
收录于话题
2024年12月2日arXiv cs.CV发文量约200余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省91分钟浏览arXiv的时间。
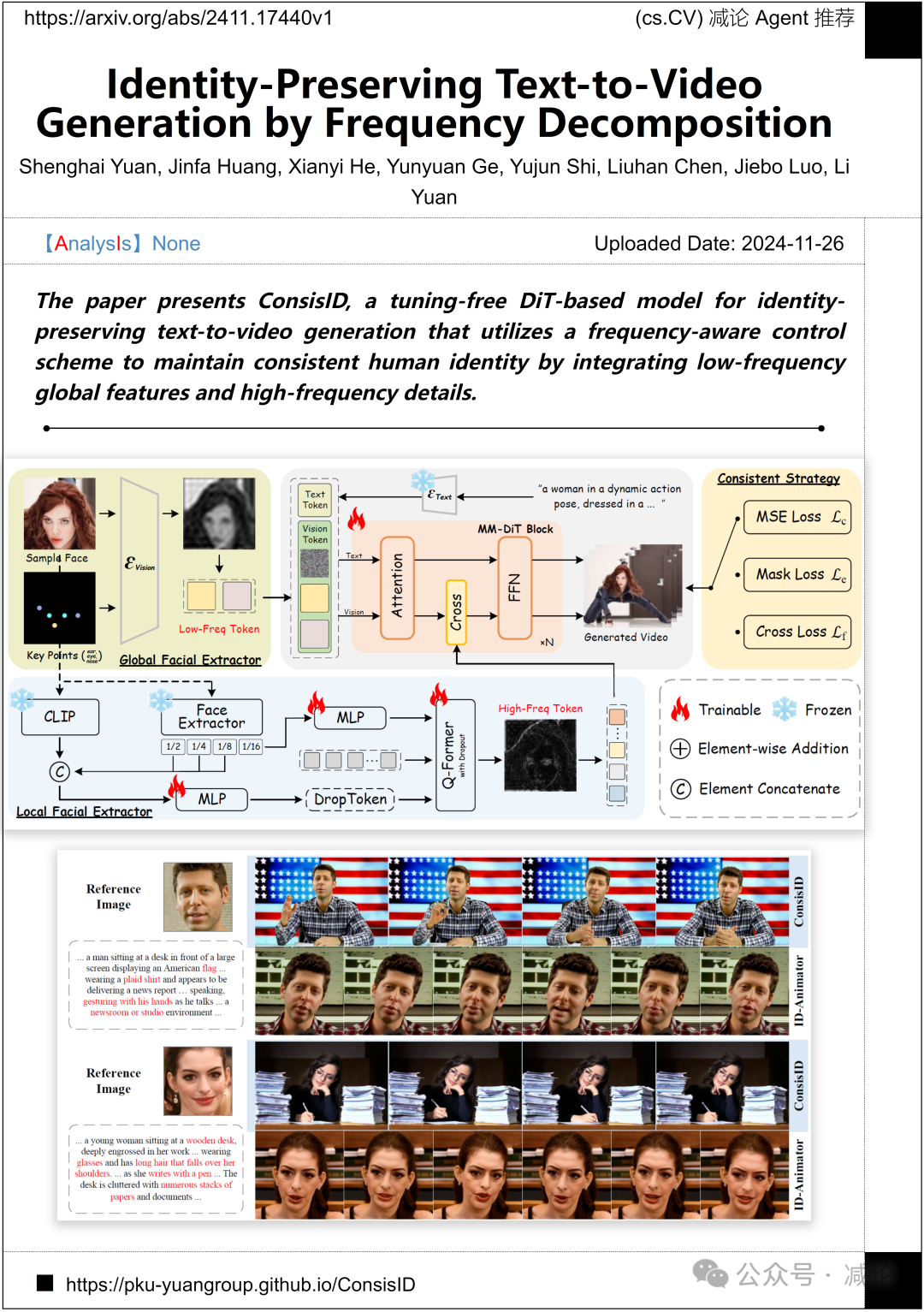

