


这篇系统文献综述(SLR)全面回顾了时空图神经网络(GNN)模型在时间序列分类和预测领域的应用现状,并评估了其在不同领域的性能和有效性。
1. 引言
近年来,图神经网络(GNN)在处理可以表示为图结构的数据方面表现出强大的能力,尤其适用于交通网络、图像分析和自然语言处理等应用场景。
GNN 旨在将图中的节点映射到欧几里得空间,生成节点嵌入,从而捕捉节点之间的关系。GNN 可用于以下三类问题:
-
图级问题:预测整个图的属性,例如预测分子的全局性质。 -
边级问题:预测图中节点对之间是否存在边,例如推荐系统中预测用户与商品之间的潜在连接。 -
节点级问题:预测图中每个节点的标识或角色,例如节点分类或回归任务。
这篇综述重点关注 GNN 在时间序列相关任务中的应用,特别是时间序列分类和预测。时空 GNN 模型旨在同时捕捉变量之间以及不同时间点之间的复杂关系,将空间维度与多元时间序列框架相关联,将时间维度与数据的时序性相关联。
尽管时空 GNN 模型具有巨大潜力,但目前缺乏针对其在时间序列应用中应用的系统文献综述。现有综述要么不是系统性的,要么不够全面,或者只关注少数应用领域。因此,这篇综述旨在:
-
全面概述时空 GNN 在不同领域的分类和预测应用。 -
评估时空 GNN 模型当前的流行程度是否与其有效性相符,以及其在不同领域的有效性和准确性。 -
收集结果和基准,以帮助研究人员通过综合现有文献来开展研究工作。
2. 研究方法
为了进行这项 SLR,研究人员检索了 Scopus、IEEE Xplore、Web of Science 和 ACM 四个数据库,并制定了以下排除标准:
-
排除 2024 年的论文,因为尚未结束,综述仅涵盖截至 2023 年的文献。 -
仅考虑期刊文章,以确保纳入“已确立”的来源,并排除会议论文和书籍章节。 -
仅纳入用英语发表的论文。
研究人员使用以下高级搜索查询来检索相关文献:
(("graph neural network" OR gnn) AND "time series") AND (classification OR forecasting)
该查询旨在将 GNN 模型的范围限制在时间序列领域,并将搜索重点放在分类和预测应用上。
文献筛选过程包括以下几个阶段:
-
数据库检索:将搜索查询提交给四个数据库,并将所有记录导入 CSV 文件。 -
去重:识别并删除重复记录。 -
标题和摘要筛选:通过阅读标题和摘要筛选剩余记录,剔除明显不符合标准的文献。 -
全文筛选:逐一分析剩余论文的全文,进一步评估其适用性。 -
数据提取:从纳入的研究中提取相关数据,并进行分析,以便更好地讨论方法,并介绍每个确定领域中最常见的模型和数据集。
最终,共确定了 156 篇期刊论文。
3. 文献概述
对选定的论文进行分组,并根据应用领域进行主题分析。

3.1 出版趋势
从 2020 年开始,关于时空 GNN 模型的出版物数量呈累积性增长趋势,其中“环境”、“通用”和“移动”领域的出版物数量增长最快。
3.2 发表期刊
95 种不同的期刊发表了关于 GNN 模型用于时间序列预测或分类的论文。期刊的多样性表明,时空 GNN 模型在不同领域具有广泛的潜在应用。这表明研究人员通常根据应用的具体领域选择期刊,以便接触目标受众,并在各自领域做出贡献。
3.3 研究团队
合作网络分析表明:
-
存在许多不同的研究团队,表明该领域高度碎片化。 -
一些研究团队在早期活跃,但后来消失了,而另一些研究团队则是最近形成的。 -
一些研究人员随着时间的推移与不同的团队进行合作。
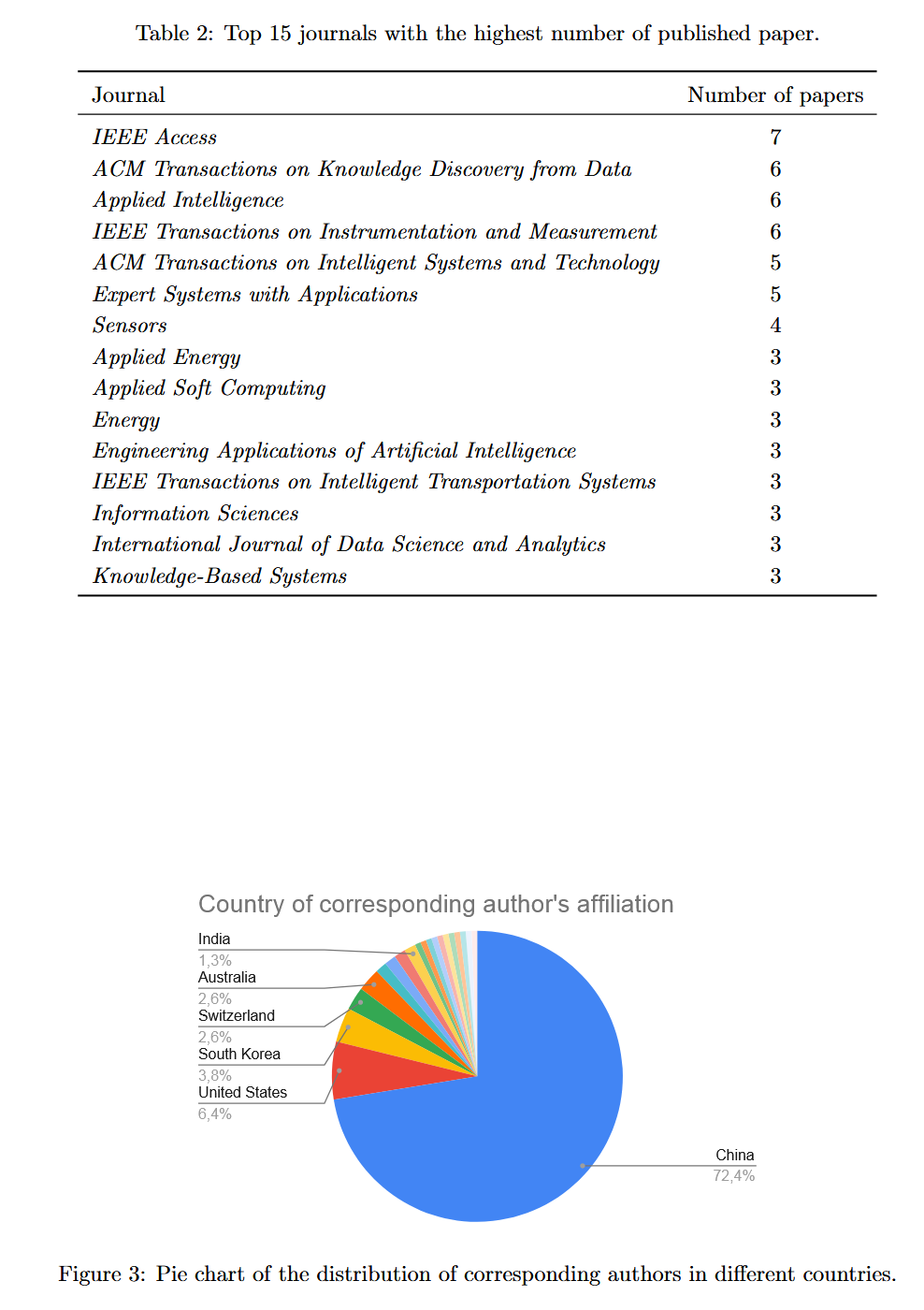
3.4 作者所在国家
超过 70% 的作者隶属于中国机构。
4. 图神经网络
4.1 基本定义
-
时间序列:按时间顺序排列的数据点序列。 -
单变量时间序列:按时间顺序收集的标量观测值序列。 -
多变量时间序列:按时间顺序收集的 D 维向量观测值序列。 -
图:由节点集合 V 和边集合 E 组成的图 G = (V, E)。 -
无向图:每条边都是节点的无序对。 -
有向图:边具有方向性,对应于节点的有序对。 -
空间-时间图:四元组 G = (V_t, E_t, X_t, T),其中 T 为时间戳集合,V_t 为节点集合,E_t 为边集合,X_t 为节点和边的属性集合。 -
邻接矩阵 A:描述图中节点之间的连接关系,A_ij 表示节点 v_i 到节点 v_j 的连接数。 -
度矩阵 D:描述图中每个节点的度数。
4.2 图神经网络概述
GNN 模型旨在为图中的每个节点生成嵌入,即将图表示到可能不同维度的空间,同时保留其结构信息。
GNN 的概念最初由 Gori 等人于 2005 年提出,用于将图映射到欧几里得空间。节点嵌入的计算方法包括迭代传播邻居信息,直到达到稳定不动点,然后反向传播误差。
4.3 时空 GNN 及其分类
时空 GNN 主要针对多变量时间序列,将节点视为不同变量,边表示变量之间的关系。时空 GNN 模型假设节点的特征信息取决于其自身的历史值以及相邻节点的历史数据。
时空 GNN 模型的开发主要有两种方法:
