
收录于话题
2024年11月14日arXiv cs.CV发文量约68余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省28分钟浏览arXiv的时间。
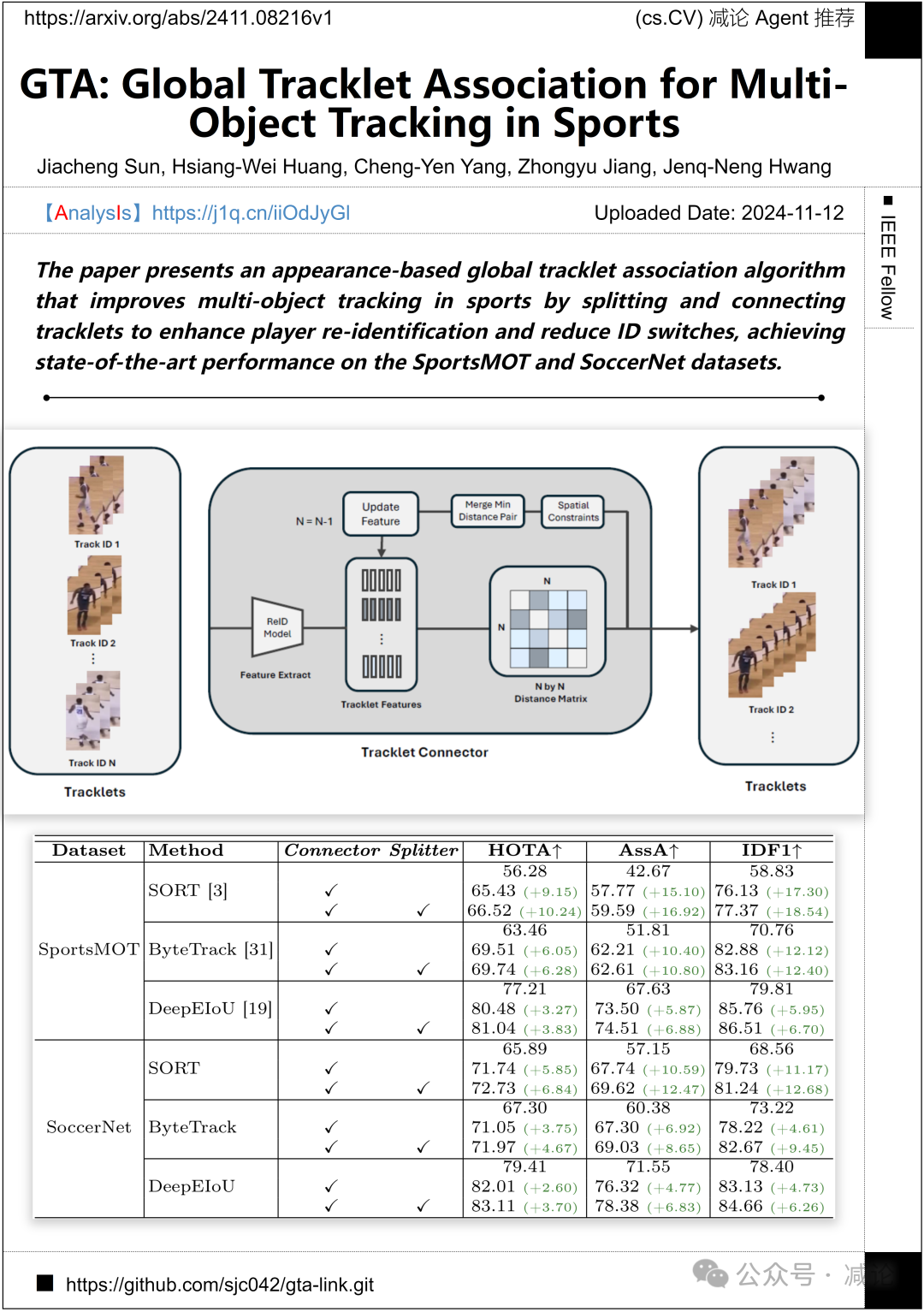

华盛顿大学提出了一种基于外观的全局轨迹关联算法,通过分割和连接轨迹来增强球员再识别并减少ID切换,从而改善体育中的多目标跟踪。该论文在SportsMOT和SoccerNet数据集上实现了最先进的性能。
【Bohr精读】
https://j1q.cn/iiOdJyGl
【arXiv链接】
http://arxiv.org/abs/2411.08216v1
【代码地址】
https://github.com/sjc042/gta-link.git

密歇根大学的研究团队提出了使用扩散Transformer的Encode-Identify-Manipulate(EIM)框架,用于零样本细粒度图像编辑的方法。该方法利用语义上解耦的联合潜在空间来识别和操纵特定的编辑方向,这些方向由文本提示引导。
【Bohr精读】
