
收录于话题
2024年11月22日arXiv cs.CV发文量约110余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省46分钟浏览arXiv的时间。


IDEA Research推出了DINO-X,这是一种统一的以物体为中心的视觉模型。该模型利用基于Transformer的架构和大规模数据集,实现了无提示的开放世界物体检测,并显著提高了长尾物体识别任务的性能。
【Bohr精读】
https://j1q.cn/VQi5GNt7
【arXiv链接】
http://arxiv.org/abs/2411.14347v1
【代码地址】
https://github.com/IDEA-Research/DINO-X-API

香港大学、香港科技大学和德克萨斯农工大学联合提出了一种新颖的流程。该流程通过利用大型基础模型进行分割和三维重建,从单视图图像中重建手物体交互,随后进行先验引导的优化,以确保符合物理约束和输入图像内容。这项研究为图像处理和计算机视觉领域提供了新的视角和方法,具有重要的学术价值和应用潜力。
【Bohr精读】
https://j1q.cn/tWG9IsY4
【arXiv链接】
http://arxiv.org/abs/2411.14280v1
【代码地址】
https://lym29.github.io/EasyHOI-page/

约翰霍普金斯大学、Adobe研究和香港科技大学介绍了DiffusionGS,这是一种单阶段3D扩散模型。该模型能够从单一视角生成3D高斯点云,并通过场景–物体混合训练策略确保视角一致性和提高生成质量。
【Bohr精读】
https://j1q.cn/u80YTe1D
【arXiv链接】
http://arxiv.org/abs/2411.14384v1
【代码地址】
https://caiyuanhao1998.github.io/project/DiffusionGS/

苹果介绍了AIMV2,这是一种新颖的多模态预训练方法,专为视觉编码器设计。该方法结合了图像块和文本token的自回归生成技术,在多种视觉任务中表现出色,超越了当前最新的对比模型。AIMV2的推出为视觉编码领域带来了新的可能性,为研究人员和开发者提供了更强大的工具和方法。
【Bohr精读】
https://j1q.cn/EzG6DjKo
【arXiv链接】
http://arxiv.org/abs/2411.14402v1
【代码地址】
https://github.com/apple/ml-aim

阿卜杜拉国王科技大学推出了StereoCrafter-Zero,这是一种用于零样本立体视频生成的新颖框架。该框架利用视频扩散先验,并结合噪声重启策略和迭代优化,以增强深度一致性和时间平滑性,而无需配对训练数据。
【Bohr精读】
https://j1q.cn/bvL9O42R
【arXiv链接】