北京大学、罗切斯特大学和新加坡国立大学联合提出了ConsisID方法,这是一种基于DiT的免调优模型,用于身份保持的文本到视频生成。该模型通过频率感知控制方案整合低频全局特征和高频细节,以保持一致的人类身份。
【Bohr精读】
https://j1q.cn/MC0ibekO
【arXiv链接】
http://arxiv.org/abs/2411.17440v1
【代码地址】
https://pku-yuangroup.github.io/ConsisID

中国科学院自动化研究所、中国科学院大学和北京师范大学提出了ProtoGCN方法。这是一种图卷积网络模型,通过可学习的原型关注局部骨架组件的细粒度运动细节,从而增强基于骨架的动作识别,能够有效区分相似动作。
【Bohr精读】
https://j1q.cn/zioh9MpL
【arXiv链接】
http://arxiv.org/abs/2411.18941v1
【代码地址】
https://github.com/firework8/ProtoGCN

穆罕默德·本·扎耶德人工智能大学、伦敦大学学院和澳大利亚国立大学联合推出了GEOBench-VLM方法,专门用于评估地理空间任务中的视觉语言模型。该方法针对场景理解、物体计数和时间分析等独特挑战。
【Bohr精读】
https://j1q.cn/AUMl9QhZ
【arXiv链接】
http://arxiv.org/abs/2411.19325v1
【代码地址】
https://github.com/The-AI-Alliance/GEO-Bench-VLM

慕尼黑工业大学与马克斯·普朗克智能系统研究所提出了GaussianSpeech方法。该方法结合语音信号与3D高斯喷射,利用音频条件的transformer模型,能够捕捉详细的面部动作和表情,从语音音频中合成个性化的3D人头头像高保真动画序列。这一技术为语音驱动的动画生成提供了新的视角,具有广泛的应用潜力。
【Bohr精读】
https://j1q.cn/dHSbNPHV
【arXiv链接】
http://arxiv.org/abs/2411.18675v1
【代码地址】
https://shivangi-aneja.github.io/projects/gaussianspeech

慕尼黑工业大学提出的SpaRC是一种稀疏融合transformer方法,结合了多视角图像语义与雷达和摄像头点特征。该方法采用稀疏视锥融合、范围自适应雷达聚合和局部自注意力机制,显著提升了自动驾驶的3D感知能力。与传统的基于密集BEV的方法相比,SpaRC在效率和准确性上均有显著提升。
【Bohr精读】
https://j1q.cn/BqsIeTmd
【arXiv链接】
http://arxiv.org/abs/2411.19860v1
【代码地址】
https://github.com/phi-wol/sparc

