
收录于话题
2024年12月3日arXiv cs.CV发文量约200余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省89分钟浏览arXiv的时间。


北京大学和中国科学院大学联合推出了HandOS方法,作为一种用于3D手部重建的端到端框架。该框架将手部检测、2D姿态估计和3D网格重建整合为单阶段过程,消除了左右分类的需求,有效减少了计算冗余和错误。
【Bohr精读】
https://j1q.cn/yPHcJqEg
【arXiv链接】
http://arxiv.org/abs/2412.01537v1
【代码地址】
idea-research.github.io/HandOSweb
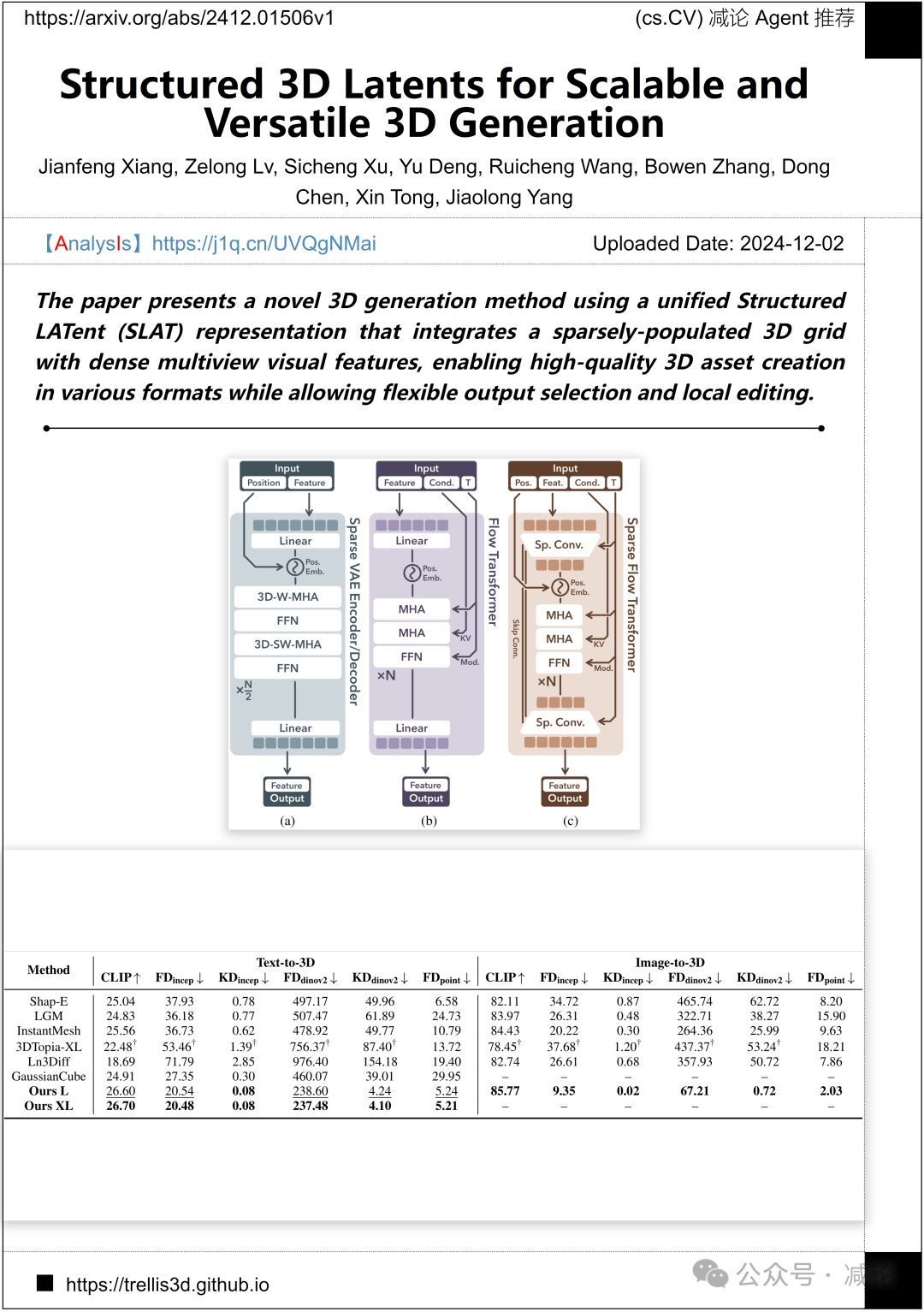
清华大学、中国科学技术大学和微软研究院提出了一种新颖的3D生成方法,采用统一的结构化潜在(SLAT)表示,结合稀疏分布的3D网格与密集的多视图视觉特征。该方法实现高质量的3D资产创建,支持多种格式,允许灵活的输出选择和局部编辑。
【Bohr精读】
https://j1q.cn/UVQgNMai
【arXiv链接】
http://arxiv.org/abs/2412.01506v1
【代码地址】
https://trellis3d.github.io

香港大学、加利福尼亚大学默塞德分校和商汤科技研究院提出了SyncVIS方法,这是一个用于视频实例分割的同步建模框架。该框架结合了视频级和帧级查询嵌入,采用新颖的视频–帧建模范式和嵌入优化策略,在具有挑战性的基准上取得了最先进的结果。
