
基于DNN加速器深度优先空间探索的硬件分析模型
本文介绍一篇发表在2023 IEEE High-Performance Computer Architecture(HPCA)的文章,该文章首先提出了DNN加速器的深度优先调度空间,该空间框架涵盖了从激活主导到权重,主导的网络,从片外DRAM到片上存储器数据移动,以及数据的缓存方式和网络的分解方式等众多信息,相比之前的分析框架更为全面具体,也能使支持的成本模型衡量评价更加到位。
论文地址:L. Mei, K. Goetschalckx, A. Symons and M. Verhelst, “DeFiNES: Enabling Fast Exploration of the Depth-first Scheduling Space for DNN Accelerators through Analytical Modeling,” 2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Montreal, QC, Canada, 2023, pp. 570-583, doi: 10.1109/HPCA56546.2023.10071098.
在具体提出该深度优先设计空间之后,本文又提出了一个统一的架构成本和性能的建模框架DeFiNES。在考虑每个内存级别的数据访问时,从能量和延迟两方面分析估计可能调度的硬件成本。通过优化选择每个操作数、层和特征映射块的唯一组合的内存层次结构的活动部分,为所研究的每个调度和硬件体系结构完成这项工作。同时,考虑到数据计算和数据复制两个阶段,对硬件成本进行了估计。并通过深度优先DNN加速器DepFiN的测量数据进行验证,在端到端神经网络层面显示出良好的建模精度。
欢迎加入自动驾驶实战群


Introduction
深度神经网络(Deep Neural Networks, DNN)目前已经很成熟,各种各样的硬件加速器正在被开发以提高其执行效率。在开发这种加速器时,一个关键的方面是如何将dnn映射到它们上。不同的执行顺序可能导致能量、延迟和内存占用方面的巨大差异。因此,能够快速评估给定进度、DNN和加速器的成本是很重要的。
