
收录于话题


在实际的机器学习应用中,表格数据是最常见的数据类型。这类数据由固定数量的特征(列)组成,这些特征可以是数值型或分类型,与图像或文本数据相比,缺乏时空结构。表格数据的中等维度和缺乏对称性使得它能够被多种机器学习方法处理。这篇文章挑战了梯度提升决策树(GBDTs)在表格数据分类和回归任务中的主导地位,提出了一种改进的多层感知器(MLP)——RealMLP,以及针对GBDTs和RealMLP的强预调整默认参数。通过在118个数据集的元训练基准上调整RealMLP和默认参数,并在90个数据集的元测试基准上与超参数优化版本进行比较,结果显示RealMLP在中等到大型表格数据集上比起其他神经网络模型来说有着更好的时间与精度之间的权衡,并且在基准分数上与GBDTs具有竞争力。此外,RealMLP的默认参数可以在不进行超参数调整的情况下获得优异的结果。
这篇论文介绍了很多MLP模型的技巧和元学习调参,笔者通读论文后运用了一些组件到自己的模型中取得了不错的提升,各位读者可以根据提供的代码和文章内容在自己的模型中添加组件。
相关工作
文章首先回顾了深度学习在表格数据上的应用,特别是针对神经网络(NNs)的架构。作者提到了三类主要方法:数据转换方法、特定架构和正则化模型。近期的研究主要集中在基于注意力机制的特定架构上,这些方法在不同数据点之间引入了注意力机制。然而,这些方法通常比MLPs或GBDTs要慢。因此,研究者探索了如何通过架构、训练、预处理、超参数和初始化等方面的改进来提升MLP的性能。
文章还讨论了基准测试的重要性,指出了先前研究中存在的问题,例如某些方法在它们自己的数据集上表现更好。为了解决这个问题,作者使用了更多的数据集,并在未对模型进行调整的数据集上评估方法。此外,文章还提到了其他研究者提出的更大基准测试,并分析了GBDTs为何在平均情况下仍然优于深度学习方法。
文章提到了元学习在机器学习中的重要性,尤其是在找到最佳固定超参数方面。作者没有引入或使用完全自动化的方法来找到好的默认参数,但使用了元学习基准设置来评估它们。文章中还提到了其他研究者在元学习领域的工作,包括在大型基准测试上学习参数配置组合的研究。
MLP的方法论
以下部分介绍RealMLP-TD,这是我们经过调整默认属性的改进MLP。
数据预处理
在RealMLP中,我们对最多具有8个不同值(不包括缺失值)的分类特征应用独热编码,缺失值被编码为0。而对于数值特征,都进行如下处理,令是每个特征的值,令是的p-分位数,然后:
当特征具有较大的离群值时,平滑裁剪和缩放会减小异常值的影响。
神经网络架构
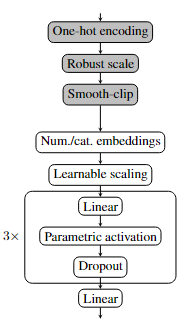
我们提出的网络架构如上图。这是一个隐藏层数量为256的多层感知机,并且做了如下的改进:
-
RealMLP-TD使用了分类嵌入层来把类别数大于8的类别特征进行嵌入。 -
对于数值特征,我们引入了PBLD(周期性偏差线性DenseNet)嵌入,具体是使用了两个小的MLP模型进行处理,公式是:,是第一个MLP的参数,它映射1维到16维,映射16维到3维,所以PBLD嵌入将原来的每个数值特征都扩展了4倍。 -
为了进行特征选择,我们在第一个线性层之前引入了一个缩放层,它是用一个对角权重矩阵对特征进行加权。换句话说,它使用每个特征的可学习缩放因子计算。我们发现该层使用较大的学习率会更好。 -
我们的线性层使用Jacot等人提出的神经切线参数化(NTP),公式为,其中是层输入的维度,也就是说在权重初始化上加一个缩放,这样它能够根据输入维度有效地修改权重矩阵的学习率,希望在特征数量过大时防止步长过大。 -