【Bohr精读】
https://j1q.cn/oB17Fxjf
【arXiv链接】
http://arxiv.org/abs/2412.00882v1
【代码地址】
https://github.com/rkzheng99/SyncVIS

穆罕默德·本·扎耶德人工智能大学、北京大学和中山大学联合开发了PhysGame,这是一个评估视频大语言模型物理常识理解的基准,使用了带有故障的游戏视频。同时,研究团队提出了PhysVLM,这是一种通过指令微调和偏好优化数据集来增强物理知识的视频大语言模型。
【Bohr精读】
https://j1q.cn/COPchl6O
【arXiv链接】
http://arxiv.org/abs/2412.01800v1
【代码地址】
https://github.com/PhysGame/PhysGame

上海交通大学与阿里巴巴集团推出了一种用于足球视频理解的多模态框架,包括SoccerReplay-1988数据集和MatchVision模型,在动作分类和解说生成等任务中取得了最先进的性能。
【Bohr精读】
https://j1q.cn/4fYyvaAi
【arXiv链接】
http://arxiv.org/abs/2412.01820v1
【代码地址】
https://jyrao.github.io/UniSoccer/

INSAIT、索非亚大学“圣克里门特·奥赫里德斯基”、印度理工学院瓦拉纳西分校和谷歌深度学习联合提出了一种训练大型视觉语言模型的方法,使用了6500万张图像和2亿个问答对的大规模数据集。该方法在视觉问答任务上进行了性能基准测试,增强了对博物馆展品的理解。
【Bohr精读】
https://j1q.cn/Nt1id7HM
【arXiv链接】
http://arxiv.org/abs/2412.01370v1
【代码地址】
https://github.com/insait-institute/Museum-65
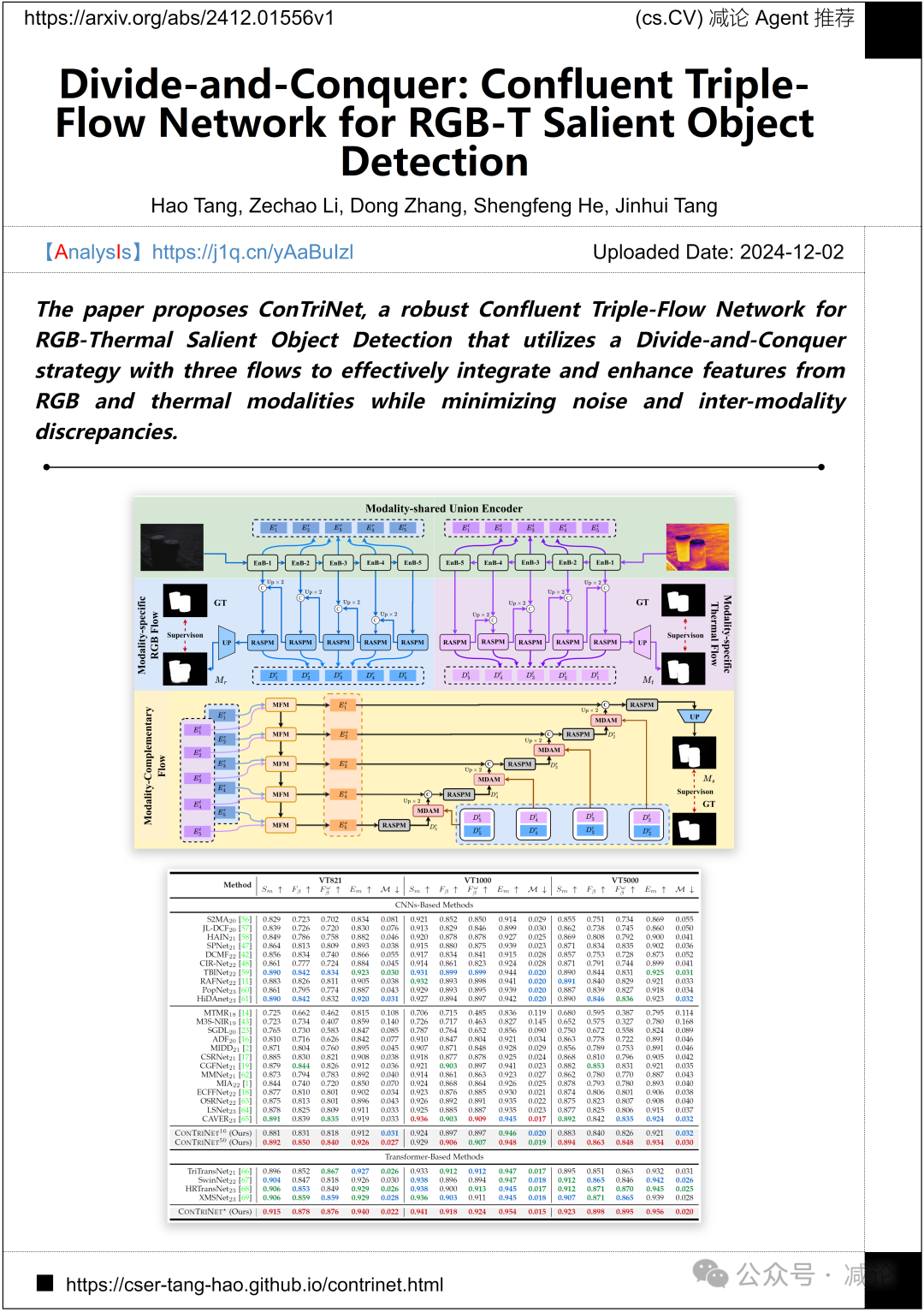
南京理工大学、香港科技大学和新加坡管理大学提出了ConTriNet方法,一种用于RGB-热成像显著目标检测的三流网络。该方法通过三条流有效整合和增强RGB与热成像模态的特征,同时减少噪声和模态间差异。
【Bohr精读】
https://j1q.cn/yAaBuIzl
【arXiv链接】
http://arxiv.org/abs/2412.01556v1
【代码地址】
https://cser-tang-hao.github.io/contrinet.html

香港中文大学提出了一种Video-3D LLM,利用将3D场景视为动态视频并结合3D位置编码的方法,显著增强了3D场景理解能力,并在多个基准测试中取得了最先进的性能。
【Bohr精读】
https://j1q.cn/Z8uAYBrA
【arXiv链接】
http://arxiv.org/abs/2412.00493v1
【代码地址】