阿卜杜拉国王科技大学、穆罕默德·本·扎耶德人工智能大学和牛津大学提出了MatchDiffusion方法。这是一种无需训练的技术,通过文本到视频扩散模型生成匹配剪辑。MatchDiffusion采用两步扩散过程对齐场景结构和运动,生成视觉连贯的视频。
【Bohr精读】
https://j1q.cn/yhVY1AUM
【arXiv链接】
http://arxiv.org/abs/2411.18677v1
【代码地址】
https://matchdiffusion.github.io
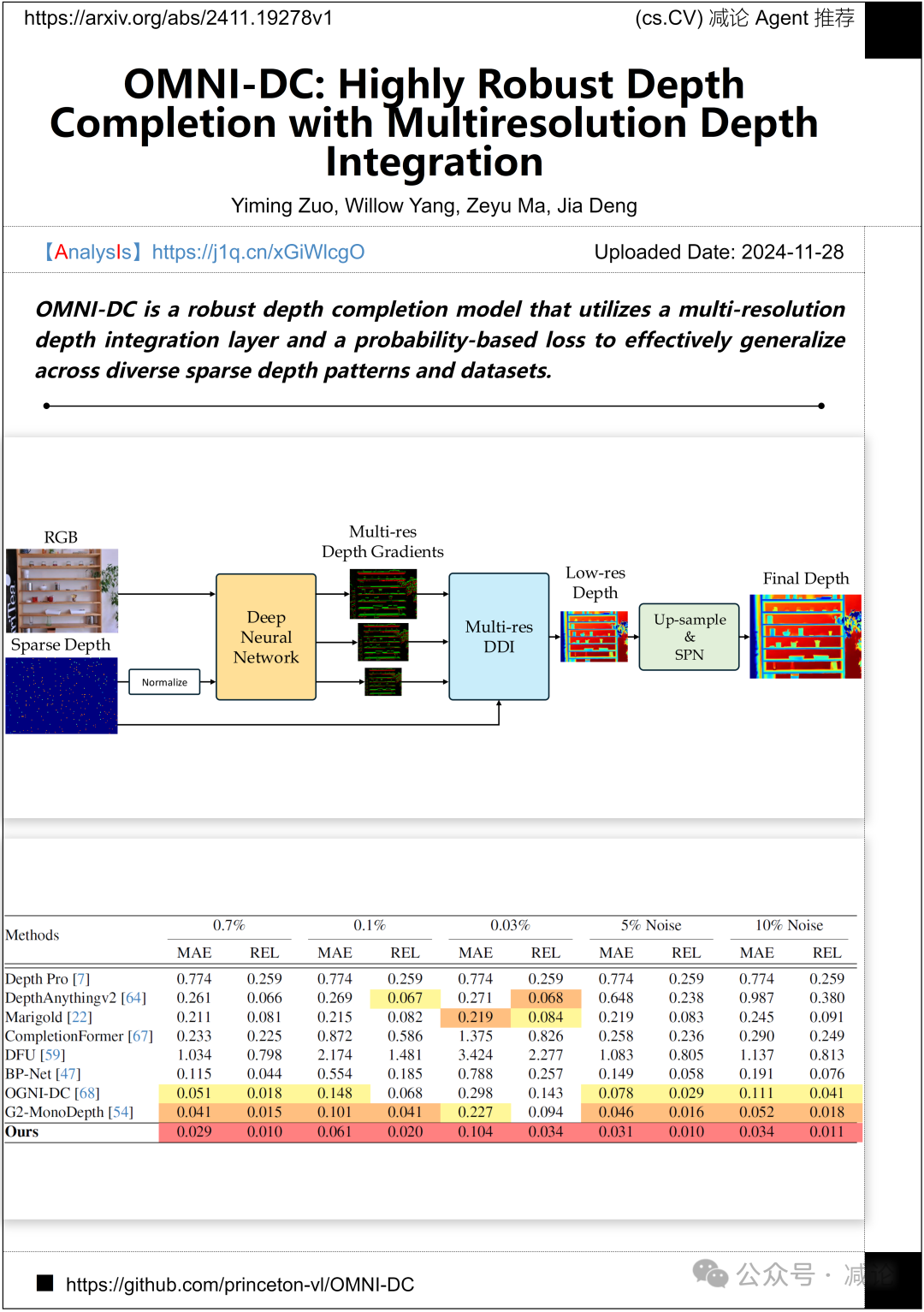
普林斯顿大学推出了OMNI-DC方法,这是一种深度补全模型。该模型采用多分辨率深度集成层和基于概率的损失函数,能够在不同稀疏深度模式和数据集上实现有效泛化。