为了做到这一点,需要一个支持各种调度、dnn和加速器的分析模型。现有的模型都只关注预测DNN在加速器上运行是的单层性能,然而,这些忽略了跨层调度的可能性,这可能导致非常次优的dnn级解决方案,因为在层之间传递数据会对整体系统性能产生很大影响。如图1-a所示,这是一种较为原始的调度方式,即单层调度SL,中间层的特征映射都写入或读进最高内存级别(即片外DRAM)。但DRAM往往会处理其他更多事务,总是频繁占用势必会影响性能。因此如果特征映射足够小,则可以将它们保持在更低、更高效的内存级别,如图1-b所示。这在本文中称为逐层LBL调度。
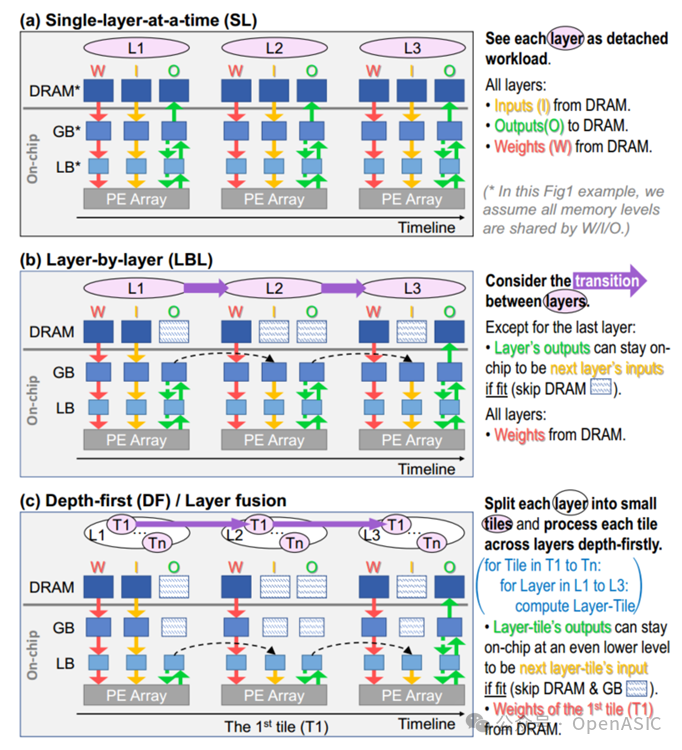
但如果特征图太大而无法进行这种优化,则可以探索“深度优先”DF调度,又称为层融合。这意味着只有部分中间特征映射(在本文中被称为tile)而不是整个特征映射一次计算并在层之间传递。这减少了在单个事务中要在层之间传递的数据的大小,这反过来又允许使用更小、更有效的内存级别来传递这些数据(如图1-c)。下文的设计空间探索将主要针对DF空间展开,而SL和LBL将会作为两个特殊顶点合并到该调度空间中,因此DF空间的全面性可见一斑。
Methods
本文的Methods主要由以下两部分组成,一是深度优先设计空间的具体维度规定,二是评估模型DeFiNES的评估步骤。
1.深度优先(DF)设计空间的三个坐标维度
遵循DF空间的设计思想,文中提出了与之有关的三个具体维度。
①tile size
考虑处理一个网络的多层,如图2-a和2-b所示。可以考虑最后一层的完整输入,这样就可以直接完整地算出最终输出的特征图,而这反过来又需要倒数第二层到最后一层的完整输出。以此类推完成了LBL推理,即从第一层开始一次一个地完全执行每个层。
或者也可以只计算最终特征映射输出的一部分。在这种情况下,只需要输入部分特征映射,如图2-c所示。推理从第一层开始,但只计算其输出特征映射中对最终输出特征映射中的目标块有贡献的那个块。然后将其传播到其他层,以计算最终特征映射中的目标tile。
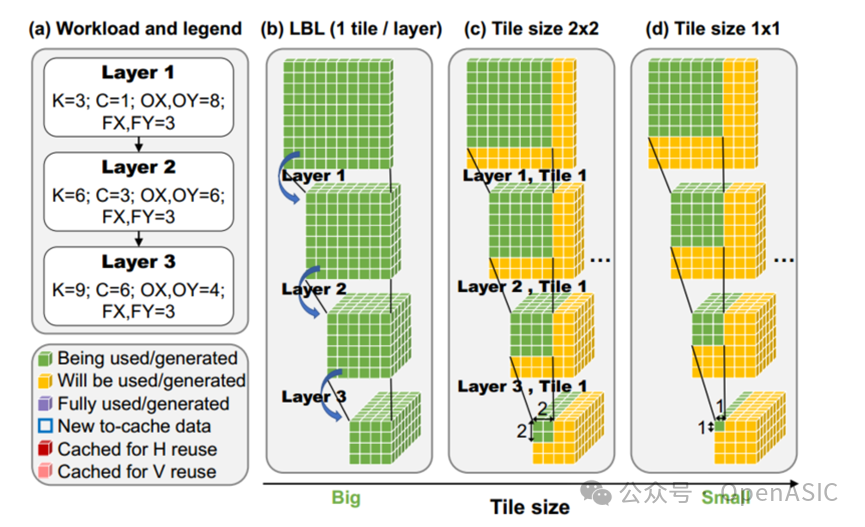