RealMLP-TD使用了带可训练参数的激活函数。对于使用的激活函数,使用可学习参数:。对于分类问题我们使用SELU,对于回归问题使用Mish。 -
我们在每个激活函数之后使用dropout。 -
对于回归任务,MLP的输出在训练时候会被裁剪到一定范围。
初始化
缩放层的参数被初始化为1,是恒等函数。类似地,参数激活函数的参数被初始化为1,也就是说初始化时就是标准的激活函数。在对训练集进行前向传递期间,我们以数据驱动的方式初始化权重和偏差。我们重新缩放标准正态初始化权重矩阵的行,以将数据集上激活前输出的方差缩放为1。对于偏差,我们使用数据相关的he+5初始化方法,具体来说,就是预先采样数据集中的若干个点,根据这些点的凸包决定偏差的初始值。
训练过程
我们使用AdamW优化器,并且把它的动量超参数进行了调整。训练的批次大小是256,进行256个训练回合。分类的损失函数使用SoftMax+交叉熵,同时进行标签平滑。对于回归,我们使用MSE损失,并且会把最终目标值进行归一化。
超参数调整
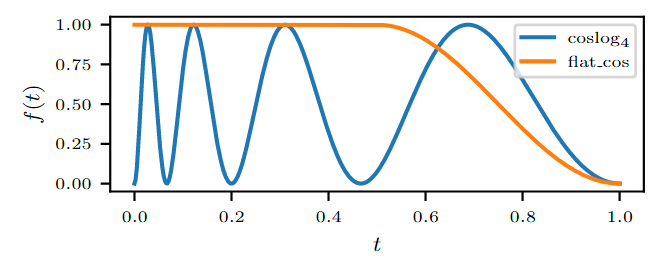
我们的一些超参数会根据超参数的原始设定值和目前训练的进度进行调整。比如,我们可以根据以下方式调整学习率:
其中,是目前的回合占总回合的比例,是开始设定的学习率值。这个函数鼓励学习率大小周期性变化,并且变化的频率越来越低。它的函数形式是:
这个值用来调整周期性变化的频率。对于dropout的比率和权重衰减(weight decay)的大小,使用以下的函数:
这两个函数的图像如下所示:

然后,因为学习率的调整机制,我们不执行经典的早停,而是训练完整的256个回合,然后将选择验证误差最低的模型,本文中的验证集损失是分类误差或回归的RMSE。如果验证集损失值相同,我们发现使用最后一个最佳回合是更好的。
性能提升
下图是该算法不同组件在分类任务和回归任务上的性能提升:
但是,这些结果还是依赖于组件添加的顺序。比如较大的权重衰减使RealMLP-TD对某些其他超参数(如动量超参数)的变化敏感。并且,我们的数值预处理方式效果很好,并且通常也对其他神经网络结构有益。缩放层和PBLD嵌入这两个组件容易使用,并且在RealTabR-D中也很有效。如果计算资源充足,更大的学习回合和使用(循环)学习率调整可能会有很好的效果。
GDBT的参数选择
为了为GBDT找到更好的默认超参数,我们采用半自动方法:我们使用hyperopt和SMAC3等超参数优化库来探索巨大的超参数空间,并评估每个参数组的训练基准分数,然后执行一些小的手动调整,例如对获得的最佳超参数进行四舍五入。为了平衡效率和准确性,我们将估计器的数量固定为1000,并在XGBoost中使用hist方法。对于不同的树算法,我们都只考虑库的默认树构建策略,因为这是它们的主要区别之一。虽然获得的一些超参数值可能对手动调整和基准设置敏感,但我们能观察到一些趋势。首先,比起列子采样,行子采样使用的更多。其次,回归树通常比分类树更深。第三,CatBoost中的伯努利自助抽样比贝叶斯自助抽样速度更快且效果相当。
实验结果
接下来,我们使用库内默认值 (D)、调整默认值 (TD) 和超参数优化 (HPO) 来评估不同的方法。TD使用在元训练基准上优化的固定参数,而HPO则独立调整每个数据集分割上的超参数。除随机森林之外的所有方法都根据准确度/RMSE在相应数据集分割的验证集上选择最佳迭代/时期。所有基于神经网络的回归方法都会标准化训练标签。