【Bohr精读】
https://j1q.cn/xGiWlcgO
【arXiv链接】
http://arxiv.org/abs/2411.19278v1
【代码地址】
https://github.com/princeton-vl/OMNI-DC
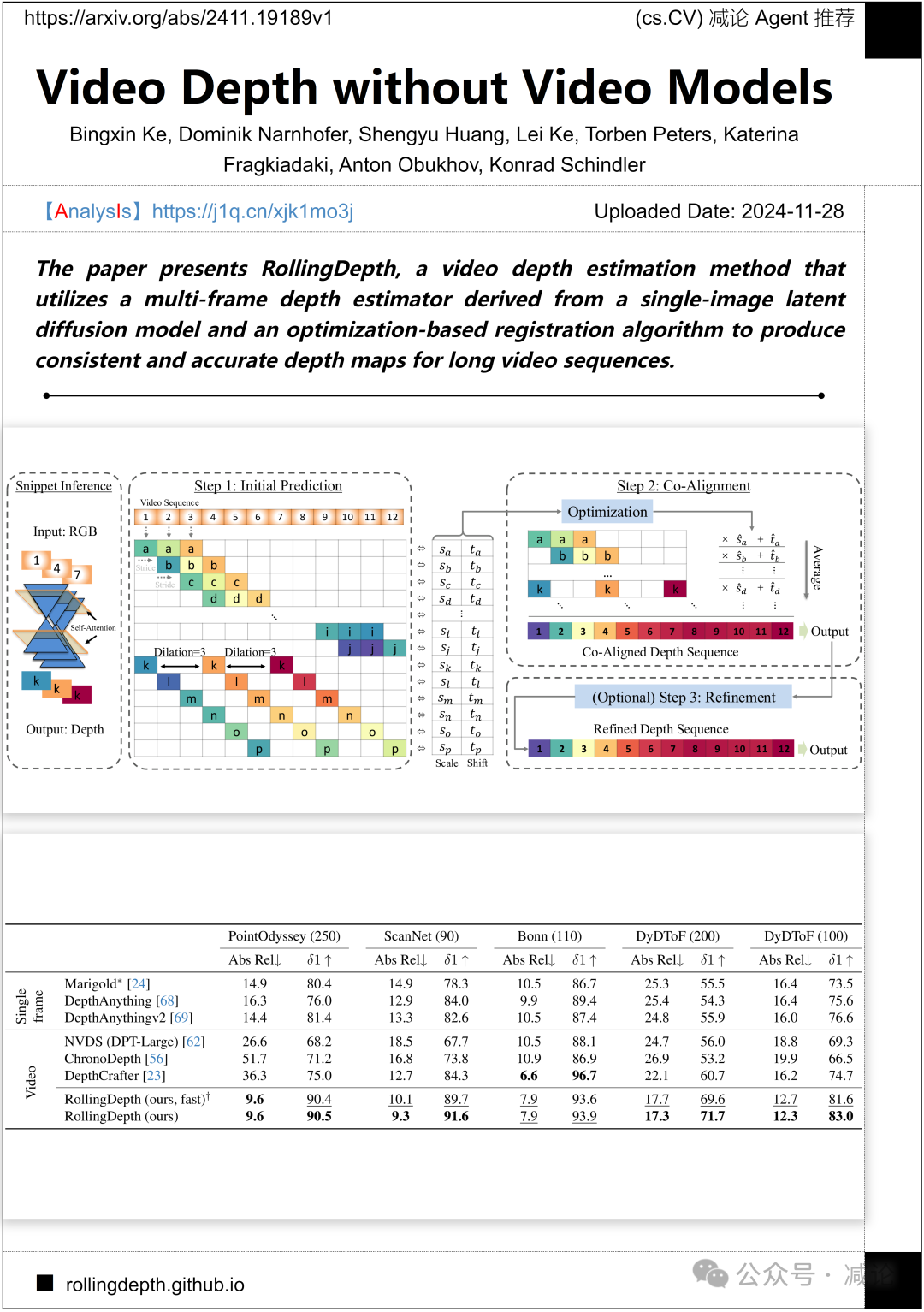
苏黎世联邦理工学院与卡内基梅隆大学联合提出了RollingDepth方法,旨在通过多帧深度估计器和基于优化的配准算法,从单图像潜在扩散模型中生成一致且准确的深度图,适用于长视频序列。
【Bohr精读】
https://j1q.cn/xjk1mo3j
【arXiv链接】
http://arxiv.org/abs/2411.19189v1
【代码地址】
rollingdepth.github.io