http://arxiv.org/abs/2411.14295v1
【代码地址】
https://github.com/shijianjian/StereoCrafter-Zero

北京大学和清华大学联合提出了LACING框架,这一创新方法通过双重注意力机制和软视觉提示,旨在减少大型视觉语言模型中的语言偏见。该框架不仅增强了模型的视觉理解能力,还在不增加训练资源的情况下有效地最小化了幻觉现象。这项研究为视觉语言模型的进一步发展提供了新的视角和解决方案。
【Bohr精读】
https://j1q.cn/PIugVzyN
【arXiv链接】
http://arxiv.org/abs/2411.14279v1
【代码地址】
https://lacing-lvlm.github.io

浙江大学推出了RestorerID,这是一种基于扩散模型的无调优盲人脸修复方法。该方法通过使用单个参考图像来保留ID信息,并通过新颖的面部ID重平衡适配器和自适应ID尺度调整策略,成功解决了内容不一致和轮廓错位的问题。
【Bohr精读】
https://j1q.cn/PjvvEkwV
【arXiv链接】
http://arxiv.org/abs/2411.14125v1
【代码地址】
https://github.com/YingJiacheng/RestorerID
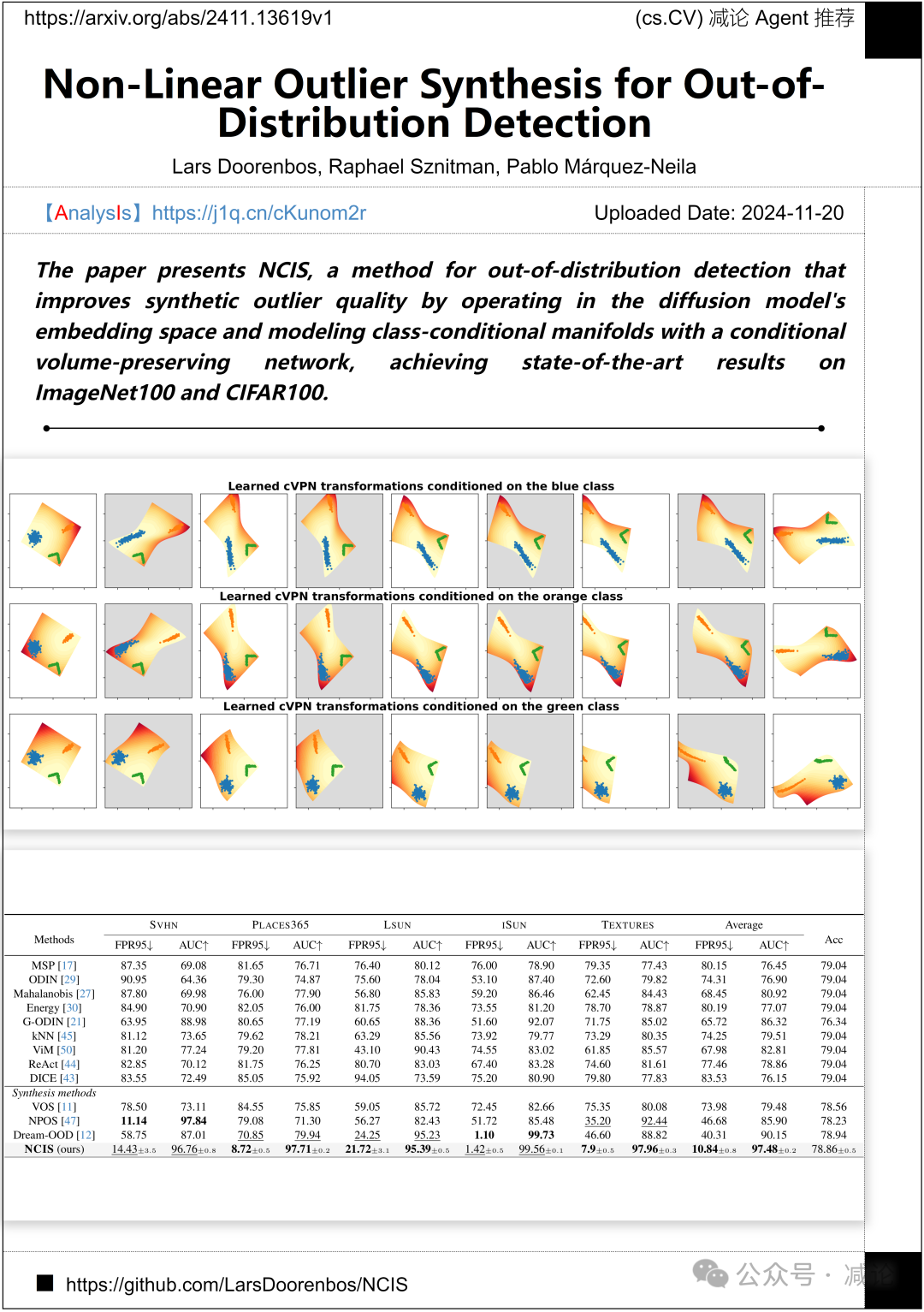
