


OccLLaMA: An Occupancy-Language-Action Generative World Model for Autonomous Driving
论文:
https://arxiv.org/abs/2409.03272
OccLLaMA 是一种创新的占用-语言-动作生成式世界模型,由来自复旦大学和清华大学的研究人员开发。它专为自动驾驶领域设计。该模型通过自回归模型将视觉、语言和动作三种模态统一起来,以实现对自动驾驶中复杂场景的理解和预测。
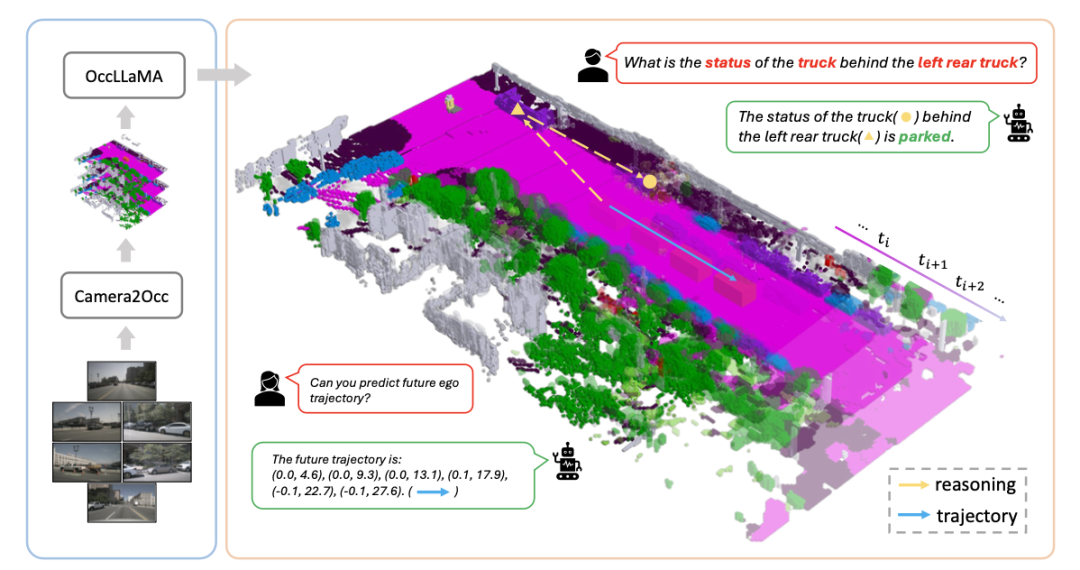
OccLLaMA 采用语义占用作为通用的视觉表示形式,并通过引入新的场景分词器来高效地离散化和重建语义占用场景。这种设计考虑了场景的稀疏性和类别不平衡问题,提高了模型处理3D视觉信息的能力和效率。OccLLaMA 的另一特点是其统一的多模态词汇表,它整合了视觉、语言和动作模态,为模型提供了一个共同的框架来处理和生成不同类型的数据。这种多模态融合方法使得OccLLaMA能够在自动驾驶的多个关键任务中表现出色,如4D占用预测、运动规划和视觉问答。

