
收录于话题

利用多模态大型语言模型(MLLMs)来实现通用多模态检索:
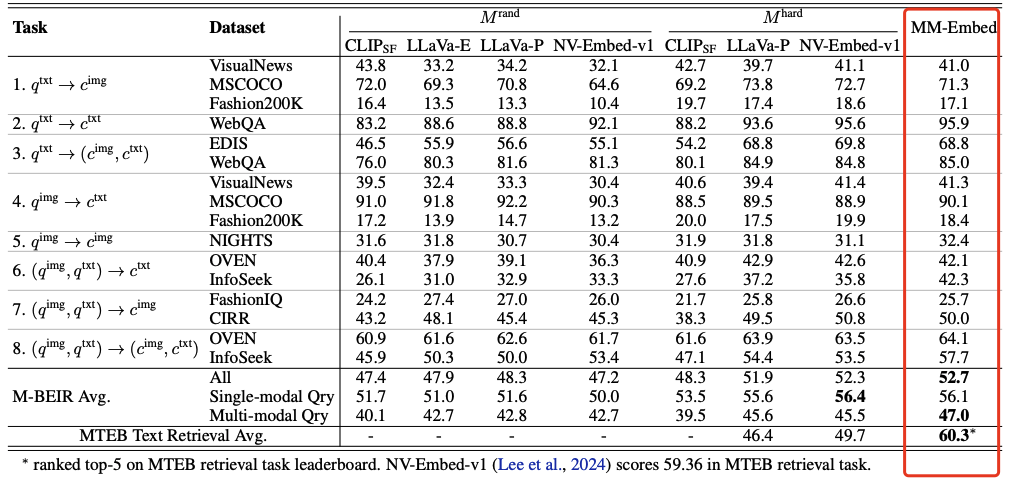
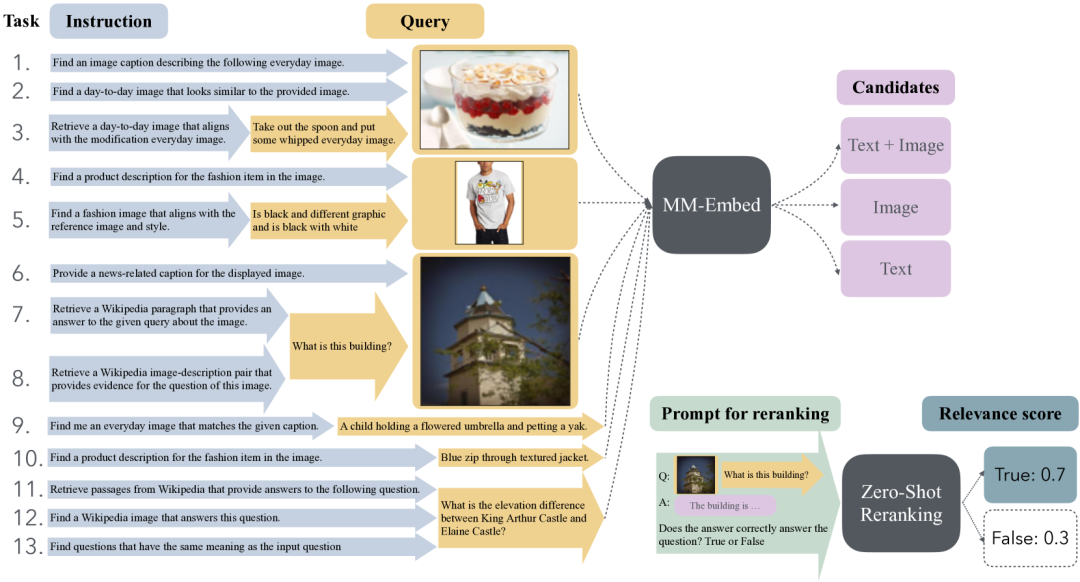
通用多模态检索的说明,支持包含指令、查询和多模态格式文档的多样化任务。在这项工作中,探索微调基于MLLM(多语言大型模型)的通用多模态检索器MM-Embed,并提示MLLM进行重新排序。
-
目标:将用户查询和任务指令映射到与多模态文档相同的语义空间,以便进行k-最近邻搜索。
-
微调过程:使用特定任务的指令作为指导,微调MLLM-based检索器,以捕捉检索任务背后的隐含意图。给定用户查询、相关和负样本文档,通过最小化InfoNCE损失来微调模型。
1. 模态感知硬负样本挖掘
-
问题:在多模态检索中,需要考虑用户指定的任务指令中期望的模态(文本、图像或交织的文本-图像)。
-
解决方案:模态感知硬负样本挖掘方法,以指导模型检索符合用户信息需求和偏好模态的候选文档。

2. 持续的文本到文本检索微调
-
目的:由于文本到文本检索仍然是最常用的检索任务之一,进一步微调模型以增强其文本检索能力。
-
过程:在多个公共文本到文本检索任务上继续微调模型,包括MS MARCO、HotpotQA、Natural Question等。
3. 使用MLLMs进行重排
-
目标:使用MLLMs对通用多模态检索器检索到的前k个候选文档进行重排。
-
方法:将重排任务构建为一系列真假问题,使用Softmax操作计算相关性得分,以用于重排。
组合图像检索和重排任务的Top-1候选结果。在许多情况下,检索和重排产生的Top-1结果与标记的正样本不同,但似乎是正确的,因为每个查询只有一个标记的正样本候选。

https://arxiv.org/pdf/2411.02571v1MM-EMBED: UNIVERSAL MULTIMODAL RETRIEVAL WITH MULTIMODAL LLMShttps://huggingface.co/nvidia/MM-Embed.
推荐阅读
欢迎关注我的公众号“PaperAgent”,每天一篇大模型(LLM)文章来锻炼我们的思维,简单的例子,不简单的方法,提升自己。