
哈喽,今儿和大家聊的是「人工神经网络ANN」~
今儿的内容非常详细,记得点赞收藏起来慢慢看!
先做一个简单的介绍,后面通过详细的推导和案例和大家来说明。
人工神经网络(Artificial Neural Network,ANN)是受生物神经网络启发而设计的一类计算模型,由大量互联的人工神经元组成。它们通过调整权重和偏置来学习和处理数据中的复杂模式,广泛应用于分类、回归、图像处理、语音识别等领域。ANN的基本思想是模仿人脑神经元之间的连接方式,通过层层传递和处理信息,实现从输入到输出的映射。
ANN通常包括以下几个部分:
1. 输入层(Input Layer):接收外部输入数据。
2. 隐藏层(Hidden Layers):进行特征提取和非线性变换。可以有一个或多个隐藏层。
3. 输出层(Output Layer):生成最终的输出结果。
每一层由若干神经元组成,神经元之间通过权重连接。每个神经元接受前一层的输出,加权求和后通过激活函数生成当前层的输出。
人工神经网络的历史背景
1943年 – 神经元模型的提出
人工神经网络的概念可以追溯到1943年,当时神经科学家沃伦·麦卡洛克(Warren McCulloch)和数学家沃尔特·皮茨(Walter Pitts)提出了第一个数学模型,称为麦卡洛克-皮茨神经元。这一模型描述了神经元的工作方式,即通过接收多个输入信号,进行加权求和并通过一个激活函数产生输出。
1958年 – 感知器(Perceptron)
1958年,弗兰克·罗森布拉特(Frank Rosenblatt)发明了感知器,这是第一个能够进行简单分类任务的神经网络模型。感知器由输入层、权重和输出组成,通过调整权重来学习输入和输出之间的关系。然而,单层感知器只能解决线性可分的问题。
1969年 – 反向传播算法
1969年,马文·明斯基(Marvin Minsky)和西摩尔·派普特(Seymour Papert)在《感知器》一书中指出,感知器无法解决线性不可分的问题,如异或(XOR)问题。这一发现一度导致神经网络研究的停滞。直到1986年,大卫·鲁梅哈特(David Rumelhart)、杰弗里·辛顿(Geoffrey Hinton)和罗纳德·威廉姆斯(Ronald Williams)等人重新提出并推广了反向传播算法,这使得多层神经网络可以高效地训练,解决了许多非线性问题。
1980年代 – 神经网络的复兴
1980年代,随着反向传播算法的推广和计算能力的提升,神经网络研究逐渐复苏。研究人员开始探索更复杂的网络结构和训练方法,如卷积神经网络(CNN)和递归神经网络(RNN)。
2010年代 – 深度学习的兴起
2010年代,深度学习(Deep Learning)技术的突破引发了人工神经网络的又一次大发展。深度神经网络(DNN)通过堆叠多层隐藏层,可以学习更复杂的特征表示,显著提高了在图像识别、语音识别、自然语言处理等领域的性能。关键推动因素包括:
-
大规模数据集的出现 -
高性能计算硬件(如GPU)的发展 -
新型网络结构(如深度卷积神经网络和长短期记忆网络(LSTM))的设计 -
高效训练算法的优化
人工神经网络的发展历程体现了计算模型从简单到复杂的演变过程,以及计算能力和算法优化对其发展的重要影响。从最初的感知器到如今的深度学习,ANN已经成为现代人工智能的核心技术之一。
理论基础
人工神经网络(ANN)是一种模拟生物神经系统的计算模型,由大量互联的神经元(Neuron)组成。它通过学习数据中的模式来执行各种任务,如分类、回归、图像识别等。
数学原理
1. 神经元(Neuron)
每个神经元接收多个输入信号,进行加权求和并加上一个偏置,然后通过激活函数输出结果。数学表示如下:
其中:
-
是第 个输入信号 -
是对应的权重 -
是偏置 -
是线性组合的结果
然后,激活函数 作用在 上,得到神经元的输出:
常见的激活函数有:
-
Sigmoid:
-
ReLU:
-
Tanh:
2. 网络结构
ANN由多个层(Layer)组成,通常包括:
-
输入层(Input Layer):直接接收输入数据
-
隐藏层(Hidden Layer):对输入进行特征提取和变换
-
输出层(Output Layer):输出最终的结果
每一层的输出作为下一层的输入。隐藏层和输出层的每个神经元都可以使用不同的激活函数。
3. 前向传播(Forward Propagation)
前向传播是计算神经网络输出的过程。具体步骤如下:
-
输入数据通过输入层传递到第一个隐藏层。 -
隐藏层的每个神经元计算其输出(激活值)。 -
隐藏层的输出传递到下一层,依次类推,直到输出层。 -
输出层产生最终结果。
例如,对于一个三层神经网络(输入层、一个隐藏层和输出层):
-
输入层: -
隐藏层:权重矩阵 和偏置向量 -
输出层:权重矩阵 和偏置向量
前向传播计算如下:
-
隐藏层输入: -
