
转自公众号:QuantML
http://mp.weixin.qq.com/s?__biz=Mzg2MzAwNzM0NQ==&mid=2247487959&idx=1&sn=9ad7b54e01bfd7994f631b71ecd11c31
深度森林(Deep Forest)是一种新颖的决策树结构,它由深层的神经网络模型启发,试图通过深度堆叠树的方法来提升树模型预测的性能。深度森林的特点在于教少的超参数和自适应复杂度,在不同规模的数据上,深度森林都可以做得很好。
算法介绍
深度学习近年来取得了巨大的成功,基于深度学习的实际应用已经走进我们身边,特别是最近GPT类的大语言模型带来了很多应用场景。传统来说,深度学习就是深度神经网络,它是一个由逐层的神经元加上各种激活函数构成的可微组件。那么,深度学习一定就是深度神经网络吗?周志华教授发表于2017年的深度森林论文《Deep Forest》提出了另外一种可能。
在论文中,作者认为,深度神经网络的成功有着如下三个因素:第一,算法需要有逐层的处理;第二,算法需要有特征的内部变换;第三,算法需要有足够的模型复杂度。以下是一个经典的神经网络识别图像的过程,可以看到是满足以上几点的。
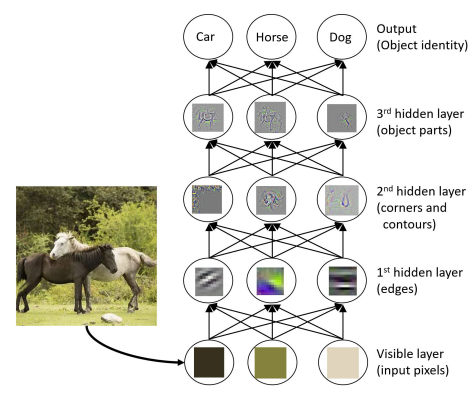

他们点出了深度神经网络可能会有的一些问题,包括:1.深度神经网络模型需要有大量的参数需要调整,且参数调整的经验难以共享。2.深度神经网络模型的可复现性相对来说不如树模型。3.并且,在使用深度神经网络模型时,需要事先定好复杂度。但是在解决任务之前很多时候可能是不知道需要多少复杂度的。在现实任务中,深度神经网络往往也是在图像、视频、声音这几类典型任务上表现比较好,都是连续的数值建模问题。而在别的凡是涉及到混合建模、离散建模、符号建模这样的任务上,其实深度神经网络的性能可能比其他模型还要差一些。
作者想出了用树模型作为基模型,然后进行堆叠(stacking)的方法。但是,如果这样简单的堆叠树,实际上是不可能训练的很深的,因为过拟合会比较严重。作者指出,通过提升每一层模型的多样性(包括选用不同的特征、选用不同的树模型),就可以把模型训练的比较深。他们所提出的gcForest算法是首个不依赖梯度、不依赖反向传播的深度模型,并且除了大规模图像数据之外,在其中的大多数任务上gcForest都可以获得和深度神经网络类似的表现。
然而,原始的深度森林在实际应用中有占有的内存高、只能用CPU训练等问题。LAMDA组后面又发布了一个新的深度森林开源库DF-21来提升性能。在此版本中,在千万级别的表格型数据集上进行训练,模型占用的内存一下减少到了原来的十分之一左右,这在一定程度上解决了深度森林固有的内存消耗、只能用CPU训练等问题。该库中深度森林模型的架构如下图:
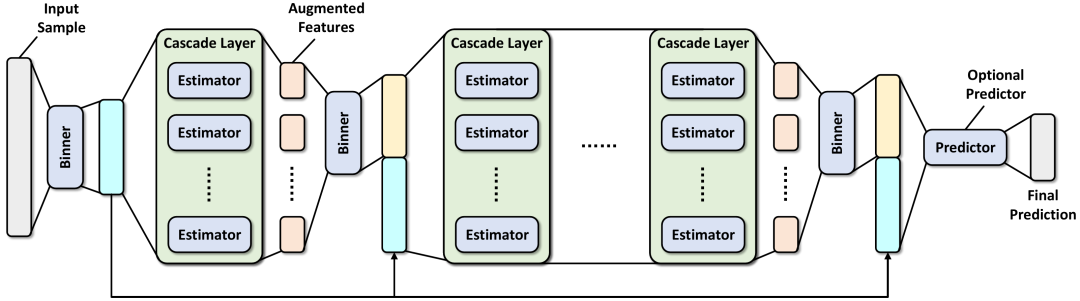
我们根据上图给大家介绍深度森林的构成和组件。
-
输入特征(Input Sample) -
分箱器(Binner):用于将特征进行分箱。具体来说,比如某个特征x有10000个不同的值,分箱器会获取该特征的个分位数信息(通常来说,远小于10000),然后将这10000个值分入对应的分位数中。因为决策树需要划分数值特征,这样做能够减少决策树的备选划分数量,也能减少异常值的影响,增强鲁棒性。 -
级联层(Cascade Layer):这是一系列估计器(Estimator)的组合。每个估计器都是一颗树模型,可以使用多种不同的树模型作为估计器。每个级联层里的估计器都会接受同样的输入特征,然后生成增强特征(Augmented Features)。增强特征会和输入特征拼接进入下一层的级联层。通过多层级联层后,最终得到一个最后的特征组合。 -
预测器(Predictor,可选):将最后的特征组合再次过一个树模型获得最终的预测结果。
算法的整个流程如下:
-
数据分箱:使用分箱器对输入特征进行分箱 -
然后构建第一个级联层,训练级联层内部的所有树模型。
在进行完上述的流程后,如果定义的树深度大于1,则进入以下循环:
-
使用上一个级联层对该层的输入进行预测,输出增强特征。 -
将增强特征和输入特征进行拼接,作为构建该层级联层的训练数据。 -
构建该层级联层,训练级联层内部的所有树模型。(训练的方式与第一层相同) -
使用K折方法,通过样本外估计目前模型的泛化性能。 -
