收录于话题


本文介绍了一种名为深度函数因子模型(DF2M)的贝叶斯非参数模型,用于分析高维函数时间序列。DF2M基于印度自助过程和多任务高斯过程,结合深度核函数捕捉非马尔可夫和非线性时间动态。与许多黑箱深度学习模型不同,DF2M通过构建因子模型并整合深度神经网络在核函数中,提供了一种可解释的方法。此外,本文还开发了一种计算高效的可变推理算法来推断DF2M。实证结果表明,DF2M在解释性和预测准确性方面优于传统深度学习模型。
1. 引言
函数时间序列是指具有时间依赖性的函数对象的序列集合,近年来引起了越来越多的关注。随着数据收集技术和计算能力的进步,包含大量函数时间序列的高维数据集变得越来越普遍。例如,不同国家的年度年龄特定死亡率、不同家庭的每日能源消耗曲线以及数百只股票的日内累计回报轨迹。这些数据可以表示为p维函数时间序列Yt(·) = (Yt1(·),…, Ytp(·))T,其中每个Ytj(·)是在紧致区间U上定义的随机函数。分析高维函数时间序列需要使用降维技术来解决高维问题,使用函数方法来处理曲线数据的无限维性质,并使用时间序列建模方法来捕捉时间依赖性。
2. 预备知识
2.1 印度自助过程
印度自助过程(IBP)是一种概率分布,用于生成具有有限行和无限列的稀疏二进制矩阵。矩阵Z从IBP生成,表示为Z ~ IBP(α),其中α控制Z的列稀疏性。IBP可以通过顾客依次访问自助餐并选择菜品的比喻来解释。
2.2 高斯过程
高斯过程X(·)是在紧致区间U上定义的连续随机过程,其特点是任意有限集合的值属于L维多元高斯分布。高斯过程完全由其均值函数m(u) = E[X(u)]和协方差函数κ(u, v) = Cov(X(u), X(v))确定。协方差函数,也称为机器学习文献中的核函数,指定了不同点值之间的相关性。
2.3 序列深度学习
深度学习方法在计算机视觉、自然语言处理和强化学习中广泛应用,也逐渐用于时间序列预测。特别是循环神经网络(RNN)和注意力机制,通常用于自然语言处理中的序列预测任务,可以适应时间序列数据中的时间预测任务。
3. 深度函数因子模型
3.1 稀疏函数因子模型
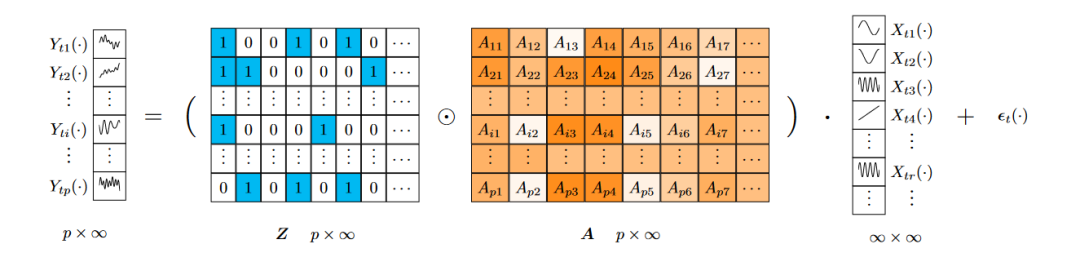
首先,本文提出了一个从贝叶斯角度出发的函数因子模型:其中,观测到的函数时间序列表示为Yt(·),二进制矩阵Z从印度自助过程生成,Z ~ IBP(α)。加载权重矩阵A的元素Atr ~ Normal(0, σA2)。潜在函数因子时间序列表示为Xt(·) = (Xt1(·), Xt2(·),…, Xtr(·),…)T,特异性成分表示为εt(·),遵循高斯分布的白噪声过程。
3.2 函数高斯过程动态模型
其次,通过将高维观测Yt(·)投影到低维潜在函数因子Xt(·),可以捕捉时间序列模型的序列结构。为了建模Xt(·)的时间依赖性,本文采用高斯过程来编码历史信息。具体来说,设计了跨因子r和l的协方差如下:其中,t和s表示两个时间戳,κ_X和κ_U分别是在X和U上定义的核函数。指示函数I(r = l)在r = l时等于1,否则为0。
3.3 深度时间核
