
作者:中投靓仔
链接:https://zhuanlan.zhihu.com/p/9584597631
最近在研究机器人领域的Visual Grounding任务,把今年上半年用来给Grounding-dino制作Image-Text Pair数据集的BLIP系列工作总结一下。Instruction BLIP是2023年的工作,它是一种根据图像内容和文本指令进行文本生成的模型,可以用于VQA,caption等很多任务。本文从BLIP V1开始分享Instruction BLIP的原理。
欢迎加入自动驾驶实战群


-
BLIP V1
-
整体网络结构
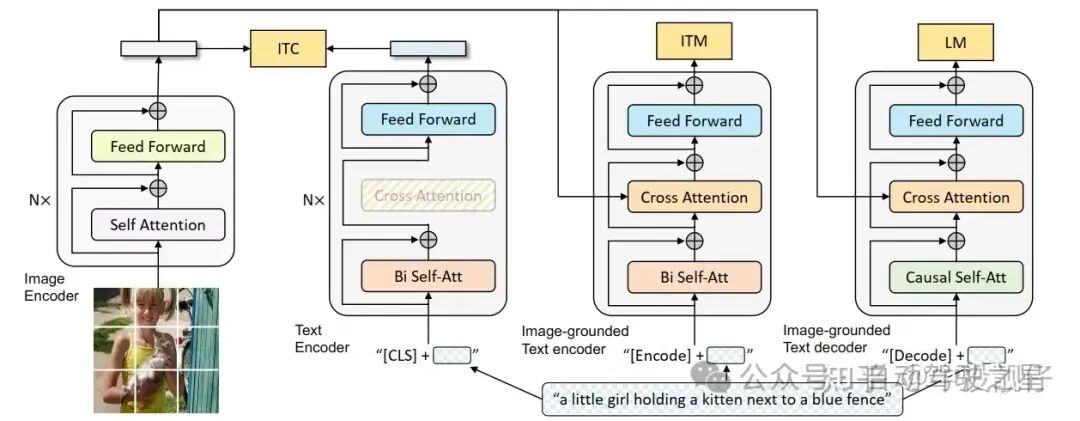
上图中颜色相同的模块是参数共享的。BLIP V1通过ITC,ITM,LM三个子任务来完成image-text的特征融合。
Bi Self Attention:就是正常的transformer attention结构,word embedding可以看到左右两侧其他word的信息并做融合。适用于Bert这种结构。
Casual Self Attention:用一个下三角mask将后面的内容全部遮住,当前的word只能看到前面的,不能看到后面的word信息。适用于生成式的LM,例如GPT。
-
ITC
contrastive loss:在batch内构造相似性矩阵,交叉熵损失作为约束,目的是让text-image的特征对齐。下图是CLIP中截取的:
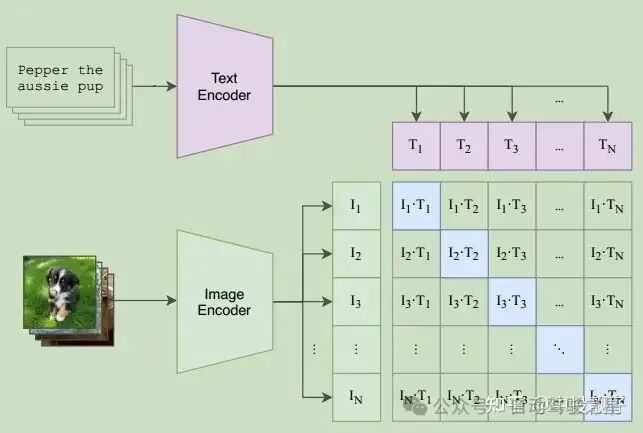
-
ITM
ITM出自于另外一篇paper:
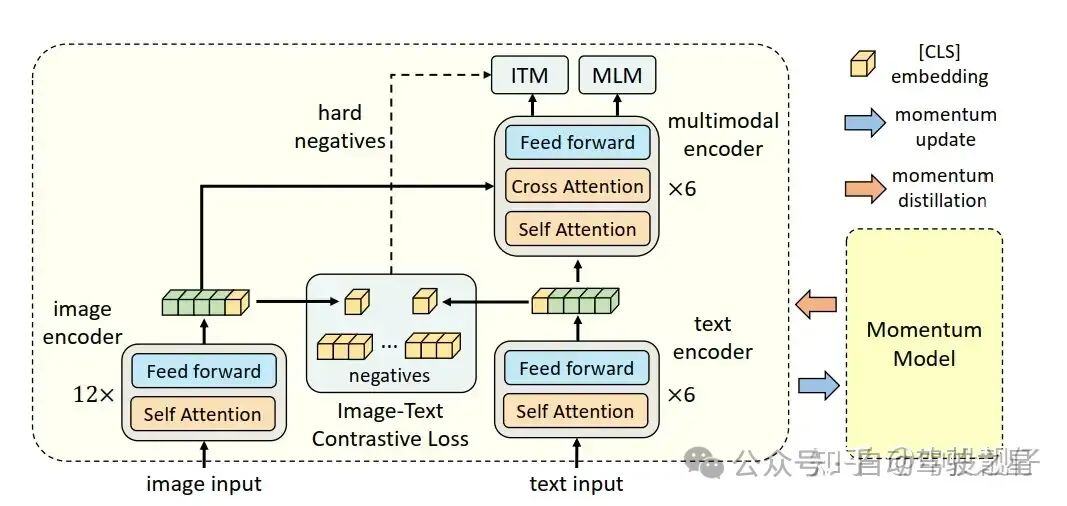
ITM子任务中,一段文本经过self attention和corss attention之后,取第一个embedding,这个embedding在self-attention中看到了全部的文本内容,并在cross attention中获取了图像特征。这个embedding经过FC层构造二分类问题。相当于是想让text-image融合后的特征能够胜任这个分类任务,进一步地提升文本-图像特征的对齐能力。
在这个过程中,如果cross attention是 对应的text-image做的,那么label就是1;另一方面还需要提供一些负样本,这时候会从ITC(CLIP)中找到得分数第二高的,当作负样本。
-
LM
LM就是一个文本生成模型。
-
BLIP V2 和 Instruction BLIP
BLIP V2的训练方式如下:
-
pretrain stage1:frozen image encoder,训练Q-former
-