-
分别处理空间和时间子结构。 -
将空间和时间子结构整合在一起进行处理。
时空 GNN 模型可以进一步分为以下几类:
-
循环 GNN:使用迭代收缩映射生成节点嵌入。 -
卷积 GNN:使用不同的参数,通过堆叠多个图卷积层来提取节点嵌入。 -
注意力 GNN:使用注意力机制来聚合节点特征。
时空 GNN 模型通常由空间模块、时间模块或混合模块组成的空间、时间或混合模块堆叠而成。
-
空间模块:负责在节点之间传播信息,从而能够分析不同变量之间的横向相互依赖关系。 -
时间模块:关注数据随时间的变化,独立于横向节点交互。
4.4 图结构确定
时空 GNN 模型面临的挑战之一是图结构的确定,即节点的连接关系。
-
一些时间序列数据集本身具有预定义的图结构,例如道路网络。 -
其他数据集则没有预定义的图结构,需要用户根据领域知识或某些指标定义,或由模型本身学习。
图结构确定后,需要定义加权图邻接矩阵,其条目由图的边权重给出。边权重可以由用户预先定义,也可以由模型根据预定义架构学习。
5. 主题分析
5.1 能源
能源预测对于电网稳定性和运营效率至关重要。
-
研究重点:风能和太阳能发电预测。 -
数据集:没有普遍认可的基准数据集,研究人员通常使用特定数据集,例如 NREL 数据集。 -
提出的模型: -
大多数模型使用卷积 GNN 或注意力 GNN。 -
图结构通常基于地理空间位置或时间序列之间的相关性构建。 -
损失函数以 MSE 为主。 -
代码实现主要使用 Python 和 Matlab,以及 PyTorch 和 TensorFlow 库。 -
基准模型: -
主要使用经典机器学习基准,例如 ARIMA、BiLSTM、CNN、LSTM、GRU 等。 -
很少使用 GNN 模型作为基准。 -
结果:作者声称提出的 GNN 模型优于基准模型,但没有共同的数据集进行比较。
5.2 环境
环境研究领域广泛,包括空气质量预测、海水温度预测、风速预测等。
-
研究重点: -
海面温度预测 ([209], [87], [147], [47], [187], [173], [164]) -
风速预测 ([7], [157], [8], [49], [46], [40]) -
PM2.5 浓度预测 ([131], [171], [110], [139], [86], [151]) -
数据来源: -
NOAA 海数据集 ([209], [47], [187], [40], [164]) -
中国环境监测总站数据 ([131], [151]) -
Copernicus 3D 热盐数据 ([147]) -
韩国半岛海洋数据 ([87]) -
台湾空气质量数据集 ([171]) -
美国 EPA PM2.5 数据集 ([22], [110]) -
缺乏公认的基准数据集。常用数据集包括: -
数据粒度范围从 1 分钟到 1 个月不等,预测范围从 10 分钟到 240 天不等。 -
大多数数据集需要进行预处理,包括缺失数据插值、异常值去除和归一化。 -
提出的模型: -
许多论文提到了 Python 和 PyTorch 库。 -
少数论文提供了所提出模型的源代码链接。 -
并非所有论文都指定了用于训练模型的损失函数。 -
在指定损失函数的论文中,MAE 和 MSE 的使用比例大致相当。 -
部分论文描述不够详细,对图结构的静态或动态性质含糊其辞。 -
在近一半的论文中,边权重是通过模型直接学习的,通常使用图注意力机制。 -
当图结构是手动定义时,最常用的标准是站点之间的空间距离 (d),甚至是其指数形式 (e-d) 或反比例形式 (1/d)。 -
少数论文融合了多个图结构以捕捉更复杂的动态。 -
大多数论文使用卷积 GNN (17 篇),其次是注意力 GNN (6 篇) 和混合架构 (3 篇)。 -
基准模型: -
图卷积神经网络和长短期记忆网络 (GC-LSTM) [154],用于空气质量预测问题。 -
时空图卷积网络 (STGCN) [216]。 -
多变量时间序列预测与图神经网络 (MTGNN) [201],在许多论文中表现出仅次于最佳模型的性能。 -
主要使用经典机器学习模型,例如 BiLSTM、CNN、CNN-LSTM、ConvLSTM、FNN、GRU、Informer、LSTM、SVR、Transformer、Wavelet-DBN-RF、XGBoost 等。 -
结果: -
CCMP 风速数据集: 动态自适应时空图神经网络 (DASTGN) [46] 在所有时间范围内均表现出最高精度。 -
中国国家城市空气质量数据集: 混合可解释神经网络和图神经网络模型 (INNGNN) [39] 在所有时间范围内均表现出最高精度,除了 1 小时外,被元图卷积循环网络模型 (MegaCRN) [74] 超越。 -
在所有论文中,作者声称提出的 GNN 模型优于基准模型。 -
常用的误差指标包括 MAE、RMSE 和 MAPE。 -
由于没有共同的基准数据集,无法比较模型的准确性。
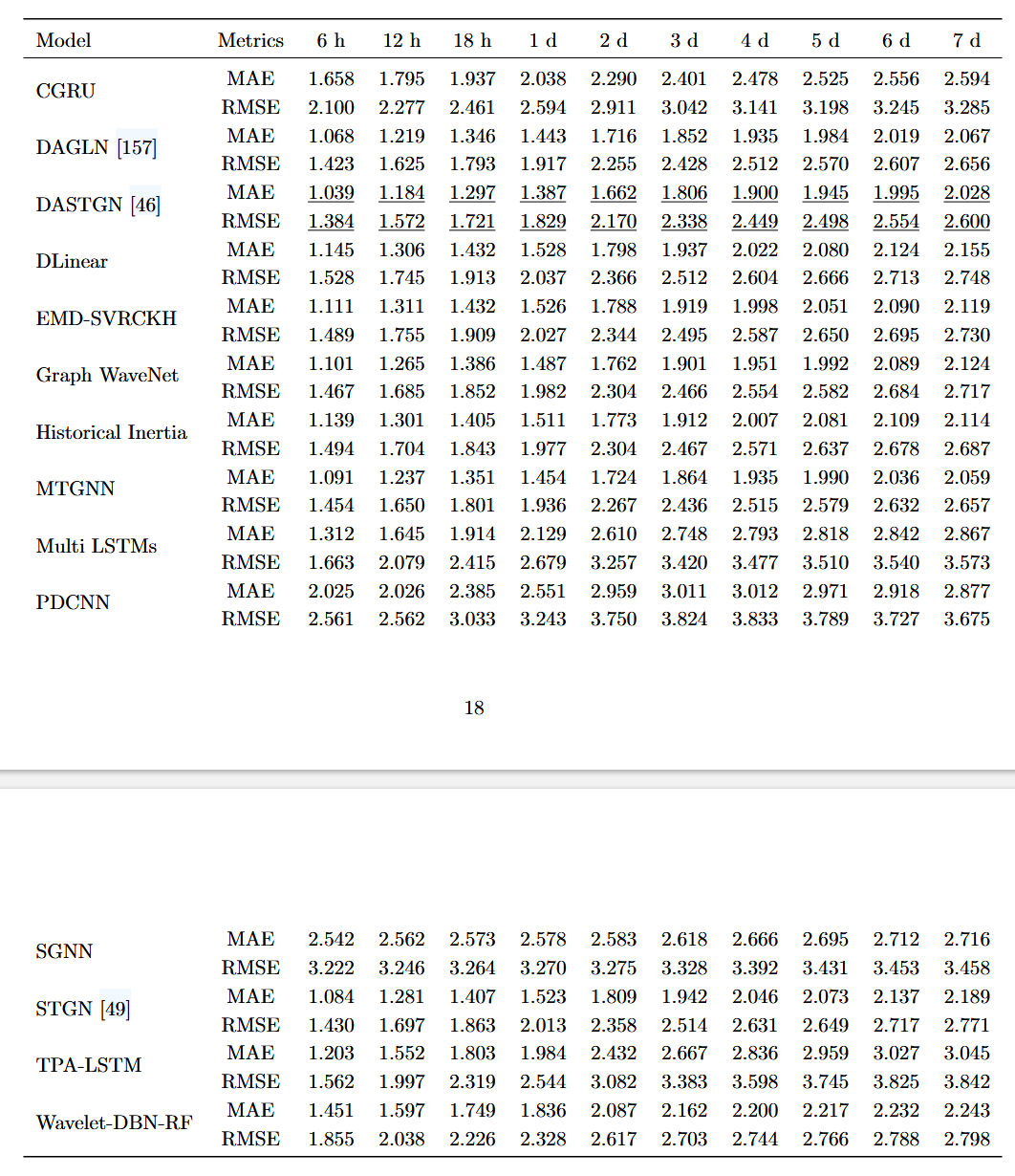
5.3 金融