伯尔尼大学提出了NCIS方法,这是一种用于检测分布外数据的创新技术。该方法通过在扩散模型的嵌入空间中进行操作,并利用条件体积保持网络对类条件流形进行建模,显著提高了合成异常值的质量。在ImageNet100和CIFAR100数据集上的实验结果表明,该方法达到了当前最先进的水平。
【Bohr精读】
https://j1q.cn/cKunom2r
【arXiv链接】
http://arxiv.org/abs/2411.13619v1
【代码地址】
https://github.com/LarsDoorenbos/NCIS

香港中文大学、香港科技大学和华为诺亚方舟实验室联合推出了一种新颖的视频合成方法——MagicDriveDiT。该方法通过利用流匹配、渐进训练和时空条件编码,显著提高了生成高分辨率、长街景视频的可扩展性和控制性,旨在应用于自动驾驶领域。这一创新技术为自动驾驶系统提供了更为精确和可控的视频生成解决方案,推动了相关研究的进一步发展。
【Bohr精读】
https://j1q.cn/xnofx7BO
【arXiv链接】
http://arxiv.org/abs/2411.13807v1
【代码地址】
https://flymin.github.io/magicdrivedit/

上海海事大学与弗里德里希–亚历山大大学埃尔朗根–纽伦堡联合提出了MLDet,这是一种专为SAR图像中的船舶检测设计的多任务学习框架。该框架集成了目标检测、斑点抑制和目标分割等任务,通过角度分类损失、双特征融合注意力、旋转高斯掩码进行分割,以及加权旋转框融合策略,显著提高了检测的准确性和鲁棒性。