https://github.com/LaVi-Lab/Video-3D-LLM

复旦大学与百度公司提出了一种基于transformer的视频生成模型,用于动画化肖像图像。该模型解决了非正面视角、动态物体和沉浸式背景的挑战。通过身份参考网络确保面部身份一致性,并利用语音音频驱动实现连续视频生成。
【Bohr精读】
https://j1q.cn/Kx1z0N7z
【arXiv链接】
http://arxiv.org/abs/2412.00733v1
【代码地址】
https://github.com/fudan-generative-vision/hallo3

南京理工大学推出了一个包含多种退化的百万级真实世界图像数据集,并介绍了强大的模型FoundIR。该模型结合了基于扩散的通用模型和退化感知的专业模型,以增强图像在各种真实场景中的修复能力。
【Bohr精读】
https://j1q.cn/kTFBi4kH
【arXiv链接】
http://arxiv.org/abs/2412.01427v1
【代码地址】
https://www.foundir.net

中国科学技术大学与香港理工大学提出了一种新方法,利用姿态引导的图像到视频扩散模型和3DGS网格混合表示,从单张图像创建逼真且可动画的全身说话头像。该研究解决了动态建模及新手势和表情的泛化问题。
【Bohr精读】
https://j1q.cn/UFZcrXf8
【arXiv链接】
http://arxiv.org/abs/2412.01106v1
【代码地址】
