
收录于话题
2024年11月18日arXiv cs.CV发文量约99余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省42分钟浏览arXiv的时间。
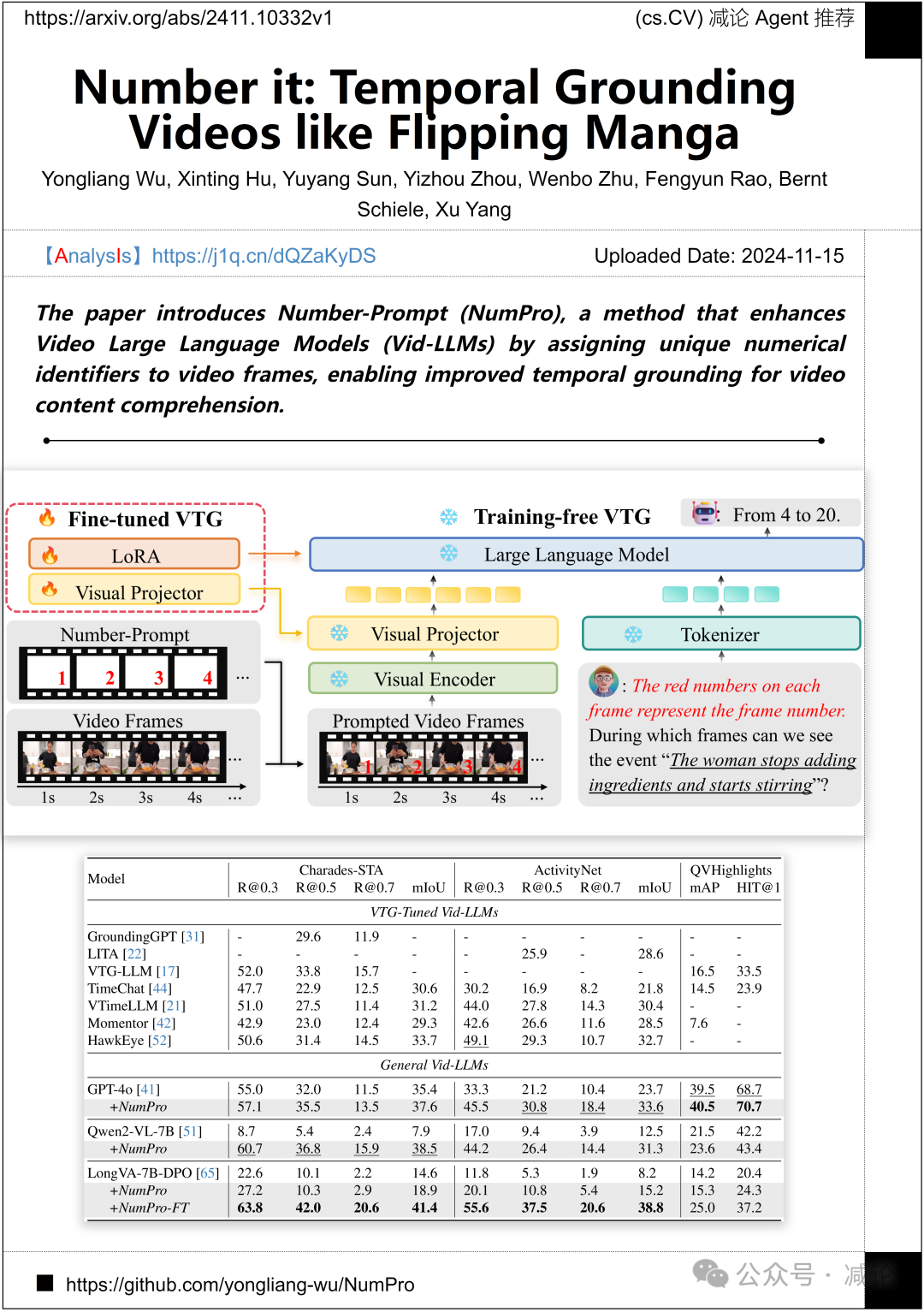

东南大学,马克斯·普朗克信息学研究所,加州大学伯克利分校的研究团队推出了一种新方法。该论文介绍了Number-Prompt(NumPro),一种通过为视频帧分配唯一的数字标识符来增强Video Large Language Models(Vid-LLMs)的方法,从而实现对视频内容理解的时间基准的改进。
【Bohr精读】
https://j1q.cn/dQZaKyDS
【arXiv链接】
http://arxiv.org/abs/2411.10332v1
【代码地址】
https://github.com/yongliang-wu/NumPro