南京理工大学提出了FaithDiff方法,这是一种基于潜在扩散模型的技术。该方法通过对齐退化输入特征与扩散过程,联合微调编码器和扩散模型,以提高图像超分辨率的保真度和结构一致性。
【Bohr精读】
https://j1q.cn/MDhEAFE7
【arXiv链接】
http://arxiv.org/abs/2411.18824v1
【代码地址】
https://jychen9811.github.io/FaithDiff_page/

复旦大学提出了ForgerySleuth方法,这是一种利用多模态大型语言模型进行图像篡改检测的技术。该方法通过融合线索生成分割输出,识别被篡改区域,并借助ForgeryAnalysis数据集和数据引擎增强预训练效果。
【Bohr精读】
https://j1q.cn/CGL0IqEe
【arXiv链接】
http://arxiv.org/abs/2411.19466v1
【代码地址】
https://github.com/sunzhihao18/ForgerySleuth

摩德纳和雷焦艾米利亚大学、比萨大学及意大利国家研究委员会信息科学与技术研究所提出了一种名为Talk2DINO的方法。该方法结合了DINOv2的空间精度与CLIP的语言理解能力,通过将文本嵌入对齐到局部视觉块,增强了开放词汇分割,且无需对模型进行微调。
【Bohr精读】
https://j1q.cn/WHx1iigA
【arXiv链接】
http://arxiv.org/abs/2411.19331v1
【代码地址】
https://lorebianchi98.github.io/Talk2DINO/

华盛顿大学、山东大学和精彩科技提出了LLaMo方法。LLaMo是一个多模态框架,通过保留人类动作的原始形式进行指令微调,增强模型同时处理视频、动作数据和文本以解释复杂行为的能力。
【Bohr精读】
https://j1q.cn/0EPuwjzY
【arXiv链接】
http://arxiv.org/abs/2411.16805v1
【代码地址】
https://github.com/ILGLJ/LLaMo

中国科学技术大学与东北大学提出了GREAT方法,这是一种开放词汇的3D对象可供性定位框架,结合不变的几何属性和类比推理,增强了对3D对象上动作可能性的理解。
【Bohr精读】
https://j1q.cn/EBjAab0N
【arXiv链接】
http://arxiv.org/abs/2411.19626v1
【代码地址】
project

