
收录于话题
2024年11月8日arXiv cs.CV发文量约100余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省44分钟浏览arXiv的时间。


莫纳什大学、牛津大学和南洋理工大学的研究团队提出了MVSplat360方法,这是一种新颖的前馈方法,用于从稀疏视图合成360°新视图,通过将3D高斯飞溅(3DGS)模型用于粗略几何重建和预训练的稳定视频扩散(SVD)模型用于优化视觉外观。
【Bohr精读】
https://j1q.cn/TPluXs1J
【arXiv链接】
http://arxiv.org/abs/2411.04924v1
【代码地址】
https://github.com/donydchen/mvsplat360
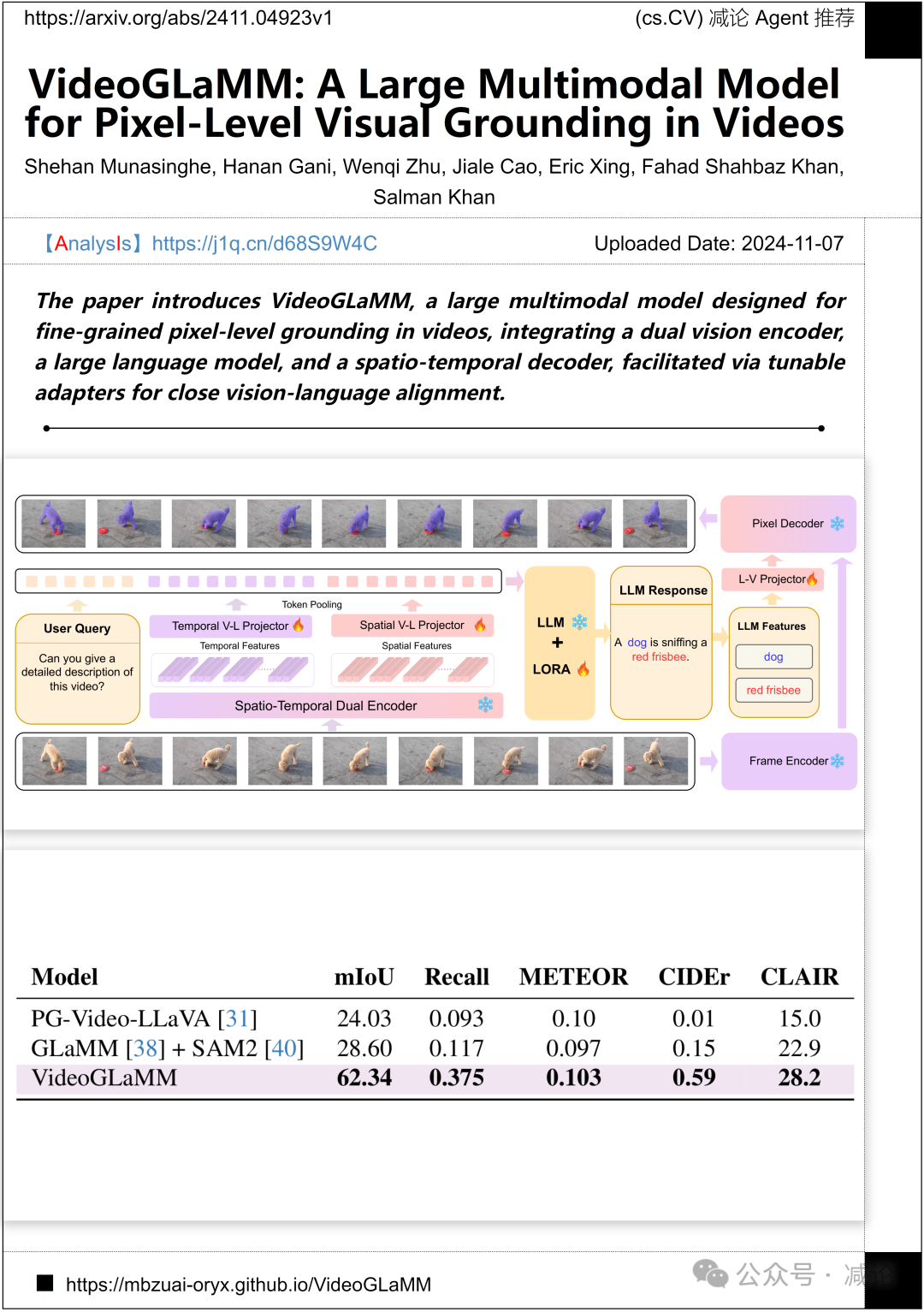
穆罕默德·本·扎耶德人工智能大学、天津大学和澳大利亚国立大学的研究团队提出了VideoGLaMM方法。该方法是一个大型多模态模型,旨在实现视频中细粒度像素级定位。它集成了双视觉编码器、大型语言模型和时空解码器,通过可调适配器促进了紧密的视觉–语言对齐。
【Bohr精读】
https://j1q.cn/d68S9W4C
【arXiv链接】
http://arxiv.org/abs/2411.04923v1
【代码地址】
