
收录于话题
-
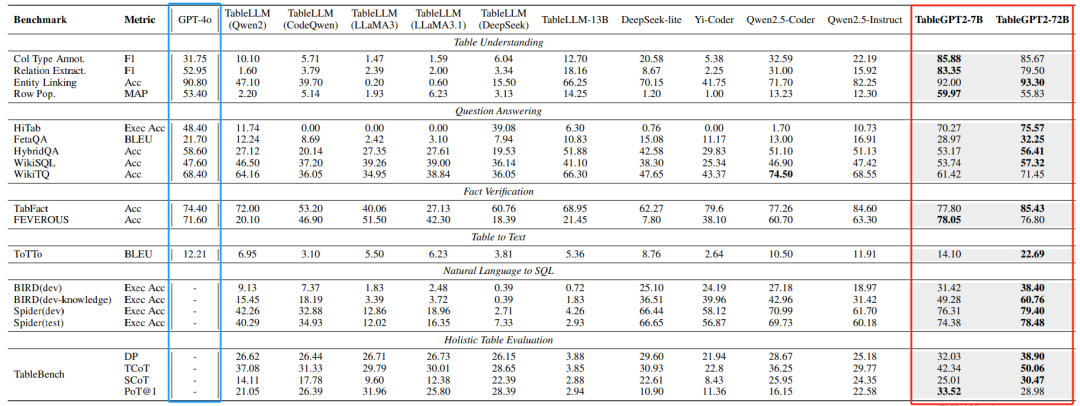
在23个基准测试指标上,TableGPT2在7B模型上比之前的基准中性LLMs平均性能提高了35.20%,在72B模型上提高了49.32%。 -
在某些基准测试中,TableGPT2甚至达到了优于或相当于GPT-4o的结果。 -
在涉及层次结构化表格的复杂数据基准测试,如HiTab中,TableGPT2执行准确率比Qwen2.5系列高出超过60%的绝对增长。

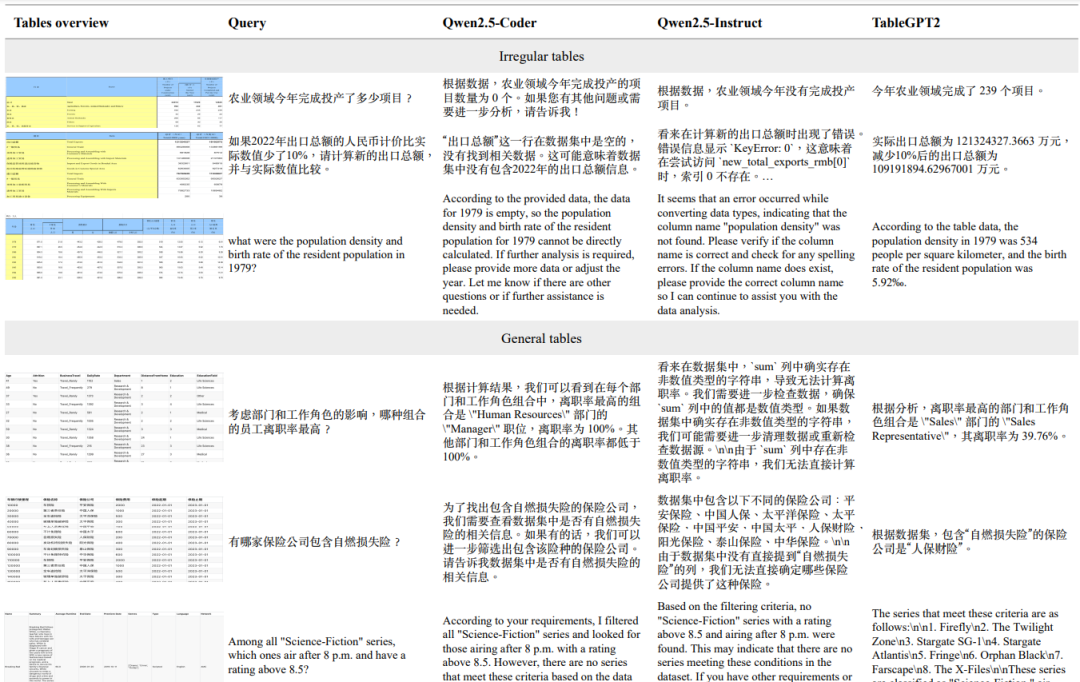
TableGPT2的定性案例
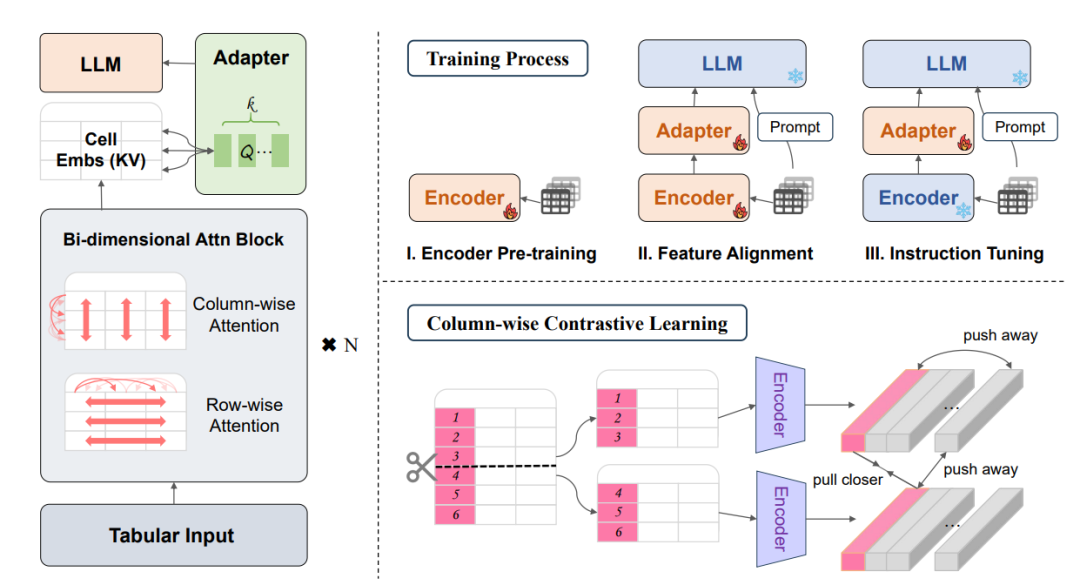
TableGPT2-7B 基于 Qwen2.5 架构构建,包含专门用于表格数据的编码。它具有独特的语义编码器,旨在解释表格数据,从行、列和整个表格中获取见解。已应用持续预训练 (CPT) 和监督微调 (SFT),以使模型能够用于实际的 BI 应用程序和复杂的查询处理。
TableGPT2的一个关键创新是其新颖的表格编码器,专门设计来捕获模式级别和单元格级别的信息。这个编码器增强了模型处理模糊查询、缺失列名和不规则表格的能力,这些在现实世界的应用中很常见。与视觉-语言模型(VLMs)类似,这种方法与解码器集成,形成了一个强大的大型多模态模型。

语义表格编码器的总体设计
https://huggingface.co/tablegpt/TableGPT2-7Bhttps://arxiv.org/pdf/2411.02059TableGPT2: A Large Multimodal Model with Tabular Data Integrationhttps://github.com/tablegpt/tablegpt-agent
推荐阅读
欢迎关注我的公众号“PaperAgent”,每天一篇大模型(LLM)文章来锻炼我们的思维,简单的例子,不简单的方法,提升自己。