显然,tile大小的选择至关重要,这也构成了设计空间的第1个axis。当然文中重点强调是划分最后一层输出特征图,然后反算前面所有层中对最后输出tile有贡献的部分。这么做的目的是为了避免在正向传播的过程中,由于tile划分过小,导致中间某一层tile尺寸已经小于卷积核尺寸,无法进行卷积运算。另外可以注意的是,选择更大的tile大小可以增强局部权重重用,但需要同时在层之间传递更多特征,这可能需要更高级别的内存。
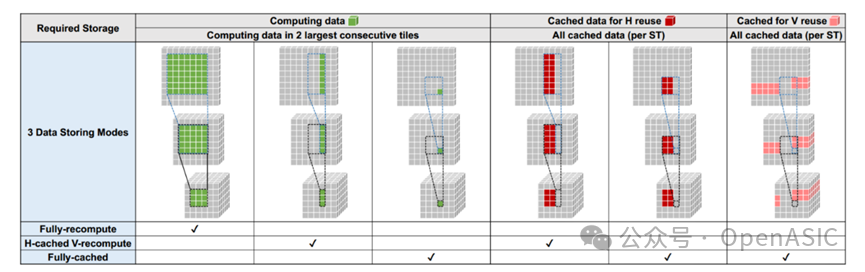
②overlap storage mode
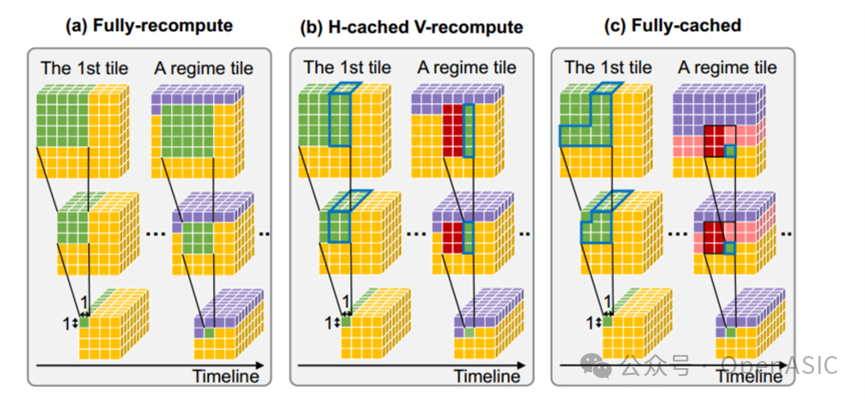
在上面的推理过程中,理论上只有最后一层输出tile是手动划分,推理得到的先前的中间特征图相邻tile均存在重叠部分,如图3所示。对于这些重叠部分,要么重新计算那些重叠的特征,要么将它们缓存在一些内存中,以便跨块重用它们,因此形成了DF空间中的第二个维度。理论上该维度下共有4种模式:完全重计算图3-a、水平缓存与垂直重计算图3-b、垂直缓存与水平重计算和完全缓存图3-c。但在这项工作中,我们没有进一步考虑垂直缓存与水平重计算,因为转置特征映射和相应的权重结果相同,也就是带来的存储量和重计算量没有区别。但垂直缓存与水平重计算的数据存储生命更长,因为tile的行进方式是先从左往右,再从上往下,因此overlap的数据要放在内存中一整行tile的时间,显然无故占用更长时间的存储空间对性能是不利的。
③Fuse depth
最后一个维度为层融合深度,如图4-b所示,可以只将部分层进行融合,称这些层为一个stack。每个stack运算结束后,会将输出特征图送到片外的DRAM中,下一个stack再从DRAM调入,并完成该stack中包含的层的卷积计算。因此,融合更多的层通常需要更多的低级别权重内存容量,但可以节省对激活的更高级别内存的访问。注意,不宜融合太多的层,因为增加底层存储器的存储容量会显著降低它们的效率。
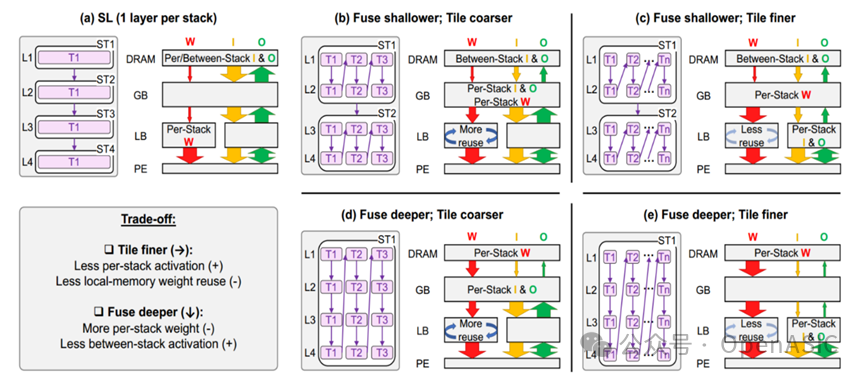
另外,正如先前所说,LBL推理和SL可以放在这个设计空间中。在tile size的维度上,可以将tile大小设置为DNN的最终输出特征映射(图2-b),即为LBL调度。另外,LBL调度将整个网络视为一个堆栈。
