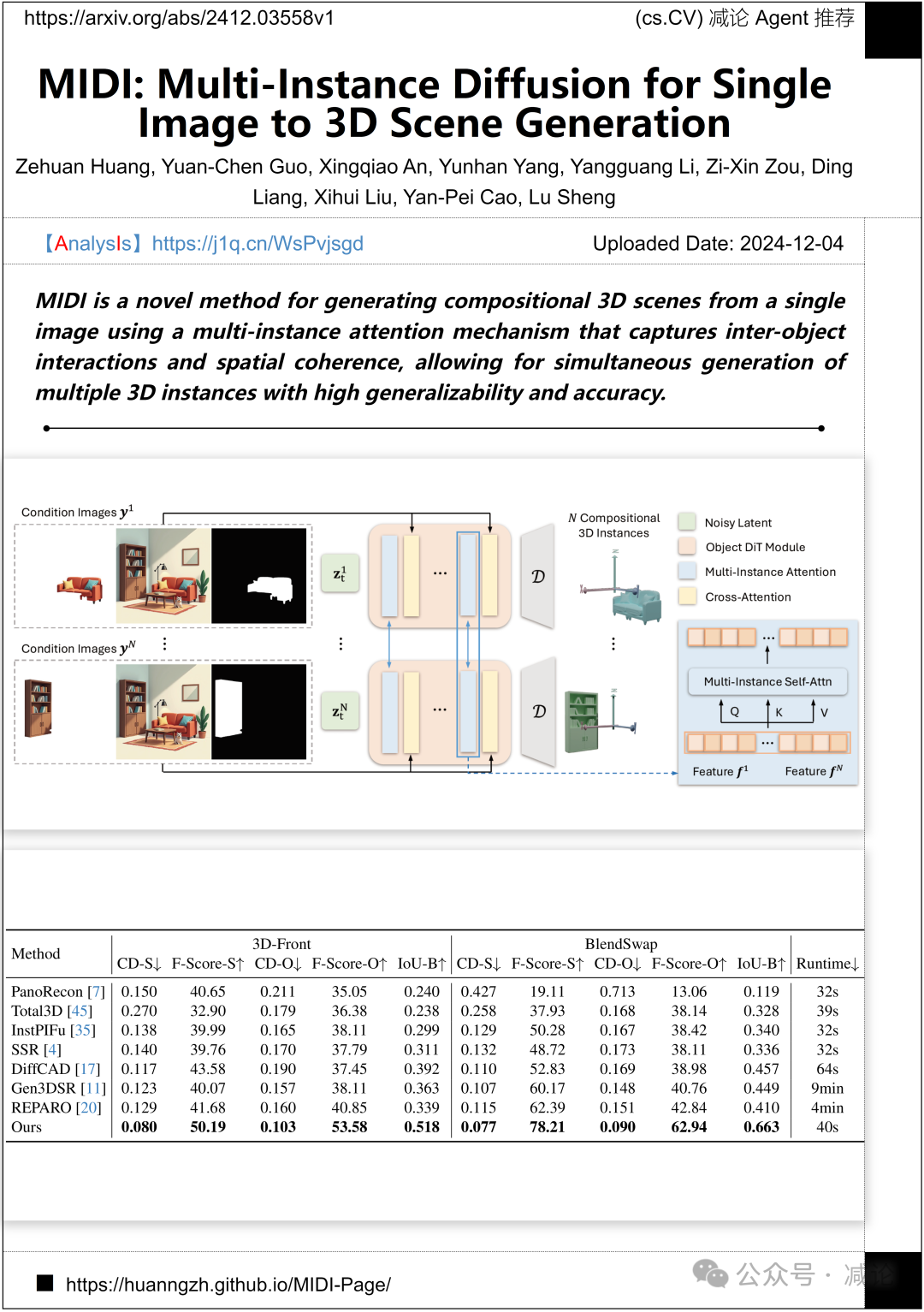
北京航空航天大学、越南科学院和香港大学提出了一种新方法——MIDI。该方法利用多实例注意机制,从单张图像生成三维场景,能够有效捕捉物体间的交互和空间一致性,实现多个三维实例的同时生成,展现出高度的泛化性和准确性。
【Bohr精读】
https://j1q.cn/WsPvjsgd
【arXiv链接】
http://arxiv.org/abs/2412.03558v1
【代码地址】
https://huanngzh.github.io/MIDI-Page/

武汉大学推出的QuadricsReg是一种新颖的点云配准方法,利用简洁的二次曲面基元建立对应关系,有效估计六自由度变换,显著提高了大规模点云场景中的鲁棒性和精确性。
【Bohr精读】
https://j1q.cn/Hy0FqzoM
【arXiv链接】
http://arxiv.org/abs/2412.02998v1
【代码地址】
https://levenberg.github.io/QuadricsReg
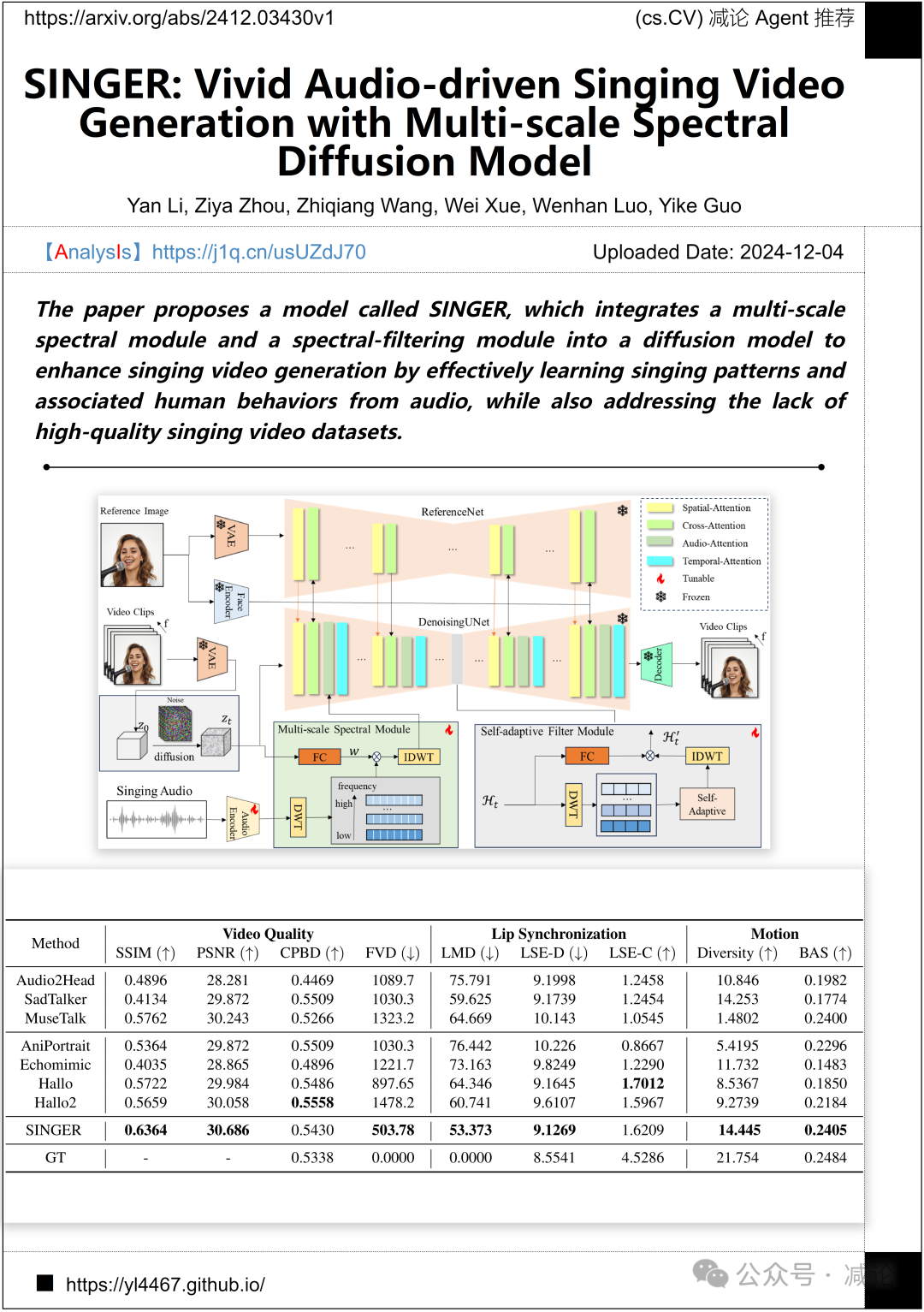