北京大学国际数字经济学院提出了一种单阶段框架,用于实时从单个RGB图像估计多人3D人体网格。该框架利用尺度自适应token,根据个体大小动态调整处理分辨率,提升计算效率的同时保持高精度。
【Bohr精读】
https://j1q.cn/3JONCkRg
【arXiv链接】
http://arxiv.org/abs/2411.19824v1
【代码地址】
https://ChiSu001.github.io/SAT-HMR/
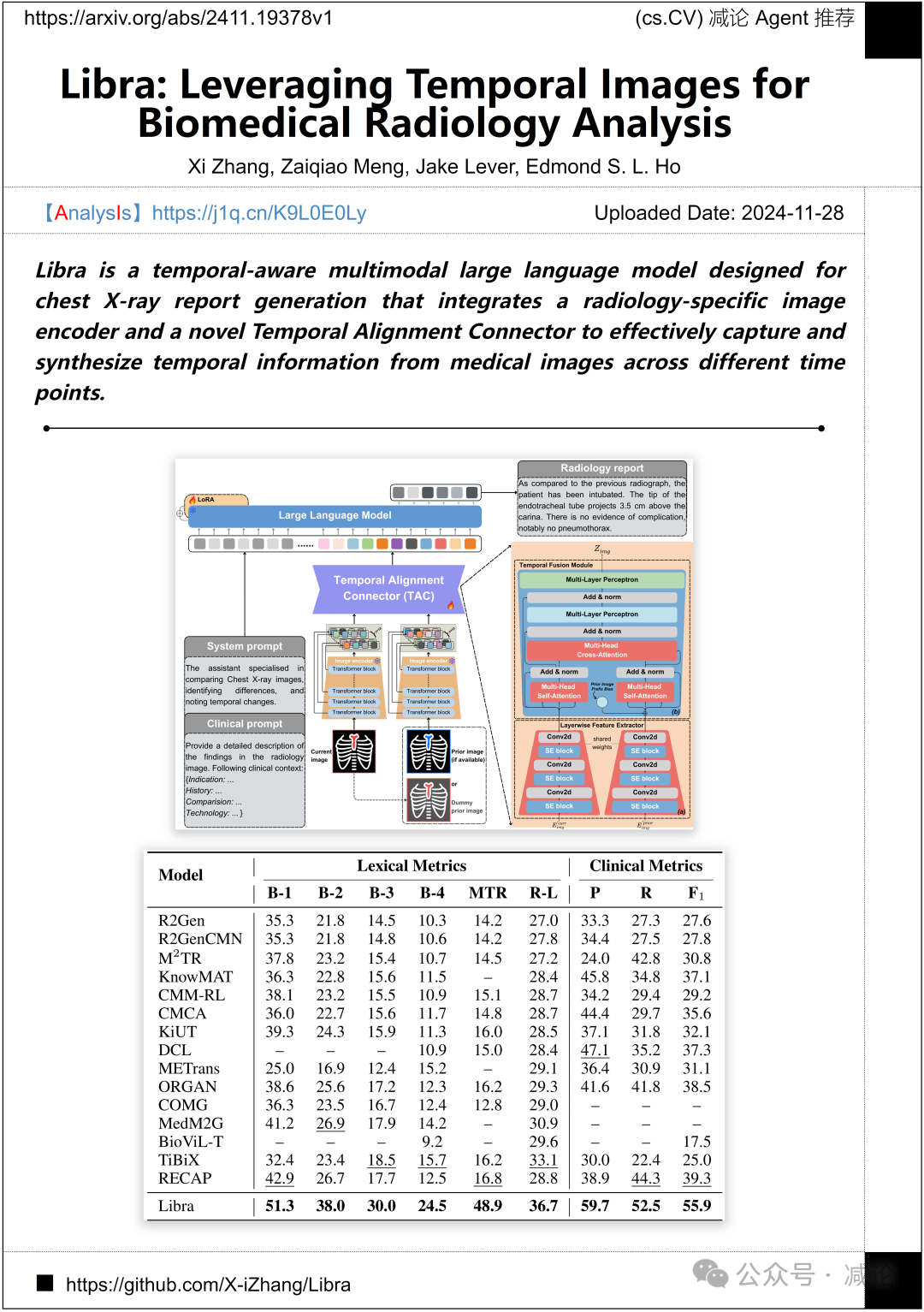
格拉斯哥大学推出的Libra方法是一种时间感知的多模态大型语言模型,专用于生成胸部X光报告。该方法集成了放射学特定的图像编码器和时间对齐连接器,能够有效捕捉和综合不同时间点医学图像中的时间信息。
【Bohr精读】