如果在每个stack中只包含一个层,即第3个维度中层融合深度为1,这就是SL调度(图4-a)。因为只有一个tile,因此对于SL和LBL来说,tile之间没有重叠,第二个维度不会带来影响。
2.统一成本分析模型DeFiNES的具体架构
图5展示了该模型的概述。该模型能够预测给定硬件架构上dnn的推理成本(能量和延迟),并支持深度优先(层融合)的完整设计空间。其基本思想是使用现有的映射搜索引擎和成本模型来优化和预测单个层的成本。然而,由于这些模型的单层限制,因此使用这些工具时要假设每一层的输入和输出特征映射需要分别来自并到达最高级的输入和输出存储器。定义然后提供统一分析成本模型作为其之上的一层,以提供深度优先兼容性,
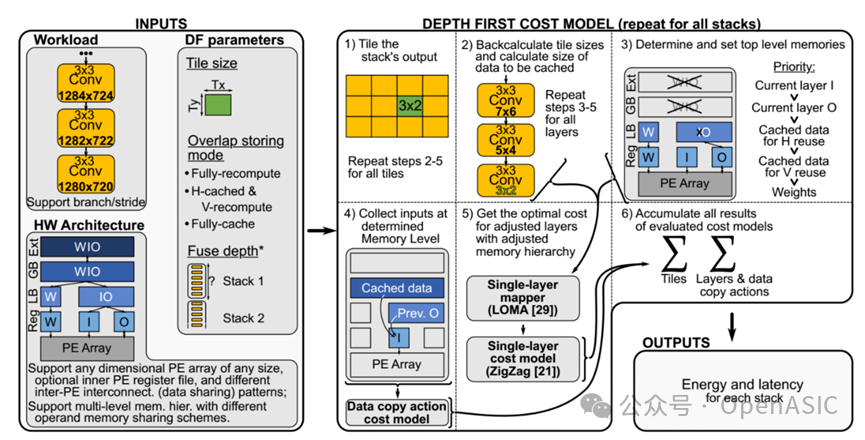
该分析模型由三个输入组成:
-
①工作负载:是一个神经网络,它可能有卷积层、分支层、池化层、跨步层、深度层等。 -
②HW硬件架构:由一组处理元素(pe)和一个内存层次结构组成。后者可以具有在操作数(输入、输出和权重)之间共享的内存、不同操作数的不同级别,以及在PE数组的一个或多个维度上展开的内存。 -
③DF参数:它确定了DF设计空间中的一个点,称为“DF策略”。其中第三个维度融合深度,可以手动给定或自动确定。在后一种情况下,只要堆栈中的权重总数符合保存权重的最高片上内存级别,就会向融合堆栈添加层。
当上述三个参数都确定了之后,便可以按照图5右侧所示的六个步骤对每个stack进行模型开销和性能的评估。以下具体解释这六个步骤:
①划分输出层的tile大小
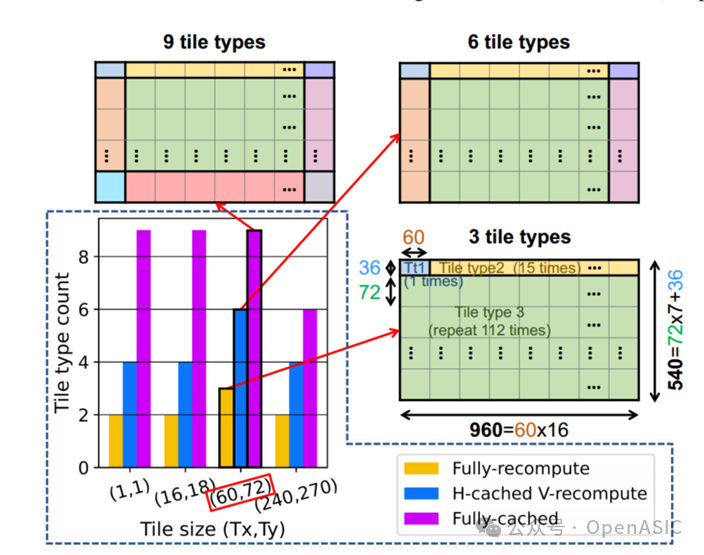
根据给出的DF参数,划分输出tile大小。值得注意的是,tile的大小不一定能够整除整个特征图的大小,并且在不同模式下,特征图边缘的tile缓存的读写情况和中间tile也有所不同,因此会形成不同的tile种类(如图6所示)。对于每种类型的tile,以下步骤2-6只需要执行一次,因为结果可以被复制到相同的tile副本上,从而显著减少了definitions的运行时间。tile类型的数量反映了实现解决方案的代码和控制复杂性,因为每种tile类型可以有不同的参数集和时间映射,这些都需要编程到加速器中。
②根据输出tile的大小,反算前面所有层的tile大小,并确定overlap的数据