信息技术研究所的研究团队提出了一种新颖的音视频深度伪造检测框架DiMoDif,利用机器对语音的感知中的跨模态差异来识别音频和视频信号之间帧级不一致,从而比现有方法更有效地定位深度伪造。
【Bohr精读】
https://j1q.cn/ZmnRANdG
【arXiv链接】
http://arxiv.org/abs/2411.10193v1
【代码地址】
https://github.com/mever-team/dimodif

约翰霍普金斯大学、加州大学伯克利分校和加州大学圣克鲁兹分校的研究团队介绍了M-VAR。这是一个针对图像生成的分尺度自回归框架,它将局部空间依赖的尺度内建模与跨尺度关系的尺度间建模分离开来,提高了计算效率,并在图像质量和生成速度方面胜过现有模型。
【Bohr精读】
https://j1q.cn/p8H0p0i9
【arXiv链接】
http://arxiv.org/abs/2411.10433v1
【代码地址】
https://github.com/OliverRensu/MVAR

澳门大学和武汉大学的研究团队提出了一种方法,用于单图像3D肖像生成。通过在条件和扩散过程中整合多视角先验,增强了跨视图一致性,从而产生高保真度、细节丰富的3D模型。
【Bohr精读】
https://j1q.cn/WmqU4NEY
【arXiv链接】
http://arxiv.org/abs/2411.10369v1
【代码地址】
https://haoran-wei.github.io/Portrait-Diffusion

杭络科技、华南理工大学、香港中文大学的研究团队提出了BiDense,一种通用的二值神经网络。该网络通过使用适应分布的二值化器来增强密集预测任务,以提高信息保留,并利用适应通道的全精度旁路来最小化信息丢失。这种方法可以实现与全精度模型相当的性能,同时降低内存和计算成本。
【Bohr精读】
https://j1q.cn/aKBe6K1O
【arXiv链接】
http://arxiv.org/abs/2411.10346v1
【代码地址】
https://github.com/frickyinn/BiDense

蚂蚁集团EchoMimicV2团队提出了一种半身人类动画方法,通过音频–姿势动态协调简化控制条件,利用头部局部注意力进行头部数据训练,并引入特定阶段的去噪损失以增强动画质量,优于现有方法。
【Bohr精读】
https://j1q.cn/iHPa6bQE
【arXiv链接】
http://arxiv.org/abs/2411.10061v1
【代码地址】
https://antgroup.github.io/ai/echomimic v2
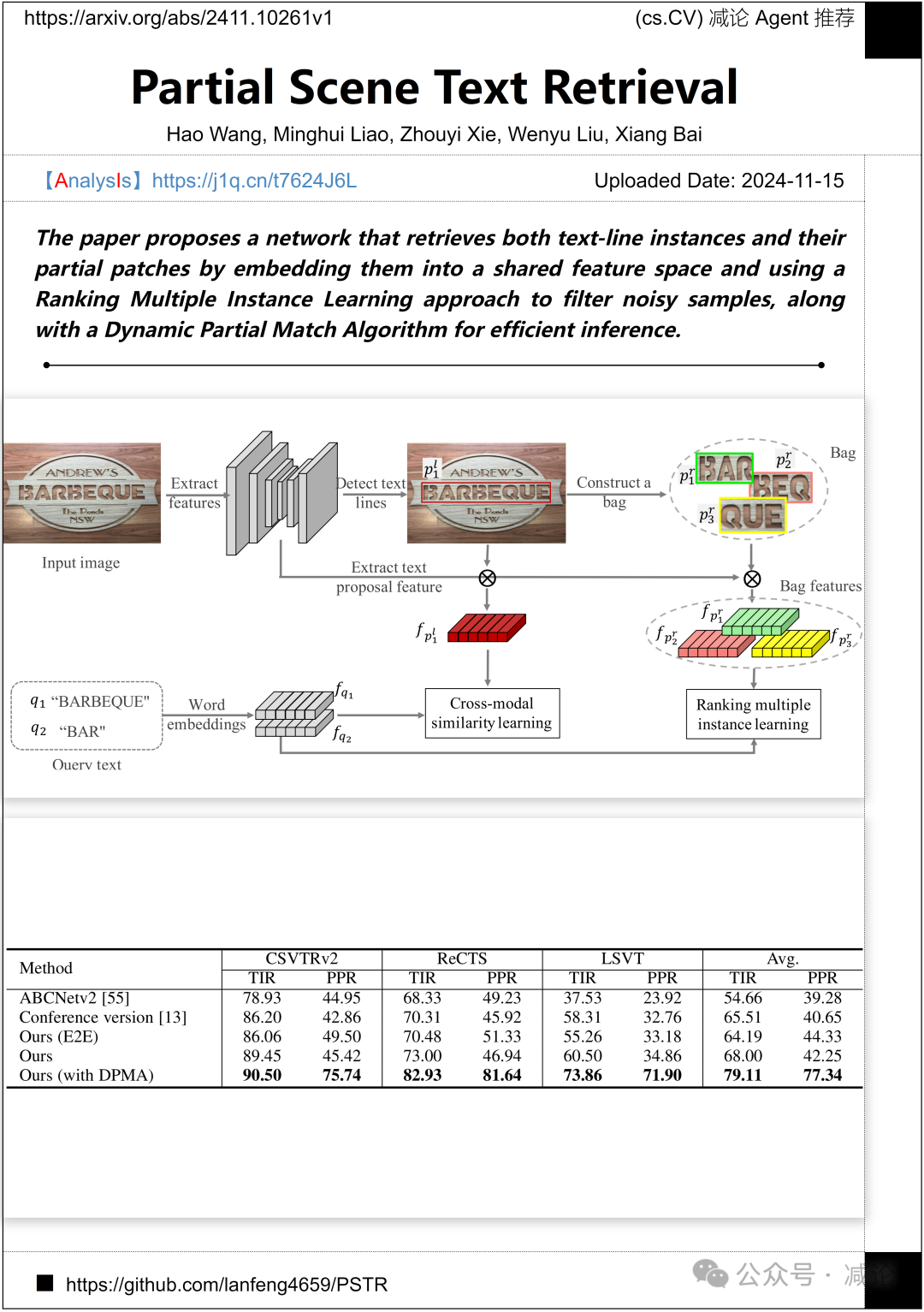
华中科技大学和华为团队提出了一个新的网络,通过将文本行实例和它们的部分补丁嵌入到共享特征空间中,并使用排名多实例学习方法来过滤噪声样本,同时还采用动态部分匹配算法进行高效推断。
【Bohr精读】
https://j1q.cn/t7624J6L
【arXiv链接】
http://arxiv.org/abs/2411.10261v1
【代码地址】
https://github.com/lanfeng4659/PSTR