https://j1q.cn/PkXyasa6
【arXiv链接】
http://arxiv.org/abs/2411.08196v1
【代码地址】
https://anonymous.com/anonymous/EIM-Benchmark

厦门大学、上海交通大学和武汉大学的研究团队提出了一项新的研究成果。他们介绍了V2X-R,一个结合激光雷达、摄像头和4D雷达数据的模拟数据集,并提出了一个合作式激光雷达-4D雷达融合管道,其中包含一个多模态去噪扩散模块,以提高在恶劣天气条件下的3D物体检测性能。
【Bohr精读】
https://j1q.cn/sbdg1XlJ
【arXiv链接】
http://arxiv.org/abs/2411.08402v1
【代码地址】
https://github.com/ylwhxht/V2X-R

武汉大学、国防科技大学和挪威科技大学的研究团队提出了OSMLoc,这是一种受大脑启发的单图像视觉定位方法,通过将几何和语义引导集成到匹配图像与OpenStreetMap数据中,提高了准确性和鲁棒性。
【Bohr精读】
https://j1q.cn/GhmX3Ng8
【arXiv链接】
http://arxiv.org/abs/2411.08665v1
【代码地址】
https://github.com/WHU-USI3DV/OSMLoc
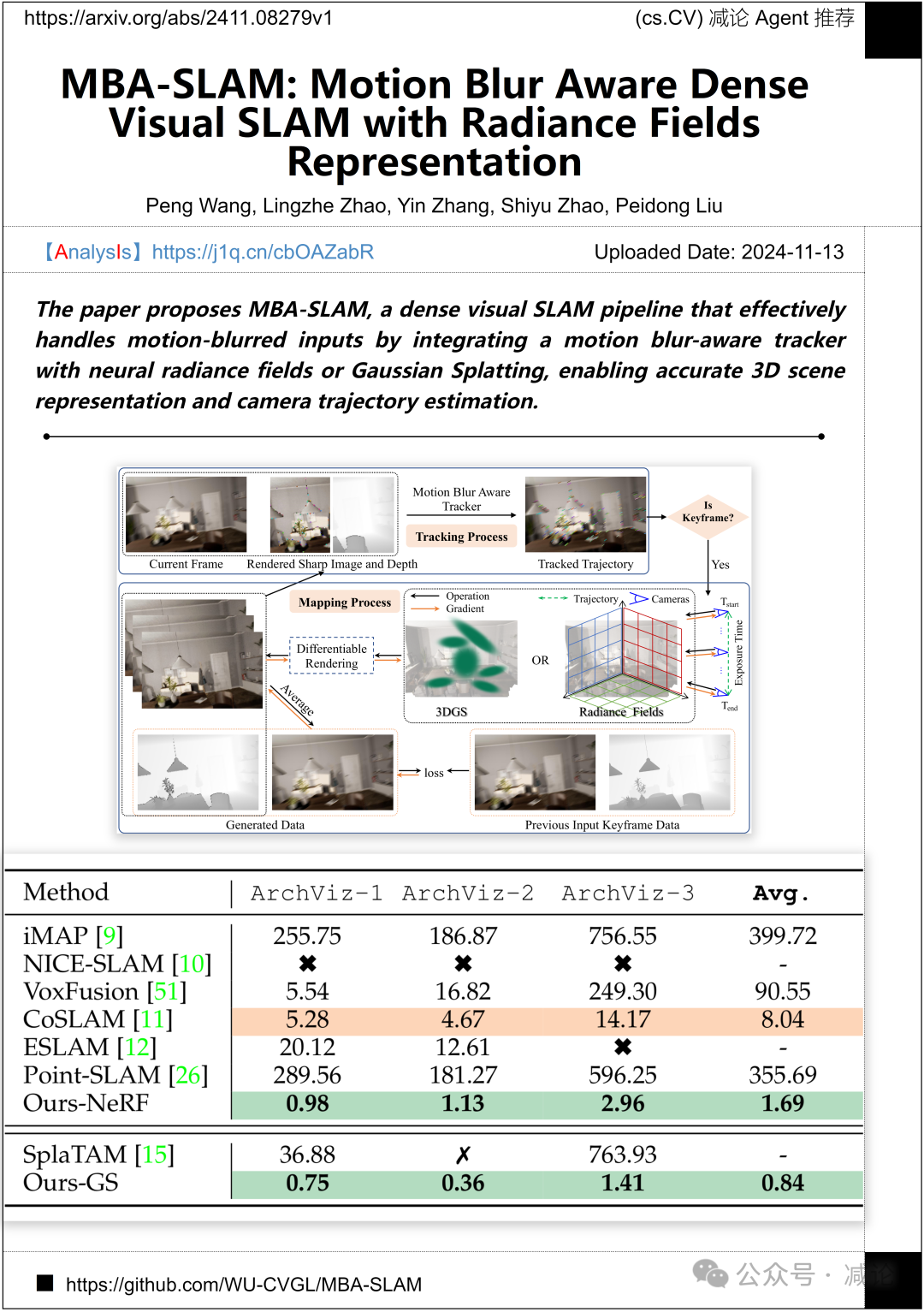
浙江大学和西湖大学的研究团队提出了MBA-SLAM,这是一个密集视觉SLAM流水线,通过将运动模糊感知跟踪器与神经辐射场或高斯喷洒相结合,有效处理运动模糊输入,实现准确的3D场景表示和相机轨迹估计。
【Bohr精读】
https://j1q.cn/cbOAZabR
【arXiv链接】
http://arxiv.org/abs/2411.08279v1
【代码地址】
https://github.com/WU-CVGL/MBA-SLAM
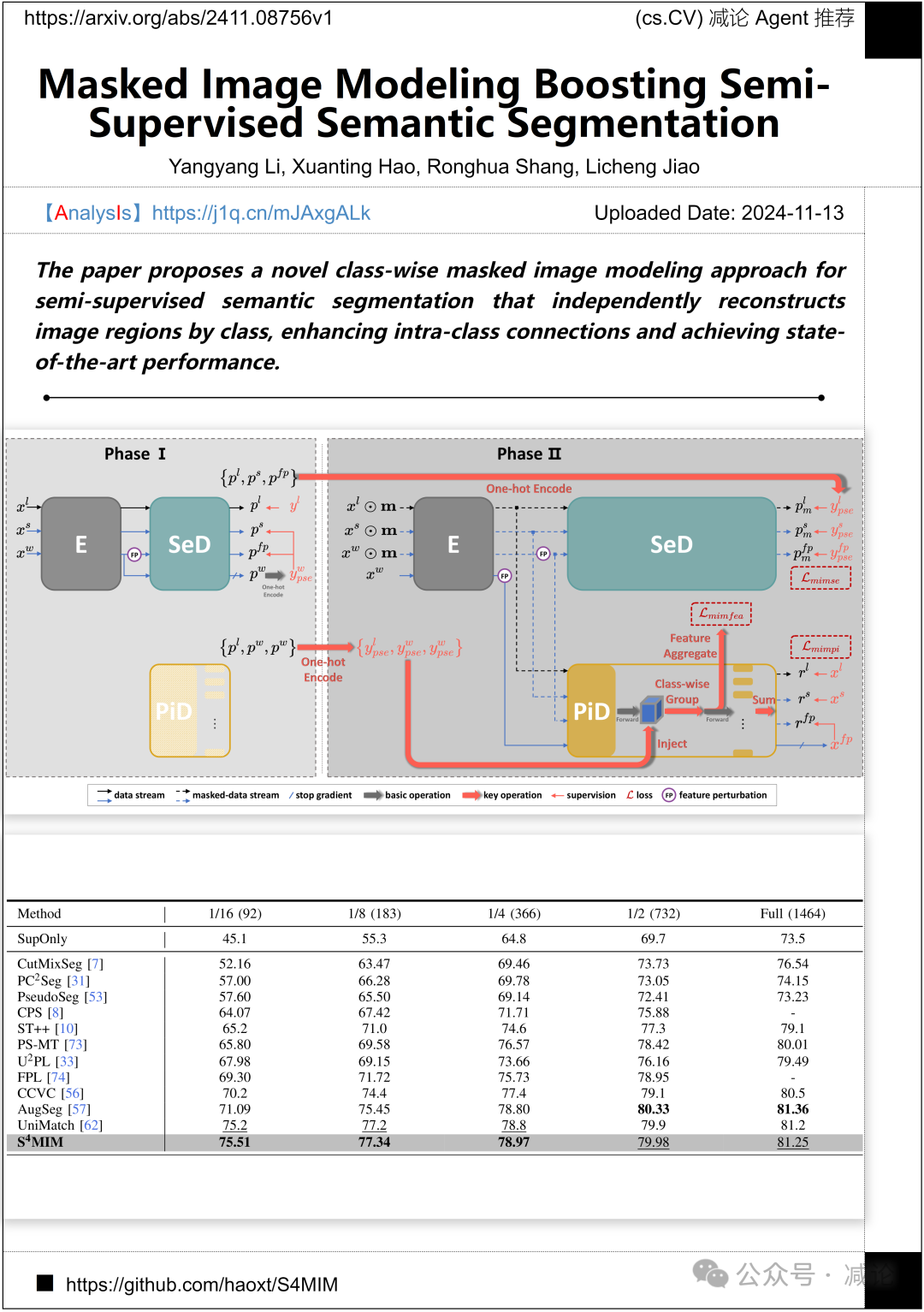
西安电子科技大学的研究团队提出了一种新颖的按类别掩码图像建模方法,用于半监督语义分割。通过按类别独立重建图像区域,增强类内连接,实现了最先进的性能。
【Bohr精读】
https://j1q.cn/mJAxgALk
【arXiv链接】
http://arxiv.org/abs/2411.08756v1