如图7所示,在反向计算过程中,算法还跟踪图中每种类型的数据(来自先前或将来的重叠块)应该缓存多少。注意,如果没有缓存重用,需要重新计算的就是完整输入的tile中所有数据。然而,对于跨tile重用的缓存,并非所有这些特性都需要计算,因为有些特性可以从缓存的数据中获取。因此,这一跟踪是有必要的。
③对每一个tile,确定各类数据的最高级内存
在步骤②中,确定了每一层数据(包括输入、输出、缓存、权重等)的数量,根据这些数据种类的数据量大小和优先级,需要为其分配调度合适的内存级别。各类数据的优先级如图5右侧步骤3中所示。高优先级的数据会分配给等级更低,效率更高的内存级别。
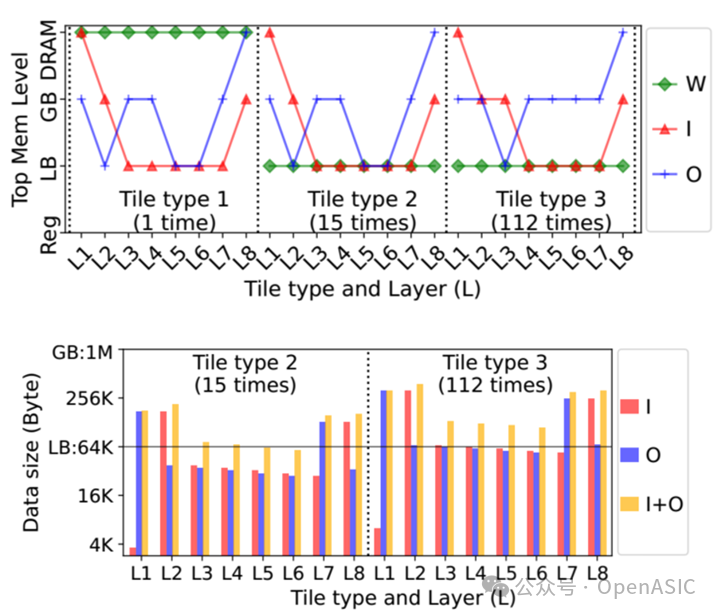
注意,分配给不同数据类型的最高内存级别在tile和层之间是不同的,即对特定的层,不同的tile种类会导致内存等级不同。图8给出一个具体的示例。左边为不同种类的tile每一层相关数据量的大小,右边为分配的内存等级。综合图8中上下两图来看,数据的内存分配规则如下:
-
(1)对权重,只有第1个tile从DRAM中获取权值,后续这些权值会分给对应tile的LB存储单元中(如果放得下),因此其他tile种类从LB中获取权值。 -
(2)对激活,所有种类tile的第1层输入都从片外DRAM获取,最后一层的输出都写入DRAM,其它的根据数据量的大小和优先级进行分配。分配规则为:1)当总激活大小(I+O)可以装入LB(例如Tile type 2 – L6)时,LB是I和O的顶级内存 2)当总激活大小(I+O)不能适合LB,而I或O都可以(例如,Tile类型3 – L6)时,I优先使用LB作为其最高内存级别,而O则被推至GB。
④在确定好的内存级别手机输入数据
根据③中的描述,单个layer-tile的组合可以拥有位于不同内存级别的输入特征数据,例如,前一层新创建的输出可以位于比前一图层缓存数据更低的内存级别。因此,在调用单层映射器和成本模型之前,我们对将这些数据统一收集到单个内存级别的操作进行建模,该内存级别被决定作为第③步中输入的顶级内存。若不存在这个情况,直接收集即可。