中佛罗里达大学计算机视觉研究中心、中央佛罗里达大学、西澳大利亚大学和德克萨斯大学达拉斯分校的研究团队提出了基于动作的视频推理方法。该方法旨在根据问题生成视频分割掩模,支持一个名为GROUNDMORE的大型数据集和一种新颖的模型MORA,通过多模态推理和像素级感知增强动作理解。
【Bohr精读】
https://j1q.cn/5PpXk1DC
【arXiv链接】
http://arxiv.org/abs/2411.09921v1
【代码地址】
https://groundmore.github.io/

香港理工大学的研究团队提出了OSDiffST,一种新颖的风格迁移方法。该方法利用预训练的扩散模型,在保持结构完整性和减少失真的同时,有效地呈现3D场景的多视图图像中的多样风格。
【Bohr精读】
https://j1q.cn/kT96SJvC
【arXiv链接】
http://arxiv.org/abs/2411.10130v1
【代码地址】
https://github.com/YushenZuo/OSDiffST

暨南大学与伯明翰大学的研究团队提出了GGAvatar,这是一个用于从单目视频中脱衣人的解耦和逼真重建的模型,利用先进的参数化模板和分阶段训练来有效地将服装与身体分离。
【Bohr精读】
https://j1q.cn/m48CsbRZ
【arXiv链接】
http://arxiv.org/abs/2411.09952v1
【代码地址】
https://github.com/J-X-Chen/GGAvatar/
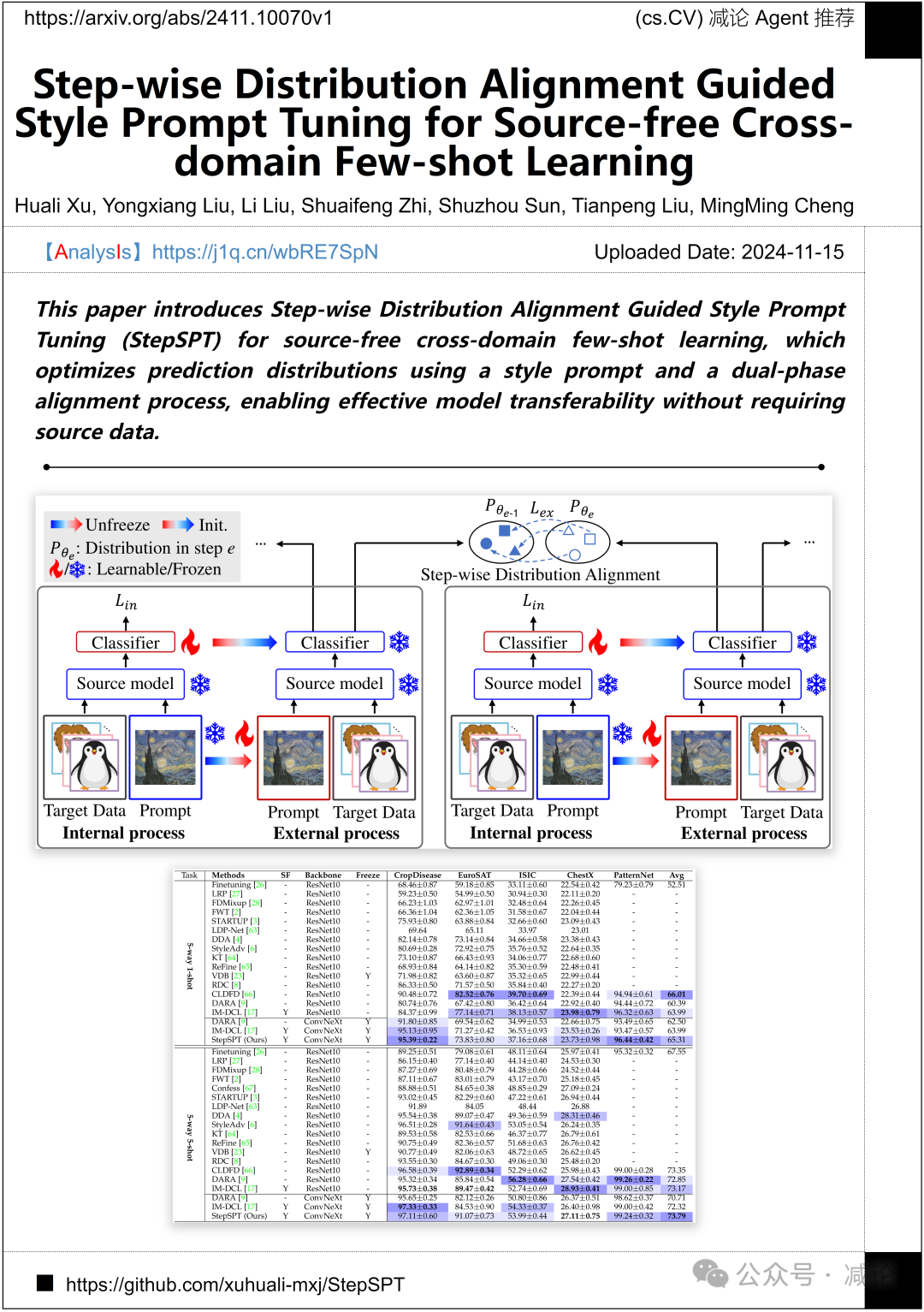
奥卢大学、国防科技大学和南开大学的研究团队提出了适用于无源跨领域少样本学习的逐步分布对齐引导风格提示调整(StepSPT)方法。通过使用风格提示和双阶段对齐过程优化预测分布,实现了有效的模型可迁移性,无需源数据。
【Bohr精读】