pretrain stage2:frozen LLM,训练Q-former+Image Encoder
-
finetune:frozen LLM,训练Q-former + Image Encoder(我感觉这里Image Encoder可以不学,因为pretrain的时候图像特征已经学差不多了,instruction blip就把image encoder给frozen了)
Instruction BLIP 是在BLIP V2的pretrain model上进行Instruction Finetune的。因此,Instruction BLIP相当于是一种在pretrain model上的finetune方法。下面把两个一起讲了。
-
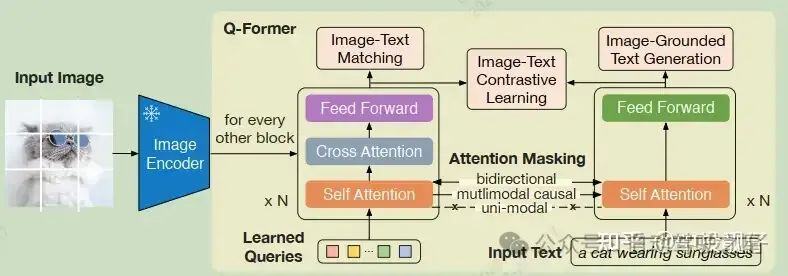
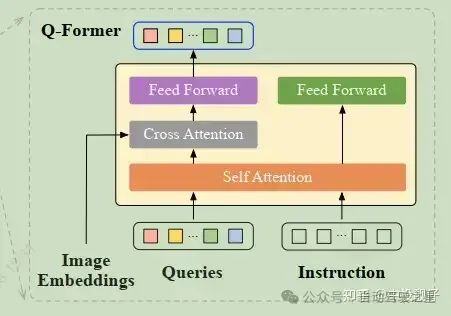
Q-Former
像沙漏一样提取图像中和文本强相关的关键特征。
Q-Former的结构是两个并行的transformer,self attention的输入比较特殊,是Queries和Input Text在sequence维度上拼接,self attention的过程中有相互的信息融合。
-
左侧:Queries融合了文本信息,和图像特征做cross attention,获取到和文本强相关的信息。
-
右侧:是一个生成类的LM模型,文本融合了图像信息,生成和图像相关的文本,所以叫做“Image Grounded Text Generation”
这样做的好处是:Query的数量为超参32,这个应该是远小于Image encoder输出的embeddings的数量,左侧相当于是提取了和文本强相关的图像特征,像是一个沙漏过滤掉不重要的信息。这样在text-image特征对齐的时候能削弱灾难性遗忘。
-
Pretrain Stage1:Representing Learning
跟BLIP1差不多,也是ITM,ITC,ITG三个任务。只不过这里需要用mask避免信息泄露
ITC:主要是用来约束文本特征和图像特征的对齐,因此在self attention时,它们互相不可以看到对方
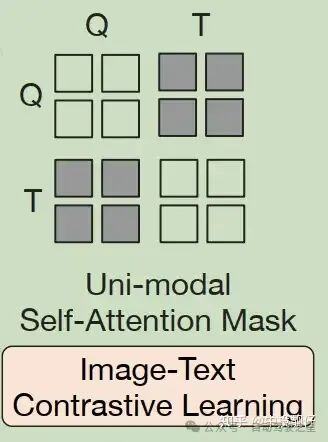
ITG:简单讲是根据图像的信息生成文本,所以Text可以随便看Q的内容,但是在Text的内部,前面的文本不能看到后面的。

ITM:这个任务输出的特征是文本-图像融合后的特征。相当于是想让text-image融合后的特征能够胜任这个分类任务,进一步地提升文本-图像特征的对齐能力。因此,这个子任务中就是想让Q和T相互看到。
-
Pretrain Stage2
先思考:paretrain stage1训练出来的Q-Former具有什么能力?