https://j1q.cn/K9L0E0Ly
【arXiv链接】
http://arxiv.org/abs/2411.19378v1
【代码地址】
https://github.com/X-iZhang/Libra
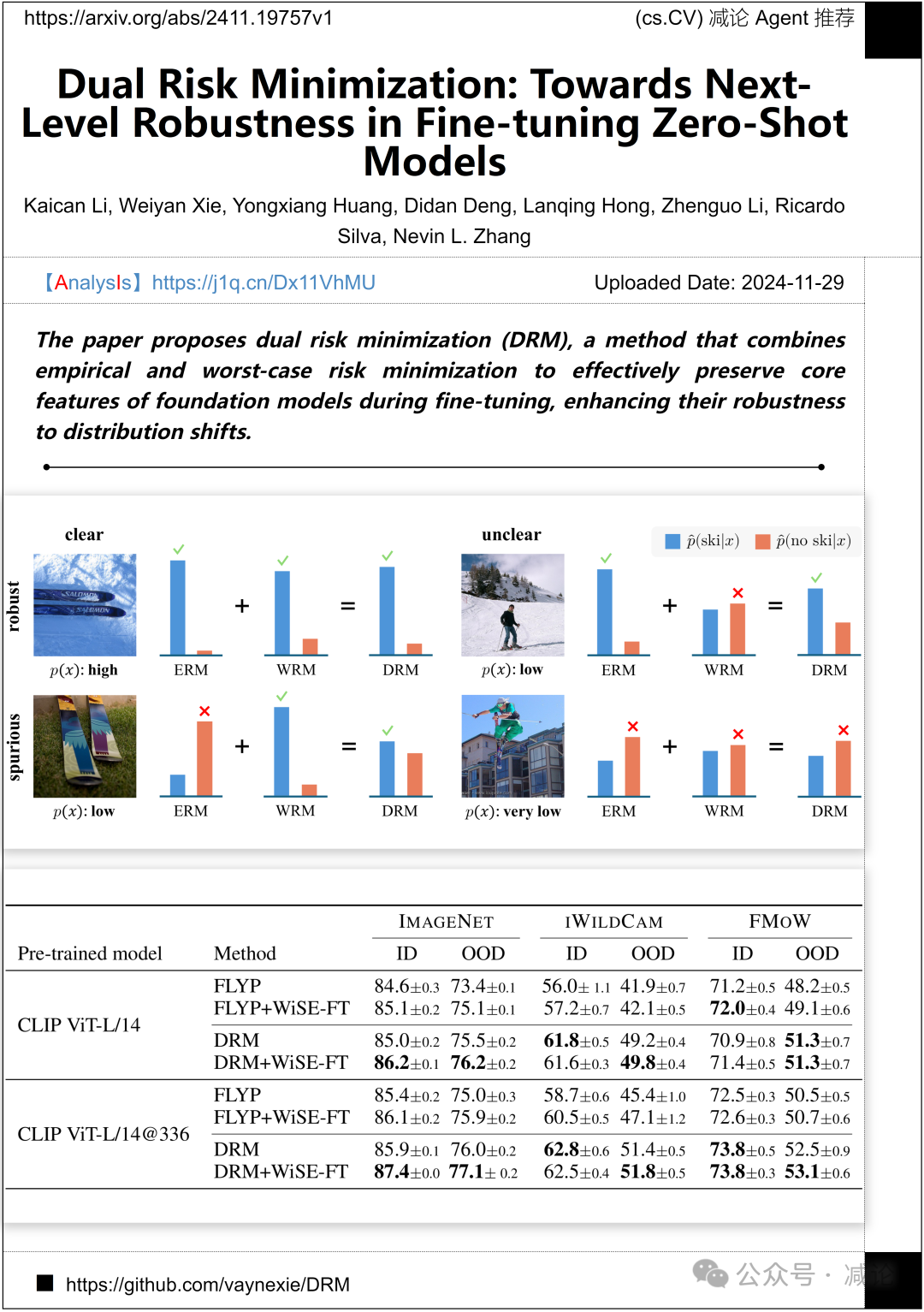
香港科技大学与华为联合提出了双重风险最小化(DRM)方法,结合了经验风险最小化和最坏情况风险最小化。在微调过程中,该方法有效保留了基础模型的核心特征,增强了对分布变化的鲁棒性。
【Bohr精读】
https://j1q.cn/Dx11VhMU
【arXiv链接】
http://arxiv.org/abs/2411.19757v1
【代码地址】
https://github.com/vaynexie/DRM