https://ustc3dv.github.io/OneShotOneTalk/

阿里巴巴集团与上海交通大学提出了一种新颖的整体范式用于对比语言–图像预训练(CLIP)。该方法为每个图像生成多样化的多文本,并采用多对多对比优化,显著增强了对齐效果,提高了视觉–语言任务的可解释性和泛化能力。
【Bohr精读】
https://j1q.cn/mmOWHbcX
【arXiv链接】
http://arxiv.org/abs/2412.00440v1
【代码地址】
https://github.com/anakin-skywalker-Joseph/Holistic-CLIP
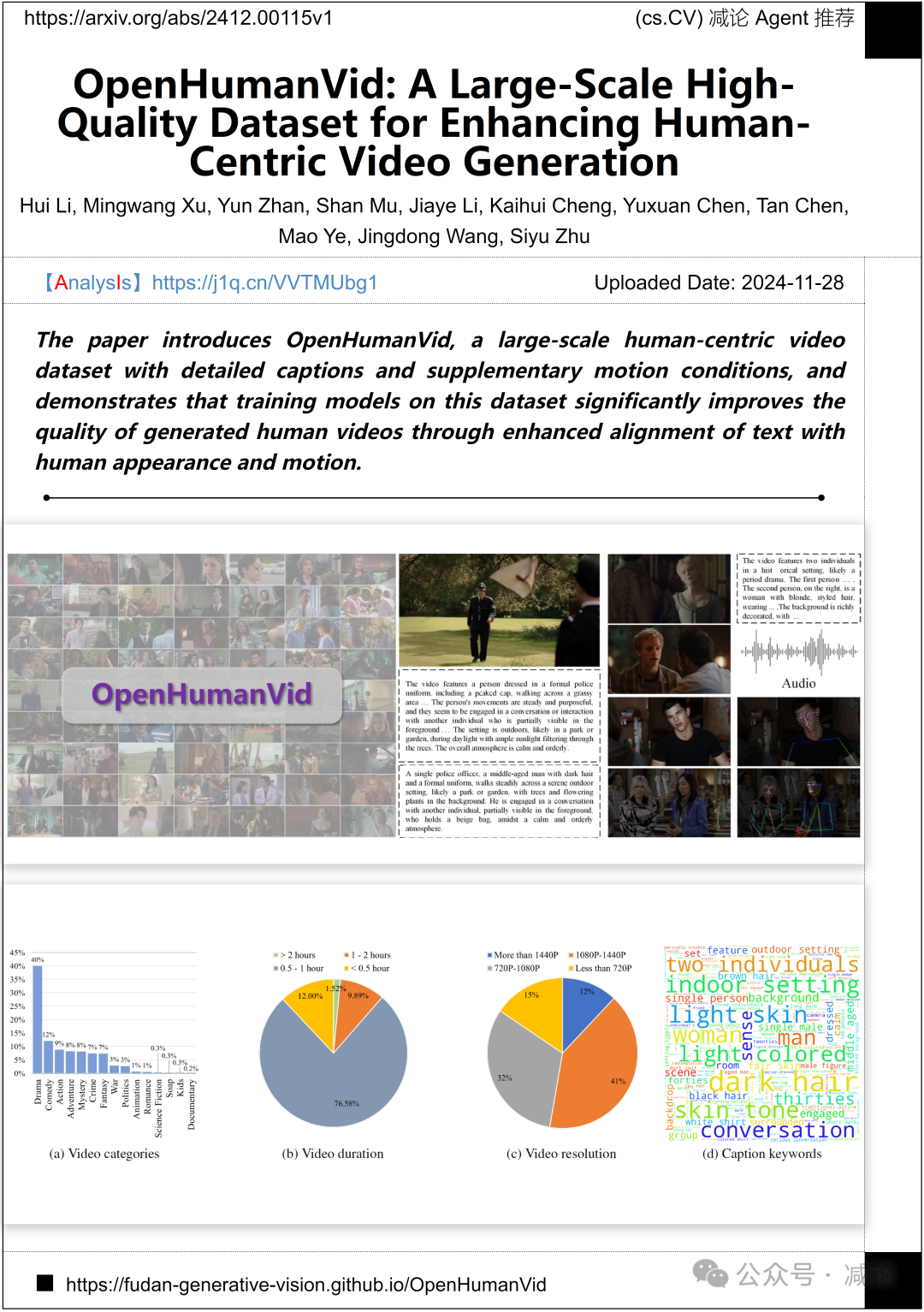
复旦大学、上海交通大学和百度公司联合推出了OpenHumanVid,一个包含详细字幕和补充运动条件的大规模视频数据集。研究表明,在该数据集上训练模型显著提升了生成的人类视频质量,增强了文本与人类外观和运动的对齐。
【Bohr精读】
https://j1q.cn/VVTMUbg1
【arXiv链接】
http://arxiv.org/abs/2412.00115v1
【代码地址】
https://fudan-generative-vision.github.io/OpenHumanVid
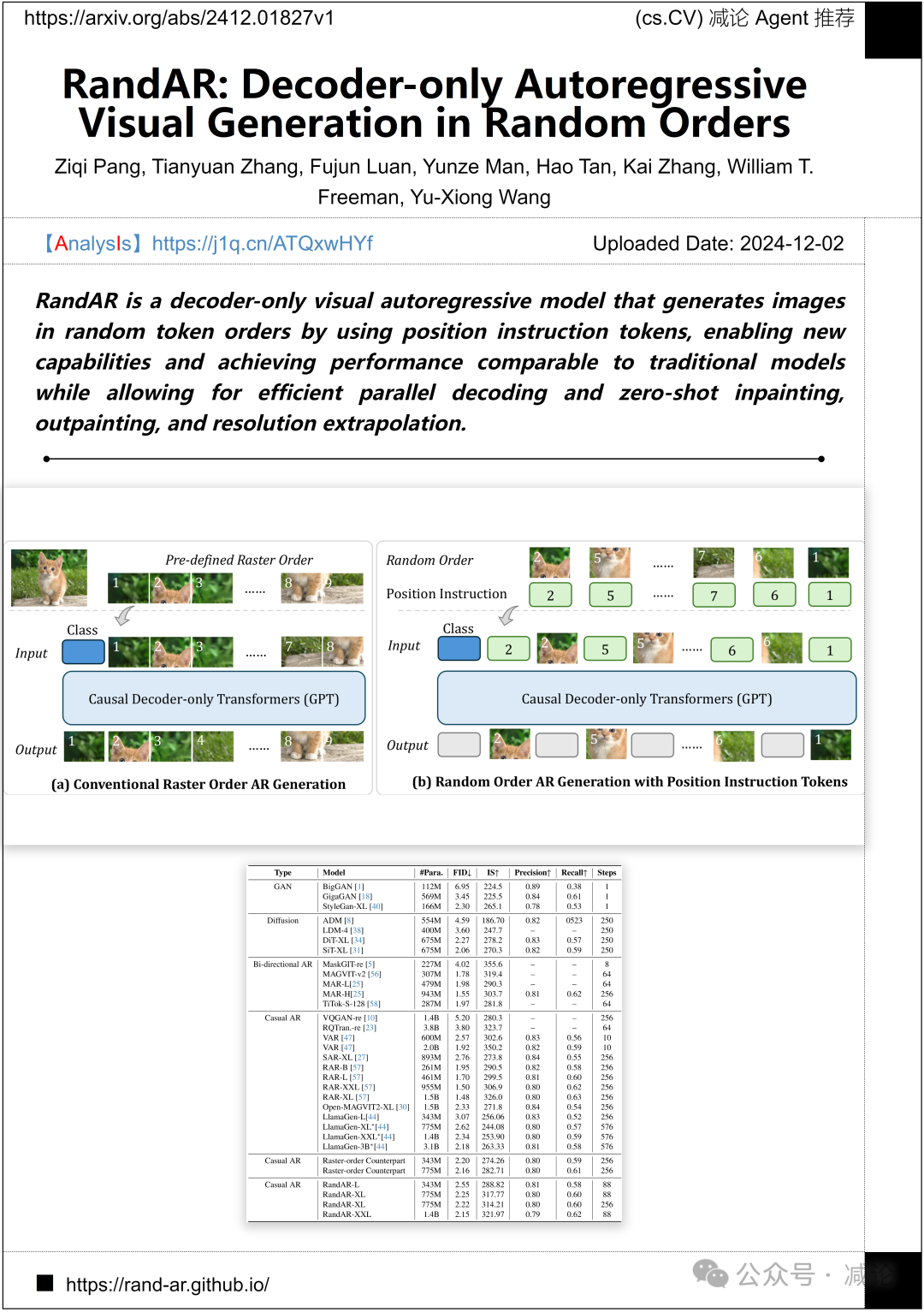
