
收录于话题
2024年11月15日arXiv cs.CV发文量约85余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省36分钟浏览arXiv的时间。
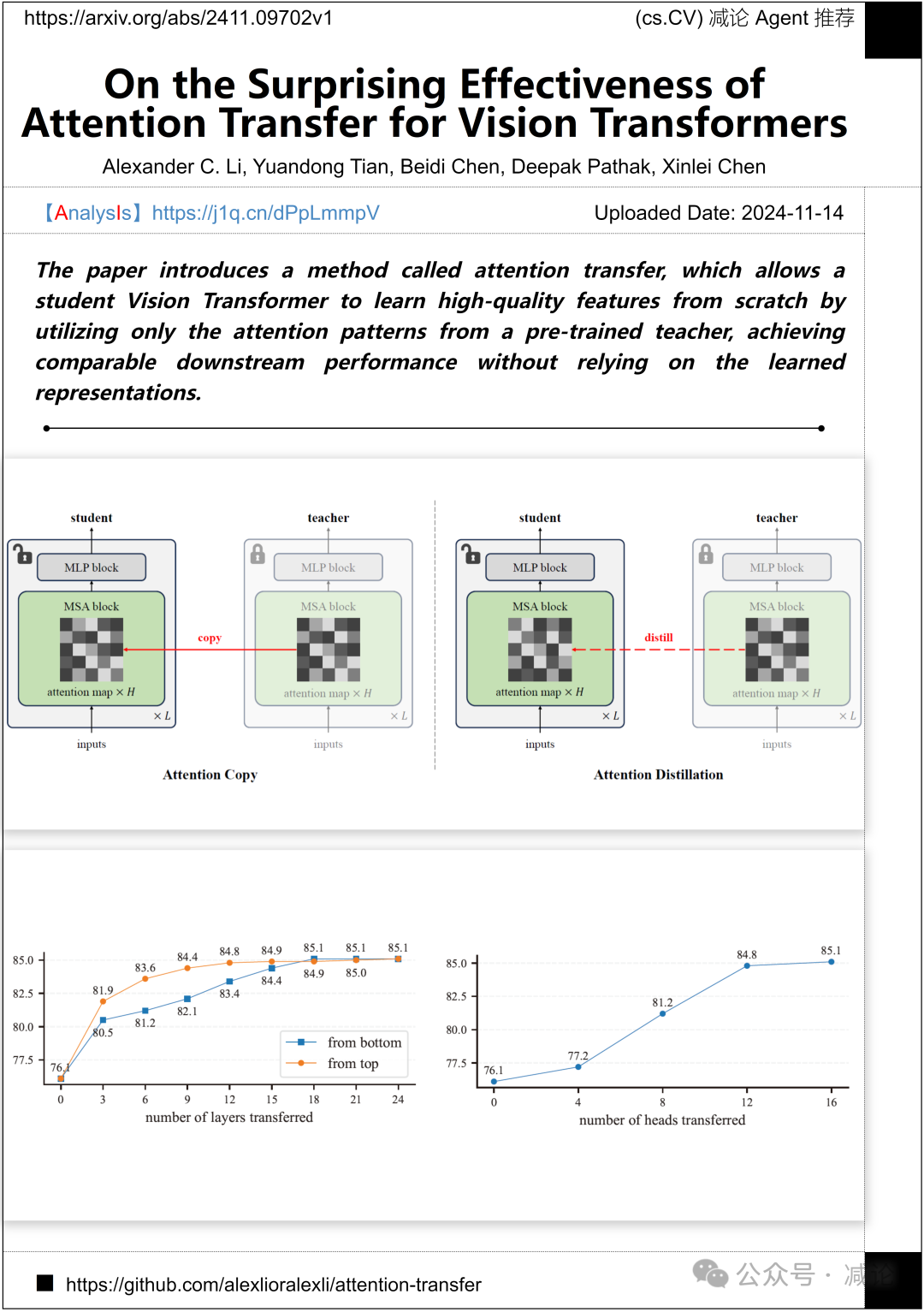

卡内基梅隆大学FAIR团队介绍了一种名为注意力迁移的方法,允许学生视觉转换器通过仅利用预训练教师的注意力模式,从零开始学习高质量特征,实现可比较的下游性能,而无需依赖学习到的表示。
【Bohr精读】
https://j1q.cn/dPpLmmpV
【arXiv链接】
http://arxiv.org/abs/2411.09702v1
【代码地址】
https://github.com/alexlioralexli/attention-transfer

北京邮电大学、加州大学和中国科学院的研究团队提出了一项关于多模态生成模型中越狱攻击和防御机制的研究。他们系统地探索了这些机制的生命周期,并提出了一套方法和评估框架的分类,以增强在现实世界应用中的安全性。