香港科技大学提出了SINGER模型,集成了多尺度谱模块和谱过滤模块到扩散模型中。该模型通过有效学习音频中的唱歌模式和相关人类行为,增强了唱歌视频生成,并解决了优质唱歌视频数据集缺乏的问题。
【Bohr精读】
https://j1q.cn/usUZdJ70
【arXiv链接】
http://arxiv.org/abs/2412.03430v1
【代码地址】
https://yl4467.github.io/
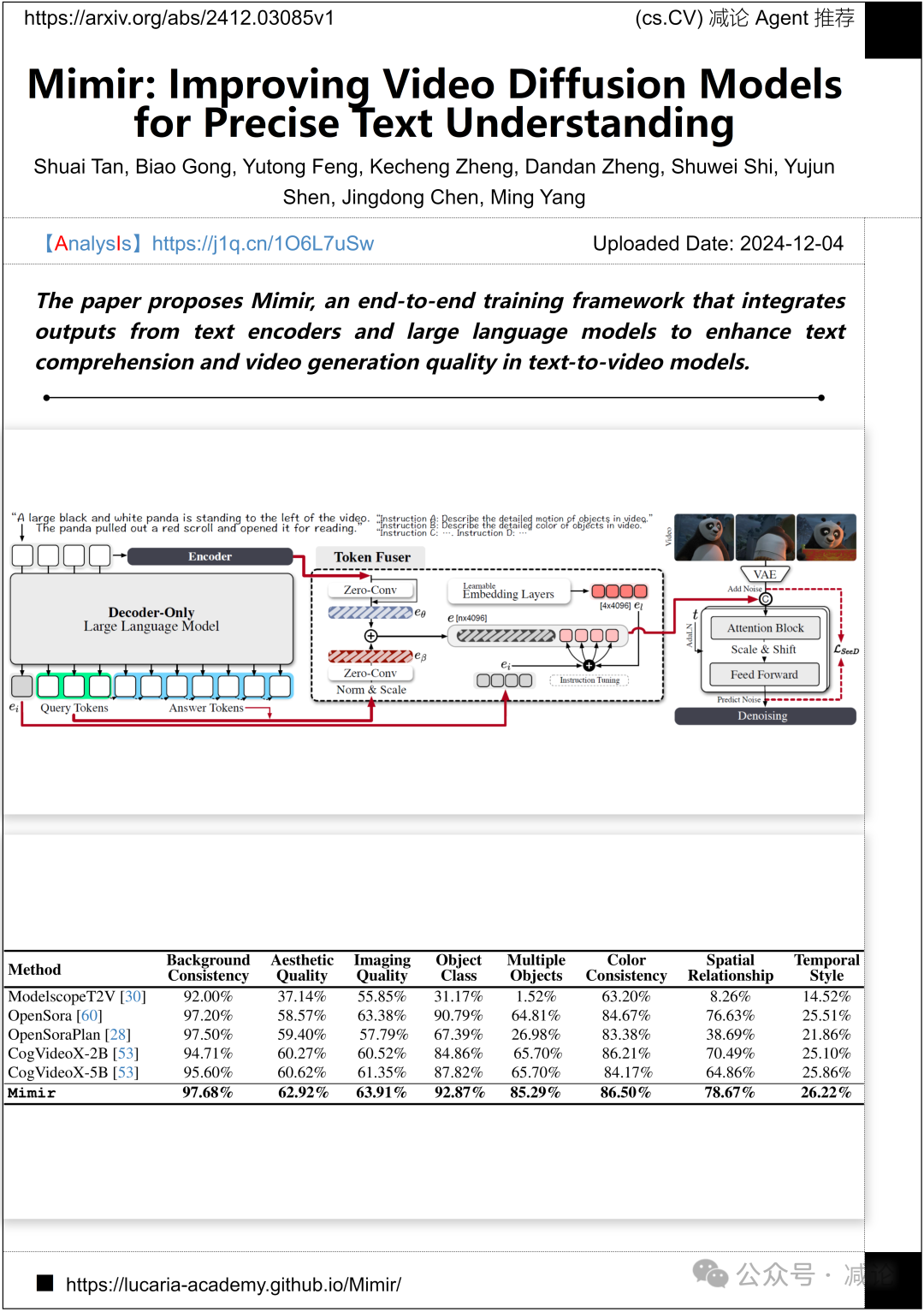
蚂蚁集团与清华大学提出了Mimir端到端训练框架,集成了文本编码器和大型语言模型的输出,以提升文本视频模型的文本理解能力和视频生成质量。
【Bohr精读】
https://j1q.cn/1O6L7uSw
【arXiv链接】
http://arxiv.org/abs/2412.03085v1
【代码地址】
https://lucaria-academy.github.io/Mimir/

