提示词:卓别林把草撒向空中 (新清影生成)
1985年巴黎一家咖啡馆的地下室,卢米埃尔兄弟第一次向观众展示了他们的“电影”。
1910年,托马斯·爱迪生将发明的有声电视展现在新泽西州的朋友们面前。
提示词:卓别林把草撒向空中 (新清影生成)
1985年巴黎一家咖啡馆的地下室,卢米埃尔兄弟第一次向观众展示了他们的“电影”。
1910年,托马斯·爱迪生将发明的有声电视展现在新泽西州的朋友们面前。
从默片到有声,电影经历了15年;而对于AI视频,可能只需要15个月。
就在今天,智谱全新迭代的AI视频模型“新清影”,正式上线。
10s长度、4k分辨、60帧、任意尺寸……影、音的结合似乎又将碰撞出新的火花。
第一时间测试了一下,发现在画面质量上,新清影模型擅长生成“环境描述类镜头”,对自然语言的理解有明显的提升;音效则是第一次直观让人觉得视频有了灵魂。
目前智谱清言视频模型已经上线,人人可用。音效模型这个月也即将上线。
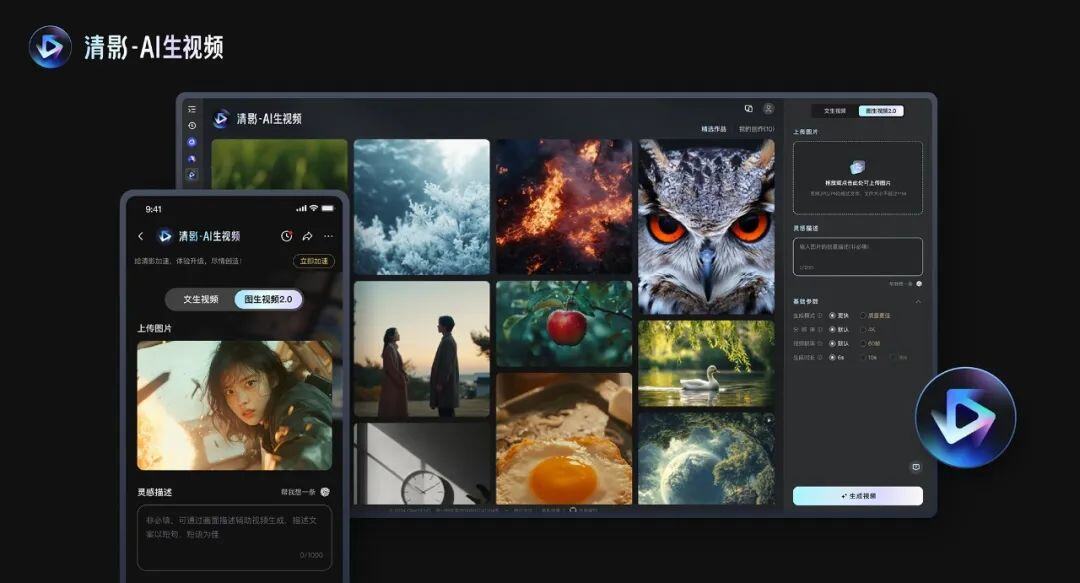
三个月前,清影推出了国内首款面向公众的AI视频生成应用——清言App,只需一段指令或图片,30秒内即可生成AI视频,清影为广告、短视频、表情包等创作带来了新的可能。
在当时,清影是国内最早全量上线 C 端、人人可用的生成视频功能。
此后,GLM团队开源了CogVideoX系列模型,包括在消费级显卡上流畅运行的CogVideoX-5B,并催生了多个二次开发项目。
再到智谱“新清影”,即将上线公测的音效模型 CogSound 尤其让我好奇,也很开心得到了内测资格。
木柴在篝火里发出噼里啪啦的声音,随着火苗的跳动而随之响起。
火车轰鸣,发出轰隆隆的声响,只听见一声汽笛声,火车驶来了。
我尤其喜欢这个趴在汉堡上睡觉的小老虎,打呼噜的声音非常有气势。