金融数据预测具有挑战性,因为市场具有复杂性和波动性。
-
研究重点: -
股票价格预测 ([69], [149], [176], [186], [174]),通常作为分类任务。 -
评估预测对投资回报稳定性的影响。 -
数据来源: -
中国证券指数 (CSI) -
标准普尔 (S&P) 指数 -
中国 A 股指数 -
数据集有限,主要包括: -
许多研究还包含其他市场数据、事件和新闻等外部数据。 -
数据粒度通常为 1 天,预测范围也通常为 1 天。 -
一些论文使用归一化技术,例如最小-最大归一化、Z-score 归一化和对数归一化。 -
提出的模型: -
主要使用 Python 和 PyTorch 和 TensorFlow 库。 -
只有一篇论文提供了源代码链接。 -
大多数论文使用交叉熵损失函数。 -
一些论文使用模型自行学习图结构,而另一些论文则根据公司和股票之间的关系预先定义图结构。 -
注意力 GNN (5 篇) 和卷积 GNN (4 篇)。 -
基准模型: -
没有共识,最常用的基准是 LSTM,其次是图卷积网络 (GCN) 和分层图注意力网络 (HATS) [89]。 -
结果: -
提出的分类模型的准确性主要通过准确性、精密度和 F1 分数来评估。 -
两篇论文比较了使用 5、10 和 20 个交易日作为记录的结果。 -
知识图和图卷积神经网络 (KG-GCN) [186] 和股票价格走势预测通过卷积网络与对抗超图模型 (MONEY) [174] 是表现最好的两个模型。
5.4 健康
GNN 在健康领域的应用包括健康监测、疾病建模和诊断工具。
-
研究重点: -
流行病预测,例如 COVID-19 传播预测。 -
传感器数据用于慢性病诊断。 -
数据来源: -
没有共同的数据集,每篇论文都使用不同的数据集,主要与 COVID-19 相关。 -
数据粒度通常为每日。 -
一些论文包含外部变量,例如地理、人口、健康状况、疫苗接种等。 -
提出的模型: -
所有论文都使用 Python 和 PyTorch。 -
一些论文提供了源代码链接。 -
MSE 用于预测任务,交叉熵用于分类任务。 -
一些论文基于数据的地理分布构建图。 -
其他论文使用模型自行学习图结构。 -
图通常是静态的。 -
卷积 GNN (5 篇),注意力模型 (2 篇) 和混合卷积-注意力架构 (1 篇)。 -
基准模型: -
没有特别相关的基准模型,也没有 GNN 基准模型。 -
常用的基准模型包括 ARIMA、FNN、LSTM 等。 -
结果: -
作者声称提出的 GNN 模型优于基准模型。 -
常用的误差指标包括 MAE 和 MSE。
5.5 移动
移动领域的研究数量最多,包括城市交通、航空旅行和自行车需求等。
5.5.1 概述
城市交通预测对于提高交通运输系统的效率、帮助驾驶员更有效地规划行程以及缓解城市拥堵至关重要。智能城市基础设施和交通运输系统的出现,促进了从道路传感器收集丰富的数据,这些数据可用于交通预测。然而,由于交通模式随时间和空间不断变化,以及天气状况和特殊事件等外部因素的影响,准确预测交通状况具有挑战性。
与传统的统计和机器学习模型相比,GNN 可以通过建模空间和时间域中的复杂关系,更有效地进行交通预测。近年来,该领域发表的论文数量逐年增加,这反映了人们对 GNN 模型日益增长的信心和研究兴趣。
主要研究方向:
-
城市交通预测,特别是交通流量和速度预测。 -
研究表明,GNN 模型在捕捉交通数据的时空依赖性方面表现出色。 -
例如,STGCN 模型 [216] 通过时空卷积块整合了图卷积和门控时间卷积,能够有效预测交通流量和速度。 -
DCRNN 模型 [119] 使用双向随机游走捕捉空间依赖性,并使用具有计划采样的编码器-解码器架构捕捉时间依赖性。 -
ASTGCN 模型 [57] 并行建模近期、每日周期性和每周周期性依赖性,并使用时空注意力机制和时空卷积来捕捉动态时空相关性。
数据来源:
-
常用数据集包括 PeMS 数据集 (http://pems.dot.ca.gov/) 和 METR-LA 数据集 (https://paperswithcode.com/dataset/metr-la)。 -
PeMS 数据集由加利福尼亚交通运输局性能测量系统提供,包含不同时间范围、空间覆盖范围和传感器数量的多个版本。 -
METR-LA 数据集从洛杉矶县高速公路的环路检测器收集数据。 -
其他常见数据集可以在 https://paperswithcode.com/task/traffic-prediction 找到。 -
常用外部数据包括天气状况、时间信息(例如一天中的时间和星期几)、事件(例如节假日)以及道路网络信息(例如兴趣点)。 -
数据粒度大多数为 5 分钟,预测范围从 5 分钟到 1 小时不等。 -
数据预处理通常包括缺失值插补、数据归一化(例如最小-最大归一化或 Z-score 归一化)以及选择最近、每日和每周数据的窗口。
5.5.3 提出的模型
-
提出的模型中,18 个属于纯卷积 GNN 范式,其次是 11 个注意力 GNN、9 个混合卷积-注意力架构和 1 个循环 GNN。 -