哈尔滨工业大学、长安汽车和阿德莱德大学联合提出了一种新颖的CogDriving方法,采用扩散Transformer架构和整体4D注意力模块,以合成高质量的多视角驾驶视频。该方法提高了跨视角和跨帧的一致性,并配备轻量级微控制器,实现精确的布局控制。
【Bohr精读】
https://j1q.cn/1KWXX0zR
【arXiv链接】
http://arxiv.org/abs/2412.03520v1
【代码地址】
https://luhannan.github.io/CogDrivingPage/

字节跳动提出的TokenFlow方法是一种统一的图像tokenizer,采用双码本架构,分别学习语义和像素级特征,并保持一致性。此方法显著提升了多模态理解和生成任务的性能。
【Bohr精读】
https://j1q.cn/cl8GvlCv
【arXiv链接】
http://arxiv.org/abs/2412.03069v1
【代码地址】
https://byteflow-ai.github.io/TokenFlow/
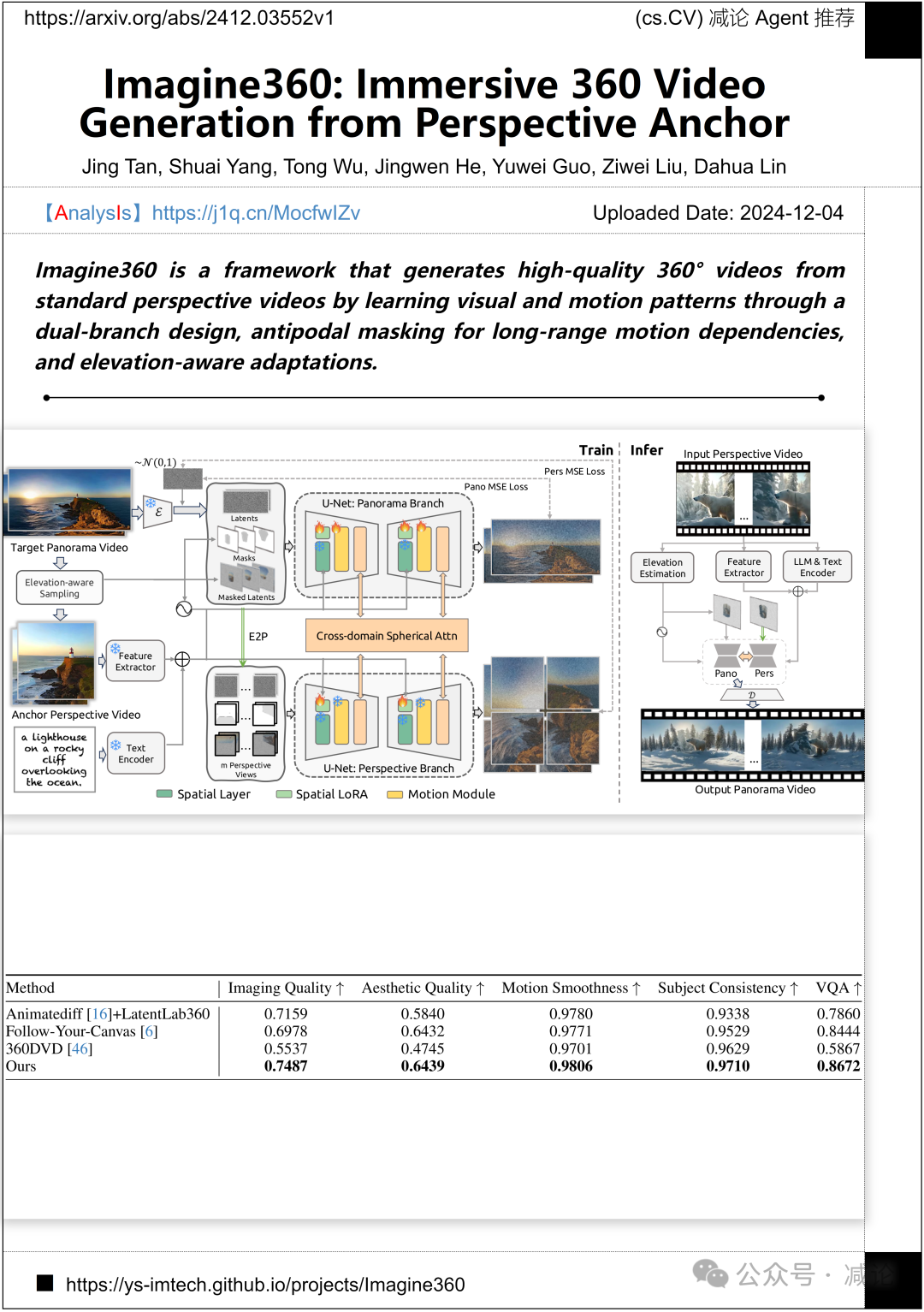