在stage2中使用的时候,Q-Former输入只有一张图(并没有文本)。

回头看下面这张图:在训练ITG这部分的时候,Input Text这部分是用下三角的掩码mask住的。在Input Text前会有一个[decoder]的embedding,或者blabla其他的embedding,总之这个embedding表示我要开始解码输出文本了。这里主要是根据在self-attention中获取到的图像信息来进行解码,当解码出靠前的word后,后面的文本才能根据前面的图像特征+文本特征继续进行解码。所以还是要再次关注下Image-Grounded Text Generation这个命名,很有意义。换句话说,即便只输入了Image和Queries,Q-former也能自行生成出文本。
前面的pretrain阶段只是让模型有根据图像进行文本生成的能力,输入一张图,输出文本描述,类似caption。和具体的下游任务例如VQA等还没有一点关系,下游任务需要finetune。
-
Instruction Tuning
看了一些Instraction Tuning的工作,它们都指的是基于pretrain model进行finetune的工作。这里的Instruction就是和下游任务相关的指令。BLIP加Instruction的位置有两个:
-
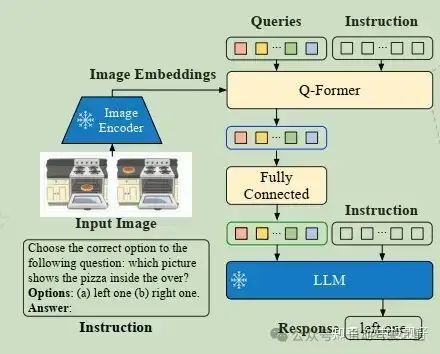
Q-Former的输入:加在与Queries并列的位置,Finetune的时候让Queries提取的图像特征与任务更相关
LLM的输入:接在visual prompt的后面,让LLM理解任务训练的方式是Multi-Task,就是把caption,vqa等等全部的任务混在一起训练。
-
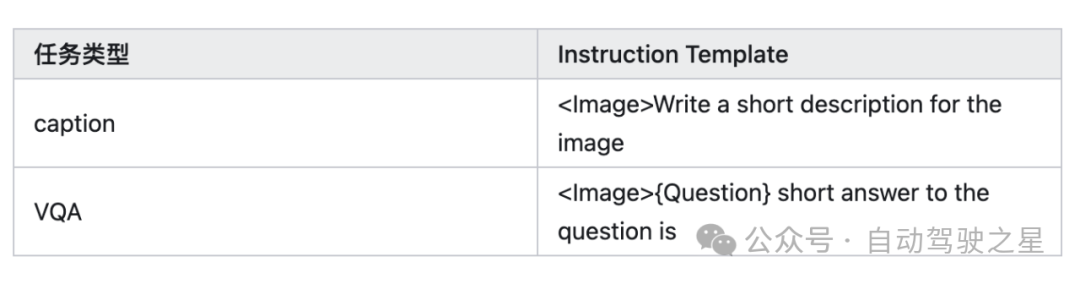
Instruction Template
-
数据
Web Data数据制作:
爬虫到Image-Text Pair数据,将Image输入到最大的BLIP模型中,生成10个不同的caption(通过语言模型的参数控制)。然后将10个语言模型和Web text 与 Image之间使用CLIP计算相似性,保留相似性最大的两个caption,作为训练数据。在pretrain 的不同epoch,随机选取两个caption中的一个。
-
参数含义
huggingface:https://huggingface.co/spaces/hysts/InstructBLIP
-
number of beams
Beam search方法中,每一次选取 n=5 个概率最大的词
-
Max Length
生成sentence的最大词数量
-
Top P
Nucleus方法中,每一次选取概率总和刚好等于P的最小数量的words
-
Temperature
设置温度改变词的概率分布: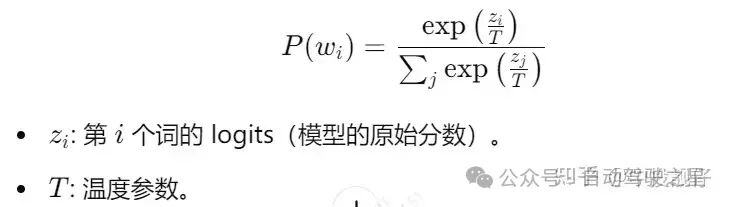
当温度很小时,模型选择的是概率最高的词;温度=1时,就是标准的softmax,默认的就是1;温度很大时,输出更加不稳定,生成的文本多样。所以,问答系统一般T<1,生成类的任务T=1,或者T>1.Length Penalty 长度惩罚系数也是改变词的概率分布,通过下面的公式直接改变每个词的得分值。我的理解是α越大,概率值越小,同时EOS的概率值越小,越不容易停止。

最后别忘了,帮忙点“在看”。
您的点赞,在看,是我创作的动力。
AiFighing是全网第一且唯一以代码、项目的形式讲解自动驾驶感知方向的关键技术。
长按扫描下面二维码,加入知识星球。