为了捕捉复杂的潜在时间结构,本文使用神经网络来构建核函数。具体来说,输入向量通过深度神经网络进行变换,生成用于构建核函数的输出。具体公式如下:其中,Xt-1 = (Xt-1,1,…, Xt-1,r,…)T,F是映射函数,H表示序列深度学习框架。
4. DF2M的贝叶斯推理
4.1 稀疏变分推理
本文采用变分推理框架来推断DF2M。变分推理通过最大化证据下界(ELBO)来近似后验概率,等价于最小化变分分布和真实后验分布之间的Kullback-Leibler(KL)散度。对于DF2M,假设变分分布在潜在变量之间是独立的,其ELBO可以表示为:
使用印度自助过程的棍子断裂表示法,变分分布可以分解为:
变分分布的加载权重矩阵A可以分解为:
为了避免奇异矩阵求逆并提高计算效率,本文提出了一种基于Titsias(2009)的稀疏变分推理方法。该方法引入了一组诱导变量,表示潜在函数在U的小子集上的值。此外,本文采用了Hamelijnck等人(2021)的建议,即所有任务共享同一组诱导点,从而进一步提高计算效率。
4.2 因子变分分布的采样
为了优化变分分布,本文采用自动微分变分推理(ADVI)算法来最大化ELBO。具体步骤包括更新变分分布参数和训练参数。为了进行ADVI,需要从变分分布中采样Xt(·)。直接从nL × nL矩阵中采样计算成本高昂,因此本文利用时间核和空间核的可分离性,提出了一种更高效的方法。
具体来说,对于任意u = (u1,…, uL)T,首先将空间协方差矩阵划分为块矩阵:
然后,利用条件多元高斯分布的公式,计算Xt(·)的后验均值和方差。具体公式如下:
通过这种方法,可以高效地采样Xt(·),并计算ELBO。
4.3 初始化、训练和预测
本文使用ADVI技术训练变分参数的后验,通过计算ELBO相对于参数的梯度。训练过程包括迭代更新变分分布参数和训练参数,直到ELBO收敛。具体步骤如下:
-
更新变分分布参数μtr和Str,以及其他变分参数,包括印度自助过程Z和加载权重矩阵A的参数。
-
更新序列深度学习框架H中的可训练参数,通过ELBO相对于ΣX的梯度。
预测过程通过迭代生成未来时间步的预测序列。具体公式如下:
其中,和分别表示观测和因子的预测均值,和分别是Z和A的后验均值,Σn+1,1:n是1 × n矩阵,表示时间步n+1与前n个时间步的协方差。
5. 实验
5.1 数据集
本文将DF2M应用于四个真实世界的高维函数时间序列数据集:
-
日本死亡率数据集:包含1975年至2017年日本47个县的年龄特定死亡率数据,共43个观测值。
-
能源消耗数据集:包含2012年12月至2013年1月伦敦选定家庭的每半小时测量的能源消耗曲线,共55个观测值。
-
全球死亡率数据集:包含1960年至2010年不同国家的年龄特定死亡率数据,共50个观测值。
-
股票日内数据集:包含2017年S&P 100成分股票的高频价格观测数据,共45个交易日,每十分钟记录一次价格和累计日内回报轨迹。
每个数据集经过预处理并转换为适当的格式进行分析。
5.2 实验设置和指标
为了评估模型的预测准确性,本文将数据分为训练集和测试集,使用训练集训练模型参数,并在测试集上进行预测。计算平均绝对预测误差(MAPE)和平均平方预测误差(MSPE)来评估模型性能。具体公式如下:
其中,M = Kp(n2 – h + 1)。