【Bohr精读】
https://j1q.cn/DfZfsSVg
【arXiv链接】
http://arxiv.org/abs/2411.13847v1
【代码地址】
https://github.com/zx152/MLDet

天津大学提出了一种轻量且准确的去阴影框架。该框架利用一种新颖的区域注意力机制,有效捕捉非阴影区域的关键信息,增强阴影区域的恢复能力。在效率和性能上,该模型优于现有的其他模型,为去阴影任务提供了新的解决方案。
【Bohr精读】
https://j1q.cn/YD647v74
【arXiv链接】
http://arxiv.org/abs/2411.14201v1
【代码地址】
https://github.com/CalcuLuUus/RASM

香港城市大学与商汤科技联合提出了一种名为GLMix的方法。该方法在不同粒度水平上整合卷积和多头自注意力,利用卷积提取细粒度的局部特征,并通过多头自注意力提取粗粒度的全局特征,从而显著提高了视觉任务的效率和可扩展性。这一创新为相关领域的研究和应用提供了新的视角和工具。
【Bohr精读】
https://j1q.cn/BnbRFSQ2
【arXiv链接】
http://arxiv.org/abs/2411.14429v1
【代码地址】
https://github.com/rayleizhu/GLMix
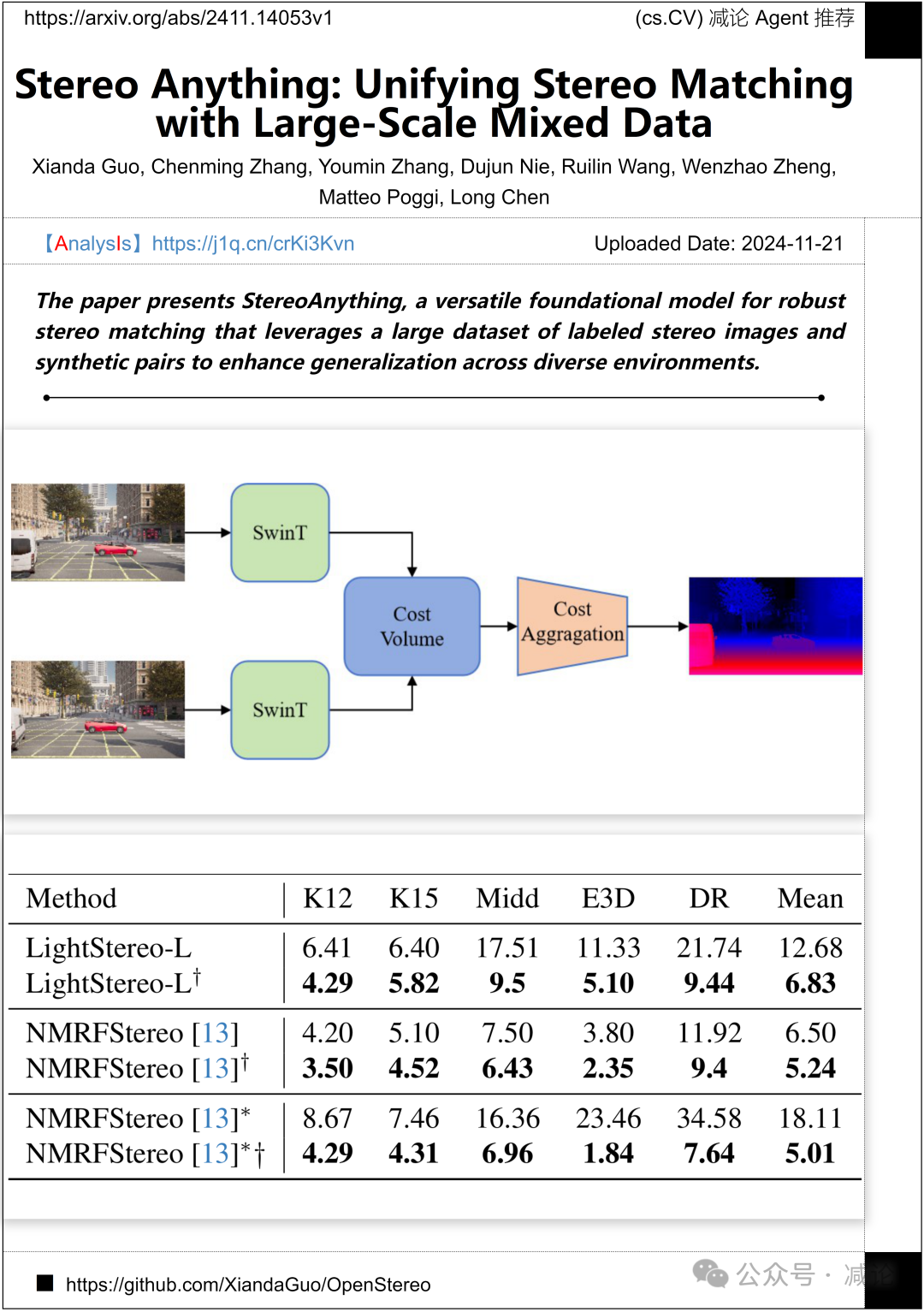
武汉大学、西安交通大学和加州大学伯克利分校联合介绍了StereoAnything,这是一种多功能的基础模型,专注于稳健的立体匹配。该模型通过利用大量标注的立体图像数据集和合成对,显著增强了在不同环境中的泛化能力。这一研究为立体视觉领域提供了新的思路和工具,适用于多种复杂应用场景。
【Bohr精读】
https://j1q.cn/crKi3Kvn
【arXiv链接】
http://arxiv.org/abs/2411.14053v1
【代码地址】
https://github.com/XiandaGuo/OpenStereo
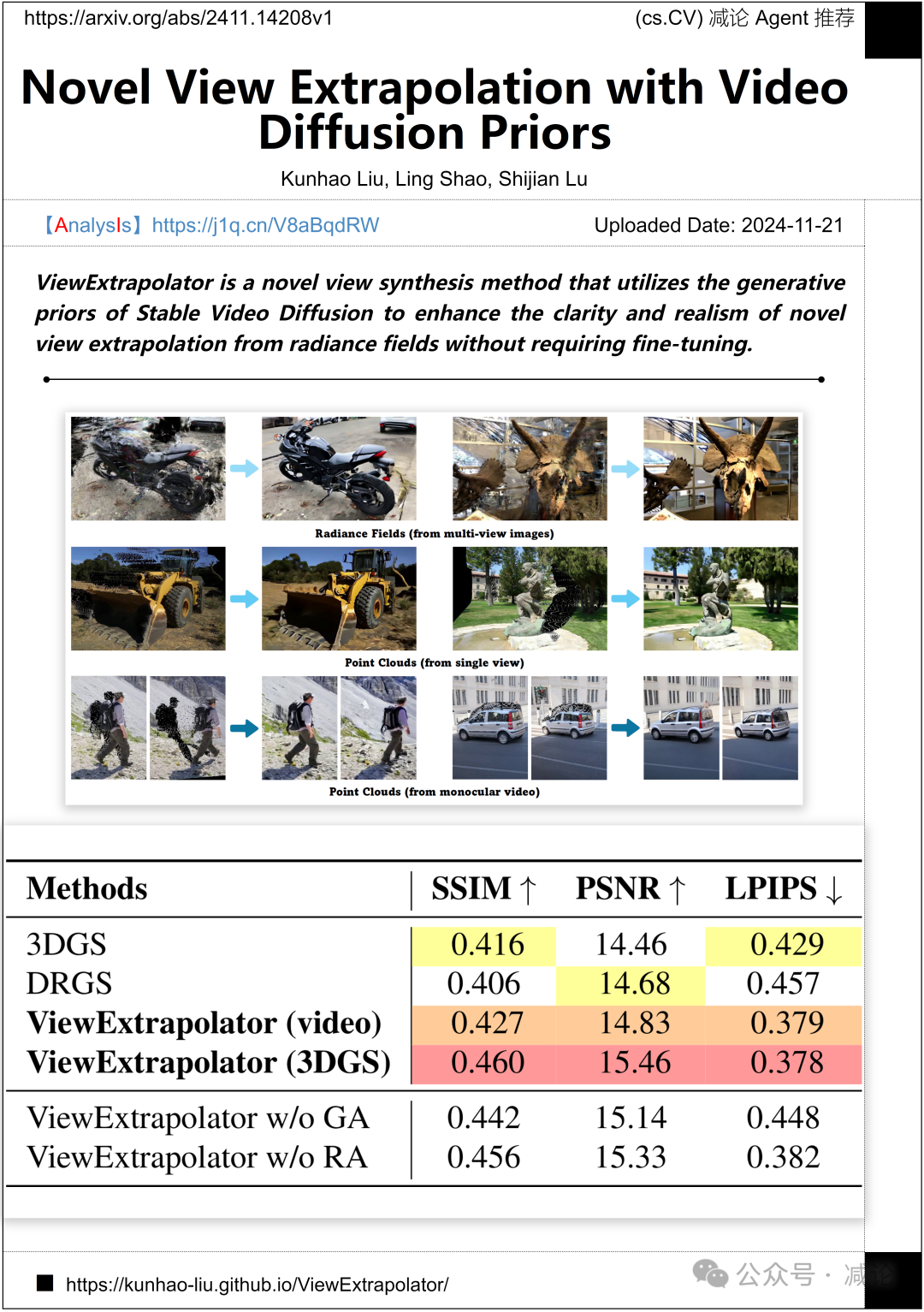
南洋理工大学和中国科学院大学联合推出了一种新颖的视图合成方法——ViewExtrapolator。该方法利用Stable Video Diffusion的生成先验,在无需微调的情况下,提高了从辐射场中进行新视图外推的清晰度和真实感。这一研究为视图合成领域提供了新的解决方案,具有重要的学术价值和应用前景。
【Bohr精读】
https://j1q.cn/V8aBqdRW
【arXiv链接】
http://arxiv.org/abs/2411.14208v1
【代码地址】
https://kunhao-liu.github.io/ViewExtrapolator/