【Bohr精读】
https://j1q.cn/NuP1XG5z
【arXiv链接】
http://arxiv.org/abs/2411.09259v1
【代码地址】
https://github.com/liuxuannan/Awesome-Multimodal-Jailbreak

布拉格捷克理工大学的研究团队提出了MFTIQ模型,这是一种密集的长期跟踪模型,通过集成独立质量模块来增强Multi-Flow Tracker框架。该模型能够提高跟踪精度和灵活性,在遮挡和复杂动态期间实现可靠的轨迹预测,并且与任何光流方法兼容,无需微调。
【Bohr精读】
https://j1q.cn/S1XxX4KP
【arXiv链接】
http://arxiv.org/abs/2411.09551v1
【代码地址】
https://github.com/serycjon/MFTIQ
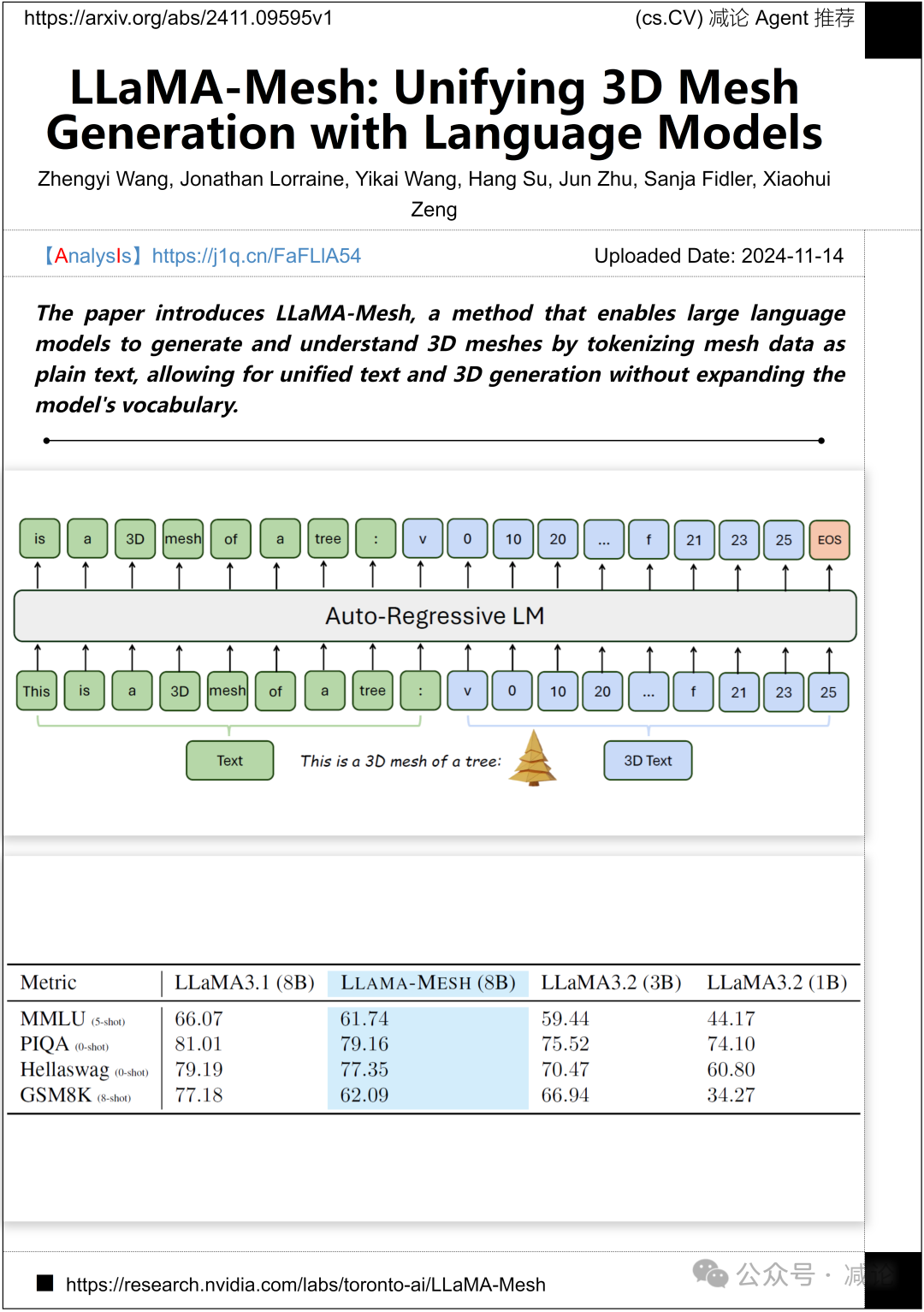
清华大学和NVIDIA的研究团队推出了LLaMA-Mesh方法,通过将网格数据标记为纯文本,使大型语言模型能够生成和理解3D网格,实现统一的文本和3D生成,而无需扩展模型的词汇表。