香港中文大学、上海交通大学和南洋理工大学提出了Imagine360框架。该框架通过学习视觉和运动模式,采用双分支设计和对跖面遮掩,处理长距离运动依赖,并进行高程感知适应,从标准视角视频生成高质量360°视频。
【Bohr精读】
https://j1q.cn/MocfwIZv
【arXiv链接】
http://arxiv.org/abs/2412.03552v1
【代码地址】
https://ys-imtech.github.io/projects/Imagine360

清华大学与美团公司联合提出了一种时间步感知扩散模型。该模型在早期去噪阶段自适应整合低分辨率图像特征,并在后期激发预训练Stable Diffusion模型的生成能力,显著增强图像超分辨率。
【Bohr精读】
https://j1q.cn/ZEC9Yn96
【arXiv链接】
http://arxiv.org/abs/2412.03355v1
【代码地址】
https://github.com/SleepyLin/TASR

清华大学与美团公司提出了PrefixKV方法,该方法通过基于二分搜索的逐层保留策略,优化大型视觉语言模型中的键值缓存大小,从而保留上下文信息并提升推理效率。
【Bohr精读】
https://j1q.cn/yENeP91h
【arXiv链接】
http://arxiv.org/abs/2412.03409v1
【代码地址】
https://github.com/THU-MIG/PrefixKV
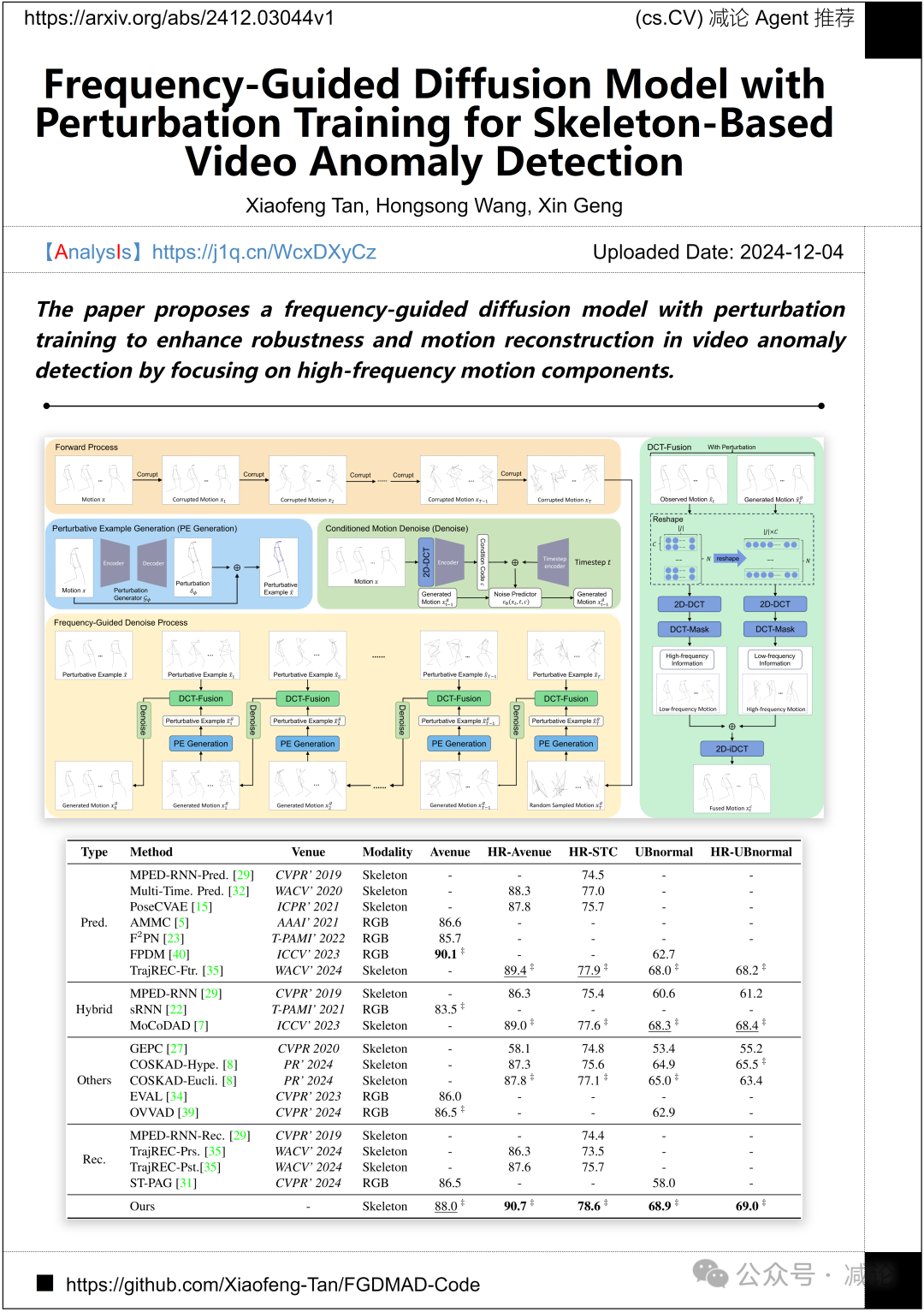
东南大学提出了一种频率引导的扩散模型,利用扰动训练增强视频异常检测的鲁棒性和运动重建,重点关注高频运动组件。这一方法提高了检测精度和处理效率。
【Bohr精读】
https://j1q.cn/WcxDXyCz
【arXiv链接】
http://arxiv.org/abs/2412.03044v1
【代码地址】
https://github.com/Xiaofeng-Tan/FGDMAD-Code

慕尼黑大学提出了一种轻量级的无监督微调方法,针对扩散模型,能够提取高质量、无噪声的语义特征。该方法在多项任务中表现显著优于以往技术。
【Bohr精读】
https://j1q.cn/6kQGOdi5
【arXiv链接】
http://arxiv.org/abs/2412.03439v1
【代码地址】