伊利诺伊大学厄本那–香槟分校、麻省理工学院和Adobe研究提出了一种名为RandAR的视觉自回归模型,该模型仅使用解码器。RandAR通过位置指令token以随机token顺序生成图像,具备高效的并行解码、零样本图像修补、扩展和分辨率外推的能力,同时实现了与传统模型相当的性能。
【Bohr精读】
https://j1q.cn/ATQxwHYf
【arXiv链接】
http://arxiv.org/abs/2412.01827v1
【代码地址】
https://rand-ar.github.io/
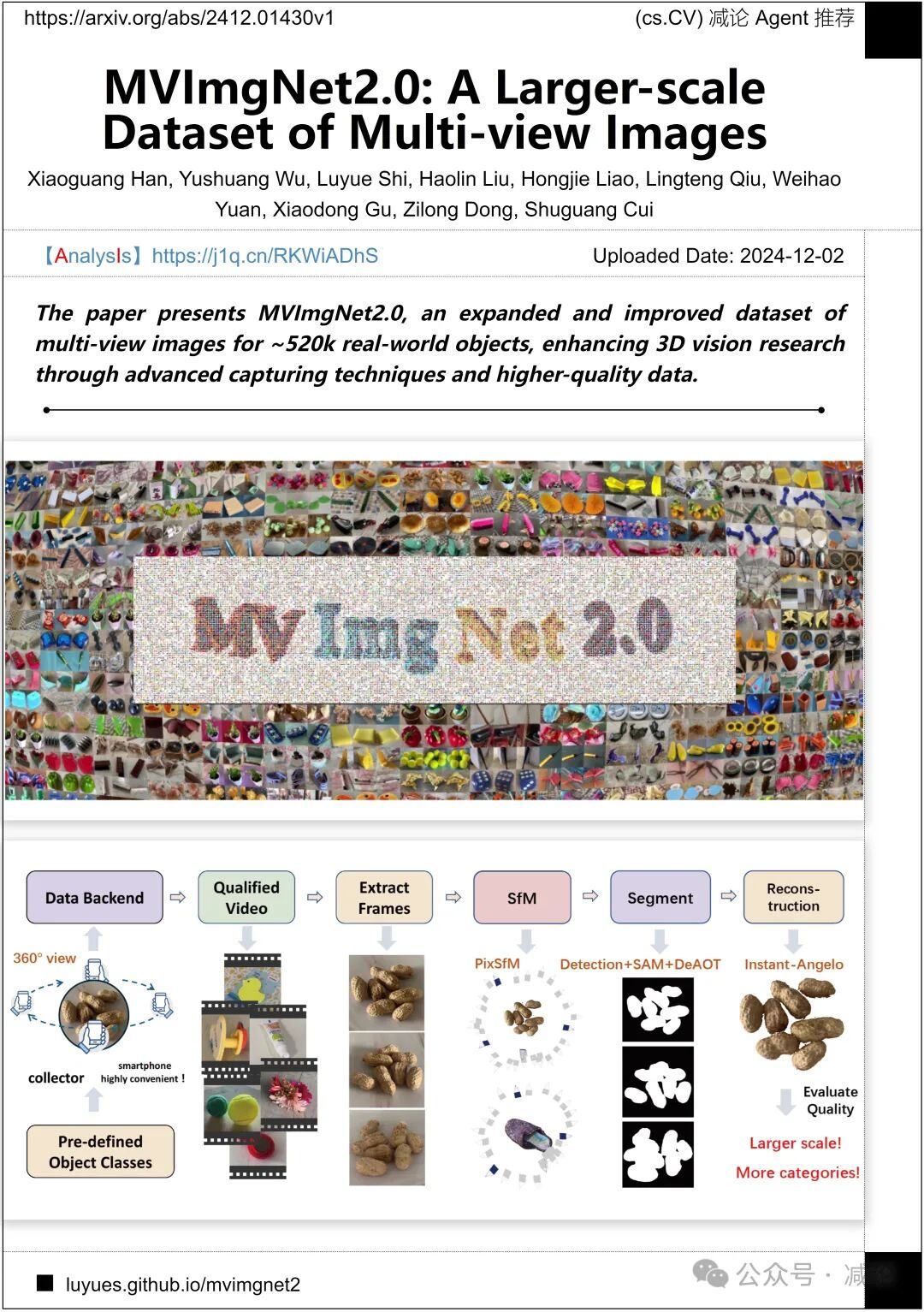
香港中文大学(深圳)与阿里巴巴集团联合推出MVImgNet2.0,这是一个扩展和改进的多视图图像数据集,包含约52万真实世界物体。该数据集采用先进的捕捉技术,提供更高质量的数据,以提升3D视觉研究的效果。
【Bohr精读】
https://j1q.cn/RKWiADhS
【arXiv链接】
http://arxiv.org/abs/2412.01430v1
【代码地址】
luyues.github.io/mvimgnet2

武汉理工大学、湖北大学和南洋理工大学提出了一种新颖的提示学习框架,称为语义上下文集成(SCI),用于衣物更换行人再识别(CC-ReID)。该框架利用CLIP的视觉–文本表示增强ID相关特征,并通过语义分离增强(SSE)模块和语义引导交互模块(SIM)最小化衣物更换的影响。
【Bohr精读】
https://j1q.cn/fTCDziX5
【arXiv链接】
http://arxiv.org/abs/2412.01345v1
【代码地址】