大概两周前,智谱刚刚发布最新的 GLM-4-Voice 情感语音模型。
很快,随着音效模型的加入,GLM 大模型在声音模态领域即将实现人声、音效、音乐的多链路呈现。
基于图像、视频和声音的多模态模型矩阵由此更加完整,对创作者来说也将拓展很多应用。
 提示词:飞车溅起泥巴
基于 CogVideoX 模型的技术进展,新清影在以下 4 个方面有所提升。
提示词:飞车溅起泥巴
基于 CogVideoX 模型的技术进展,新清影在以下 4 个方面有所提升。
-
模型能力提升:在图生视频的质量、美学表现、运动合理性以及复杂提示词语义理解方面能力显著增强。
-
4K 超高清分辨率:支持生成 10s、4K、60 帧超高清视频。
-
可变比例:支持任意比例,从而适应不同的播放需求。
-
多通道生成能力:同一指令/图片可以一次性生成 4 个视频。
 提示词:戴眼镜的外国老头微笑。
一次性生成4个视频,真的很节省时间,能够让我不用逐一等待,可以集中写好提示词再统一等待。
灵活调节尺寸,也是一个谁用谁知道好的、很贴心产品功能。
提示词:戴眼镜的外国老头微笑。
一次性生成4个视频,真的很节省时间,能够让我不用逐一等待,可以集中写好提示词再统一等待。
灵活调节尺寸,也是一个谁用谁知道好的、很贴心产品功能。
电影级的画质、人物的细腻皱纹、色彩的丰富艳丽、复杂提示词的理解到位,这些新清影能做到,其实我不算意外。
对物理世界的理解一直是视频生成的难题,从Sora开始也引发了一轮又一轮的研究和应用。
新清影的世界观里,物理世界从宏观到微观,从变化到运动,都有很贴近真实的呈现。
 提示词:一朵盛开的粉红色牡丹花,一只毛茸茸的蜜蜂从远处飞来停在花朵中心。蜜蜂的翅膀微微颤动,采集花蜜。