如果估计的性能优于之前构建的层,深度森林就会继续构建新层,直到到了用户定义的最大层数。否则,就会触发早停机制。
最后,如果定义了预测器,此预测器接受最后一个级联层的连接训练数据作为输入,并输出分类问题的预测类概率和回归问题的预测值。
使用说明
现在,深度森林的包已经可以很简单的通过pip安装:
pip install deep-forest
深度森林定义模型方式如下:
from deepforest import CascadeForestClassifier
model = CascadeForestClassifier(n_estimators=1)
在官方定义的模型中,每个估计器都是一个RandomForest和ExtraTrees的结合(对于这两个模型可以参考scikit-learn的文档)。因此,如果使用官方定义的模型,需要调整n_estimators决定估计器的数量,以及调整估计器内部的一些参数,包括max_depth(树的深度)、n_trees(树的数量)等。
我们也可以定义自己想要的估计器。下方给出了一个简单的示例来定义估计器(需要安装XGBoost和LightGBM):
import xgboost as xgb
import lightgbm as lgb
from deepforest import CascadeForestRegressor
model = CascadeForestRegressor()
estimator = [xgb.XGBRegressor(), lgb.LGBMRegressor()]
model.set_estimator(estimator)
最终的预测器官方提供了forest、xgboost和lightbgm,当然,我们也可以自定义预测器。
predictor = xgb.XGBRegressor()
model.set_predictor(predictor)
深度森林使用了与scikit-learn类似的API设计。例如,下面的代码片段展示了在安装完成后,如何将深度森林利用在一个简单的数字分类数据集上:
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from deepforest import CascadeForestClassifier
X, y = load_digits(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
model = CascadeForestClassifier(random_state=1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred) * 100
下面的代码展示了如何保存模型和读取模型:
# 保存
model.save(MODEL_DIR)
# 读取
new_model = CascadeForestClassifier()
new_model.load(MODEL_DIR)
性能展示
库里使用深度森林和几种经典的树模型算法进行了比较,包括随机森林、sklearn中的直方图GBDT、XGBoost和LightGBM。
对于分类任务,以下是分类任务所使用的数据集:
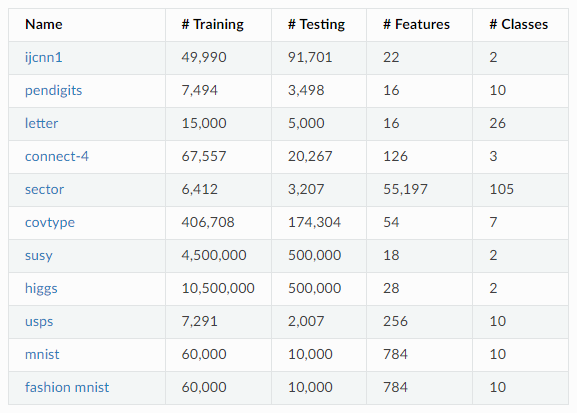
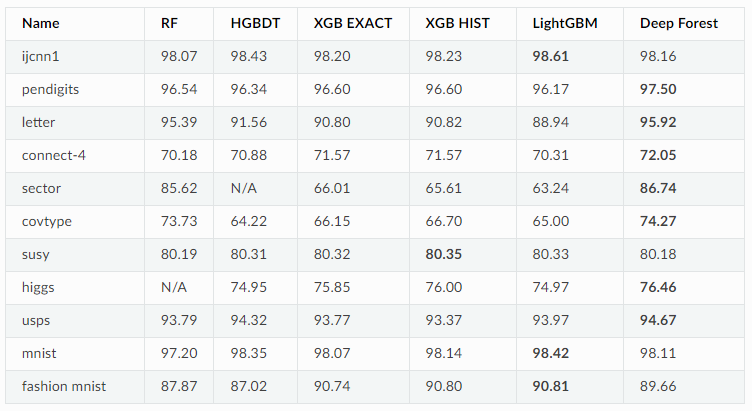
分类准确率如下,可以看到深度森林在大部分数据集中还是占优的:
对于回归任务,以下是回归任务所使用的数据集:
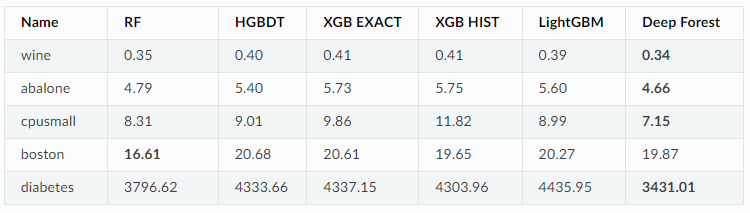
回归RMSE如下,深度森林也有优势。
最后,笔者尝试用深度森林构建过全A股票选股策略(因为某些原因,没法公开自用的因子,但是提供了一个简单的版本),对比了XGBoost和LightGBM的结果(19-24年):
深度森林:IC 0.071,ICIR 0.8495,多头1组超额年化38%
XGBoost:IC 0.065,ICIR 0.7493,多头1组超额年化32.4%
LightGBM:IC 0.067,ICIR 0.7835,多头1组超额年化33.1%
参考文献
项目地址:https://deep-forest.readthedocs.io/
论文:https://arxiv.org/abs/1702.08835
(本文来自星球会员乌萨奇的投稿,作者提供的完整代码见星球)