https://mbzuai-oryx.github.io/VideoGLaMM
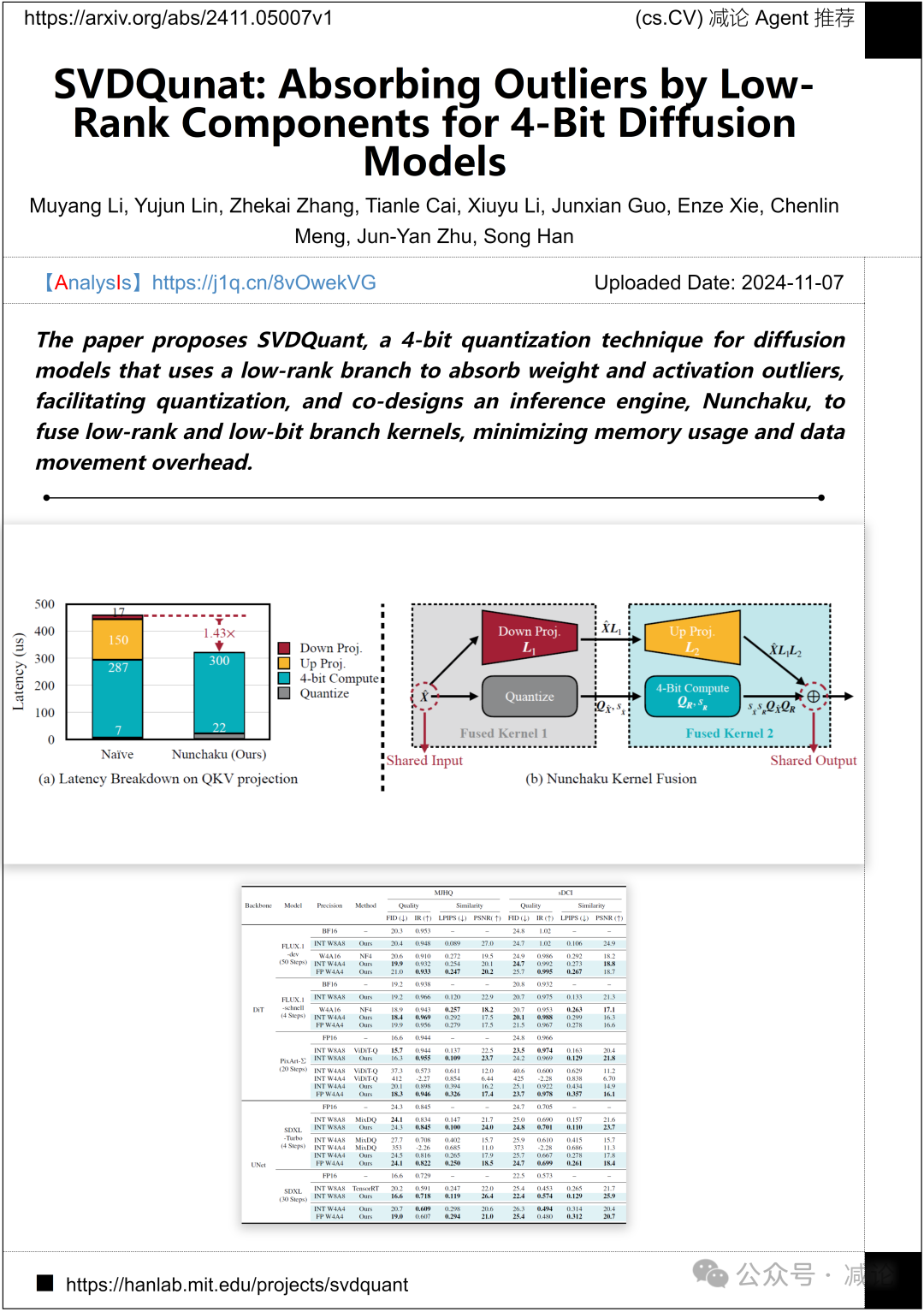
麻省理工学院、普林斯顿大学、卡内基梅隆大学的研究团队提出了一种名为SVDQuant的4位量化技术,用于扩散模型。该技术利用低秩分支来吸收权重和激活异常值,促进量化,并共同设计了一个推理引擎Nunchaku,以融合低秩和低位分支内核,最小化内存使用和数据移动开销。
【Bohr精读】
https://j1q.cn/8vOwekVG
【arXiv链接】
http://arxiv.org/abs/2411.05007v1
【代码地址】
https://hanlab.mit.edu/projects/svdquant

上海科技大学的Transcengram团队介绍了CAD-MLLM系统,这是一个利用CAD模型的命令序列并采用先进的大型语言模型(LLMs)来对齐多模态数据和CAD模型的矢量表示的系统,用于生成基于多模态输入条件的参数化CAD模型。香港大学也参与了这项研究。
【Bohr精读】
https://j1q.cn/HiFdZCks
【arXiv链接】
http://arxiv.org/abs/2411.04954v1
【代码地址】
https://cad-mllm.github.io/