在DF2M的实现中,本文集成了三种先进的深度学习模块:LSTM、GRU和自注意力机制。具体模型包括DF2M-LIN、DF2M-LSTM、DF2M-GRU和DF2M-ATTN。这些模型通过线性变换或深度学习模块生成输出,并通过核函数进行预测。
5.3 实证结果
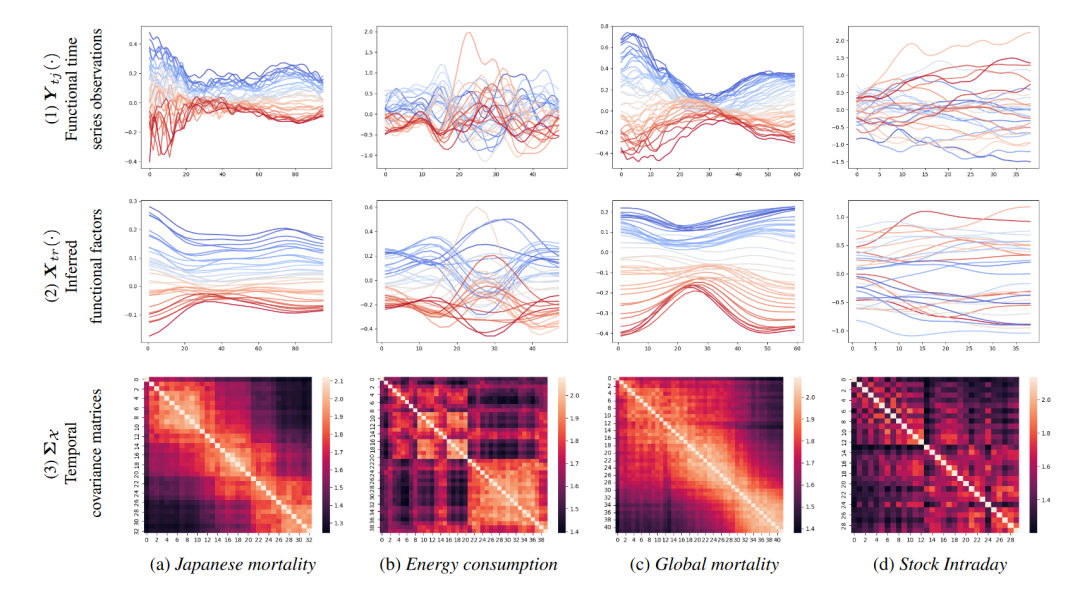
本文的主要目标是提高深度学习模型(如RNN或变换器)的解释性,同时保持或提高预测准确性。实证结果表明,DF2M在解释性和预测准确性方面优于传统深度学习模型。
解释性:首先,最大的因子在拟合模型中的时间动态显示出清晰和光滑的动态,可以用于解释时间变化的原因并进行稳健的预测。其次,时间协方差矩阵显示出不同数据集的强自相关性,特别是前三个数据集,而股票日内数据集显示出较弱的自相关性。
预测准确性:与标准深度学习模型相比,DF2M框架在所有四个数据集上的MSPE和MAPE均表现更好。具体来说,DF2M-LSTM模型在能源消耗和全球死亡率数据集上表现出色,而DF2M-ATTN模型在日本死亡率数据集上表现最佳。在股票日内数据集上,DF2M-LIN模型表现优于DF2M-LSTM和DF2M-GRU,这可能是因为金融数据中长期依赖性不明显,马尔可夫模型更适合捕捉其动态。
综上所述,DF2M通过结合可解释的结构和LSTM及注意力机制的非线性,显著提高了模型的整体性能。

6. 相关工作
在频繁主义统计方法中,已有多种方法用于高维函数时间序列分析,如基于主成分的降维、因子模型和分段变换。然而,这些方法通常假设线性和马尔可夫时间动态。本文首次提出了能够处理非线性和非马尔可夫动态的贝叶斯模型。
7. 结论
本文提出了DF2M,一种新颖的深度贝叶斯非参数方法,用于发现高维函数时间序列中的非马尔可夫和非线性动态。DF2M结合了印度自助过程、因子模型、高斯过程和深度神经网络的优势,提供了一个灵活而强大的框架。实证结果表明,DF2M在预测性能方面优于相应的标准深度学习模型。然而,本文的一个潜在局限性是依赖于简单的空间核,忽略了观测空间内的复杂关系。未来研究可以进一步探索这一领域。
本文介绍了一种名为深度函数因子模型(DF2M)的贝叶斯非参数模型,用于分析高维函数时间序列。DF2M基于印度自助过程和多任务高斯过程,结合深度核函数捕捉非马尔可夫和非线性时间动态。与许多黑箱深度学习模型不同,DF2M通过构建因子模型并整合深度神经网络在核函数中,提供了一种可解释的方法。此外,本文还开发了一种计算高效的可变推理算法来推断DF2M。实证结果表明,DF2M在解释性和预测准确性方面优于传统深度学习模型。
1. 引言
函数时间序列是指具有时间依赖性的函数对象的序列集合,近年来引起了越来越多的关注。随着数据收集技术和计算能力的进步,包含大量函数时间序列的高维数据集变得越来越普遍。例如,不同国家的年度年龄特定死亡率、不同家庭的每日能源消耗曲线以及数百只股票的日内累计回报轨迹。这些数据可以表示为p维函数时间序列Yt(·) = (Yt1(·),…, Ytp(·))T,其中每个Ytj(·)是在紧致区间U上定义的随机函数。分析高维函数时间序列需要使用降维技术来解决高维问题,使用函数方法来处理曲线数据的无限维性质,并使用时间序列建模方法来捕捉时间依赖性。
2. 预备知识
2.1 印度自助过程