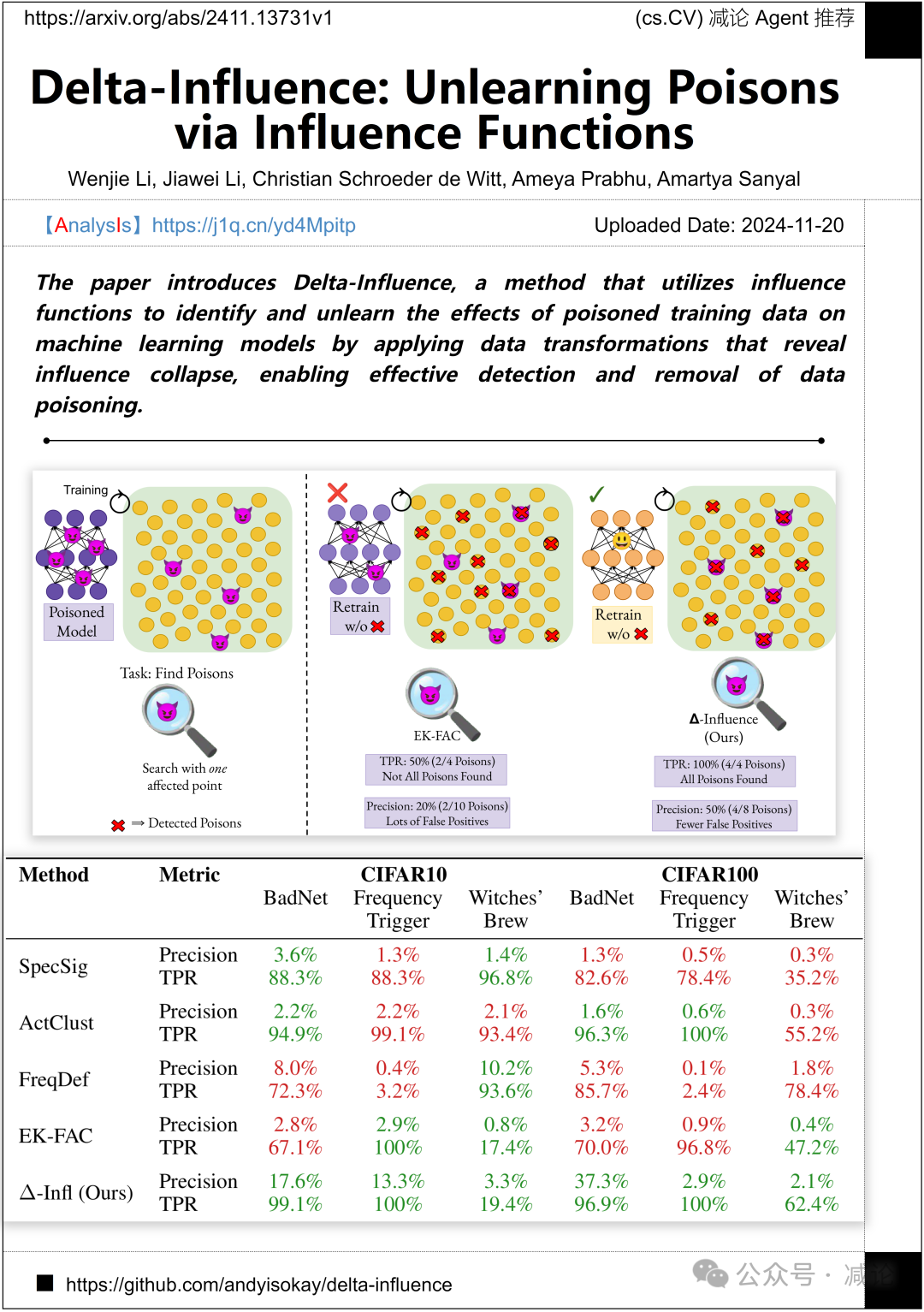
上海科技大学、清华大学和哥本哈根大学联合介绍了Delta-Influence方法。这一方法利用影响函数,通过应用揭示影响崩溃的数据转换,识别和消除中毒训练数据对机器学习模型的影响,从而实现有效检测和去除数据中毒。该研究为提高机器学习模型的鲁棒性提供了新的思路和工具,对相关领域的研究和应用具有重要意义。
【Bohr精读】
https://j1q.cn/yd4Mpitp
【arXiv链接】
http://arxiv.org/abs/2411.13731v1
【代码地址】
https://github.com/andyisokay/delta-influence
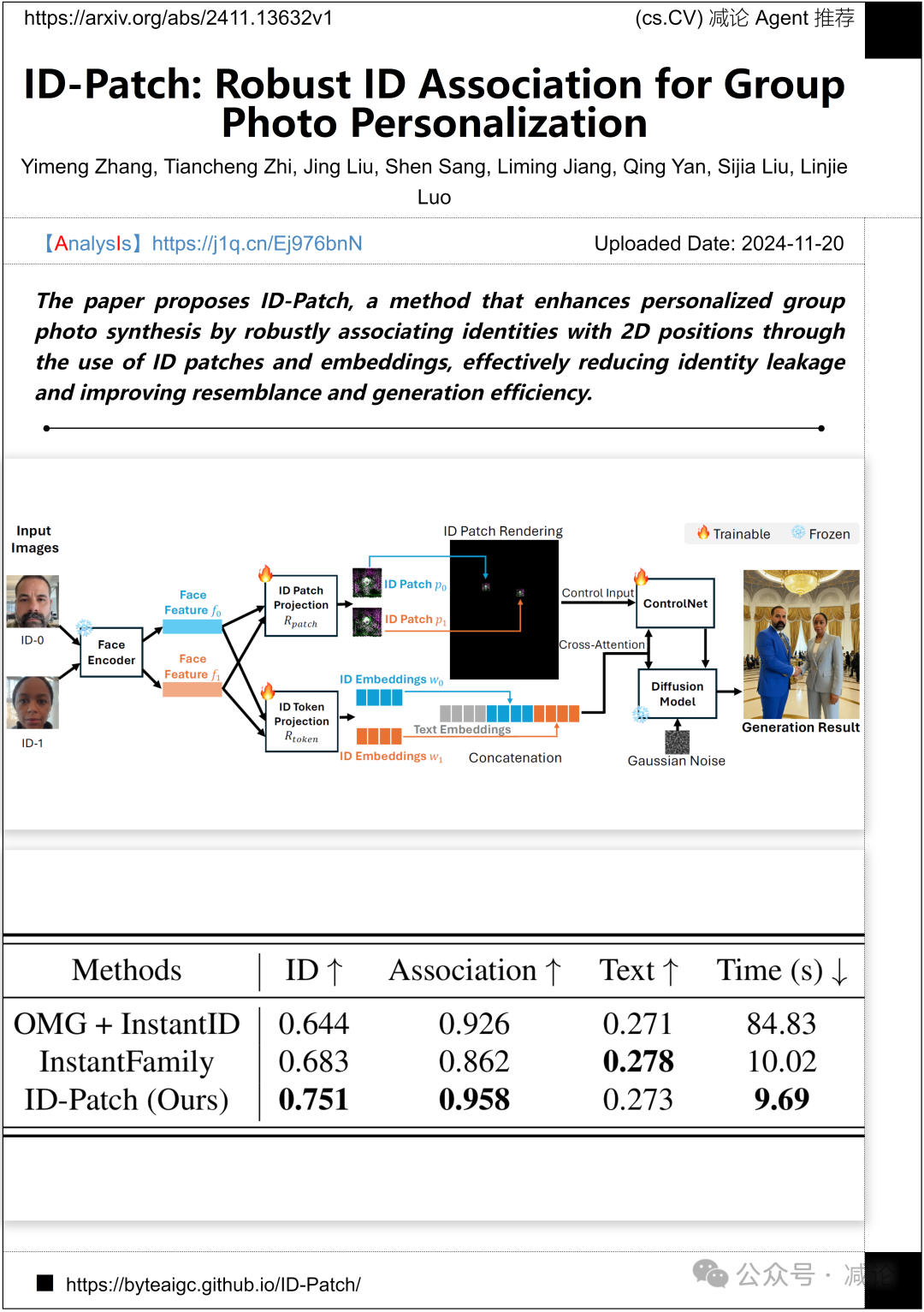
字节跳动公司和密歇根州立大学提出了ID-Patch方法,该方法通过使用ID补丁和嵌入,将身份与二维位置稳健关联,从而增强个性化合影合成。此方法有效减少了身份泄露,并提高了相似性和生成效率。
【Bohr精读】
https://j1q.cn/Ej976bnN
【arXiv链接】
http://arxiv.org/abs/2411.13632v1
【代码地址】
https://byteaigc.github.io/ID-Patch/
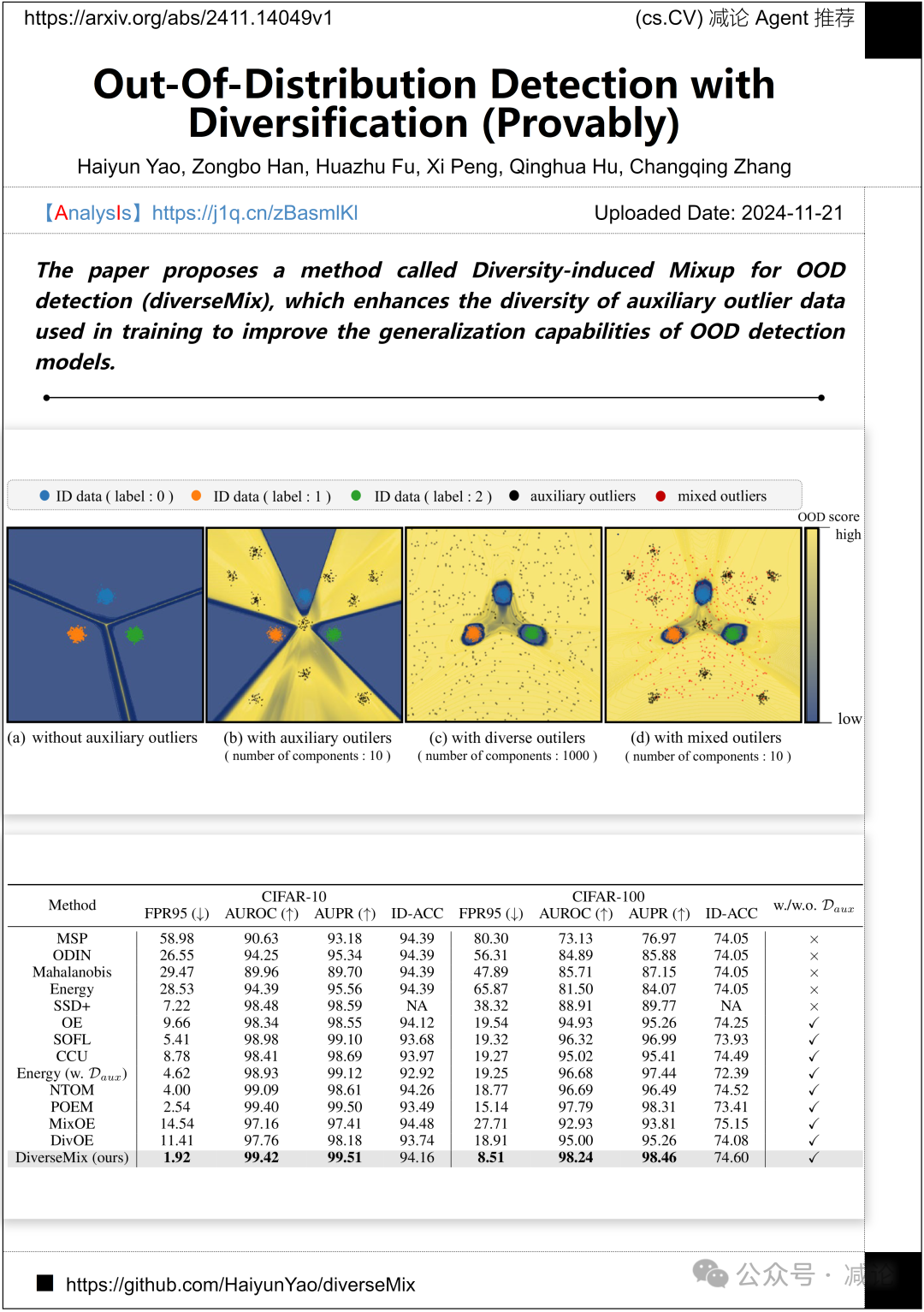
