
大家好~
XGBoost 是一种非常流行的机器学习算法,全称是 eXtreme Gradient Boosting,主要用于处理表格类型的数据(比如 Excel 表格),它在比赛和实际应用中表现非常好。
咱们今天用非常通俗的案例和大家聊聊~
1. 什么是 XGBoost?
XGBoost 是一种 集成学习算法,它其实是让很多个简单的模型(比如决策树)一起工作,来提高整体的预测能力。就好像你让很多同学一起帮你做一道难题,每个人都贡献自己的一部分知识,最后得到一个更好的答案。
2. 决策树基础
首先,XGBoost 的基本构建块是决策树。我们可以把决策树想象成一个有很多“问题”和“答案”的过程。比如,假设你想预测明天要不要带伞,决策树的工作流程可能像这样:
-
问题 1:今天的天气预报是晴天吗? -
如果是,可能不需要带伞。 -
如果不是,可能要继续问第二个问题。 -
问题 2:今天的湿度高吗? -
如果高,可能要带伞。 -
如果低,可能不用带伞。
每一个分支就是一个小小的决策,帮助我们最后得到一个预测结果。
3. 集成学习:多棵树的“合作”
单棵决策树有时可能犯错(比如天气预报不准),所以 XGBoost 并不只依赖一棵树,而是使用 多棵树。这就是集成学习的思想:很多棵决策树一起合作,让最终的结果更加可靠。
4. 什么是“Boosting”?
“Boosting”的意思是逐步改善模型。具体到 XGBoost,假设我们已经有了一棵决策树,它的预测结果还不够完美。XGBoost 做的是:让下一棵决策树专注于改正上一棵树的错误,一棵一棵地把模型调得越来越好。
举个例子,假设你要预测明天的天气,你问了五个朋友:
-
第一个朋友说:“应该不会下雨”,但其实他忽略了一个关键因素——天气预报可能不准。 -
第二个朋友就会基于第一个朋友的错误,告诉你:“我觉得天气预报不准,所以可能要下雨。” -
第三个朋友再补充说:“湿度很高,通常湿度高就容易下雨。”
他们每个人都根据前面人的错误信息,进一步改进自己的答案。最终,你结合了每个人的观点,得到一个更全面的预测。XGBoost 就是这样“逐步修正错误”的过程。
5. “Gradient Boosting”是怎么工作的?
“Gradient Boosting” 的核心是用数学方法(梯度下降)来优化模型。这听起来有点复杂,但简单来说就是:每次 XGBoost 构建一棵新的树时,它会计算 之前的树的预测有多糟糕,然后努力让新的树针对这些“糟糕的地方”做出改进。
6. 实际案例
假设你在做一个项目,要根据某个学生的学习时间、上课出勤率等信息,预测他是否能通过考试。你已经有很多学生的数据,包括他们的学习时间、出勤率、最后是否通过考试。
你可以使用 XGBoost 来构建一个预测模型,步骤可能像这样:
-
第一棵树:根据学习时间和出勤率做出初步预测,可能预测结果有点偏差,比如很多同学预测错了。 -
第二棵树:看到第一棵树的错误,专注于那些被错预测的同学,努力改进这些预测。 -
第三棵树:继续改正前面两棵树的错误。
就这样,每一棵树都在专注于改进前面树的错误,最终你会得到一个综合的模型,能准确预测学生是否能通过考试。
总之就是,XGBoost 本质上是一种不断改进模型的算法。它通过一棵棵决策树,逐步修正每一次预测的错误,最终形成一个强大的集成模型。想象一下,多个人一起讨论问题,不断纠正对方的错误,最终得出一个更加准确的答案。这就是 XGBoost 的工作方式。
XGBoost 原理
XGBoost 是通过 梯度提升 来构建一系列的弱决策树,并逐步改进模型。我们首先回顾它的核心思想,具体公式推导如下:
1. 基础模型表达式
假设我们要预测一个目标变量 ,有个样本,每个样本有个特征,表示为。我们用模型来表示对 的预测,模型可以表示为多棵树的和:
其中, 是第 棵树。每一棵树 都属于一个函数空间 ,它是一个基于特征的决策树。
2. 目标函数
为了优化模型,我们需要定义一个损失函数来衡量预测和真实值之间的差异,目标函数为:
其中, 是损失函数,常用的有平方误差 ;而 是正则化项,用来防止过拟合,定义为:
其中 是树的叶子数量, 是叶子的权重向量, 和 是正则化参数。
3. 损失函数的二阶泰勒展开
XGBoost 使用二阶泰勒展开近似来优化目标函数:
其中, 是一阶导数, 是二阶导数。
4. 树结构的优化
每棵树的叶节点会有一个权重 ,则在树的叶子节点上的损失函数为:
其中 是叶子节点上的一阶梯度和, 是叶子节点上的二阶梯度和, 表示落在叶子 上的样本集合。
最优的叶子权重 可以通过优化公式得到:
将这个权重带入目标函数,得到最优分割的目标值:
这个公式用来指导如何选择最佳的树结构。
完整案例
这里,咱们使用上述推导出的公式,构建一个基于虚拟数据的模型~
import numpy as np
import matplotlib.pyplot as plt
# 创建虚拟数据集
np.random.seed(42)
X = np.random.rand(1000, 1) * 10 # 特征 X
y = 2 * X.squeeze() + 3 + np.random.randn(1000) * 2 # 线性关系 + 噪声