【代码地址】
https://github.com/haoxt/S4MIM
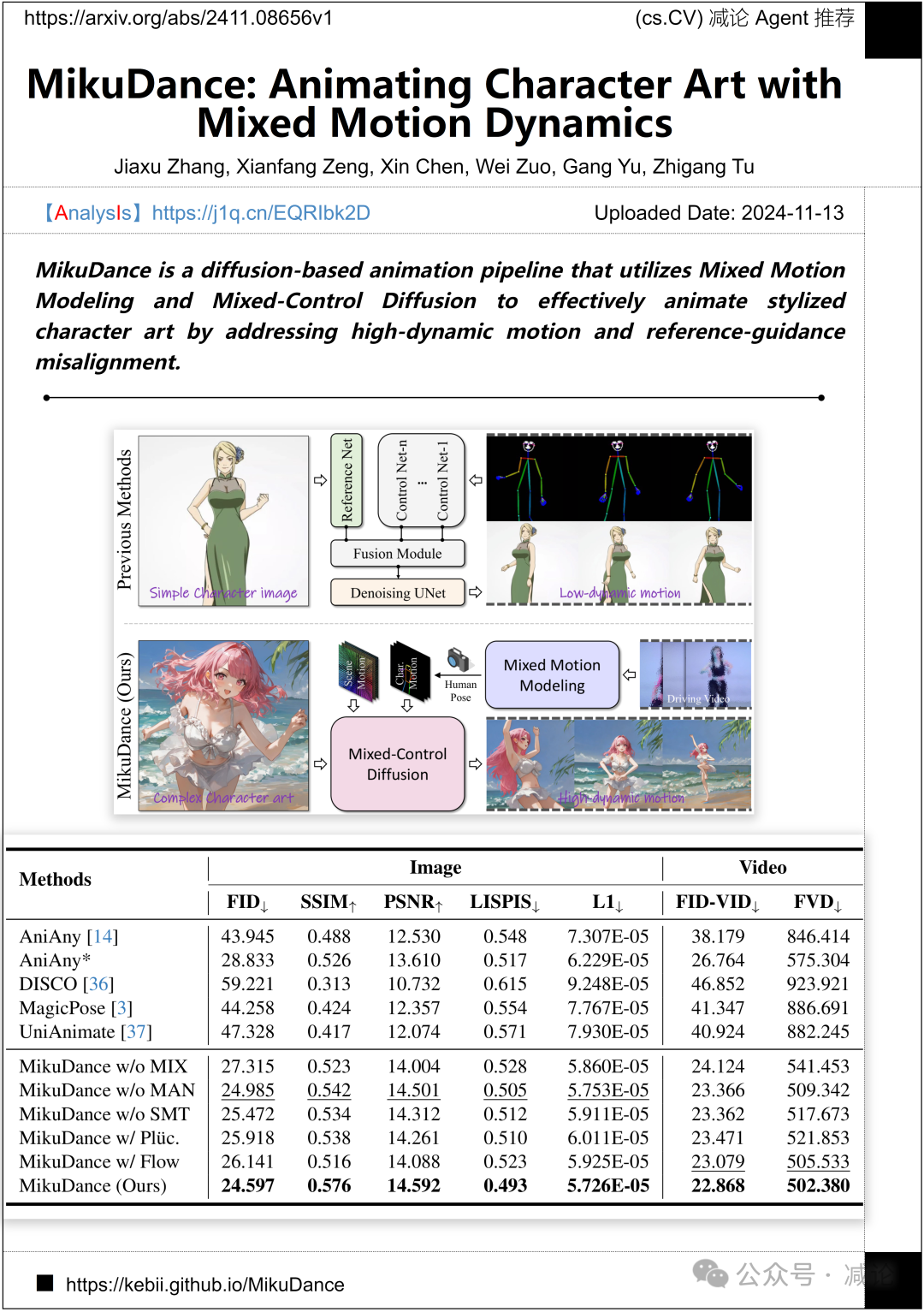
武汉大学StepFun团队提出了MikuDance是一种基于扩散的动画流水线,利用混合动作建模和混合控制扩散来有效地为风格化角色艺术进行动画处理,解决高动态运动和参考引导不对齐的问题的论文。
【Bohr精读】
https://j1q.cn/EQRIbk2D
【arXiv链接】
http://arxiv.org/abs/2411.08656v1
【代码地址】
https://kebii.github.io/MikuDance

上海交通大学和复旦大学的研究团队提出了MVideo,这是一个新颖的框架,通过使用掩码序列作为额外的运动条件输入,增强了文本到视频生成。这一方法可以创建具有精确和流畅动作的长时间视频,同时实现文本提示和运动条件的独立编辑。
【Bohr精读】
https://j1q.cn/5OpNEtXD
【arXiv链接】
http://arxiv.org/abs/2411.08328v1
【代码地址】