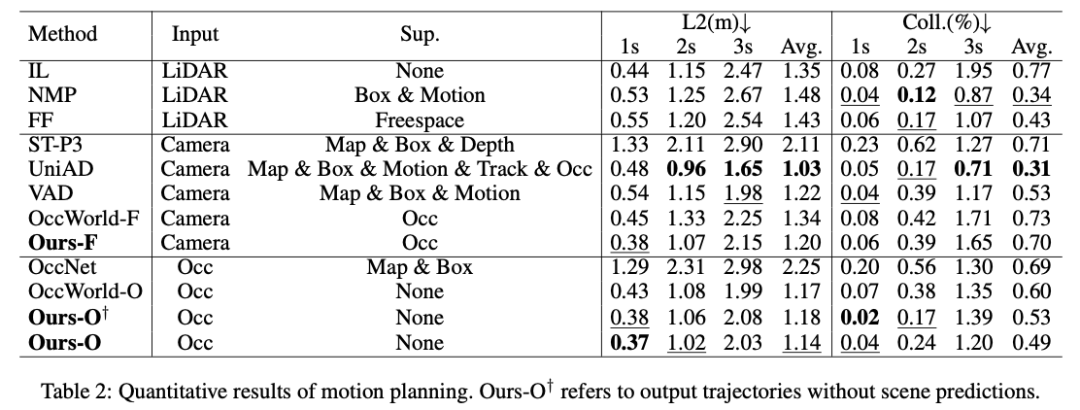

通过在这些任务上的广泛实验,OccLLaMA证明了其作为自动驾驶领域基础模型的潜力。
技术解读
OccLLaMA 是一种为自动驾驶设计的占用-语言-动作生成式世界模型,它通过构建一个统一的框架来整合视觉、语言和动作模态,以模拟和预测自动驾驶中的复杂场景。
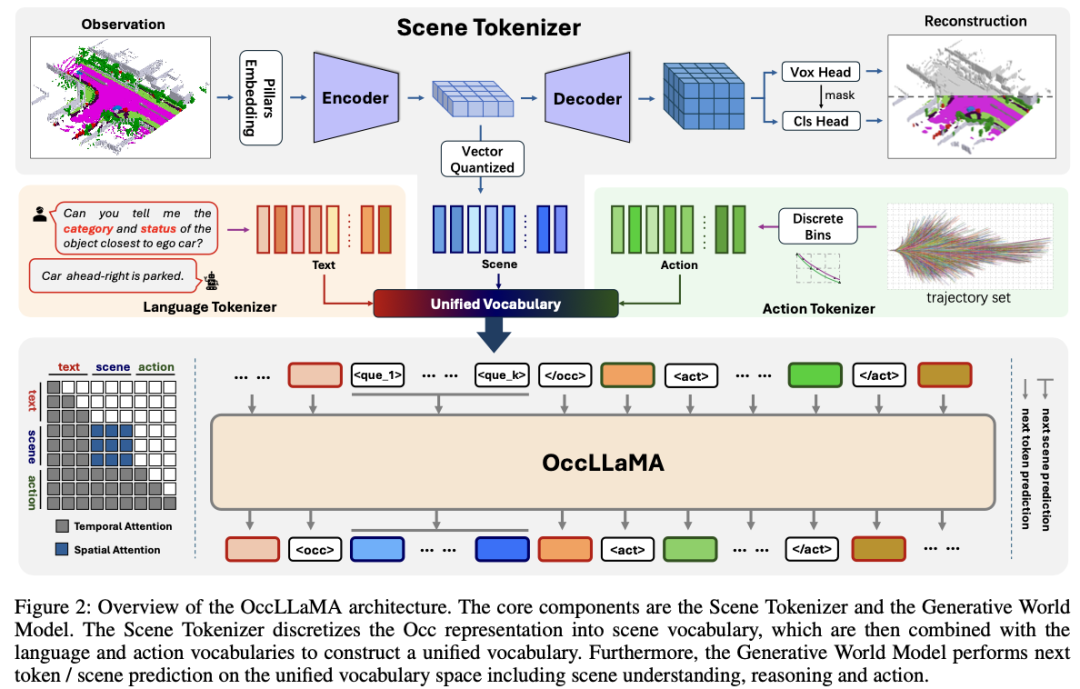
该模型利用语义占用作为视觉表示的核心,通过自回归模型来实现对场景的理解和动作的规划。它引入了场景分词器来高效处理和重建稀疏的3D占用场景,并构建了一个多模态词汇表来统一不同模态的数据表示。此外,OccLLaMA通过自回归模型的下一个标记/场景预测机制,实现了对自动驾驶中多种任务的支持,包括4D占用预测、运动规划和视觉问答。
OccLLaMA 在处理过程中首先通过场景分词器将3D占用场景转换为离散的标记,然后结合语言和动作词汇表,形成一个统一的多模态词汇表。这一词汇表使得模型能够在一个共同的空间内处理和生成不同类型的数据。技术上,OccLLaMA 采用了稀疏编码策略和向量量化技术来提高场景重建的效率和准确性。它还引入了空间注意力机制来捕捉场景内的复杂空间关系,并通过自回归模型的预测机制来实现对场景的动态理解和未来状态的预测。
OccLLaMA 为自动驾驶领域提供了一个强大的世界模型,能够处理和预测复杂的动态场景。它的多模态融合能力和高效的3D场景处理技术,使其在自动驾驶的关键任务中展现出了卓越的性能。展望未来,OccLLaMA 的进一步优化和应用将有望成为自动驾驶领域的一个重要基础模型,特别是在提高自动驾驶系统的预测准确性和决策效率方面,为实现更高级别的自动驾驶功能提供支持。
论文解读
- 提出了OccLLaMA模型,它通过自回归模型统一了视觉、语言和动作模态。
- 引入了一种新的场景分词器,有效处理语义占用场景的稀疏性和类别不平衡问题。
- 构建了统一的多模态词汇表,用于自动驾驶中的多种任务。
- 在多个自动驾驶任务中,如4D占用预测、运动规划和视觉问答,OccLLaMA展现出了竞争性的性能。
- 讨论了多模态大型语言模型(MLLMs)在自动驾驶领域的应用。
- 强调了构建代理的世界模型对于发展体现智能的重要性。
- 自动驾驶领域的世界模型研究现状,以及提出统一视觉、语言和动作(VLA)建模的模型的必要性。
- 2.1 MLLMs在自动驾驶中的应用:探讨了LLMs在场景理解、端到端决策制定中的应用。
- 2.2 自动驾驶中的世界模型:分析了不同世界模型在自动驾驶中的应用,包括2D图像、3D点云和3D占用表示。
- 2.3 自回归视觉生成:讨论了自回归方法在图像生成中的应用,以及如何将自回归语言模型与视觉生成相结合。
- 3.1 概述:介绍了OccLLaMA框架的核心组件,包括场景分词器和生成式世界模型,以及三阶段训练方案。
- 3.2 场景分词器:详细描述了如何使用VQVAE架构将场景离散化为标记,并处理稀疏性和类别不平衡问题。
- 3.3 生成式世界模型:介绍了统一词汇表的构建,以及如何通过自回归模型进行下一个标记/场景预测。
- 3.4 训练阶段:说明了场景分词器的训练、3D占用-语言-动作预训练和指令调整的三个训练阶段。
- 4.1 实验设置:介绍了使用的数据集和实现细节。
- 4.2 结果与分析:展示了OccLLaMA在4D占用预测、运动规划和视觉问答任务中的定量和定性结果,并与现有技术进行了比较。
- 4.3 消融研究:分析了不同组件和训练设置对模型性能的影响。
- 总结了OccLLaMA的主要贡献,并提出了未来的研究方向,包括增加数据多样性和探索模型量化与蒸馏。