# 定义损失函数的梯度和二阶梯度 (平方误差损失)
def gradient(y_true, y_pred):
return y_pred - y_true
def hessian(y_true, y_pred):
return np.ones_like(y_true)
class SimpleTree:
def __init__(self, lambda_=1.0):
self.lambda_ = lambda_
self.split_value = None
self.left_weight = None
self.right_weight = None
def fit(self, X, grad, hess):
# 确保 grad 和 hess 是一维数组
X = X.squeeze() # 转换 X 为一维数组
grad = grad.squeeze() # 转换 grad 为一维数组
hess = hess.squeeze() # 转换 hess 为一维数组
print("Shape of grad:", grad.shape)
print("Shape of hess:", hess.shape)
best_gain = -float('inf')
best_split = None
for split in np.unique(X):
left_mask = X < split
right_mask = ~left_mask
# 使用布尔索引进行一维数组的索引,确保 grad 和 hess 是一维的
G_left = np.sum(grad[left_mask]) # 计算左子集的梯度和
H_left = np.sum(hess[left_mask]) # 计算左子集的Hessian和
G_right = np.sum(grad[right_mask]) # 计算右子集的梯度和
H_right = np.sum(hess[right_mask]) # 计算右子集的Hessian和
if H_left + self.lambda_ == 0 or H_right + self.lambda_ == 0:
continue
gain = 0.5 * (G_left ** 2 / (H_left + self.lambda_) + G_right ** 2 / (H_right + self.lambda_))
if gain > best_gain:
best_gain = gain
best_split = split
self.split_value = best_split
left_mask = X < self.split_value
right_mask = ~left_mask
# 计算最优权重
G_left = np.sum(grad[left_mask])
H_left = np.sum(hess[left_mask])
G_right = np.sum(grad[right_mask])
H_right = np.sum(hess[right_mask])
self.left_weight = -G_left / (H_left + self.lambda_)
self.right_weight = -G_right / (H_right + self.lambda_)
def predict(self, X):
X = X.squeeze() # 确保 X 是一维的
pred = np.zeros_like(X)
pred[X < self.split_value] = self.left_weight
pred[X >= self.split_value] = self.right_weight
return pred
# 手工实现的 XGBoost
class SimpleXGBoost:
def __init__(self, n_estimators=10, lambda_=1.0):
self.n_estimators = n_estimators
self.lambda_ = lambda_
self.trees = []
self.base_score = None
def fit(self, X, y):
self.base_score = np.mean(y) # 初始模型
y_pred = np.full_like(y, self.base_score)
for _ in range(self.n_estimators):
grad = gradient(y, y_pred)
hess = hessian(y, y_pred)
tree = SimpleTree(lambda_=self.lambda_)
tree.fit(X, grad, hess)
y_pred += tree.predict(X)
self.trees.append(tree)
def predict(self, X):
y_pred = np.full(X.shape[0], self.base_score)