比如蜜蜂翅膀的震颤、汽车驶过溅起的水花、凯旋门前的车流和行人。这些运动状态的捕捉和还原,底层还是对物理规律的把握。
有些公司擅长通过“整花活”的方式来促进传播,而智谱的产品则是常给我一种“扎实”的感觉。
像是成绩最均衡、基础打最牢的优等生,每个模型都做得不错,每种视频成片类型都可圈可点。
提示词:一朵盛开的粉红色牡丹花,一只毛茸茸的蜜蜂从远处飞来停在花朵中心。蜜蜂的翅膀微微颤动,采集花蜜。
比如蜜蜂翅膀的震颤、汽车驶过溅起的水花、凯旋门前的车流和行人。这些运动状态的捕捉和还原,底层还是对物理规律的把握。
有些公司擅长通过“整花活”的方式来促进传播,而智谱的产品则是常给我一种“扎实”的感觉。
像是成绩最均衡、基础打最牢的优等生,每个模型都做得不错,每种视频成片类型都可圈可点。
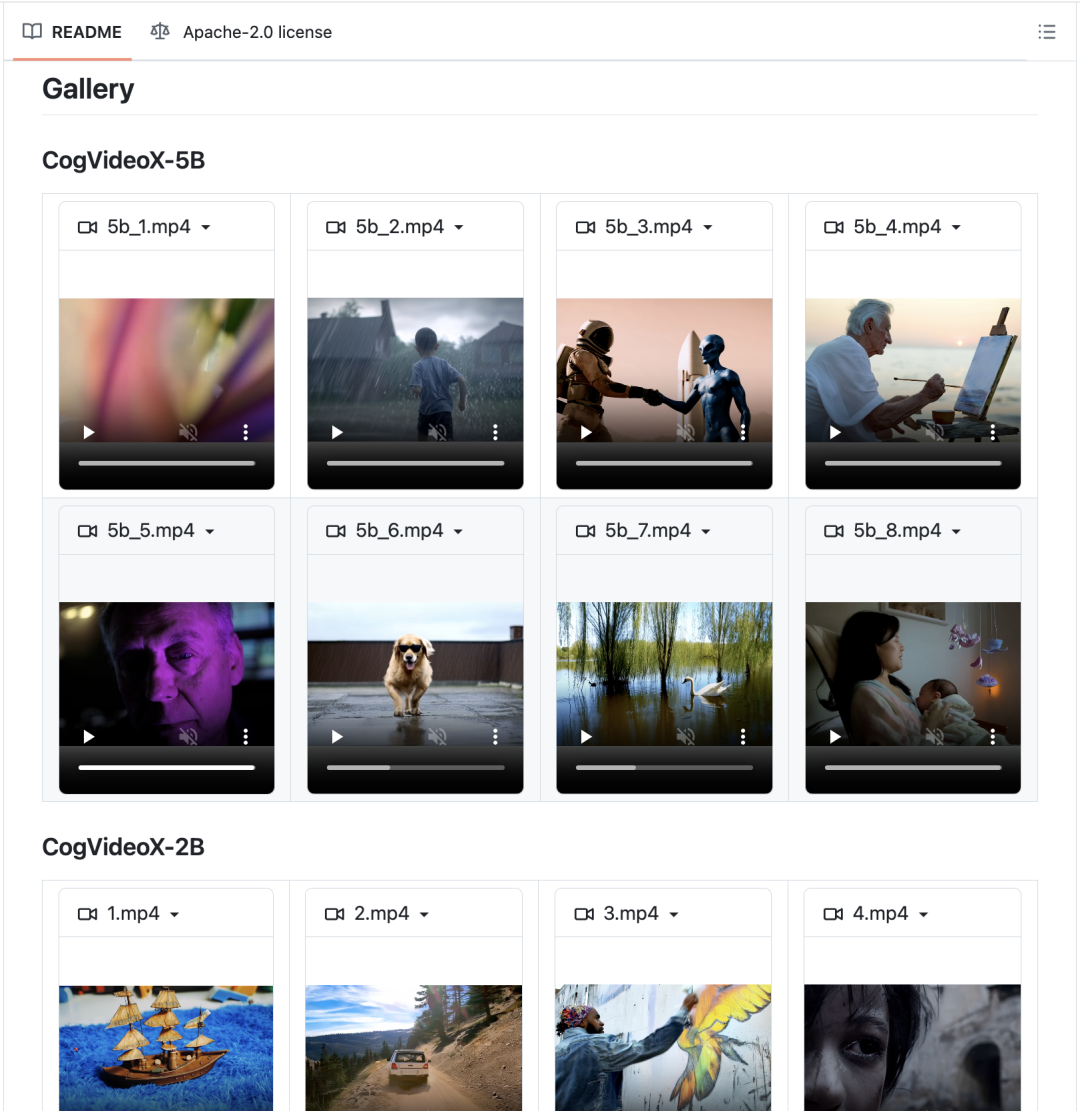
最新的 CogVideoX v1.5 直接进行了开源,开发者们肯定又要大呼痛快。开源地址在这里:https://github.com/thudm/cogvideo
开源文档里,有信息增量的内容非常多,各种技术细节和例子一目了然,看完以后甚至让我有种“我上我也行”的错觉。
开源文档的Gallery里,也有大量的展示案例,“AI有声电影”没看够的朋友真的强烈建议亲自去看一看。
受到海外网友启发,我拿一张《甄嬛传》的图片用新清影“图生视频”,人物的表情、眉眼、神态也很是生动。
如果用新清影来做表情包、动图、短视频、梗图等等,甚至还可以把声音给带上,而且画幅比例能够自己根据需要调整,确实实用。
从长远来看,从脚本、视频画面到声音和音效,理想情况下传统视频制作步骤均可由大模型完成,从而实现全流程自动化。
好奇为什么新清影能在内容连贯性、可控性和训练效率等方面,都有优秀的表现。特意去看了一下 CogVideoX 的模型架构:
