
前言,熟悉英伟达GPU的朋友肯定都知道,在主流GPU型号A100、H100的参数里对FP16性能的描述有两个值,一个是稠密算力,另一个是稀疏算力,并且稀疏算力的值是稠密的2倍,“稀疏”后为什么能够实现性能提升?今天我们简单聊聊英伟达GPU的“稀疏矩阵”技术。


一、英伟达推出“稀疏矩阵”技术的背景
目前AI大模型的数据体量非常庞大,且指数级增长,从十亿、百亿、到千亿级别的参数规模。英伟达稀疏矩阵的核心逻辑是:精准预测与推论不需要用到所有参数,而有些参数可以转换为零,以确保模型变「稀疏」的同时不会牺牲准确性。Tensor 核心最高可以将稀疏模型的效能提高 2 倍。将模型稀疏化对于人工智能推论有益,同时也能改善模型训练效能(参考自英伟达的官网描述)。
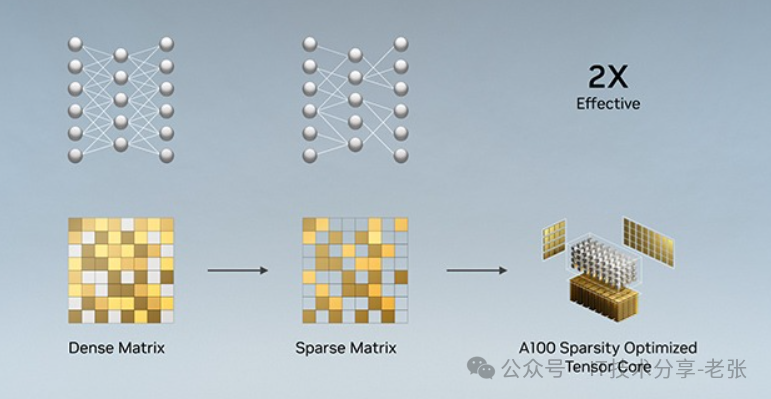
二、“稀疏矩阵”实现性能提升的逻辑
自 Ampere 架构开始, 随着 A100 Tensor Core GPU 的推出,增加了新的细粒度结构化稀疏功能,该功能主要用于加速推理。此功能是由稀疏 Tensor Core 提供,这些稀疏 Tensor Core 需要 2:4 的稀疏模式。也就是说,以 4 个相邻权重为一组,其中至少有 2 个权重必须为 0,即 50% 的稀疏率。稀疏模式下可实现高效的内存访问能力,有效的模型推理加速,并可轻松恢复模型精度。
在模型压缩后,存储格式只存储非零值和相应的索引元数据(如下图)。稀疏 Tensor Core 在执行矩阵乘法时仅处理非零值,理论上,计算吞吐量是同等稠密矩阵乘法的 2 倍。
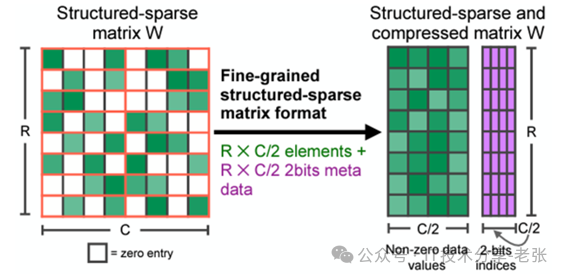
注:结构化稀疏功能主要应用于能够提供 2:4 稀疏权重的全连接层和卷积层。如果提前对这些层的权重做剪枝,则这些层可以使用结构化稀疏功能来进行加速。
在训练方面,有渐进式稀疏训练方法,腾讯机器学习平台部门 (MLPD) 利用了渐进式训练方法,简化了稀疏模型训练并实现了更高的模型精度。借助稀疏功能和量化技术,他们在腾讯的离线服务中实现了 1.3 倍~1.8 倍的加速(本段内容来自网络,供参考)。
三、为何很多客户依然参考GPU“稠密”算力
个人认为主要因素有三个,1是稀疏矩阵技术主要是面向推理的,在训练上带来的提升有限。2是增加操作复杂度,需要对特定层做裁剪。3是现阶段“稀疏矩阵”技术在训练和推理侧真正的应用还并不普遍。因此很多客户在进行智算中心规划时,明确提出按照GPU“稠密”性能的数值进行设备采购。
—-老张会持续通过公众号分享前沿IT技术,创作不易,大家多多点赞和关注!