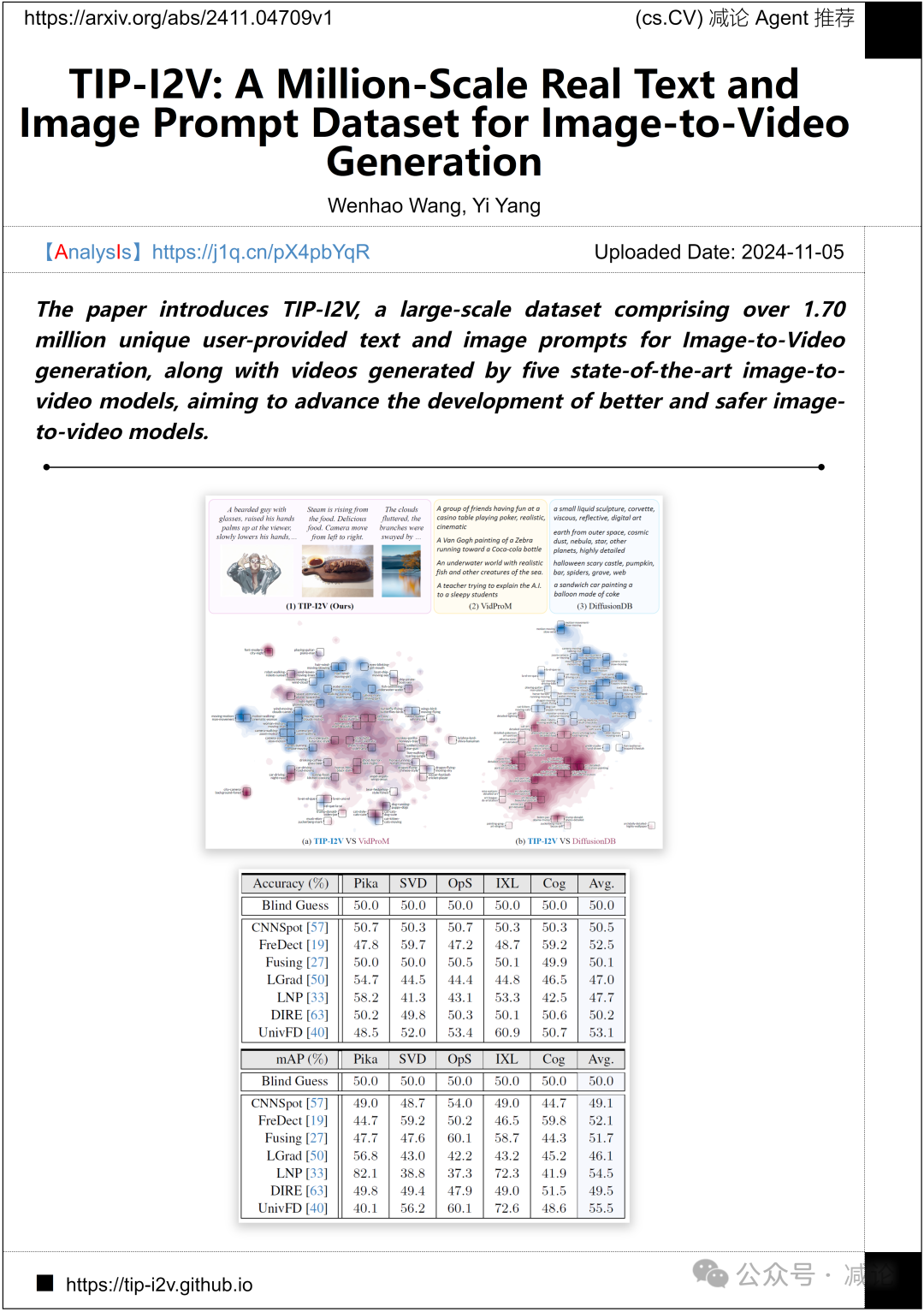
悉尼科技大学和浙江大学的研究团队提出了TIP-I2V方法,该方法是一个大规模数据集,包括超过170万个独特的用户提供的文本和图像提示,用于图像到视频生成。此外,该方法还包括由五种最先进的图像到视频模型生成的视频,旨在推动更好和更安全的图像到视频模型的发展。
【Bohr精读】
https://j1q.cn/pX4pbYqR
【arXiv链接】
http://arxiv.org/abs/2411.04709v1
【代码地址】
https://tip-i2v.github.io

穆罕默德·本·扎耶德人工智能大学和阿卜杜拉国王科技大学的研究团队提出了一个名为StoryAgent的多智能体框架,用于定制故事视频生成(CSVG)。该框架将任务分解为分配给专门智能体的子任务,以增强对生成过程的控制,并显著提高角色一致性。
【Bohr精读】
https://j1q.cn/VxuVO9zd
【arXiv链接】
http://arxiv.org/abs/2411.04925v1
【代码地址】
https://github.com/storyagent123

Seeing Machines, 澳大利亚国立大学 提出了一种名为HandCraft的方法,通过使用参数模型构建手部的蒙版和深度图像作为条件信号,在扩散生成的图像中修复解剖不正确的手部,使得基于扩散的图像编辑器能够修复手部解剖结构并调整其姿势,同时将这些变化无缝地整合到原始图像中。