【Bohr精读】
https://j1q.cn/FaFLlA54
【arXiv链接】
http://arxiv.org/abs/2411.09595v1
【代码地址】
https://research.nvidia.com/labs/toronto-ai/LLaMA-Mesh
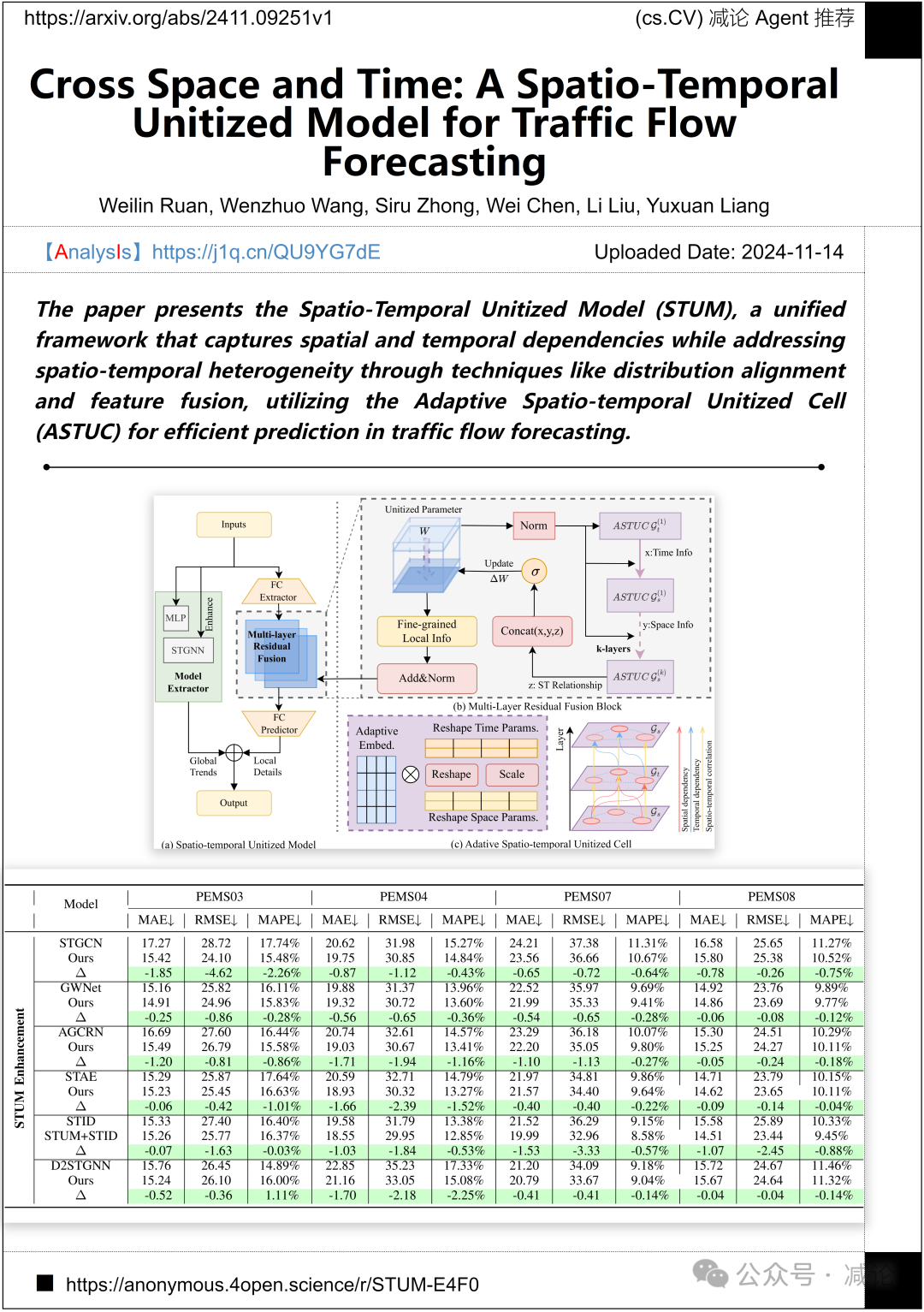
香港科技大学、暨南大学和重庆大学的研究团队提出了时空单元化模型(STUM)。这一统一框架利用分布对齐和特征融合等技术,捕捉空间和时间依赖关系,同时通过自适应时空单元化单元(ASTUC)实现了高效的交通流量预测。
【Bohr精读】
https://j1q.cn/QU9YG7dE
【arXiv链接】
http://arxiv.org/abs/2411.09251v1
【代码地址】
https://anonymous.4open.science/r/STUM-E4F0