https://github.com/
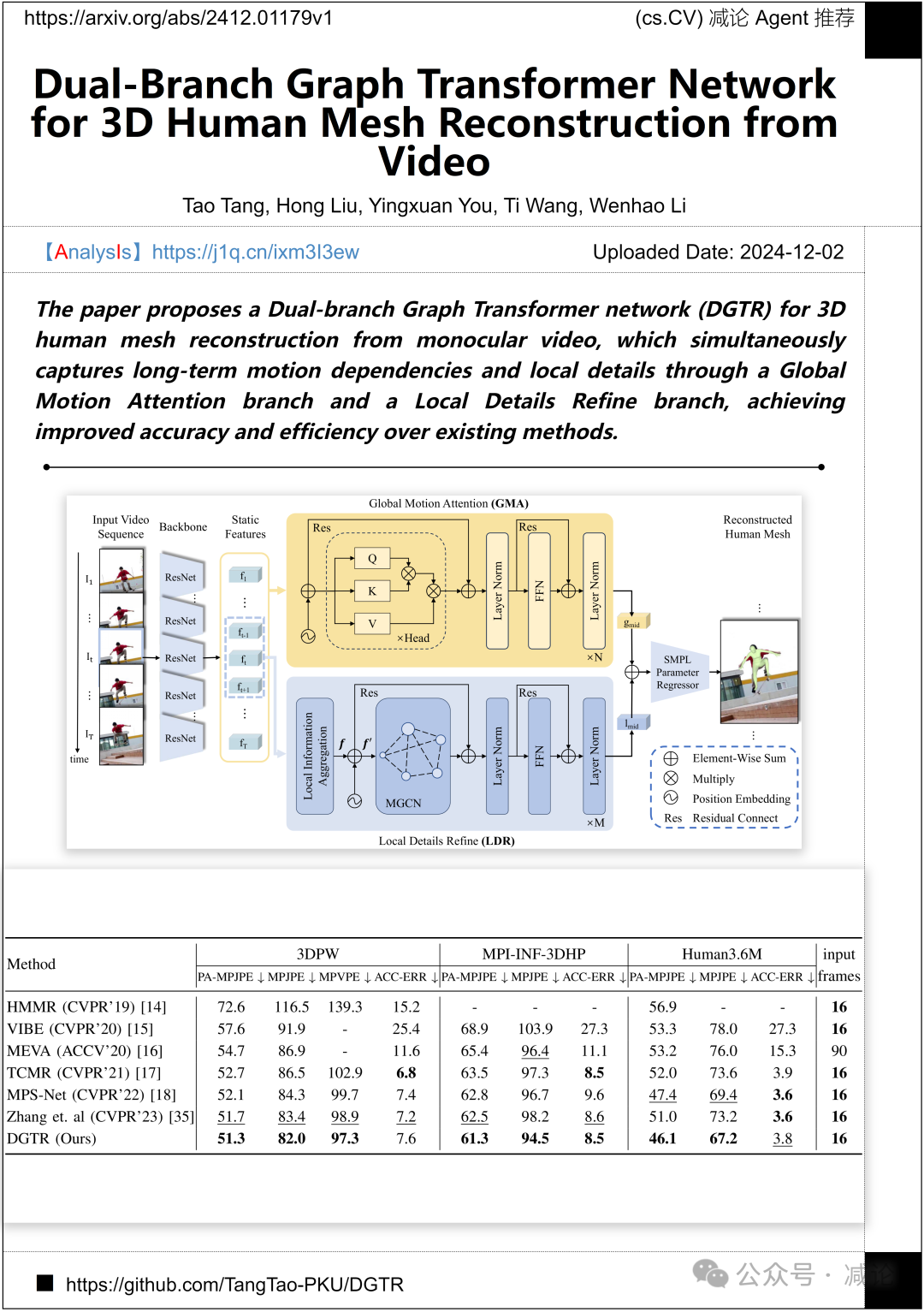
北京大学提出了一种双分支图形Transformer网络(DGTR),用于从单目视频重建3D人体网格。该网络通过全局运动注意力分支捕捉长期运动依赖,同时通过局部细节优化分支提升局部细节,从而显著提高了准确性和效率。
【Bohr精读】
https://j1q.cn/ixm3I3ew
【arXiv链接】
http://arxiv.org/abs/2412.01179v1
【代码地址】
https://github.com/TangTao-PKU/DGTR

蚂蚁集团推出了EmojiDiff,一种用于身份保留肖像生成的细粒度表情控制端到端解决方案。该方法以RGB表情图像作为输入模板,通过解耦方案将表情特征与身份信息分离。研究利用与身份无关的数据迭代和身份增强对比对齐,显著提升了合成质量和身份保真度。
【Bohr精读】
https://j1q.cn/8UY8Bp2E
【arXiv链接】
http://arxiv.org/abs/2412.01254v1
【代码地址】
https://emojidiff.github.io
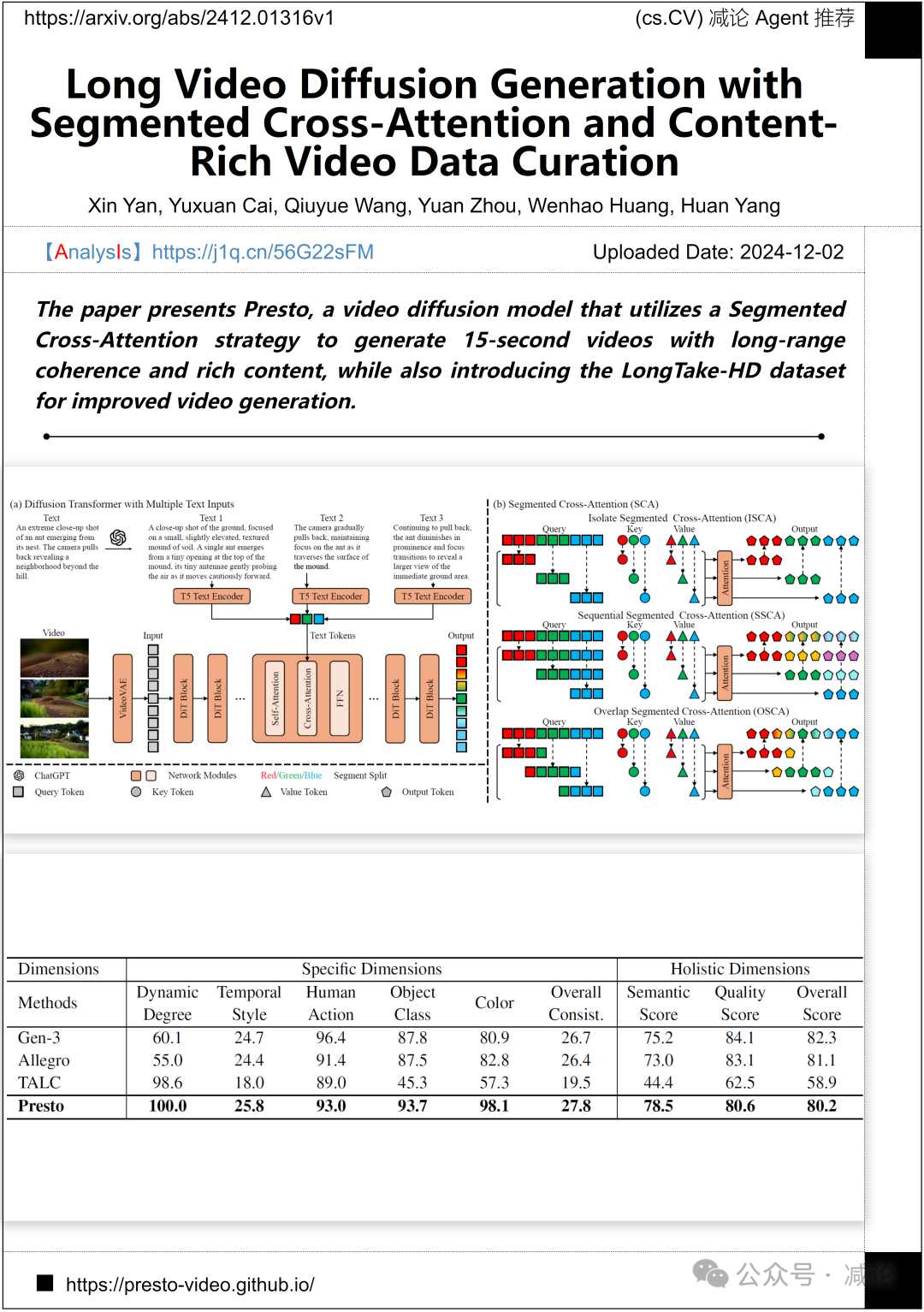
Presto是一种视频扩散模型,采用分段交叉注意力策略生成长达15秒的连贯且内容丰富的视频。此外,引入了LongTake-HD数据集以增强视频生成效果。
【Bohr精读】
https://j1q.cn/56G22sFM