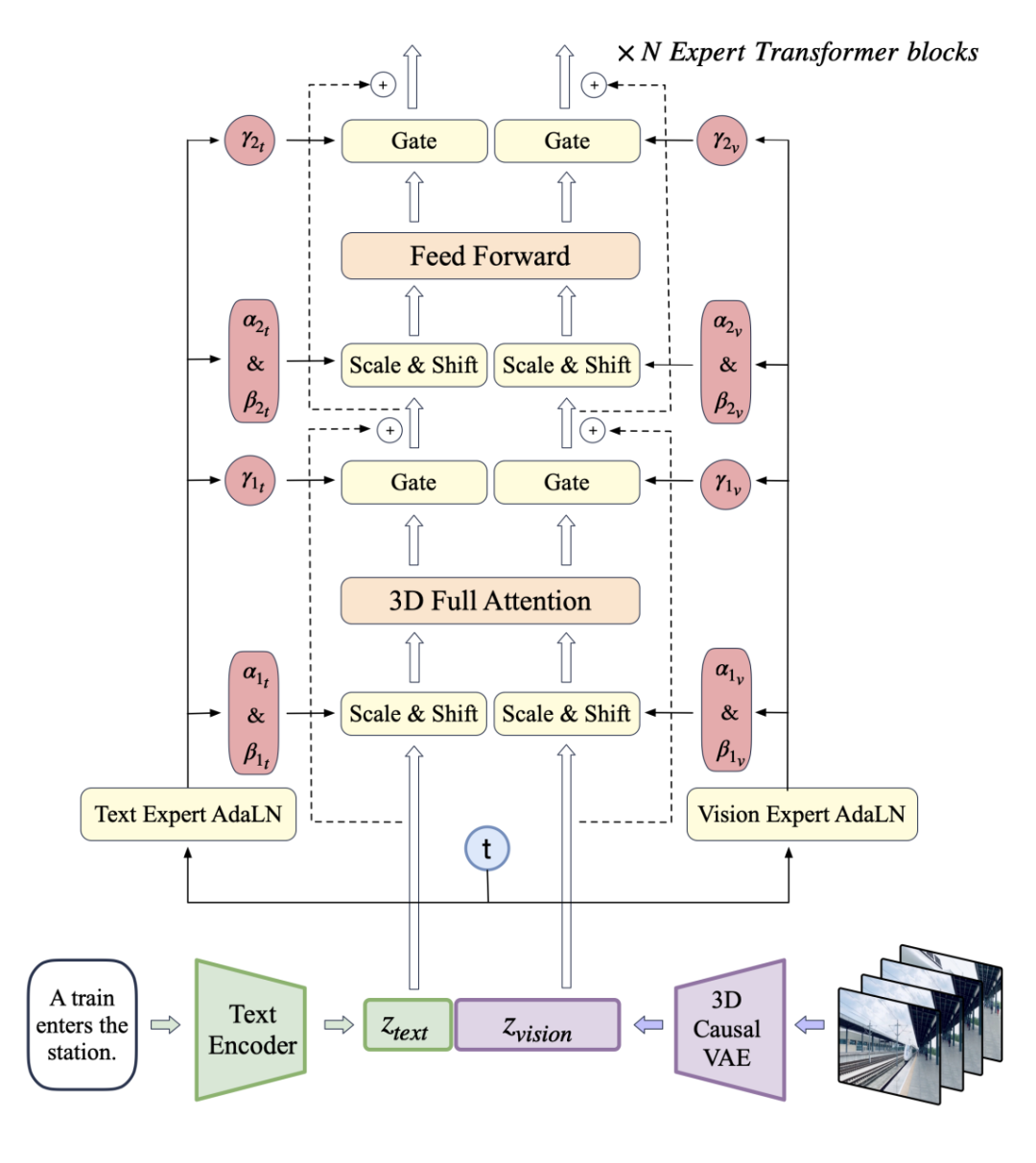 图|CogVideoX 架构
大家都知道,数据是大模型训练的关键,但相当一部分视频数据的分布噪声很大,并不适用于视频生成模型的训练。
为此,智谱专门构建了一个自动化的数据筛选框架,来过滤不良数据。
针对内容连贯性问题,智谱自研了一个高效的三维变分自编码器结构(3D VAE),将原视频空间压缩至 2% 大小,大大减少了视频扩散生成模型的训练成本和难度。
在工程部署方面,智谱基于时间维度上的序列并行(Temporal Sequential Parallel)对变分自编码器做了微调和部署,使其能够在更小的显存占用下支持极高帧数视频的编解码。
图|CogVideoX 架构
大家都知道,数据是大模型训练的关键,但相当一部分视频数据的分布噪声很大,并不适用于视频生成模型的训练。
为此,智谱专门构建了一个自动化的数据筛选框架,来过滤不良数据。
针对内容连贯性问题,智谱自研了一个高效的三维变分自编码器结构(3D VAE),将原视频空间压缩至 2% 大小,大大减少了视频扩散生成模型的训练成本和难度。
在工程部署方面,智谱基于时间维度上的序列并行(Temporal Sequential Parallel)对变分自编码器做了微调和部署,使其能够在更小的显存占用下支持极高帧数视频的编解码。
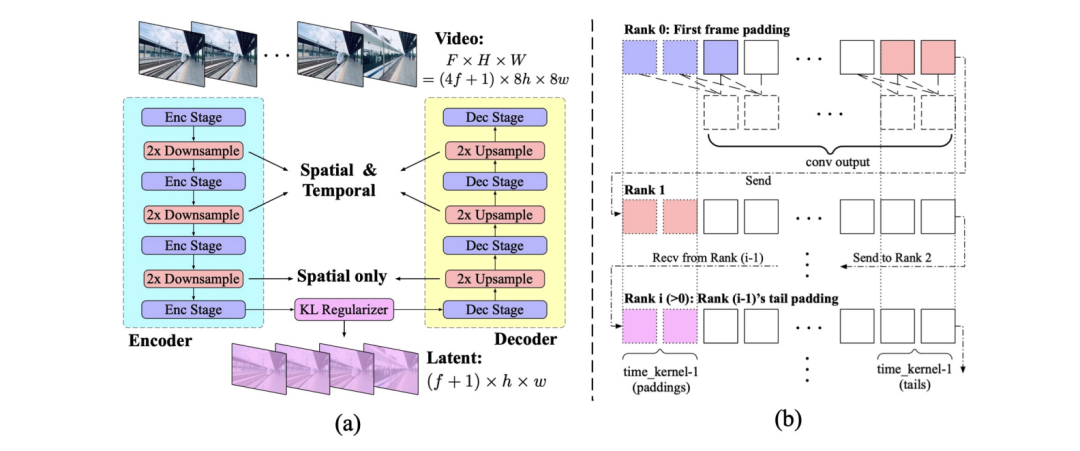 图|3D VAE 结构由一个编码器、一个解码器和一个潜空间 regularizer 组成,实现了从像素到潜空间的 8×8×4 倍的压缩(a)。时间因果卷积的上下文并行实现(b)。
为解决大多现有视频数据缺乏对应描述性文本或描述质量低下的问题,智谱还自研了一个端到端的专门用于标注视频数据的视频理解模型 CogVLM2-caption。
