
大家好~
这几天有同学问到关于支持向量机、以及核支持向量机 的内容。
咱们今天就把这些内容和大家做一个完整的分享,一文搞懂~
什么是支持向量机(SVM)?
SVM 是一种用来分类数据的工具。假设你有两类不同的数据(比如苹果和橘子),SVM 的目标是找到一条“线”(在更高维度可能是“面”或“超平面”),把这两类数据分开。而且这条线需要离两类数据中的点都尽可能远,确保分类稳健。
直观例子:
想象你在沙滩上划了一道线,把红色的贝壳和蓝色的贝壳分开,你会选择这样一条线,让红的和蓝的各自尽可能远离这条线,这样当新贝壳出现时,你可以用这个线判断它是红色还是蓝色。
那什么是「核技巧」呢?
有时候,你的两类数据可能根本无法用一条直线分开。这时候怎么办呢?咱们需要 核技巧(Kernel Trick)。
举个例子:
-
假设你有一个圆形的盘子,里面有红色豆子和蓝色豆子,红豆在中心,蓝豆在外围。 -
如果你试图在二维平面上用一条线分开这些豆子,根本做不到对吧?因为无论怎么划线,都会混淆红豆和蓝豆。 -
这时,「核技巧」就像把盘子整个拿起来,往空中弹一下,让数据从二维变成三维!在三维空间里,红豆可能会被抬到一个高度,而蓝豆仍然分布在平面上。这时你可以用一个平面(而不是线)来把红豆和蓝豆分开。
核支持向量机是怎么做到的?
核支持向量机利用数学公式把数据从低维“映射”到高维空间(就像刚刚从二维盘子到三维空间),让它更容易找到分割边界。
-
低维世界里:数据看起来混乱,无法分开。 -
高维世界里:数据变得“干净整齐”,可以用一个简单的面分开。
核技巧的好处是,你不需要真的手动把数据搬到高维,而是通过数学公式计算完成,大大节省时间和资源。
现实生活中的例子
你是一家外卖平台的客服,想根据订单情况判断顾客是否满意。你收集了以下两个指标:
-
等餐时间(分钟) -
配送距离(公里)
发现问题:
-
如果你只看等餐时间,不能区分满意和不满意,因为有的顾客等了很久但很满意。 -
如果你只看配送距离,也不能区分,因为有的顾客远的也满意。
数据在二维平面上看起来混在一起(类似咱们的盘子例子)。但如果你加一个额外维度,比如顾客心情指数(主观评分),你可能发现满意和不满意的数据点可以更清楚地分开。
解决方法:
核支持向量机通过数学计算,把这些数据点“映射”到一个新的空间,在那里找到分割线(或超平面),轻松分类满意和不满意的顾客。
数学原理
1. 问题表述
对于一组数据点 :
-
是特征向量 -
是分类标签
支持向量机目标是找到一个决策边界:
使得最大化分类间隔,并满足约束条件:
2. 优化问题
转化为拉格朗日形式:
通过拉格朗日乘子 :
对偶问题:
其中:
-
是核函数。
咱们选择 高斯核:
完整案例
咱们手动实现以下步骤:
-
数据生成与可视化 -
使用高斯核函数计算核矩阵 -
实现支持向量机的训练(对偶问题求解) -
数据分类及结果分析
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import minimize
# 1. 数据生成
np.random.seed(0)
# 生成两类数据
class1 = np.random.randn(1000, 2) + [2, 2]
class2 = np.random.randn(1000, 2) + [-2, -2]
X = np.vstack((class1, class2))
y = np.hstack((np.ones(1000), -np.ones(1000)))
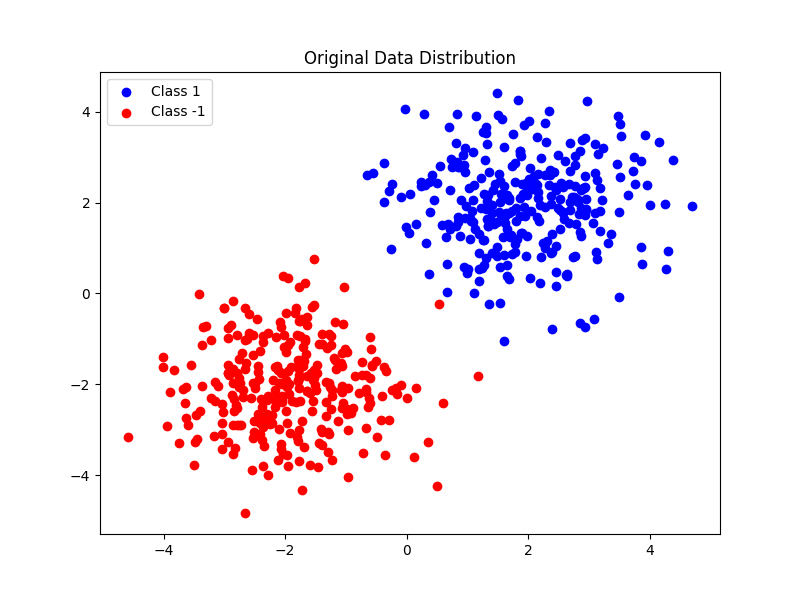
# 2. 可视化原始数据
plt.figure(figsize=(8, 6))
plt.scatter(class1[:, 0], class1[:, 1], color='blue', label='Class 1')
plt.scatter(class2[:, 0], class2[:, 1], color='red', label='Class -1')
plt.title("Original Data Distribution")
plt.legend()
plt.show()
# 3. 核函数定义(高斯核)
def gaussian_kernel(x1, x2, sigma=1.0):
return np.exp(-np.linalg.norm(x1 - x2) ** 2 / (2 * sigma ** 2))
# 4. 核矩阵计算
def compute_kernel_matrix(X, kernel_func):