https://mvideo-v1.github.io/

国立台湾大学的Trap-MID团队介绍了基于陷阱的模型逆向防御(Trap-MID)方法,该方法通过在深度学习模型中集成陷阱来引导模型逆向攻击,从而误导攻击者提取陷阱触发器而不是私有训练数据。
【Bohr精读】
https://j1q.cn/MWa8KBp0
【arXiv链接】
http://arxiv.org/abs/2411.08460v1
【代码地址】
https://github.com/ntuaislab/Trap-MID
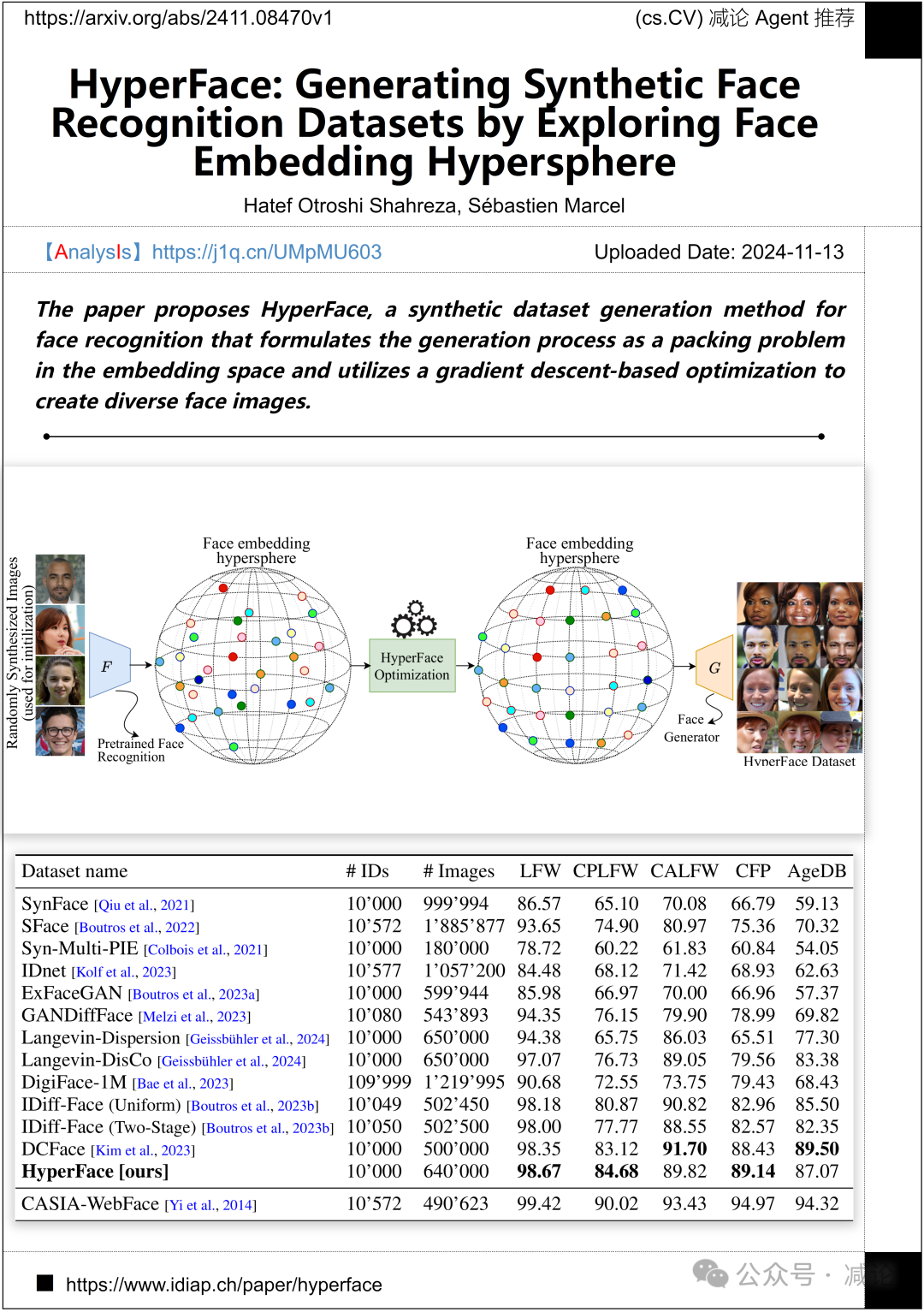
瑞士伊迪亚普研究所,洛桑联邦理工学院,洛桑大学的研究团队提出了HyperFace,一种用于人脸识别的合成数据集生成方法。他们将生成过程构建为嵌入空间中的一种装箱问题,并利用基于梯度下降的优化方法来创建多样化的人脸图像。
【Bohr精读】
https://j1q.cn/UMpMU603
【arXiv链接】
http://arxiv.org/abs/2411.08470v1
【代码地址】
https://www.idiap.ch/paper/hyperface

阿里巴巴、中国科学院大学和清华大学的研究团队提出了EgoVid-5M数据集和EgoDreamer方法。 EgoVid-5M包含500万个高质量自我中心视频剪辑,具有详细的动作注释。 EgoDreamer是一种利用动作描述和运动控制信号生成自我中心视频的方法。
【Bohr精读】
https://j1q.cn/xBNzb4ef
【arXiv链接】
http://arxiv.org/abs/2411.08380v1
【代码地址】
https://egovid.github.io

南加州大学、苏黎世联邦理工学院和德克萨斯农工大学的研究人员提出了动态原型更新(DPU)框架,用于多模态的超出分布检测。该框架动态调整类中心表示,以考虑类内变异性,显著提高检测性能。
【Bohr精读】
https://j1q.cn/thJLmdM9
【arXiv链接】
http://arxiv.org/abs/2411.08227v1
【代码地址】
https://github.com/lili0415/DPU-OOD-Detection

欢迎关注减论,持续输出有深度的人工智能极减理解,提升信息获取效率和认知维度。看完点颗小星星再走呗~