图结构定义: -
道路连接性 ([230], [231], [146], [77]) -
空间距离 ([133], [102], [107], [95], [13], [15]) -
兴趣点信息 ([203], [102]) -
时间序列之间的相似性度量,例如相关系数或余弦相似度 ([33], [54], [85], [146]) -
给定时间步道路上的出行人数 ([203], [193], [14], [38]) -
大多数论文详细讨论了图结构的定义。 -
一半的论文基于预定义的邻接矩阵。 -
其他论文提出的模型可以自行学习邻接矩阵,其中一半基于矩阵的预初始化。 -
图结构定义方法多种多样,例如: -
损失函数: -
最常用的损失函数是 MSE 和 MAE。 -
一些论文在处理需要自行学习图结构的模型时,考虑了损失函数的组合。 -
代码实现: -
并非所有论文都指定了用于代码的语言或库。 -
在指定的论文中,Python 是最常用的语言,大多数使用 PyTorch,而只有少数研究人员使用 TensorFlow。 -
少数论文提供了所提出模型的源代码链接。
5.5.4 基准模型
基本数学和统计方法: ARIMA 和历史平均 (HA) 模型是两种广泛使用的基准模型。尽管它们看似简单,但在某些情况下,这些模型的准确性可以与更复杂的模型相媲美。
传统机器学习模型: LSTM 被广泛认为是能够处理交通数据中长期依赖关系的循环神经网络类型。
GNN 模型: 最常用的三个模型依次是时空图卷积网络 (STGCN) [216]、扩散卷积循环神经网络 (DCRNN) [119] 和基于注意力的时空图卷积网络 (ASTGCN) [57],它们都是专门为交通预测问题开发的。
-
STGCN 模型由 Yu 等人于 2018 年提出,通过时空卷积块整合了图卷积和门控时间卷积。源代码可在 https://github.com/VeritasYin/STGCN_IJCAI-18 找到。 -
DCRNN 模型由 Li 等人于 2017 年提出,旨在使用图上的双向随机游走来捕捉空间依赖性,并使用具有计划采样的编码器-解码器架构来捕捉时间依赖性。代码可访问 https://github.com/liyaguang/DCRNN。 -
ASTGCN 模型由 Guo 等人于 2019 年提出,并行建模近期、每日周期性和每周周期性依赖性,作为三个独立的组件,并使用时空注意力机制来捕捉动态时空相关性,以及同时使用图卷积来捕捉空间模式的时空卷积。代码可在 https://github.com/Davidham3/ASTGCN-2019-mxnet 找到。
5.5.5 结果
所有论文的作者都声称,提出的基于 GNN 的模型优于其他基准模型。然而,在某些情况下,一些简单的统计和数学模型表现出相当的准确性,如表 19 和表 20 所示。
在模型比较和评估中,最常用的误差指标是 MAE、RMSE 和 MAPE。少数论文还使用不同的指标,例如决定系数 R2。然而,尽管使用了相同的指标,并且有广泛使用的数据集,但由于不同的论文通常关注数据集中不同的时间窗口,因此比较模型并非易事。
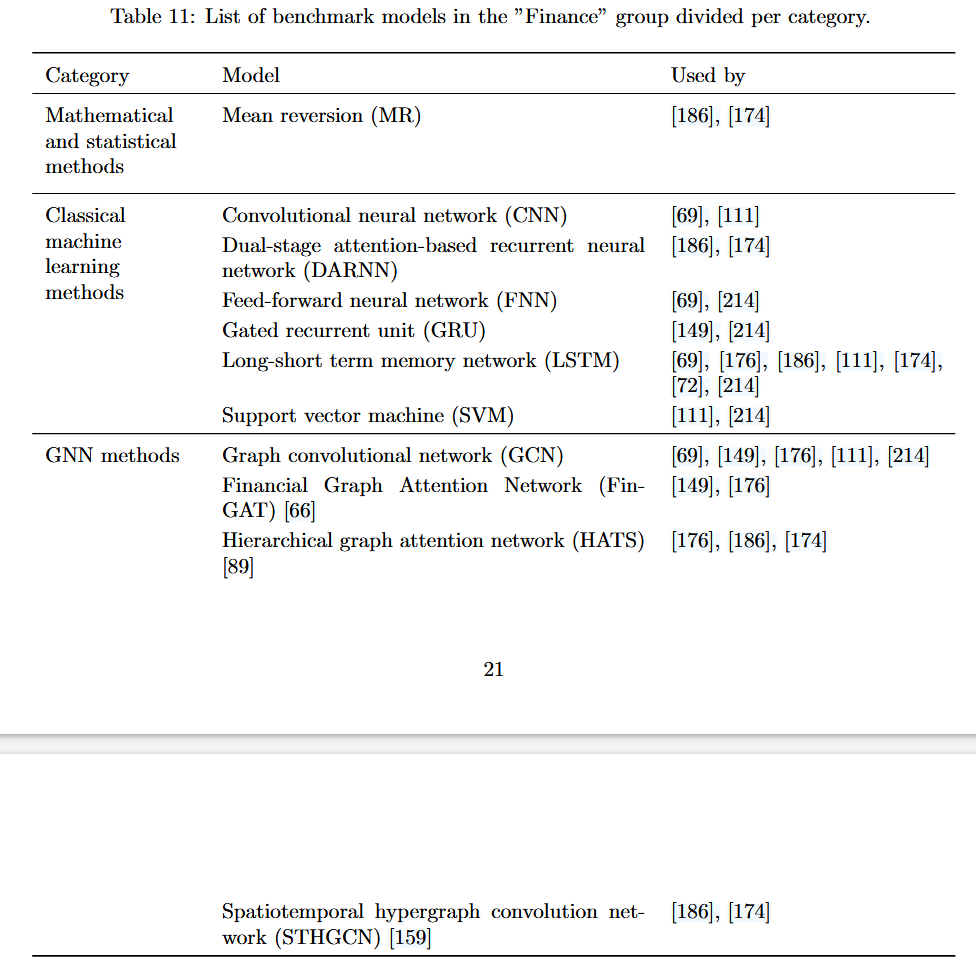
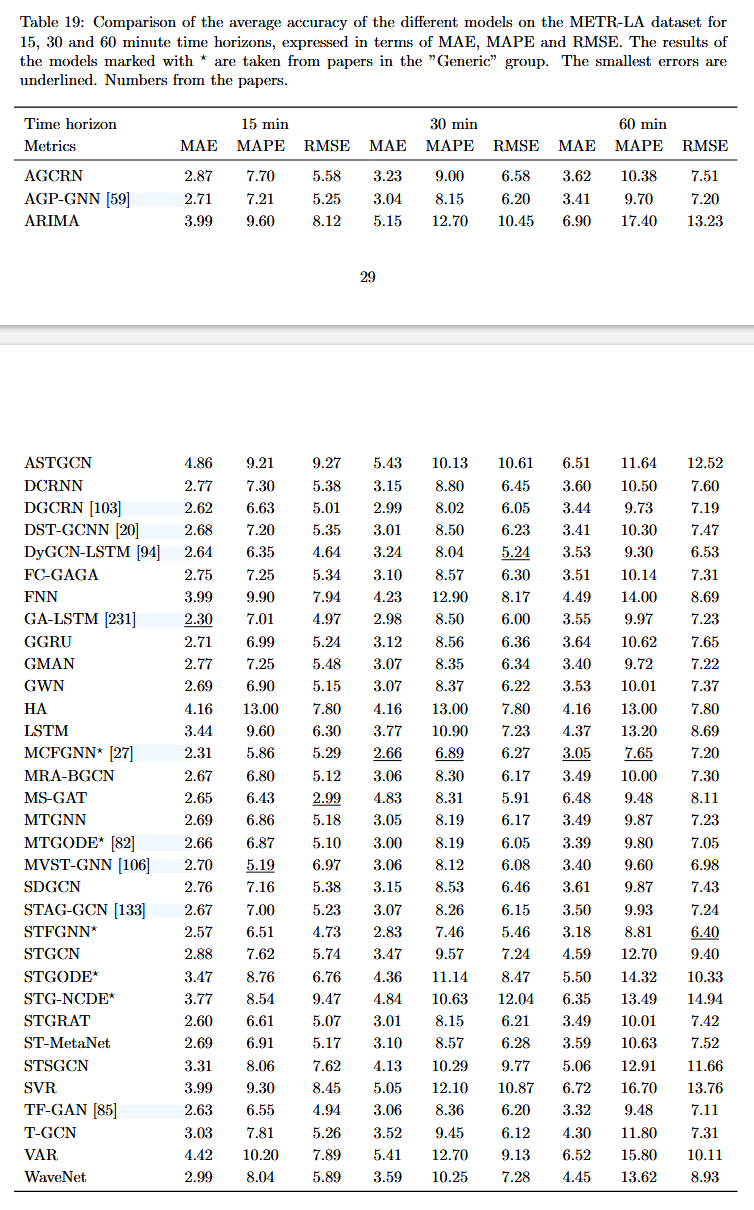
METR-LA 数据集: 表 19 显示了不同模型在 METR-LA 数据集上的准确性,该数据集的数据粒度为 5 分钟,时间范围从 2012 年 3 月 1 日到 2012 年 6 月 30 日,预测范围为 15、30 和 60 分钟,结果以 MAE、MAPE 和 RMSE 表示。
对于 METR-LA 数据集的结果并不统一,性能最佳的模型因指标和时间范围而异。然而,尤其是在更长的时间范围内,动态图卷积 LSTM 网络 (DyGCN-LSTM) [94] 似乎是最准确的模型(不包括“通用”*模型,其中性能最佳的模型是多通道融合图神经网络 (MCFGNN) [27])。
PEMS-BAY 数据集: 表 20 显示了不同模型在 PEMS-BAY 数据集上的准确性,该数据集的数据粒度为 5 分钟,时间范围从 2017 年 1 月 1 日到 2017 年 6 月 30 日,预测范围为 15、30 和 60 分钟,结果以 MAE、MAPE 和 RMSE 表示。
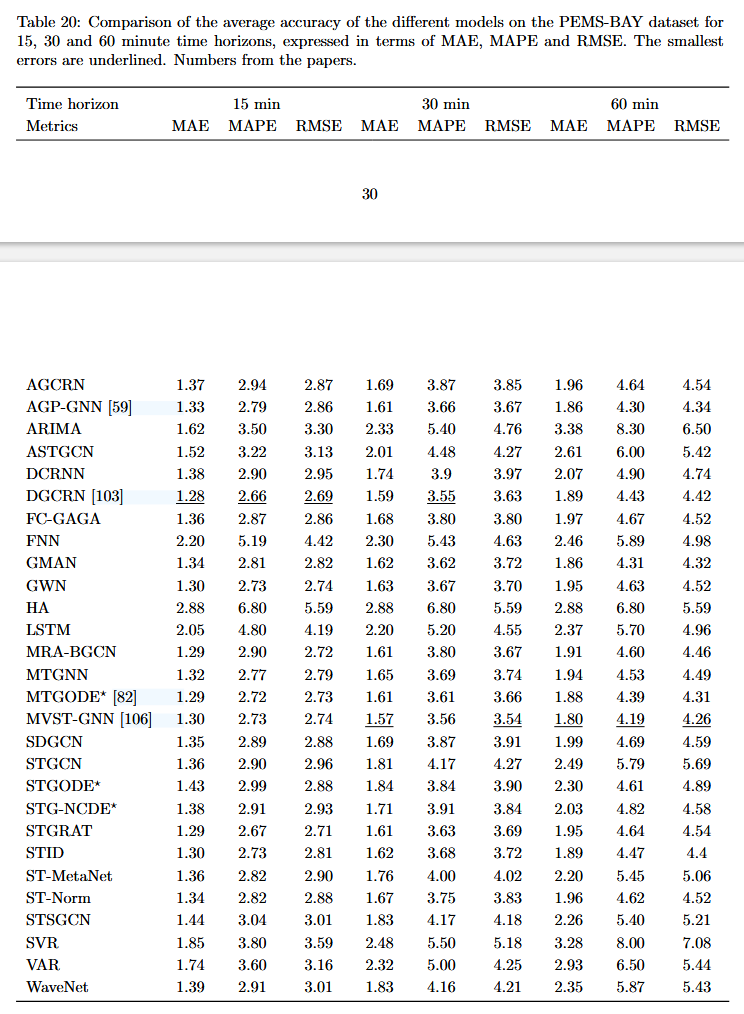
PEMS-BAY 数据集的结果表明,动态图卷积循环网络 (DGCRN) [103] 是 15 分钟预测范围内的最准确模型,而多视图时空图神经网络 (MVST-GNN) [106] 是较长预测范围内的最佳模型。
其他 PeMS 数据集: 对于 PeMS03、PeMS04、PeMS07 和 PeMS08 数据集,结果与 PEMS-BAY 数据集的结果基本一致,表明自动扩展时空同步图网络 (Auto-DSTSGN) [79] 是最准确的模型(不包括“通用”*模型),如表 21、22、23 和 24 所示。
结果总结:
-