穆罕默德·本·扎耶德人工智能大学、约翰·霍普金斯大学与IBM研究联合提出了一种无标签的提示调优方法NoLA。该方法利用自监督学习模型DINO和大型语言模型生成稳健的文本嵌入,创建伪标签,并改善视觉特征对齐,从而显著增强基于CLIP的图像分类性能。在多个数据集上表现卓越。
【Bohr精读】
https://j1q.cn/2e0gigqW
【arXiv链接】
http://arxiv.org/abs/2411.19346v1
【代码地址】
https://github.com/fazliimam/NoLA
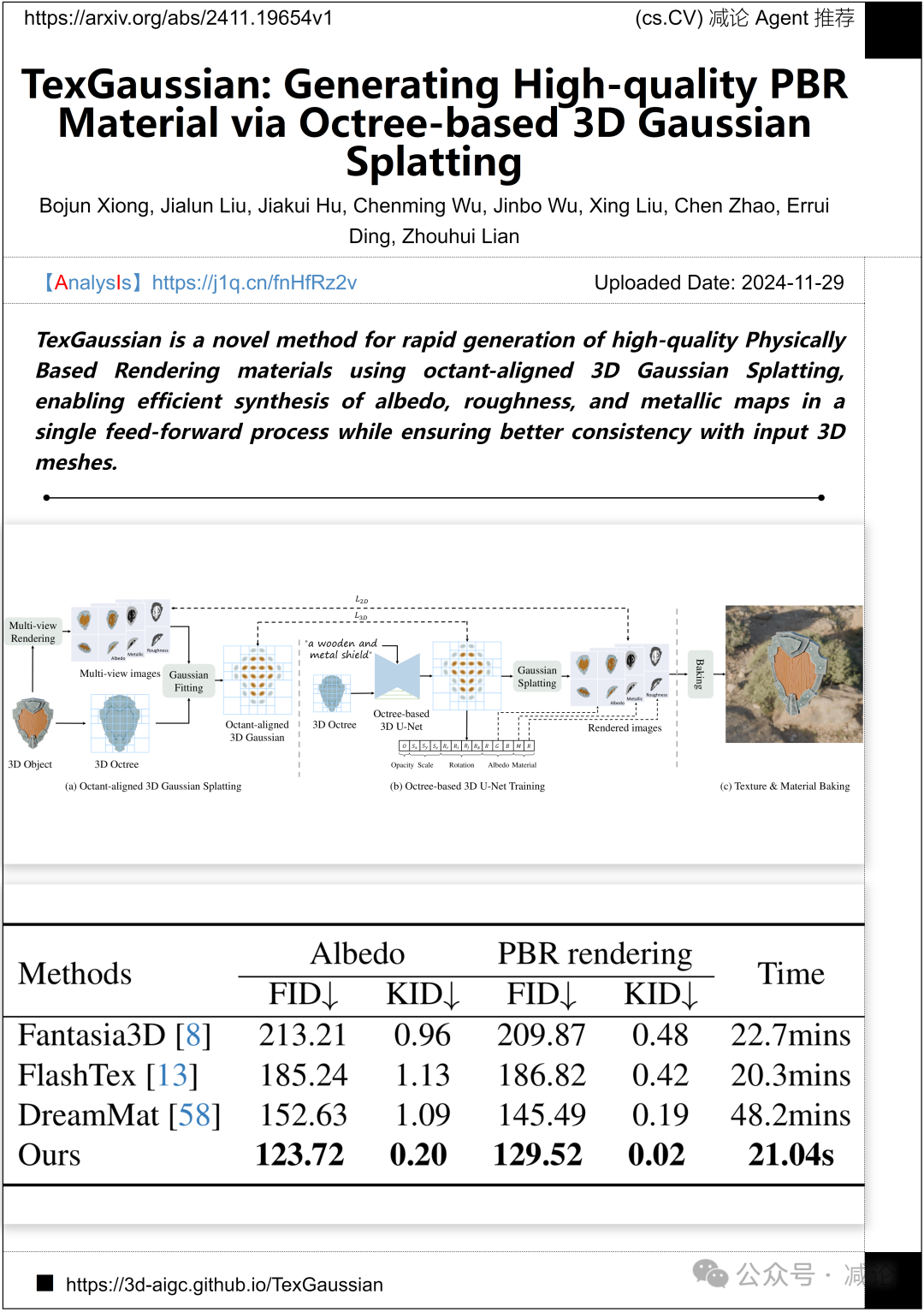
北京大学、百度视觉和北京大学医学技术研究所提出了一种新方法——TexGaussian。该方法通过八分体对齐的3D高斯散点,快速生成高质量的物理渲染材质。TexGaussian在单次前馈过程中高效合成反照率、粗糙度和金属度贴图,并确保与输入3D网格的一致性。
【Bohr精读】
https://j1q.cn/fnHfRz2v
【arXiv链接】
http://arxiv.org/abs/2411.19654v1
【代码地址】
https://3d-aigc.github.io/TexGaussian

上海人工智能实验室与复旦大学提出了新的多模态视觉无泄漏安全基准(VLSBench),解决了现有多模态安全基准中的视觉安全信息泄漏问题。研究表明,文本去学习在视觉安全泄漏场景中能实现与多模态对齐相当的安全性能。
【Bohr精读】
https://j1q.cn/ntDtdsvp
【arXiv链接】
http://arxiv.org/abs/2411.19939v1
【代码地址】
http://hxhcreate.github.io/VLSBench

欢迎关注减论,持续输出有深度的人工智能极减理解,提升信息获取效率和认知维度。看完点颗小星星再走呗~