香港城市大學和悉尼大學的研究人員提出了Trident,一个无需训练的框架,通过从CLIP和DINO中剪切特征,然后使用Segment-Anything Model(SAM)进行全局聚合和细化分割输出,从而增强语义分割。
【Bohr精读】
https://j1q.cn/q4WJagbm
【arXiv链接】
http://arxiv.org/abs/2411.09219v1
【代码地址】
https://github.com/YuHengsss/Trident

首尔大学的研究团队提出了可重复使用的运动先验(ReMP)方法。该方法利用时间注意力来准确跟踪和估计人体姿势,从而在各种传感器模式下从不完整或嘈杂的输入中显著增强3D运动数据恢复的训练效率。
【Bohr精读】
https://j1q.cn/dNXmgvOE
【arXiv链接】
http://arxiv.org/abs/2411.09435v1
【代码地址】
https://hojunjang17.github.io/ReMP
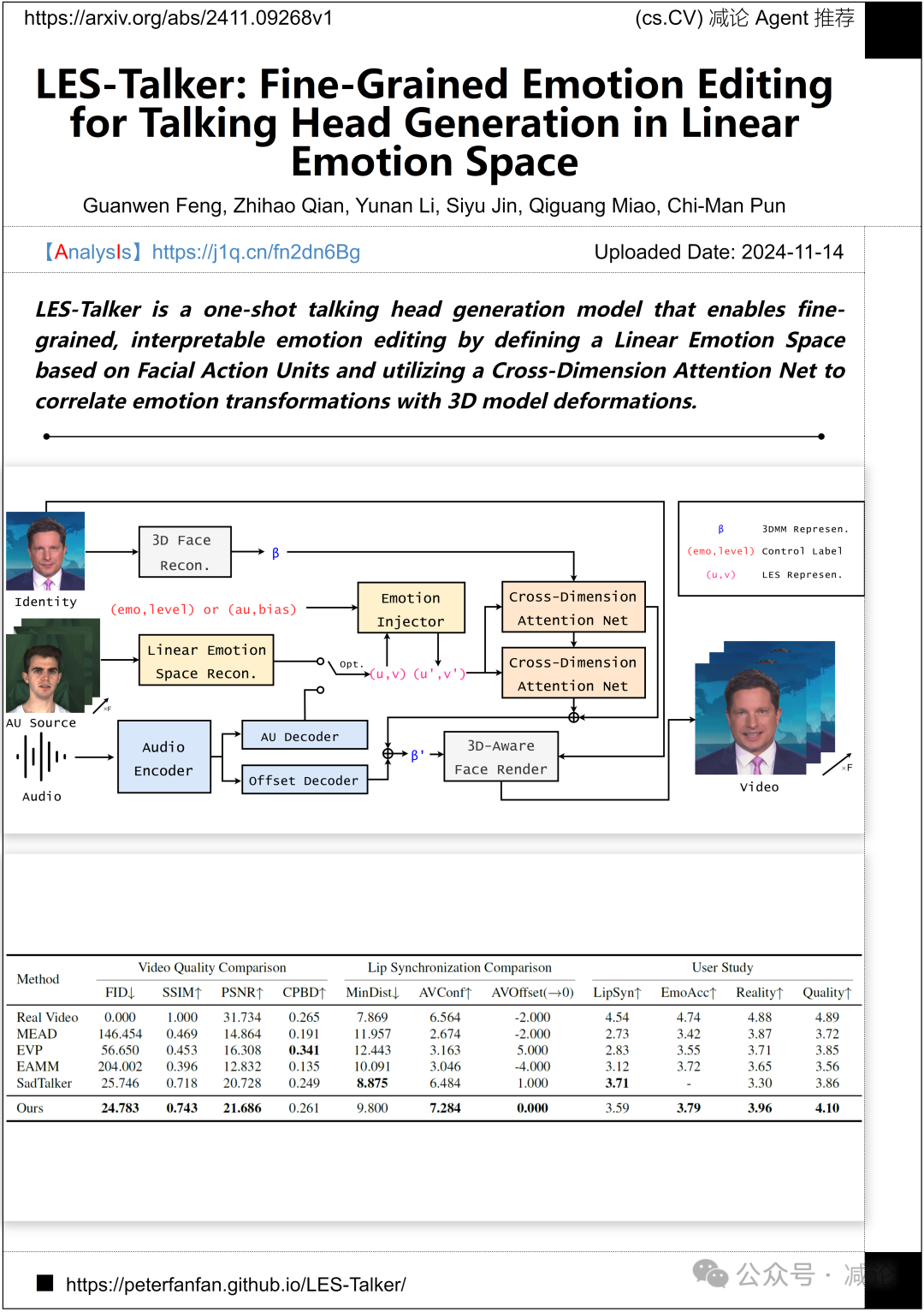