for tree in self.trees:
y_pred += tree.predict(X)
return y_pred
# 训练模型并进行预测
model = SimpleXGBoost(n_estimators=10, lambda_=1.0)
model.fit(X, y)
y_pred = model.predict(X)
# 绘制结果图形
plt.figure(figsize=(16, 10))
# 图1: 原始数据分布
plt.subplot(2, 2, 1)
plt.scatter(X, y, color='blue', label='True data', alpha=0.6)
plt.title('True Data Distribution')
plt.xlabel('Feature X')
plt.ylabel('Target y')
plt.legend()
# 图2: 预测值 vs 真实值
plt.subplot(2, 2, 2)
plt.scatter(X, y, color='blue', label='True data', alpha=0.6)
plt.scatter(X, y_pred, color='red', label='Predictions', alpha=0.6)
plt.title('Predictions vs True Data')
plt.xlabel('Feature X')
plt.ylabel('Target y')
plt.legend()
# 图3: 每一棵树的预测结果
plt.subplot(2, 2, 3)
y_tree_preds = np.zeros_like(y)
for tree in model.trees:
y_tree_preds += tree.predict(X)
plt.plot(X, y_tree_preds, color='green', label='Model Predictions after Trees')
plt.title('Model Predictions after All Trees')
plt.xlabel('Feature X')
plt.ylabel('Cumulative Prediction')
plt.legend()
# 图4: 树的分裂点(特征分布)
plt.subplot(2, 2, 4)
tree_splits = [tree.split_value for tree in model.trees]
plt.scatter(range(len(tree_splits)), tree_splits, color='purple', label='Tree Splits', alpha=0.7)
plt.axhline(y=np.mean(X), color='orange', linestyle='--', label='Mean Feature Value')
plt.title('Tree Split Values')
plt.xlabel('Tree Index')
plt.ylabel('Split Value')
plt.legend()
plt.tight_layout()
plt.show()
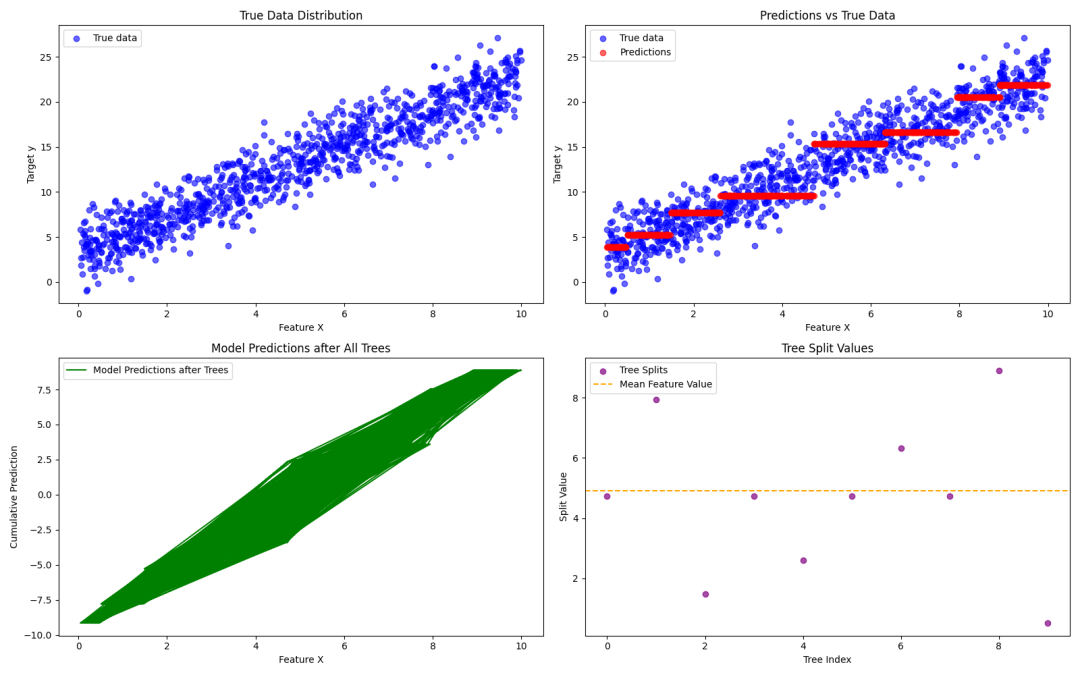

图1: 原始数据分布:这个图展示了我们的虚拟数据集中的真实数据。横轴是特征 ,纵轴是目标值 。这些数据点是线性关系加上一些噪声生成的。由于数据本身是线性关系加噪声的,图中的点呈现出一定的散布趋势。
图2: 预测值 vs 真实值:在这个图中,我们通过红色散点显示了 XGBoost 模型的预测值(通过所有树进行累积预测后得到的结果),蓝色散点表示真实数据。通过这个图,我们可以直观地看到模型的预测效果。理想情况下,红色点应该尽可能接近蓝色点,表示预测准确。预测值偏离真实值的情况说明模型的准确性,还可以通过调整树的数量或正则化。
图3: 每一棵树的预测结果:这个图展示了随着每棵树的加入,模型的预测结果逐渐变化。绿色线条显示了所有树预测的累计效果。随着树的数量增加,模型逐渐拟合数据。可以看到,初始的预测偏差较大,但通过逐步加入更多的树,模型逐渐趋向真实值。
图4: 树的分裂点:这个图展示了每棵树的分裂点(即每棵树所选择的特征的分割值)。我们通过紫色散点来表示每棵树的分割点位置,并用橙色虚线表示特征 的均值。这个图可以帮助我们了解模型是如何根据数据进行分裂的。可以看到每棵树的分裂点都不同,它们根据数据的不同特征进行划分。
最后
整个手撸的方法有助于更好地理解 XGBoost 的核心思想,尽管在实际应用中,我们通常使用现成的库(如 xgboost)来高效地进行建模,但对于大家理解其背后的原理和推导对于深入掌握机器学习算法非常有帮助。
最近准备了16大块的内容,124个算法问题的总结,完整的机器学习小册,免费领取~
另外,今天给大家准备了关于「深度学习」的论文合集,往期核心论文汇总,分享给大家。

点击名片,回复「深度学习论文」即可~
如果你对类似于这样的文章感兴趣。
欢迎关注、点赞、转发~