这是为了给海量的视频数据生成详细的、贴合内容的描述,进而增强模型的文本理解和指令遵循能力,更好地理解超长、复杂的 prompt,生成的视频也更符合用户的输入。
图|3D VAE 结构由一个编码器、一个解码器和一个潜空间 regularizer 组成,实现了从像素到潜空间的 8×8×4 倍的压缩(a)。时间因果卷积的上下文并行实现(b)。
为解决大多现有视频数据缺乏对应描述性文本或描述质量低下的问题,智谱还自研了一个端到端的专门用于标注视频数据的视频理解模型 CogVLM2-caption。
这是为了给海量的视频数据生成详细的、贴合内容的描述,进而增强模型的文本理解和指令遵循能力,更好地理解超长、复杂的 prompt,生成的视频也更符合用户的输入。
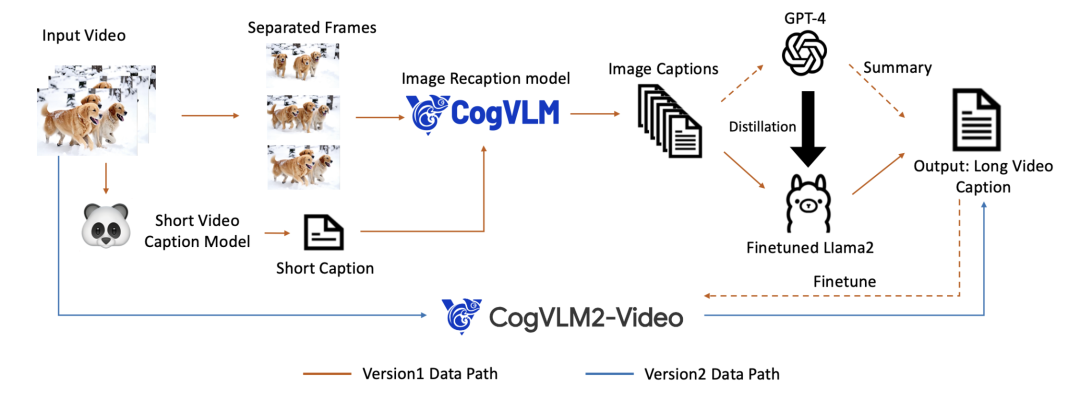 图|智谱使用 Panda70M 模型生成短视频字幕,提取帧来创建密集图像字幕,并使用 GPT-4 将其汇总为最终的视频字幕。为了加快这一过程,我们使用 GPT-4 对 Llama 2 模型进行了微调。
智谱也自研了一个融合文本、时间、空间三个维度的 transformer 架构。
该架构摒弃了传统的 cross attention 模块,在输入阶段就将文本 embedding 和视频 embedding concat 起来,以便更充分地进行两种模态的交互。
通过 expert adaptive layernorm 弥补了文本和视频两个模态在特征空间上的差异,从而更有效地利用扩散模型中的时间步信息,使得模型能够高效地利用参数,进而更好地将视觉信息与语义信息对齐。