n_samples = X.shape[0]
K = np.zeros((n_samples, n_samples))
for i in range(n_samples):
for j in range(n_samples):
K[i, j] = kernel_func(X[i], X[j])
return K
K = compute_kernel_matrix(X, gaussian_kernel)
# 5. SVM 对偶问题的求解
def svm_dual(alpha, K, y):
return -np.sum(alpha) + 0.5 * np.sum((alpha * y)[:, None] * (alpha * y) * K)
# 约束
def constraint_eq(alpha):
return np.dot(alpha, y)
# 边界条件
bounds = [(0, 1) for _ in range(len(y))]
constraints = {'type': 'eq', 'fun': constraint_eq}
# 初始值
alpha0 = np.zeros(len(y))
# 求解优化问题
result = minimize(
fun=svm_dual,
x0=alpha0,
args=(K, y),
bounds=bounds,
constraints=constraints,
method='SLSQP'
)
alpha = result.x
# 6. 计算 w 和 b
support_vector_indices = np.where(alpha > 1e-5)[0]
w = np.sum((alpha[support_vector_indices] * y[support_vector_indices])[:, None] * X[support_vector_indices], axis=0)
b = np.mean(y[support_vector_indices] - np.dot(X[support_vector_indices], w))
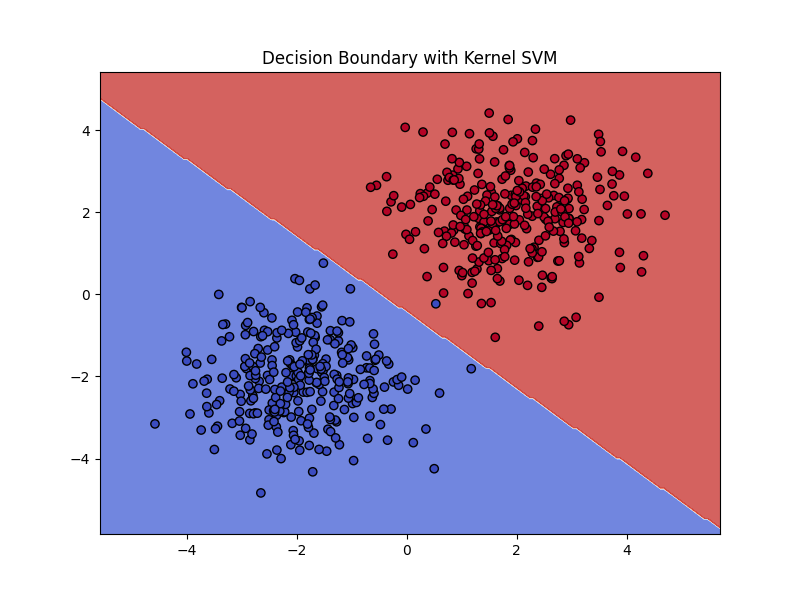
# 7. 可视化分类结果
def plot_decision_boundary(X, y, w, b):
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 200), np.linspace(y_min, y_max, 200))
grid = np.c_[xx.ravel(), yy.ravel()]
Z = np.sign(np.dot(grid, w) + b).reshape(xx.shape)
plt.figure(figsize=(8, 6))
plt.contourf(xx, yy, Z, alpha=0.8, cmap='coolwarm')
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='coolwarm', edgecolors='k')
plt.title("Decision Boundary with Kernel SVM")
plt.show()
plot_decision_boundary(X, y, w, b)
# 8. 支持向量的可视化
plt.figure(figsize=(8, 6))
plt.scatter(class1[:, 0], class1[:, 1], color='blue', label='Class 1')
plt.scatter(class2[:, 0], class2[:, 1], color='red', label='Class -1')
plt.scatter(X[support_vector_indices, 0], X[support_vector_indices, 1], s=100, facecolors='none', edgecolors='yellow', label='Support Vectors')
plt.title("Support Vectors Highlighted")
plt.legend()
plt.show()
1. 原始数据分布图:展示两类数据的初始分布。

2. 决策边界图:展示 SVM 学到的分类边界。
3. 支持向量分布图:高亮显示支持向量。

最后