在统一内存级别的过程中,我们会需要将一部分数据进行复制,在文中称为“数据复制操作”,该操作由其移动数据类型和数量、源内存级别和目标内存级别建模。其开销则由数据复制操作开销模型进行计算。该模型采用数据一个复制操作列表和HW架构(定义了所有内存端口类型、端口连接、字长和每字访问成本)来分析这组数据复制操作所花费的能量和延迟,并考虑并发操作中可能出现的内存端口冲突。
⑤对每一层的每个tile,调用单层映射和开销模型
在统一内存级别之后,便可以调用单层映射器进行操作,以获取单层layer-tile组合的成本开销。在本文中,我们使用LOMA作为映射搜索引擎,使用ZigZag,提取代价。
⑥累计结果
对于每个堆栈中所有tile和layer,将步骤4和5中评估的所有成本模型的结果加在一起,以获得最终能量和延迟成本。
Experiment(Case Study)
文章进行了三个案例研究,以回答三个关键的DF调度问题。进行实验之前,作者选择了不同的硬件架构和DNN工作负载,以进行全面的实验记录和对比(如图9所示)。
对于硬件HW,作者选择了五个深度神经网络加速器作为案例研究的架构基线:Meta-prototype、TPU、Edge TPU、Ascend和Tesla NPU。由于这些架构大多为SL和LBL设计,为了更适用于本文提出的DF空间,作者手动为其构建了适合DF空间的friendly版本,构建的原则是:
-
1)空间展开不变; -
2)片上存储器总容量不变; -
3)输入和输出激活最好在较低级内存中共享; -
4)权重应该有一个芯片上的全局缓冲区。
而对于工作负载,共使用了五种DNN网络:FSRCNN, DMCNN-VD, MCCNN, MobileNetV1和ResNet18。下图显示,FSRCNN、DMCNN-VD和MCCNN是激活主导(所有层都有大的特征图),而MobileNetV1和ResNet18是权重主导(特征图更小,权重占比更高)。
案例1:DF参数对网络的影响
在本案例中,固定HW硬件架构和工作负载,只改变DF参数,即DF空间中三个维度的分量,进行性能的验证。
选用的HW架构为Meta-proto-like DF,工作负载为FSRCNN。由于FSRCNN网络本身权重数据量较小(如图9-b中1所示),可以存入最低等级内存中,因此再划分stack减小融合深度也没有太大影响,所以该案例会着重DF空间的第1、2个维度。