对于 METR-LA 数据集,DyGCN-LSTM [94] 在较长预测范围内表现出色。 -
对于 PEMS-BAY 数据集,DGCRN [103] 在 15 分钟预测范围内表现最佳,而 MVST-GNN [106] 在较长预测范围内表现最佳。 -
对于其他 PeMS 数据集,Auto-DSTSGN [79] 是最准确的模型。
5.6 预测监控
在现代工业中,基于传感器的过程监控已成为必不可少的一部分。
5.6.1 概述
预测监控涉及对系统进行持续观察和分析,以预测其未来状态,并验证预测结果是否符合某些标准。
主要技术:
-
异常检测:旨在识别异常数据,这些数据不是由随机偏差引起的,而是由不同的潜在机制产生的。 -
故障诊断:确定系统是否发生故障,包括识别故障发生的时间、地点、类型和严重程度。 -
剩余使用寿命 (RUL) 估计:确定机器在需要维修或更换之前可以运行多长时间。
研究重点:
-
主要应用领域是工业(例如轴承故障诊断)和机械(例如发动机 RUL 估计)。 -
少数论文涉及能源相关任务,例如光伏系统故障诊断和能源网络故障诊断。 -
大多数论文旨在解决分类任务,这是异常检测和故障诊断的典型特征。
数据来源:
-
常用数据集包括 C-MAPSS 和 N-CMAPSS(NASA 提供的数据集,用于 RUL 预测)。 -
数据粒度从 1 小时到几分之一秒不等。 -
大多数数据集经过归一化处理,并使用数据增强方法来缓解正常和异常条件之间的不平衡。
5.6.3 提出的模型
-
提出的 GNN 模型中,一半属于纯卷积模型,其次是 4 个注意力 GNN、2 个混合模型和 1 个描述不明确的模型。 -
图结构: -
几乎所有模型都具有图学习模块,因此图结构很少由研究人员预先定义。 -
三篇论文使用 Lacasa 等人提出的可见性图算法 [96] 将时间序列转换为图。 -
损失函数: -
对于分类问题,最常用的损失函数是交叉熵函数。 -
对于 RUL 预测问题,最常用的损失函数是 MSE 或 RMSE。 -
代码实现: -
大多数论文提到了 Python 语言和 PyTorch 库。 -
只有两篇论文提供了其模型的源代码链接,并且都是针对 RUL 预测的。
5.6.4 基准模型
经典机器学习模型: 在该领域的论文中,使用了多种基准模型,但只有少数论文共享基准模型,尤其是在 GNN 类别中。最常用的基准模型是 CNN 和 LSTM 网络。
GNN 基准模型: 在 GNN 基准模型中,有两个模型是专门为剩余使用寿命预测开发的:
-
分层注意力图卷积网络 (HAGCN) [115]: Li 等人于 2021 年提出,使用分层图表示层对空间依赖性进行建模,并使用双向长短期记忆网络对传感器测量的时间依赖性进行建模。 -
时空融合注意力 (STFA) [93]: Kong 等人于 2022 年提出,将关于设备结构的先验知识与时空深度学习架构相结合,该架构采用 LSTM 单元和注意力机制。
5.6.5 结果
结果表明,提出的 GNN 模型优于基准模型。模型的准确性使用不同的指标进行评估,具体取决于上下文是分类还是预测。
-
对于分类任务,一些研究展示了混淆矩阵并计算了准确率百分比。 -
对于 RUL 预测问题,最常用的指标是 RMSE 和评分函数。
C-MAPSS 数据集: 表 27 显示了不同模型在 C-MAPSS 数据集上的准确性,该数据集包含四个子数据集 (FD001-FD004),结果以 RMSE 和评分函数表示。
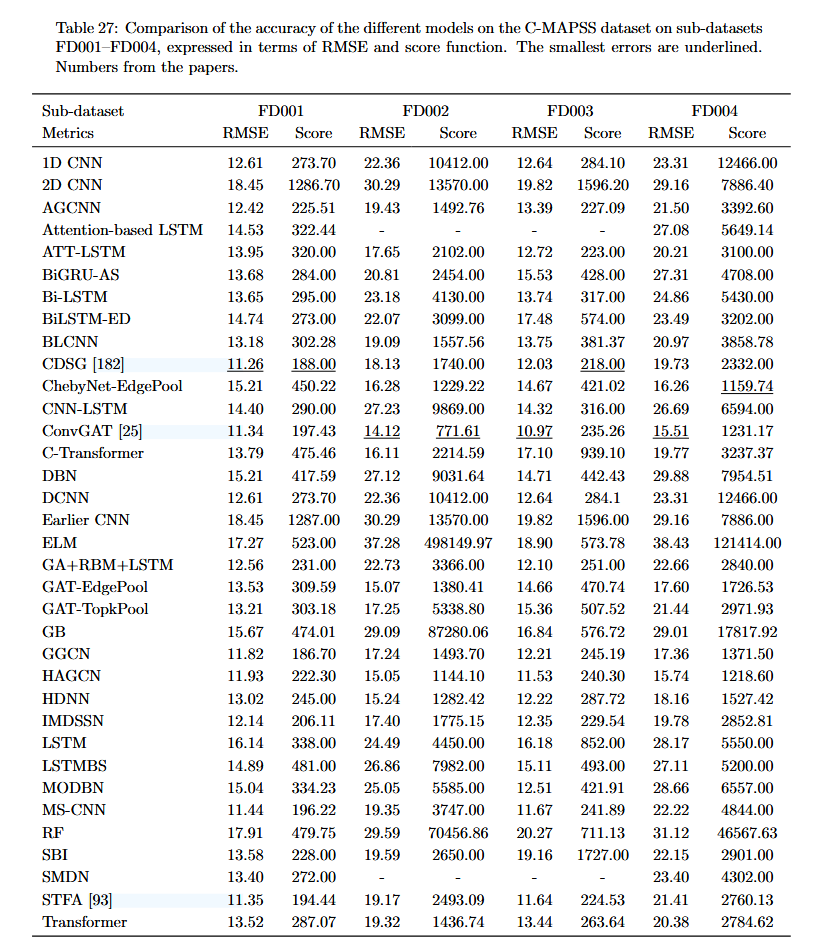
在 C-MAPSS 数据集上,CDSG [182] 和 ConvGAT [25] 模型在各个子数据集上的表现最好。
5.7 通用
本节包括所有没有明确针对特定问题的论文。
5.7.1 概述
“通用”组包含 24 篇论文。大多数工作都致力于解决不一定局限于特定领域的多变量时间序列预测问题。该组包括 1 篇 2021 年的论文、4 篇 2022 年的论文和 19 篇 2023 年的论文,这表明人们对在更广泛的背景下应用 GNN 产生了浓厚的兴趣。
数据来源: 论文中使用的公共数据集包括:
-
北京交通 ([26]) -
CCMP 风速数据 ([120]) -
CI 地震 ([10]) -
水痘病例 ([10]) -
CW 地震 ([30]) -
电量消耗 ([120], [48], [82], [121], [58], [21], [135], [170], [225], [64]) -
电量消耗负荷 (ECL) ([189], [88]) -
电量变压器温度 (ETT) ([237], [189], [88]) -
能源 ([41]) -
安然公司 (Enron) ([70]) -
Eu-Core ([120], [48], [237], [41], [121], [58], [21], [135], [88], [190], [30], [64]) -
Facebook ([70]) -
GEFCOM 2012 ([30]) -
超文本 (Hypertext) ([70]) -
ILI ([237]) -
耶拿天气 (Jena Weather) ([237]) -