西安电子科技大学和澳门大学的研究团队提出了LES-Talker方法,这是一个一次性的说话头生成模型。该方法通过基于面部动作单元定义线性情感空间,并利用交叉维度注意力网络将情感转换与3D模型变形相关联,实现精细化、可解释的情感编辑。
【Bohr精读】
https://j1q.cn/fn2dn6Bg
【arXiv链接】
http://arxiv.org/abs/2411.09268v1
【代码地址】
https://peterfanfan.github.io/LES-Talker/

香港科技大學、螞蟻集團、香港大學的研究团队提出了MagicQuill这一集成的图像编辑系统,利用多模态大型语言模型实时预测用户的编辑意图,通过简化的界面和强大的扩散先验,实现对图像的高效精确操作。
【Bohr精读】
https://j1q.cn/gY9kzW3I
【arXiv链接】
http://arxiv.org/abs/2411.09703v1
【代码地址】
https://magic-quill.github.io
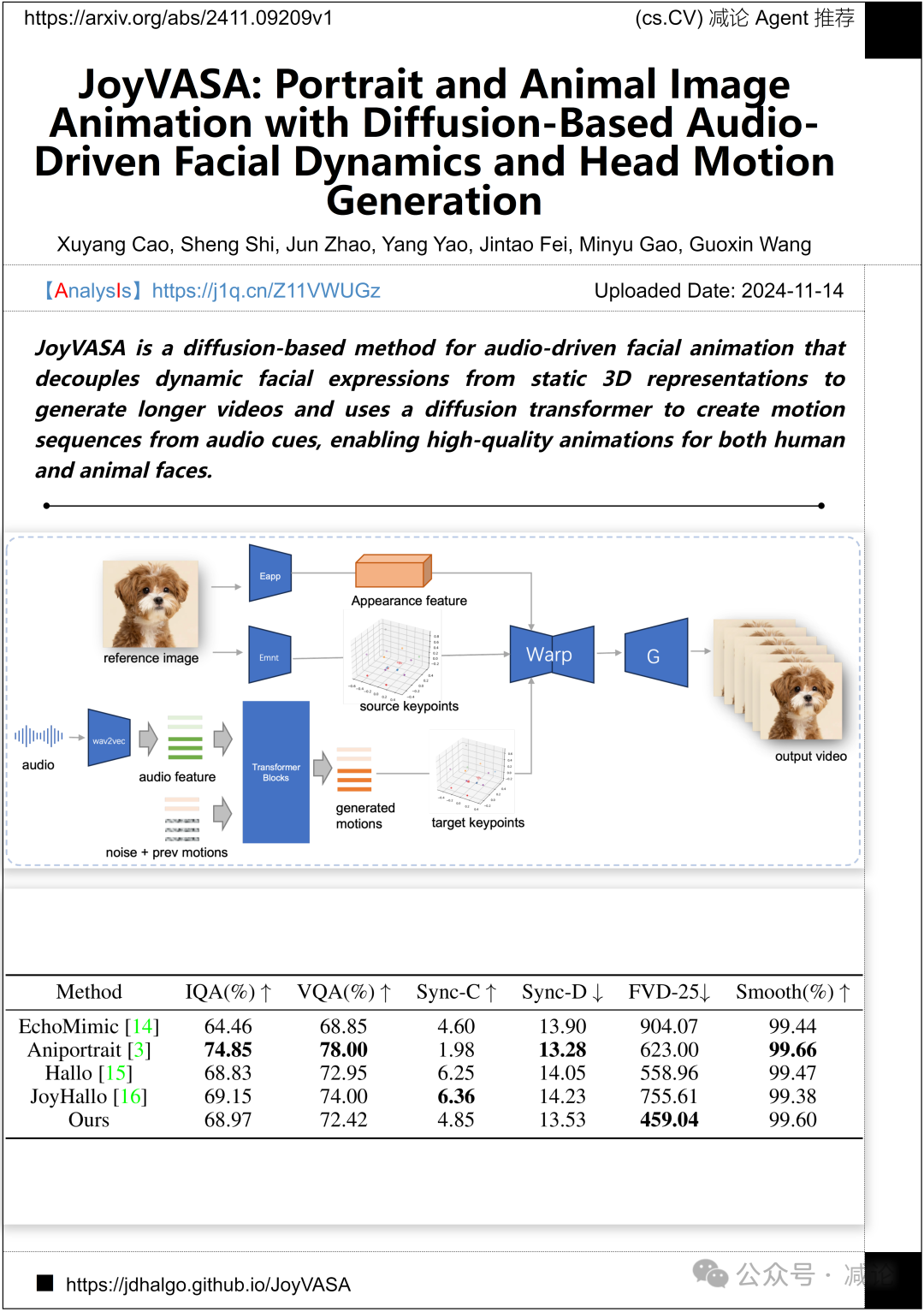