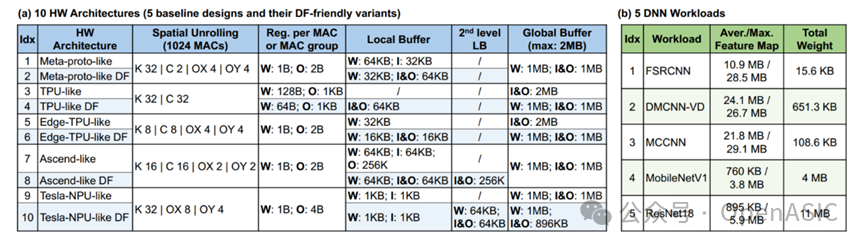
对于前两个轴,我们为三种重叠存储模式中的每一种扫描了110个tile大小(不同空间维度tile大小(Tx,Ty)组合)。结果的一个子集如图10所示,该热图显示了不同重叠存储模式下不同大小tile的总能量和延迟。
注意,FSRCNN最后一层的图图大小为960×540,因此每个热图(Tx=960, Ty=540)右下角的所有块都对应LBL处理。它们的能量和延迟数(分别为19.1和29)是相同的,因为不同的重叠存储模式对LBL没有影响。
从图10中可以提取出4个主要结果:
-
1)考虑相同重叠存储模式下不同的瓦片尺寸,瓦片尺寸过小和过大都是次优的。最好的点总是在中间的某个地方。 -
2)考虑到不同重叠存储模式下相同的贴图大小,大多数情况下能耗顺序为:full -cached < H-cached V-recompute < full -recompute。 -
3)不同的瓷砖大小和模式会严重影响能量和延迟(能量差异高达26倍,延迟差异高达57倍)。 -
4)完全重计算比完全缓存更喜欢更大的贴图大小。
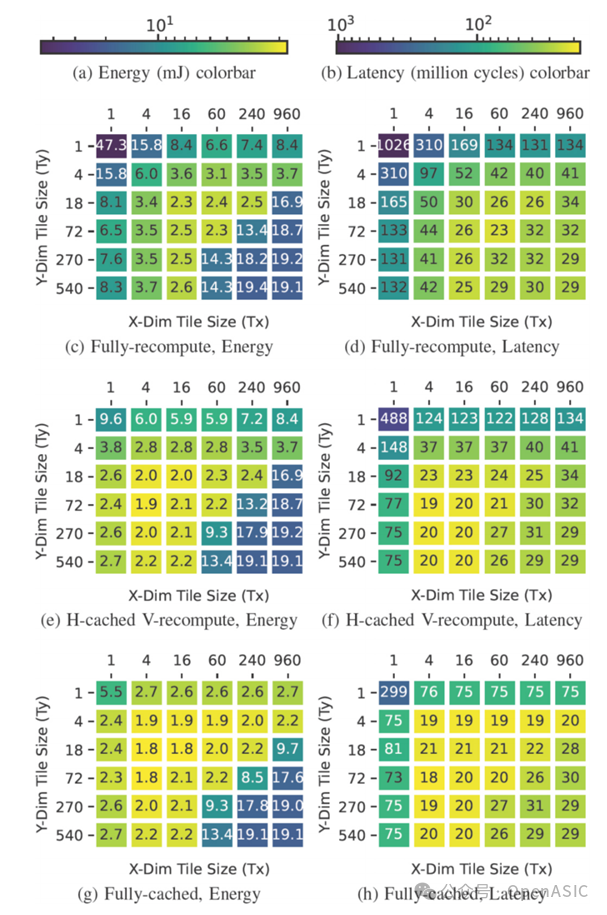
案例2:将DF参数运用到各种工作负载中的情况
本案例研究研究了不同的工作负载如何选择不同的DF策略。为此,我们将图9-b中的所有五种工作负载映射到meta-proto-like的硬件上,并比较了五种不同的推理策略:
-
1)SL:单层映射,层之间的特征映射总是存储到DRAM中并从DRAM中取出 -
2)LBL:一层接一层,中间特征映射被传递到下一层适合的最低的内存级别; -
3)DF完全缓存下,4×72的tile大小:这是案例研究1中的最佳情况; -
4)单一策略:在所有stack中使用单一策略时找到的最佳策略; -
5)最佳组合策略:其中不同的堆栈可以使用不同的DF策略,找到最好的组合。
结果表明:
-
① 对于特征映射数据较大的工作负载(FSRCNN, DMCNN-VD和MCCNN),它们的个体最佳解(紫色)并不明显优于案例研究1(绿色)中的最佳解,但却比传统的SL和LBL提升了约10倍的性能。 -