作为基于树的方法,我们使用XGBoost(XGB)、LightGBM(LGBM)和CatBoost,以及scikit-learn中的随机森林(RF)。变体 XGB-PBB-D使用元学习默认参数。对于深度学习的算法,我们使用了Gorishniy发表文章中的MLP、ResNet和FT-Transformer(FTT)、以及MLP-PLR(带嵌入的MLP)、TabR和TabR-S(无数值嵌入)。我们将这些方法与所提出的RealMLP和RealTabR(将这些提升方式利用在TabR算法中)进行比较。此外,我们研究在每个数据集上对于不同算法中选择具有最佳验证分数的参数集,算法包括of XGB、LGBM、CatBoost和MLP-PLR、RealMLP,我们把这种情况记为Best。而Ensemble采用与Best相同的方法构建加权集成。我们不会在所有基准测试上运行FTT、RF-HPO和TabR-HPO,因为某些基准测试(尤其是元测试)的运行成本更高,并且这些方法可能导致内存不足。
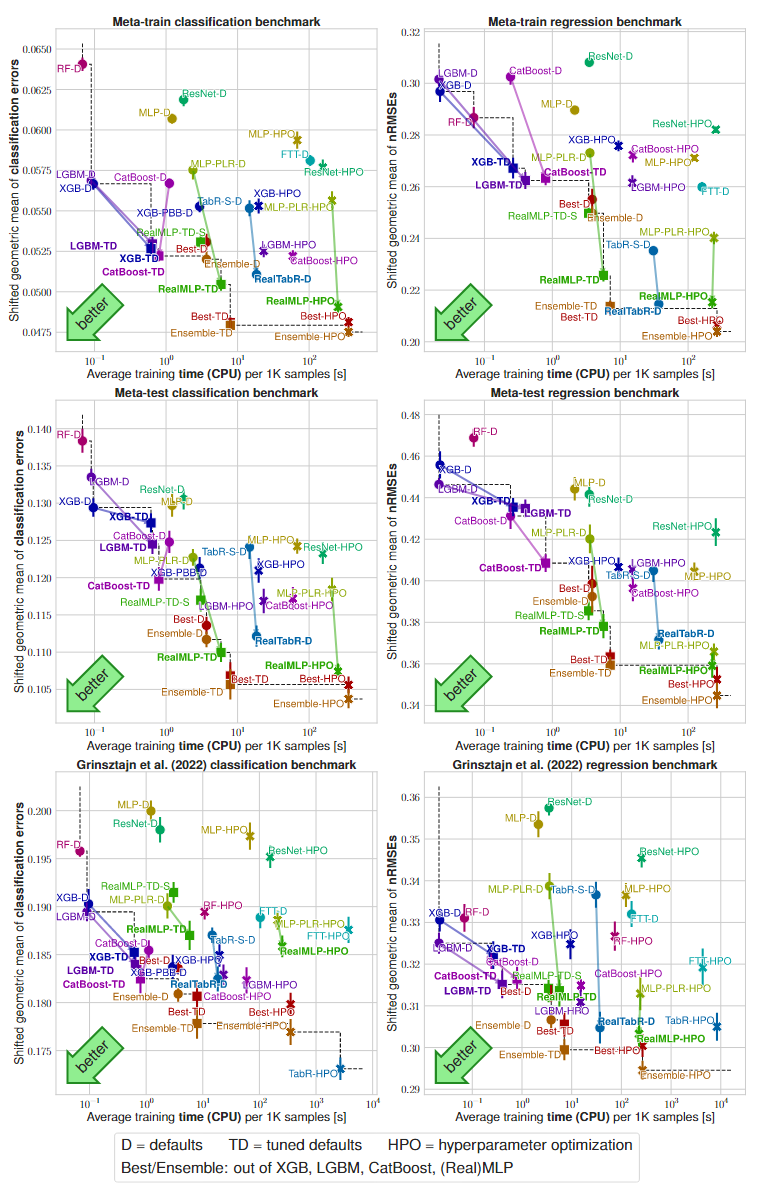
下图是所有基准测试的基准分数与平均训练时间的比较。y轴显示分类误差(左)或RMSE(右)。x轴显示每1000个样本的平均训练时间。
-
新数据集的默认值调整效果如何?为了回答这个问题,我们比较了元测试基准上TD和HPO的基准分数。在元测试基准上,RealMLP-HPO和RealMLP-TD之间的差距比较小,这表明调整后的默认参数很好地转移到了元测试基准上。对于GBDT,调整后的默认值TD在元训练集上与HPO具有竞争力,但在测试集上则不如HPO。尽管如此,它们仍然比元测试集上未调整的默认值D要好得多。 -
RealMLP和RealTabR在神经网络中表现强劲。在大多数基准测试中,RealMLP-TD和RealTabR-TD的性能比MLP-PLR-D和TabR-S-D好不少,并且所需要的额外时间消耗不多。同样,RealMLP-HPO比起MLP-PLR-HPO的性能来说也有提升。虽然RealMLP-TD在许多基准测试中都击败了TabR-S-D,但RealTabR-D在一大半的基准测试中表现甚至更好,尤其是所有回归基准测试。此外,RealMLP和RealTabR与基于树的模型相比是有竞争力的。在元训练和元测试基准上,RealMLP和RealTabR在回归任务中比GBDT表现更好,而在分类任务中也和GDBT具有可比性或稍微提升。 -
在GBDT中,CatBoost默认值的效果好但运行更慢。几篇论文发现CatBoost在GBDT中表现良好,但训练的计算成本更高,在我们的实验中也复现了这一点。 -
简单地运行默认算法比(简单的)单算法HPO更快,而且通常更好。在RealMLP或GBDT上将Best-TD与优化了50步的HPO进行比较时,我们注意到Best-TD的平均速度更快,同时也与最好的HPO模型性能相当。并且,Best-D的性能往往优于RealMLP-HPO。我们还注意到,与选择最佳模型相比,集成方法通常会在基准分数上提高0-3%,并且有可能进一步提升。
结论
在本文中,我们研究了改进GBDT的默认参数和改进的MLP的潜力,并在大型独立元测试基准上进行了评估,并研究了各种算法选择和集成场景的时间精度权衡。我们改进的MLP在运行时间适中的情况下大部分优于文献中的其他神经网络,并且与GBDT在基准分数上能有竞争力。由于许多对神经网络提出的改进与其他论文中的改进正交,因此这些改进提供了令人兴奋的组合机会,正如我们对RealTabR也用同样的方法进行改进并且提升了性能。虽然“NN与GBDT”的争论仍然很有趣,但我们的结果表明,使用良好的默认参数,即使训练时间预算适中,这两种类型的算法也值得尝试。
(论文及代码见星球)