浙江大学和京东健康国际有限公司的研究团队提出了JoyVASA方法。这种基于扩散的音频驱动面部动画方法将动态面部表情与静态的3D表示分离,从而生成更长的视频。利用扩散transformer从音频线索中创建运动序列,JoyVASA实现了人类和动物面部的高质量动画。
【Bohr精读】
https://j1q.cn/Z11VWUGz
【arXiv链接】
http://arxiv.org/abs/2411.09209v1
【代码地址】
https://jdhalgo.github.io/JoyVASA
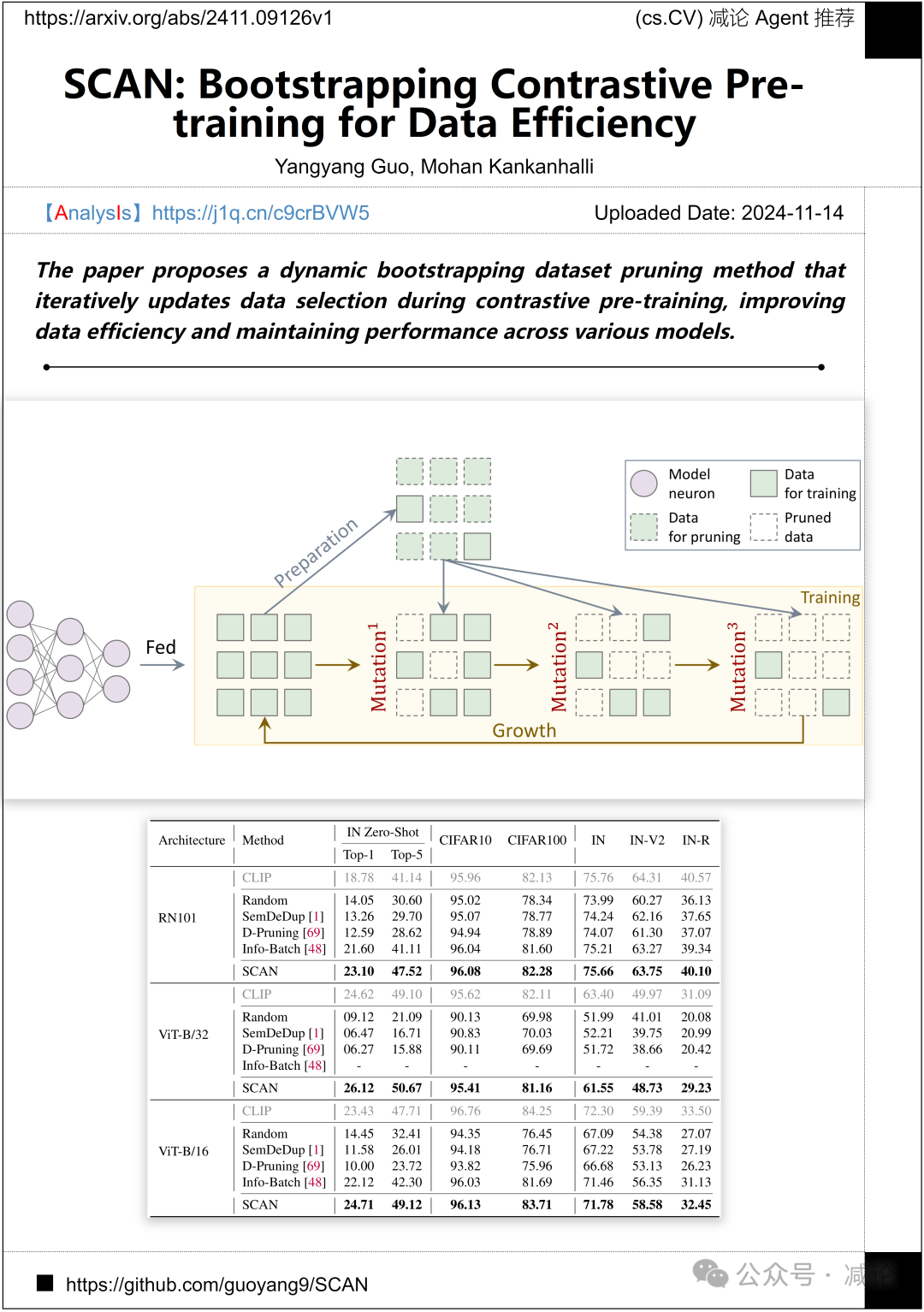
新加坡国立大学的研究团队提出了一种动态引导式数据集修剪方法,该方法通过迭代更新数据选择,提高数据效率并在各种模型中保持性能。
【Bohr精读】
https://j1q.cn/c9crBVW5
【arXiv链接】
http://arxiv.org/abs/2411.09126v1
【代码地址】
https://github.com/guoyang9/SCAN

北京航空航天大学和利物浦大学的研究团队提出了BEARD,一个统一的基准,通过各种对抗攻击和度量标准系统评估数据集精炼方法的对抗鲁棒性。
【Bohr精读】
https://j1q.cn/eTDLMjp1
【arXiv链接】
http://arxiv.org/abs/2411.09265v1
【代码地址】
https://github.com/zhouzhengqd/BEARD

南京大学,国家空地一体化信息技术重点实验室,慕尼黑工业大学的研究团队推出了LHRS-Bot-Nova,一个多模态大型语言模型,旨在理解遥感图像。该模型具有增强的视觉编码器和用于改善语言–视觉对齐的新型桥接层,支持大规模RS图像字幕数据集和指令数据集,以增强空间识别。
【Bohr精读】
https://j1q.cn/NoUY26FS
【arXiv链接】
http://arxiv.org/abs/2411.09301v1
【代码地址】
https://github.com/NJU-LHRS/LHRS-Bot

欢迎关注减论,持续输出有深度的人工智能极减理解,提升信息获取效率和认知维度。看完点颗小星星再走呗~