② 关于①的结果,在MobileNetV1和ResNet18这种特征映射数据较小的网络上表现不佳。例如,在MobileNetV1上,它比最佳结果差2.0倍。在这些工作负载中,更深的层的权重更大,这阻碍了将它们融合到一个堆栈中。最佳解决方案应为将DF应用于第一层,即激活主导层,将LBL应用于最后一层,即权重主导层。这种组合在MobileNetV1上实现了5.7倍的增益。
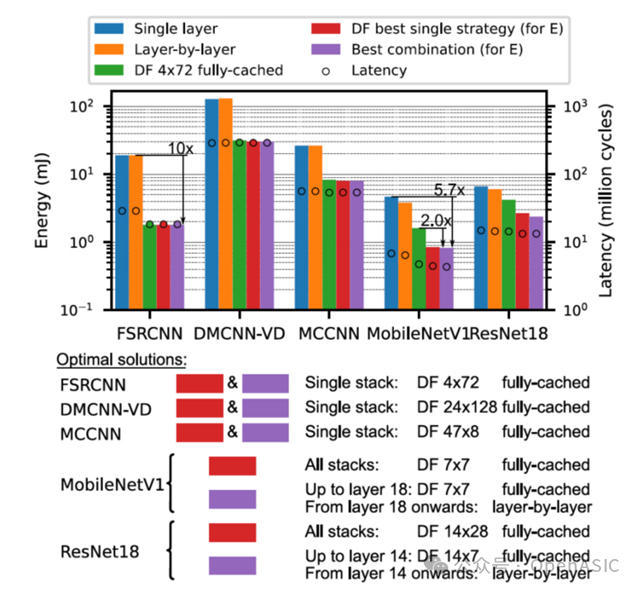
案例3:加速器体系结构与多工作负载调度的联合DSE
本案例研究考察了加速器结构对最佳推理策略的影响,特别是将上图中默认架构和DF-friendly架构进行了比较。图12展示了比较结果。
结果显示,除了TPU-like的架构,DF在所有加速器架构上都优于LBL,包括未进行DF-friendly调整的默认加速器。TPU-like的原因是缺少片上权重缓冲,对DF调度的支持很差。改进成DF-friendly的架构后,也显著优于LBL,这也体现出设计时考虑DF兼容性的重要性。DF友好型和默认型之间的整体比较进一步支持了这一发现,这表明DF友好型在使用DF时至少与默认型一样好,对于tpu-like和edge-tpu-like的硬件分别有6.0倍和4.3倍的增益,而使用LBL时最大差1.2%。
Conclusion
这项工作首次提出了深度优先(层融合)设计空间的定义,然后给出了处理整个设计空间的开销模型。此外,开销模型不仅考虑了由于激活而产生的DRAM访问或内存访问,还考虑了由权重流量引起的完整片上内存层次结构和内存访问。
案例研究表明,使用该模型时,即使工作负载不是激活主导(MobileNetV1和ResNet18),或硬件不是DF-friendly的,深度优先策略也可以显着优于逐层执行。而有些体系结构可能不适合深度优先,在这种情况下,对其设计的小调整也会导致大的改进。例如,重新分配一些架构的片上内存容量,使其能够从深度优先策略中受益等。这些示例展示了DeFiNES快速检查深度优先策略和硬件架构的不同组合的复杂设计空间的能力。
关注我们
实验室网站 http://viplab.fudan.edu.cn
微信公众号 OpenASIC
官方网站 www.openasic.org
知乎专栏 http://zhuanlan.zhihu.com/viplab