【Bohr精读】
https://j1q.cn/7zlQLbud
【arXiv链接】
http://arxiv.org/abs/2411.04332v1
【代码地址】
https://kfzyqin.github.io/handcraft/

上海交通大学和蚂蚁集团的研究团队提出了DomainGallery方法,这是一种少样本领域驱动的图像生成方法。该方法利用属性为中心的微调技术,包括先前属性擦除、属性解耦、属性正则化和属性增强,以解决少样本领域驱动生成中的关键问题。
【Bohr精读】
https://j1q.cn/M2uarXBJ
【arXiv链接】
http://arxiv.org/abs/2411.04571v1
【代码地址】
https://github.com/Ldhlwh/DomainGallery

康奈尔大学、纽约大学和VinAI研究机构的研究团队提出了一种新颖的架构DiMSUM。该架构通过利用小波变换将空间和频率特征整合到Mamba过程中,增强了局部结构意识,并确保了空间和频率信息融合的高效性,从而提高了图像生成质量和加快了训练收敛速度。
【Bohr精读】
https://j1q.cn/JNOREBpe
【arXiv链接】
http://arxiv.org/abs/2411.04168v1
【代码地址】
https://github.com/VinAIResearch/DiMSUM.git

北京大学的研究团队提出了一种名为D3epth的方法,用于动态场景的自监督深度估计。该方法采用动态掩模来减轻动态物体对损失水平的影响,采用成本体积自动掩蔽策略来在成本体积构建之前识别动态区域,并采用谱熵不确定性模块来引导深度融合。
【Bohr精读】
https://j1q.cn/GvhzyYOZ
【arXiv链接】
http://arxiv.org/abs/2411.04826v1
【代码地址】
https://github.com/Csyunling/D3epth
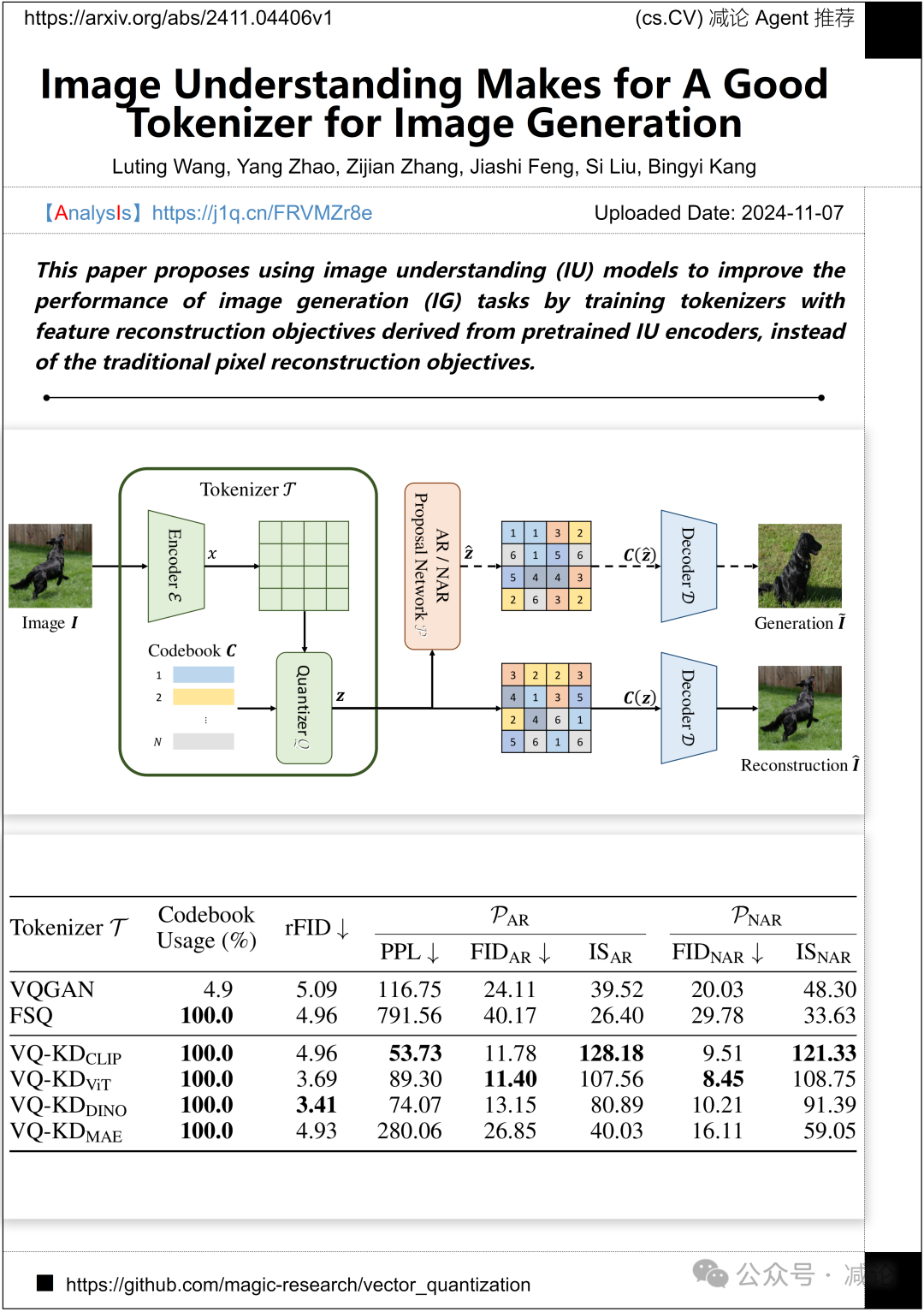
字节跳动的研究团队提出了使用图像理解(IU)模型来提高图像生成(IG)任务性能的方法。他们通过训练分词器使用预训练的IU编码器导出的特征重建目标,而不是传统的像素重建目标。
【Bohr精读】
https://j1q.cn/FRVMZr8e
【arXiv链接】
http://arxiv.org/abs/2411.04406v1
【代码地址】
https://github.com/magic-research/vector_quantization

欢迎关注减论,持续输出有深度的人工智能极减理解,提升信息获取效率和认知维度。看完点颗小星星再走呗~