天津大学、新加坡科技研究局和四川大学联合提出了一种名为Diversity-induced Mixup(diverseMix)的方法,用于提升OOD检测模型的泛化能力。该方法通过增强训练中使用的辅助异常数据的多样性,显著提高了模型在检测任务中的表现。论文详细探讨了diverseMix方法的理论基础和实验结果,为相关领域的研究提供了新的思路和方法。
【Bohr精读】
https://j1q.cn/zBasmlKl
【arXiv链接】
http://arxiv.org/abs/2411.14049v1
【代码地址】
https://github.com/HaiyunYao/diverseMix
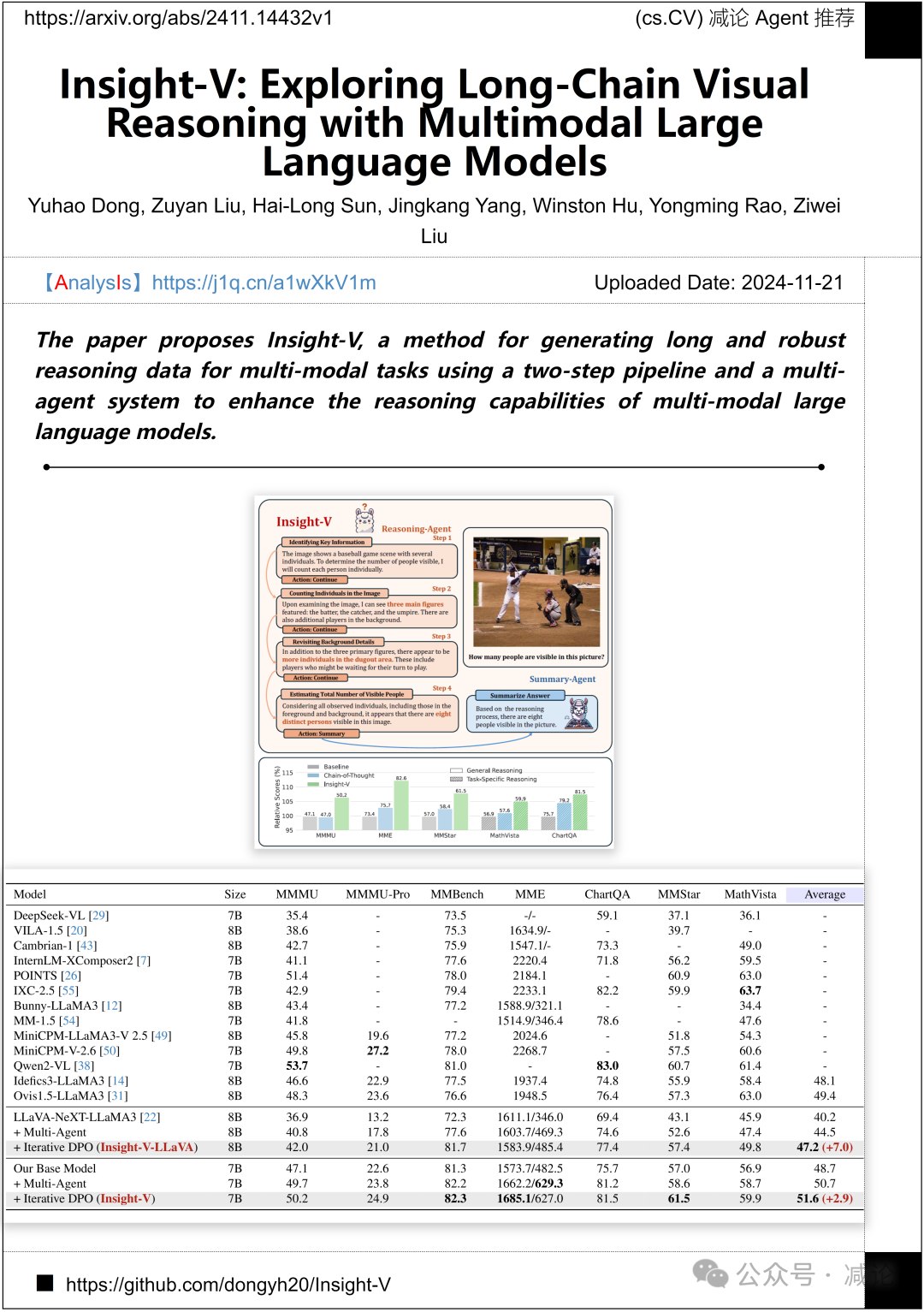
南洋理工大学、腾讯和清华大学联合提出了Insight-V,这是一种通过两步流程和多代理系统为多模态任务生成长且稳健推理数据的方法。该方法旨在增强多模态大型语言模型的推理能力,为相关领域的研究提供了新的视角和工具。
【Bohr精读】
https://j1q.cn/a1wXkV1m
【arXiv链接】
http://arxiv.org/abs/2411.14432v1
【代码地址】
https://github.com/dongyh20/Insight-V

欢迎关注减论,持续输出有深度的人工智能极减理解,提升信息获取效率和认知维度。看完点颗小星星再走呗~