【arXiv链接】
http://arxiv.org/abs/2412.01316v1
【代码地址】
https://presto-video.github.io/
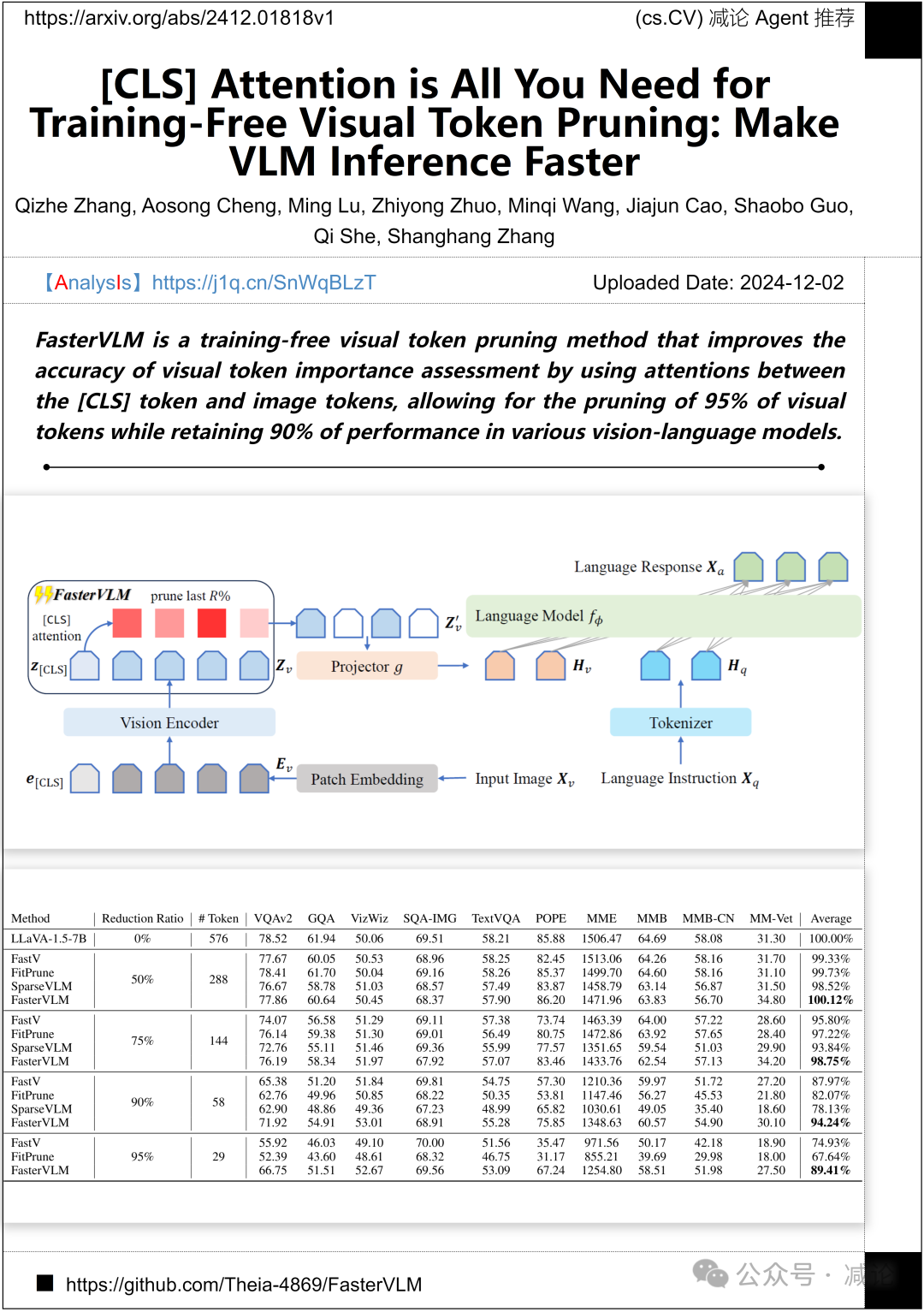
北京大学、英特尔实验室中国和字节跳动提出了FasterVLM,一种无需训练的视觉token剪枝方法。该方法通过分析[CLS] token与图像token之间的注意力,提升视觉token重要性评估的准确性。FasterVLM能够在保留90%性能的前提下,剪枝95%的视觉token。
【Bohr精读】
https://j1q.cn/SnWqBLzT
【arXiv链接】
http://arxiv.org/abs/2412.01818v1
【代码地址】
https://github.com/Theia-4869/FasterVLM

北京大学、香港科技大学和中佛罗里达大学提出了DreamDance方法。该方法利用扩散模型,从二维姿态序列中高效提取三维几何线索,能够生成高质量动画,并增强帧内连贯性和帧间一致性。
【Bohr精读】
https://j1q.cn/gx63V6XX
【arXiv链接】
http://arxiv.org/abs/2412.00397v1
【代码地址】
https://pang-yatian.github.io/Dreamdance-webpage/

欢迎关注减论,持续输出有深度的人工智能极减理解,提升信息获取效率和认知维度。看完点颗小星星再走呗~