贷款 (Loan) ([70]) -
METR-LA ([32], [82], [58], [21], [27], [10]) -
MIMIC-III 心力衰竭 (MIMIC-III Heart Failure) ([61]) -
MIMIC-III 感染 (MIMIC-III Infection) ([61]) -
MOOC 网络 (MOOC network) ([116]) -
纳斯达克 (Nasdaq) ([41], [21]) -
NOAA 天气 ([189]) -
PeMS03 ([48]) -
PeMS04 (PeMSD4) ([120], [48], [121], [58], [225]) -
PeMS08 (PeMSD8) ([120], [48], [121], [58], [225]) -
PEMS-BAY ([32], [82], [10]) -
PhysioNet ([61]) -
Reddit 网络 (Reddit network) ([116]) -
太阳能 (Solar-Energy) ([120], [48], [82], [121], [58], [21], [135], [170], [190], [225], [64]) -
TAIEX ([26]) -
淘宝 (TaoBao) ([70]) -
交通 (Traffic) ([82], [121], [58], [21], [135], [170], [88], [190], [64]) -
美国股市价格 (US stock market price) ([30]) -
Wikipedia 网络 (Wikipedia network) ([116]) -
风速 (Wind-Speed) ([237])
主要数据集: 电量消耗、汇率、太阳能和交通是四个最常见的数据集,均可在 https://github.com/laiguokun/multivariate-time-series-data 找到。
-
电量消耗数据集包含 2012 年至 2014 年间 321 名客户的每小时电量消耗(以 kWh 为单位)。 -
交通数据集描述了 2015 年至 2016 年间旧金山湾区道路网络不同传感器测量的道路占用率,数据粒度为每小时。 -
太阳能数据集记录了 2006 年阿拉巴马州 137 个光伏电站的太阳能发电量,数据粒度为每 10 分钟。 -
汇率数据集包含 1990 年至 2016 年间 8 个国家(包括澳大利亚、英国、加拿大、瑞士、中国、日本、新西兰和新加坡)的每日汇率。
数据粒度: 数据粒度差异很大,从几分之一秒到一周不等,表明没有特别关注特定的粒度。
预测范围: 几乎所有论文都关注多步预测,通常同时考虑 12 个不同的预测范围。
数据预处理: 只有少数论文提到数据预处理,通常使用最小-最大归一化或 Z-score 归一化。
5.7.3 提出的模型
-
在 24 篇“通用”论文中,19 篇使用纯卷积 GNN 方法,2 篇采用纯注意力模型。 -
一篇论文缺乏足够的细节来确定其分类。 -
另一篇论文声称使用了一种比卷积或注意力方法更简单的聚合方法。 -
还有一篇论文提出了一种多变量时间序列与动态图神经网络常微分方程 (MTGODE) 模型,其中简化图传播的连续动态由常微分方程 (ODE) 描述。 -
图结构: -
大多数模型使用自学习方法,因为这些论文都希望确保模型在不同环境中的适用性,而使用预定义的图结构定义规则会限制模型的通用性。 -
一半的论文采用动态图结构,可以适应数据中观察到的不同时间模式。 -
损失函数: -
最常用的损失函数是 MSE 和 MAE。 -
由于图结构通常由模型自行学习,因此许多论文在损失函数中包含一个正则化项,用于优化图结构。 -
代码实现: -
大多数论文指定了用于代码的语言和库,即 Python 和 PyTorch、PyTorch Geometric 和 Torch Spatiotemporal。 -
然而,只有不到一半的论文提供了源代码链接。
5.7.4 基准模型
数学和统计方法:
-
自回归综合移动平均 (ARIMA) 模型和历史平均 (HA) 模型非常流行,因为它们简单且易于解释。
经典机器学习模型:
-
最常用的模型是 LSTM、TPA-LSTM [166] 和 LSTNet [97]。 -
TPA-LSTM 模型采用一组滤波器来捕捉时间不变的时间模式,并使用注意力机制来识别与多变量预测相关的时间序列。 -
LSTNet 模型结合了卷积神经网络和循环神经网络来捕捉变量之间的短期局部依赖关系,并识别长期模式。此外,它还包含一个自回归模型,增强了深度学习对具有显著规模波动的时间序列的鲁棒性。
GNN 模型:
-
最常见的模型是 DCRNN [119] 和 MTGNN [201],这两个模型在前面章节中已经讨论过。
5.7.5 结果
-
“通用”组中评估模型时最常用的误差指标依次是平均绝对误差 (MAE)、相关系数 (CORR)、均方根误差 (RMSE)、相对均方根误差 (RRSE)、平均绝对百分比误差 (MAPE) 和均方误差 (MSE)。 -