隐藏层输出: -
输出层输入: -
输出层输出:
4. 损失函数(Loss Function)
损失函数用于衡量模型输出与真实值之间的差距。常用的损失函数包括:
-
均方误差(MSE):
-
交叉熵损失(Cross-Entropy Loss):
其中, 是真实值, 是预测值, 是样本数量。
5. 反向传播(Backpropagation)
反向传播用于计算损失函数相对于权重和偏置的梯度,并更新这些参数以最小化损失。具体步骤如下:
1. 计算损失的梯度:
-
计算输出层的损失梯度。 -
使用链式法则逐层向前传播计算每层的损失梯度。
2. 更新权重和偏置:
-
使用梯度下降法(或其变种)更新权重和偏置。 -
学习率(Learning Rate)控制每次更新的步长。
梯度下降的公式为:
其中, 是学习率。
算法流程
1. 初始化:随机初始化网络的权重和偏置。
2. 前向传播:
-
将输入数据传递到输入层。 -
计算每层的激活值并传递到下一层,直至输出层。 3. 计算损失:使用损失函数计算模型输出与真实值之间的差距。
4. 反向传播:
-
计算输出层的损失梯度。 -
使用链式法则逐层向前传播计算每层的损失梯度。 -
更新权重和偏置。 5. 迭代训练:重复前向传播、计算损失和反向传播的过程,直至达到预定的迭代次数或损失函数收敛。
6. 模型评估:在验证集或测试集上评估模型性能,调整超参数以优化模型。
详细的算法步骤
1. 数据预处理:
-
归一化:将数据标准化以加速收敛。 -
分割数据集:将数据分成训练集、验证集和测试集。
2. 初始化参数:
-
权重 通常随机初始化为小值(如从标准正态分布中采样)。 -
偏置 通常初始化为零或小值。
3. 前向传播:
-
对于每一层 : -
计算线性组合: -
应用激活函数:
4. 计算损失:
-
计算损失函数 ,其中 是输出层的索引。
5. 反向传播:
-
初始化反向传播:计算输出层的梯度: -
对于每一层 (从后向前): -
计算误差项: -
计算梯度: -
更新参数:
6. 迭代训练:
-
在所有训练样本上重复上述前向传播和反向传播步骤。 -
在每个epoch结束后评估模型的验证集性能,如果性能未提升,可以进行学习率调整或提前停止训练。
7. 模型评估:
-
使用测试集评估模型的最终性能。 -
调整超参数(如学习率、隐藏层数量、神经元数量)以进一步优化模型。
通过上述详细步骤,可以构建并训练一个人工神经网络,利用反向传播算法优化网络参数,最终实现模型在特定任务上的良好表现。
应用场景
人工神经网络(ANN)适用于多种问题,特别是那些具有复杂、非线性关系的任务。以下是ANN的适用情况、优缺点以及运用时的前提条件。
适用情况
1. 复杂非线性关系:ANN能够学习和表示复杂的非线性关系,适用于许多现实世界中的复杂问题,如图像识别、自然语言处理等。
2. 大规模数据集:当有大量数据可用时,ANN通常表现出色。大数据集可以提供足够的样本来训练模型,并帮助其泛化到新的数据上。
3. 特征提取:ANN可以自动学习数据中的特征表示,无需手工提取特征,这使得它们在许多任务中更具优势。
优点
1. 适应性强:ANN能够学习和适应各种复杂的数据模式和关系。
2. 并行处理:ANN的训练和推理过程可以并行化,利用并行计算资源可以加速模型的训练和推理。
3. 泛化能力:当正确调整时,ANN可以很好地泛化到新数据上,即使在训练集之外的数据上也能表现良好。
缺点
1. 黑箱模型:ANN通常被认为是黑箱模型,难以解释其内部决策过程,这可能在某些场景下不可接受。
2. 需要大量数据和计算资源:训练一个复杂的ANN通常需要大量的数据和计算资源,包括大量的样本和高性能的硬件。
3. 超参数调整困难:ANN中存在许多超参数需要调整,如网络结构、学习率、正则化参数等,调整这些参数需要大量的经验和实验。
运用前提条件
1. 数据准备:需要准备足够数量和质量的数据,以及进行适当的数据预处理。
2. 计算资源:训练复杂的ANN需要大量的计算资源,包括高性能的CPU或GPU。
3. 超参数调整:需要进行适当的超参数调整,以优化模型性能。
实际应用案例
案例:图像分类
问题描述:给定一组图像,识别图像中的对象或场景。
应用场景:用于自动驾驶车辆的视觉感知、医学影像识别、安防监控系统等。
ANN的作用:ANN可以学习图像中的特征表示,通过训练识别各种不同的对象或场景。例如,使用卷积神经网络(CNN)可以提取图像中的局部特征,并将其用于分类任务。
实际案例:ImageNet图像分类挑战赛是一个著名的图像分类竞赛,参与者使用ANN来识别图像中的物体类别。2012年,Hinton等人提出的AlexNet模型在该竞赛中取得了显著的成功,大大提高了图像分类的准确率,标志着深度学习在计算机视觉领域的崛起。
Python案例