https://compvis.github.io/cleandift

复旦大学与华为诺亚方舟实验室推出了Inst-IT方法,这是一种基于GPT-4o的自动化注释流水线。通过显式视觉提示指令微调,Inst-IT提升了大型多模态模型的实例级理解,并获得了基准测试和大规模数据集的支持。
【Bohr精读】
https://j1q.cn/qPj0cezw
【arXiv链接】
http://arxiv.org/abs/2412.03565v1
【代码地址】
https://inst-it.github.io
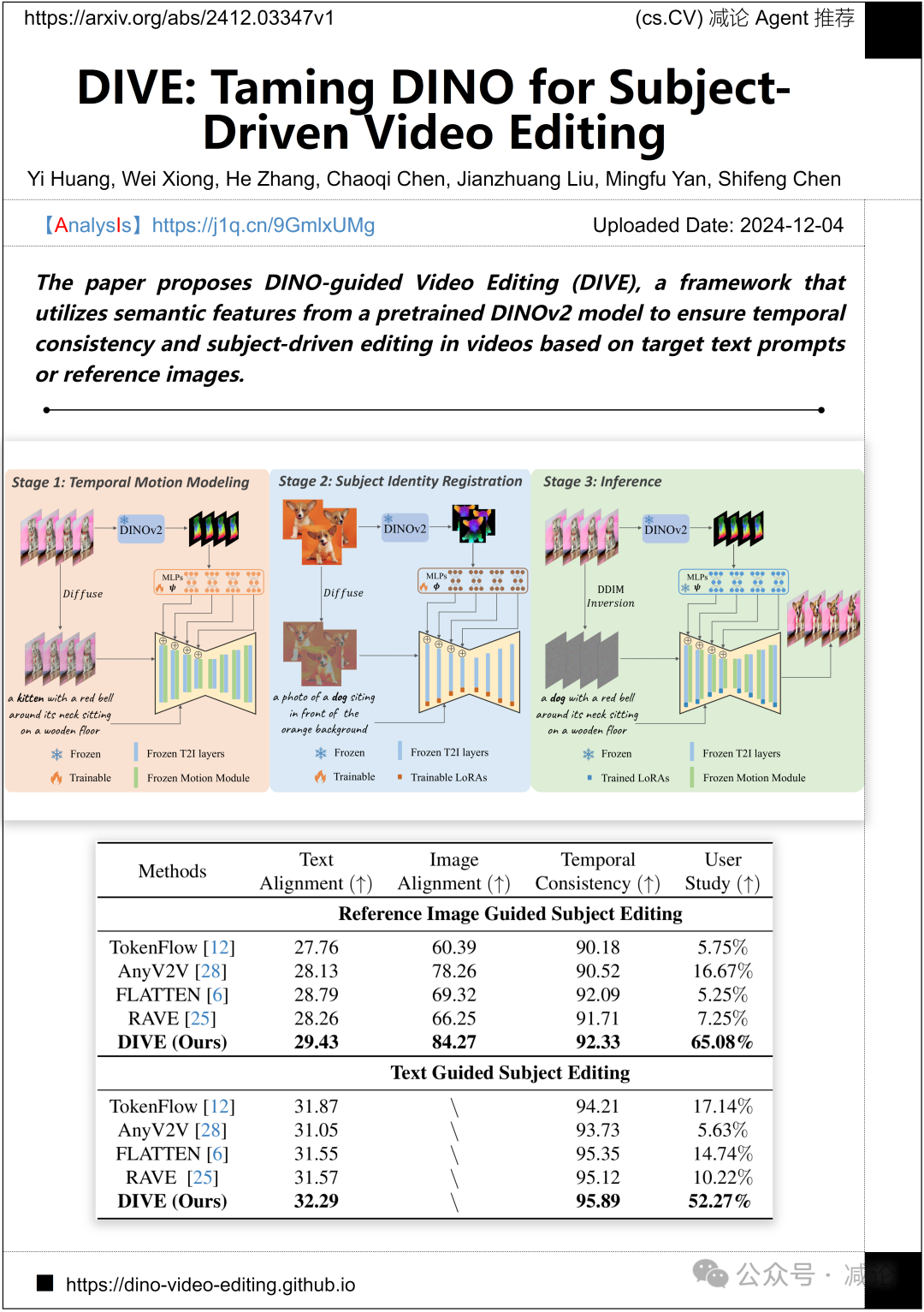
深圳先进技术研究院、中国科学院、Adobe研究和深圳先进技术大学提出了一种名为DINO-guided Video Editing(DIVE)的方法。该方法利用预训练的DINOv2模型中的语义特征,实现视频的时间一致性和主体驱动的编辑,依据目标文本提示或参考图像进行处理。
【Bohr精读】
https://j1q.cn/9GmlxUMg
【arXiv链接】
http://arxiv.org/abs/2412.03347v1
【代码地址】
https://dino-video-editing.github.io

美团Inc.和清华大学提出了一种时间步长感知的训练策略,结合低频约束和奖励反馈学习,以提升生成扩散模型在图像超分辨率中生成图像的感知和美学质量。
【Bohr精读】
https://j1q.cn/WM9qyJIt
【arXiv链接】
http://arxiv.org/abs/2412.03268v1
【代码地址】
https://github.com/sxpro/RFSR

清华大学提出了2DGS-Room,一种基于2D高斯散射的高保真室内场景重建方法。该方法通过优化种子点分布,结合深度和法线先验,以及多视角一致性,提升了几何精度并减轻了伪影。
【Bohr精读】
https://j1q.cn/Ls0Klfhp
【arXiv链接】
http://arxiv.org/abs/2412.03428v1
【代码地址】
https://valentina-zhang.github.io/2DGS-Room/

欢迎关注减论,持续输出有深度的人工智能极减理解,提升信息获取效率和认知维度。看完点颗小星星再走呗~