与其他指标不同,相关系数 (CORR) 量化了预测值和实际值之间的线性关系的强度,值越高表示性能越好。 -
对于电量消耗数据集,提出的 GNN 模型总体上优于其他模型,静态和动态图学习网络 (SDGL) [121] 是最准确的。 -
对于汇率数据集,GNN 模型总体上表现最佳。离散图结构学习用于时间序列模型 (GTS) [161] 表现出卓越的性能,是一个合适的基准。 -
对于太阳能数据集,动态时空交互图神经网络 (DSTIGNN) 模型 [48] 和静态和动态图学习网络 (SDGL) 模型 [121] 分别在较短和较长的时间范围内表现出最高的准确性。 -
对于交通数据集,模型的准确性因范围和指标而异。然而,就 RRSE 而言,在所有范围内,时间分解增强图神经网络用于多变量时间序列预测 (TDG4MSF) [135] 是最好的模型。
5.8 其他主题
本节包括 20 篇不属于上述类别的论文。
5.8.1 概述
GNN 的应用领域不断扩展,本节讨论的其他应用包括:
-
蜂窝流量预测 ([194], [17], [218]):例如 SMS 消息、通话、互联网连接、手机流量统计或位置数据,这些数据对于蜂窝网络资源管理系统至关重要。 -
调制分类 ([181], [208], [3]):根据对接收信号的观察,确定发射机使用的调制方式。 -
用户偏好研究 ([235], [83]):实现个性化体验和推荐。 -
其他应用包括加密流量分类 [37]、城市时空事件预测 [81]、运营过程质量预测 [232]、地震强度预测 [11]、尾矿坝监测 [158]、教育视频参与度预测 [144]、地下生产预测 [130]、数据中心维护的时间序列预测 [163]、水力径流 [211]、水需求预测 [222] 和人类活动识别 [136]。
5.8.2 数据集
-
本节论文中只有三个共享数据集,其中两个用于调制分类,一个用于蜂窝流量预测。 -
由于数据集的处理方式不同(例如预处理技术、选择的时间窗口或训练/测试拆分百分比),因此这些论文的结果无法直接进行比较。
6. 讨论
这篇 SLR 的目的是全面概述时空 GNN 模型在时间序列分类和预测领域中的应用,并评估其在不同应用领域的性能。
通用研究问题:
-
大多数论文使用 Python 和 PyTorch,但也有一些研究人员使用 TensorFlow。 -
几乎所有论文都获得了公共或私人实体的资助。
具体研究问题:
SQ1(应用领域):
-
研究最多的三个领域依次是“移动”、“环境”和“通用”。 -
前两个领域的数据集可以自然地转换为图,这解释了为什么它们随着时间的推移得到了更广泛的研究。 -
相比之下,“通用”组最近引起了人们的极大兴趣,因为它适用于更广泛的背景。 -
不同领域之间的主要区别与图定义有关,图定义并不总是明确的,而且基准模型的使用通常与特定社区的心态有关。 -
很难比较不同应用的结果,也很难确定最有希望的研究领域。“通用”组的研究在更广泛的领域中显示出希望。
SQ2(图构建):
-
大多数选定的论文都侧重于预定义的图结构(如果可用),目的是提取尽可能多的信息并提高模型的可解释性。 -
然而,最近人们对模型自行学习图结构和边权重越来越感兴趣。预计这种趋势在未来会变得更加普遍。
SQ3(分类):
-
时空 GNN 的设计主要有两种方法:一种是将空间和时间组件分别处理,另一种是将它们整合在一起处理。 -
分析收集到的论文表明,文献中最常见的方法是分别处理组件。具体来说,研究人员通常独立于彼此解决问题的空间和时间方面,并分别关注每个模块。 -
提出的 GNN 模型分类仅指空间组件,综述表明卷积和注意力方法是主要的。大约 62% 的模型是纯卷积的,25% 是纯注意力的,8% 是混合卷积-注意力的。 -
关于时间组件,GRU 的循环结构和注意力机制被广泛使用。
SQ4(基准模型):
-
基准模型的选择取决于具体的应用。在能源、金融、健康和预测监控等领域,重点往往放在更简单的统计和经典机器学习基准上,只有有限的 GNN 基准使用。
-
在“移动”、“环境”和“通用”组(也是研究最多的领域)中,有许多参考 GNN 基准模型。最常见的基准包括:
-
图卷积神经网络与长短期记忆 (GC-LSTM) [154]: 将图卷积网络与长短期记忆网络相结合,用于预测 PM2.5 浓度的时空变化。 -
时空图卷积网络 (STGCN) [216]: 由 Yu 等人于 2018 年提出,由两个时空卷积块和一个全连接输出层组成,每个卷积块包含两个时间门控卷积层和一个中间的图卷积层。 -
基于注意力的时空图卷积网络 (ASTGCN) [57]: 由 Guo 等人于 2019 年提出,并行建模近期、每日周期性和每周周期性依赖性,并使用时空注意力机制和时空卷积来捕捉动态时空相关性。 -
扩散卷积循环神经网络 (DCRNN) [119]: 由 Li 等人于 2017 年提出,旨在使用图上的双向随机游走来捕捉空间依赖性,并使用具有计划采样的编码器-解码器架构来捕捉时间依赖性。 -
多变量时间序列预测与图神经网络 (MTGNN) [201]: 由 Wu 等人于 2020 年提出,将图神经网络应用于多变量时间序列预测。