咱们使用 ANN 构建一个案例,包括数据预处理、模型构建、训练、评估、优化和可视化的完整流程。这个示例使用Keras库来构建和训练一个ANN模型。
使用MNIST数据集,这是一个包含手写数字的经典数据集,用于图像分类任务。
导入库
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
加载和预处理数据
# 加载MNIST数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据归一化
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
# 独热编码
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
可视化部分训练数据
# 显示部分训练数据
fig, axes = plt.subplots(2, 5, figsize=(10, 5))
axes = axes.ravel()
for i in np.arange(0, 10):
axes[i].imshow(x_train[i], cmap='gray')
axes[i].title.set_text(np.argmax(y_train[i]))
axes[i].axis('off')
plt.subplots_adjust(hspace=0.5)
plt.show()


构建ANN模型
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu'),
Dense(64, activation='relu'),
Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
定义回调函数
# 提前停止和学习率调整
early_stopping = EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True)
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.2, patience=3, min_lr=0.001)
训练模型
history = model.fit(
x_train, y_train,
epochs=50,
batch_size=128,
validation_split=0.2,
callbacks=[early_stopping, reduce_lr],
verbose=2
)
评估模型
test_loss, test_accuracy = model.evaluate(x_test, y_test, verbose=2)
print(f'Test loss: {test_loss:.4f}')
print(f'Test accuracy: {test_accuracy:.4f}')
可视化训练过程
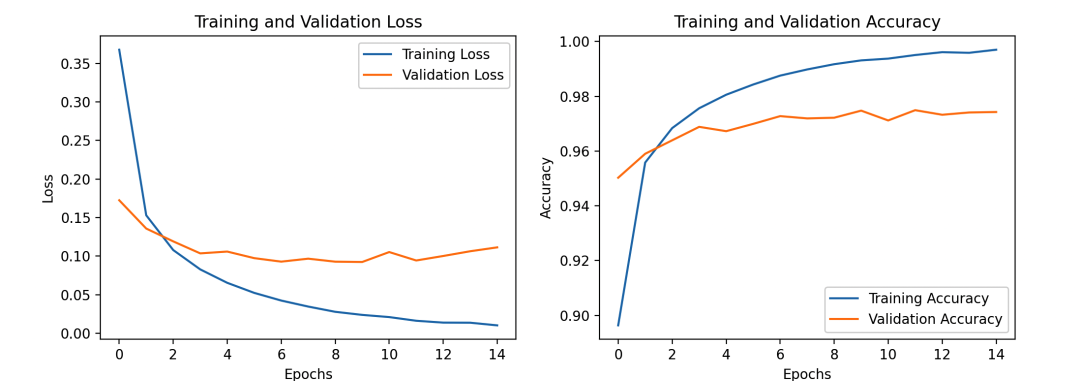
# 绘制训练和验证损失
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.title('Training and Validation Loss')
# 绘制训练和验证准确率
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.title('Training and Validation Accuracy')
plt.show()
使用模型进行预测
# 对测试集进行预测
predictions = model.predict(x_test)
# 显示一些预测结果
fig, axes = plt.subplots(2, 5, figsize=(10, 5))
axes = axes.ravel()
for i in np.arange(0, 10):
axes[i].imshow(x_test[i], cmap='gray')
axes[i].title.set_text(f"Pred: {np.argmax(predictions[i])}")
axes[i].axis('off')
plt.subplots_adjust(hspace=0.5)
plt.show()

模型优化建议
1. 增加层数和神经元数量:可以尝试增加隐藏层的数量或每层的神经元数量,但要注意防止过拟合。
2. 正则化:添加Dropout层或L2正则化,以减少过拟合。
3. 高级优化器:尝试使用高级优化器如AdamW、Nadam等,以获得更好的优化效果。
4. 数据增强:对训练数据进行数据增强(如旋转、平移、缩放等),增加数据的多样性,从而提升模型的泛化能力。
整个代码中已经包含了一些优化措施(如提前停止和学习率调整),可以根据具体情况进一步调整和优化。
最后