以及让我觉得非常有技术想象力的 CogSound,实现了更高效的音频合成过程、以及音频与视频在语义层面的高度一致性,具有更好的连贯性和平滑过渡。
图|智谱使用 Panda70M 模型生成短视频字幕,提取帧来创建密集图像字幕,并使用 GPT-4 将其汇总为最终的视频字幕。为了加快这一过程,我们使用 GPT-4 对 Llama 2 模型进行了微调。
智谱也自研了一个融合文本、时间、空间三个维度的 transformer 架构。
该架构摒弃了传统的 cross attention 模块,在输入阶段就将文本 embedding 和视频 embedding concat 起来,以便更充分地进行两种模态的交互。
通过 expert adaptive layernorm 弥补了文本和视频两个模态在特征空间上的差异,从而更有效地利用扩散模型中的时间步信息,使得模型能够高效地利用参数,进而更好地将视觉信息与语义信息对齐。
以及让我觉得非常有技术想象力的 CogSound,实现了更高效的音频合成过程、以及音频与视频在语义层面的高度一致性,具有更好的连贯性和平滑过渡。
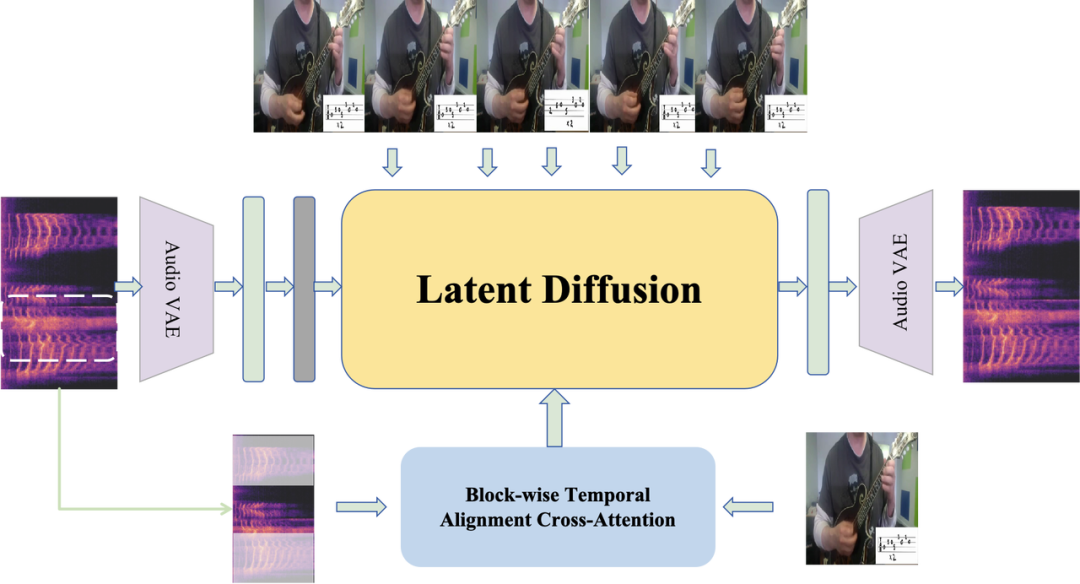 图|CogSound 架构
CogSound 让音频生成更高效、让音频和视频特征的关联性得到了加强,以及提升了时序建模的精度。
图|CogSound 架构
CogSound 让音频生成更高效、让音频和视频特征的关联性得到了加强,以及提升了时序建模的精度。
 提示词:两个男人旋转跳舞 (新清影生成)
AI教父Geoffrey Hinton在接受访谈时曾说过,多模态是AI的未来,它能让模型更好地理解学习,并且能让模型的空间推理能力更强,是提升AI能力的重要方向。
头部风险投资基金Coatue也认为,AI最好的时代还未到来,多模态模型将是前沿创新方向的重要性。