SQ5(基准数据集):
-
选定的论文中提到的大多数数据集都与具体的案例研究相关。 -
尽管“通用”组中列出了一些基准数据集,但目前还没有整个 GNN 研究社区的通用标准数据集。 -
建立一个共同的基准数据集将有助于促进该领域的比较和进步。
SQ6(建模范式):
-
大多数选定的论文都使用同构图,它对具有相同性质的多个实体之间的关系进行建模。 -
这是因为许多基本的 GNN 算法最初是为同构图开发的,而且在许多情况下,重点是多变量序列,其中感兴趣的变量和目标量本质上是相同性质。 -
在某些情况下,图结构用于描述同一实体的不同方面,从而形成异构图。
SQ7(指标):
-
误差指标的选择高度依赖于具体的案例研究。 -
最常用的指标包括: -
对于预测问题:平均绝对误差 (MAE)、均方误差 (MSE) 和平均绝对百分比误差 (MAPE)。 -
对于分类问题:准确率。
7. 局限性、挑战和未来研究方向
7.1 可比性
-
尽管 Open Graph Benchmark (OGB) [67] 的引入提高了 GNN 模型的评估水平,因为它提供了一个标准化的评估框架和各种基准图数据集,但目前还没有时空 GNN 的标准化基准。 -
因此,每个模型都在其自己选择的数据集上进行评估,这种碎片化使得比较不同研究的结果变得困难。 -
为了缓解这个问题,这篇综述提供了从选定的论文中收集的所有信息,包括数据集、基准、代码和结果表,希望研究人员能够开始审查所呈现表格中收集的数据,并随着时间的推移,确定相关的数据集和基准模型。
7.2 可重复性
-
源代码、存储库和数据集链接的可用性有限,使得评估时空 GNN 领域知识进展变得困难。 -
此外,在许多论文中,作者没有提供有关模型和图结构的详细信息,例如图的定义、节点数量、边权重的计算等。 -
这些问题使结果的验证和实验可重复性的评估变得复杂,而这些对于推动该领域的进一步研究至关重要。
7.3 可解释性
-
GNN 模型的一个关键方面是可解释性,即解释和理解其决策过程的能力。 -
尽管 GNN 试图显式地对序列之间的空间关系进行建模,但它们通常被视为“黑盒”模型。 -
目前还没有选定的论文充分解决可解释性的概念。 -
然而,最近的文献开始研究这一重要课题。例如,一些论文研究了基于扰动的解释方法,但据报道,这些方法的有效性有限 [180]。 -
其他方法,例如 GNNExplainer [215],旨在识别对 GNN 预测起关键作用的节点特征的子集。 -
最近,一些研究人员开始探索图反事实作为生成解释的一种手段 [153]。
7.4 信息容量不足
-
GNN 的另一个局限性在于图结构设计和模型定义背后的信息量不足。 -
图结构构建不当,连接不具有代表性或过于稀疏,以及模型方程中缺乏物理约束,都会显著影响性能。 -
尽管人们已经努力解决这些问题,例如通过微分方程整合物理约束,但这些方法并不总是有效的。 -
因此,开发新技术来克服这些局限性至关重要。
7.5 异质性
-
大多数当前的 GNN 模型都是为同构图设计的,其中节点和边都是相同类型。 -
因此,使用这些 GNN 处理异构图(具有不同类型的节点和边或不同输入)具有挑战性。 -
因此,需要进一步的研究来开发能够有效捕捉不同类型节点和边之间交互的 GNN 模型。
7.6 可扩展性
-
时空 GNN 被广泛用于建模和分析大型复杂的基于时间序列的网络结构。 -
然而,GNN 模型通常需要大量内存来计算邻接矩阵和节点嵌入,尤其是在动态图结构的情况下。 -
这种可扩展性挑战导致计算成本高,在许多情况下,需要使用大量 GPU 资源。 -
因此,开发更具可扩展性的 GNN 模型对于促进在计算能力有限的环境中进行时间序列分析至关重要。
8. 结论
本文介绍了时空 GNN 模型在时间序列分类和预测问题中的应用的 SLR 结果。
近年来,GNN 由于能够处理图结构数据而获得了极大的普及。这导致近年来在时间序列分析领域开发了时空 GNN,因为它们能够对变量之间以及不同时间点之间的依赖关系进行建模。
这篇 SLR 提出了两套问题:一套是通用问题,可以从文献综述的角度回答,另一套是更具体的问题,涉及所提出的时空 GNN 模型的特定方面。通过回答这些问题,可以看出,选定的论文中的大多数模型都具有卷积空间聚合的特征。然而,一些图注意力模型也正在出现。此外,虽然大多数选定的论文都侧重于具有预定义图结构的模型,但越来越多的研究(特别是在“通用”组中)开始开发能够自行学习图结构的模型。
从所呈现的概述中可以得出的第一个关键点是,当前的时空 GNN 文献非常零散,如图 4 所示。这可以归因于所涉及的 researchers 来自不同的社区,专注于特定的应用领域。因此,似乎缺乏标准化的数据集或基准。这篇综述的目标也是收集有关数据集、提出的模型、源代码链接、基准和结果的信息,以便为未来的研究奠定基础。因此,这篇综述提出的第二个主要关键点似乎是,GNN 研究社区需要致力于使用共同的数据集,并开发可比且可重复的模型。这将提高透明度,并使评估该领域的进展和更轻松地共享它们变得更加容易。
论文已整理至星球