https://j1q.cn/wbRE7SpN
【arXiv链接】
http://arxiv.org/abs/2411.10070v1
【代码地址】
https://github.com/xuhuali-mxj/StepSPT

香港大学和兰州大学的研究团队提出了概念锚引导的任务特定特征增强(CATE)方法,通过动态校准图像特征,利用任务特定概念来增强病理基础模型,以提高特定下游任务和癌症类型的性能。
【Bohr精读】
https://j1q.cn/f3ZrjU3p
【arXiv链接】
http://arxiv.org/abs/2411.09894v1
【代码地址】
https://github.com/HKU-MedAI/CATE

重庆邮电大学与重庆师范大学的研究团队提出了一种新颖的多模态图像融合方法,结合了实例归一化和组归一化与大核卷积以及多路径自适应融合模块,以增强特征相关性和细节保留,在各种融合任务中实现了最先进的性能。
【Bohr精读】
https://j1q.cn/4AhZ4f98
【arXiv链接】
http://arxiv.org/abs/2411.10036v1
【代码地址】
https://github.com/HeDan-11/LKC-FUNet

中国科学院大学、北京交通大学、上海科技大学的研究团队提出了SEAGULL,一种新颖的网络,利用视觉–语言模型和基于掩模的特征提取器,专门用于感兴趣区域(ROIs)的细粒度图像质量评估,支持两个新构建的用于训练和评估的数据集。
【Bohr精读】
https://j1q.cn/MrrPGsfi
【arXiv链接】
http://arxiv.org/abs/2411.10161v1
【代码地址】
https://github.com/chencn2020/Seagull

欢迎关注减论,持续输出有深度的人工智能极减理解,提升信息获取效率和认知维度。看完点颗小星星再走呗~