智谱是国内最早布局多模态的大模型厂商。CogVideoX率先应用于C端,使用户通过简单指令生成高分辨率视频,极大提升了视频创作效率。
同时,B 端应用场景包括专业视频制作、视频内容营销、游戏、广告营销和传媒等也受到智谱能力的带动。基于生成视频工具的内容创作成本持续走低。
可以预见,多模态AI将会是内容创作者的必备工具。智谱的多模态模型矩阵具有更加广阔的复合应用场景,不论是专业创作者还是普通用户都能便捷使用视频生成工具。
通过模型间的协作应用,如CogSound与CogVideoX结合,使声音与画面同步生成,从而进一步推动了视频创作流程的自动化。
视听享受、影音结合,AI和卓别林电影的故事,一定才刚刚开始。
提示词:两个男人旋转跳舞 (新清影生成)
AI教父Geoffrey Hinton在接受访谈时曾说过,多模态是AI的未来,它能让模型更好地理解学习,并且能让模型的空间推理能力更强,是提升AI能力的重要方向。
头部风险投资基金Coatue也认为,AI最好的时代还未到来,多模态模型将是前沿创新方向的重要性。
智谱是国内最早布局多模态的大模型厂商。CogVideoX率先应用于C端,使用户通过简单指令生成高分辨率视频,极大提升了视频创作效率。
同时,B 端应用场景包括专业视频制作、视频内容营销、游戏、广告营销和传媒等也受到智谱能力的带动。基于生成视频工具的内容创作成本持续走低。
可以预见,多模态AI将会是内容创作者的必备工具。智谱的多模态模型矩阵具有更加广阔的复合应用场景,不论是专业创作者还是普通用户都能便捷使用视频生成工具。
通过模型间的协作应用,如CogSound与CogVideoX结合,使声音与画面同步生成,从而进一步推动了视频创作流程的自动化。
视听享受、影音结合,AI和卓别林电影的故事,一定才刚刚开始。