印度自助过程(IBP)是一种概率分布,用于生成具有有限行和无限列的稀疏二进制矩阵。矩阵Z从IBP生成,表示为Z ~ IBP(α),其中α控制Z的列稀疏性。IBP可以通过顾客依次访问自助餐并选择菜品的比喻来解释。
2.2 高斯过程
高斯过程X(·)是在紧致区间U上定义的连续随机过程,其特点是任意有限集合的值属于L维多元高斯分布。高斯过程完全由其均值函数m(u) = E[X(u)]和协方差函数κ(u, v) = Cov(X(u), X(v))确定。协方差函数,也称为机器学习文献中的核函数,指定了不同点值之间的相关性。
2.3 序列深度学习
深度学习方法在计算机视觉、自然语言处理和强化学习中广泛应用,也逐渐用于时间序列预测。特别是循环神经网络(RNN)和注意力机制,通常用于自然语言处理中的序列预测任务,可以适应时间序列数据中的时间预测任务。
3. 深度函数因子模型
3.1 稀疏函数因子模型
首先,本文提出了一个从贝叶斯角度出发的函数因子模型:其中,观测到的函数时间序列表示为Yt(·),二进制矩阵Z从印度自助过程生成,Z ~ IBP(α)。加载权重矩阵A的元素Atr ~ Normal(0, σA2)。潜在函数因子时间序列表示为Xt(·) = (Xt1(·), Xt2(·),…, Xtr(·),…)T,特异性成分表示为εt(·),遵循高斯分布的白噪声过程。
3.2 函数高斯过程动态模型
其次,通过将高维观测Yt(·)投影到低维潜在函数因子Xt(·),可以捕捉时间序列模型的序列结构。为了建模Xt(·)的时间依赖性,本文采用高斯过程来编码历史信息。具体来说,设计了跨因子r和l的协方差如下:其中,t和s表示两个时间戳,κ_X和κ_U分别是在X和U上定义的核函数。指示函数I(r = l)在r = l时等于1,否则为0。
3.3 深度时间核
为了捕捉复杂的潜在时间结构,本文使用神经网络来构建核函数。具体来说,输入向量通过深度神经网络进行变换,生成用于构建核函数的输出。具体公式如下:其中,Xt-1 = (Xt-1,1,…, Xt-1,r,…)T,F是映射函数,H表示序列深度学习框架。
4. DF2M的贝叶斯推理
4.1 稀疏变分推理
本文采用变分推理框架来推断DF2M。变分推理通过最大化证据下界(ELBO)来近似后验概率,等价于最小化变分分布和真实后验分布之间的Kullback-Leibler(KL)散度。对于DF2M,假设变分分布在潜在变量之间是独立的,其ELBO可以表示为:
使用印度自助过程的棍子断裂表示法,变分分布可以分解为:
变分分布的加载权重矩阵A可以分解为:
为了避免奇异矩阵求逆并提高计算效率,本文提出了一种基于Titsias(2009)的稀疏变分推理方法。该方法引入了一组诱导变量,表示潜在函数在U的小子集上的值。此外,本文采用了Hamelijnck等人(2021)的建议,即所有任务共享同一组诱导点,从而进一步提高计算效率。
4.2 因子变分分布的采样
为了优化变分分布,本文采用自动微分变分推理(ADVI)算法来最大化ELBO。具体步骤包括更新变分分布参数和训练参数。为了进行ADVI,需要从变分分布中采样Xt(·)。直接从nL × nL矩阵中采样计算成本高昂,因此本文利用时间核和空间核的可分离性,提出了一种更高效的方法。
具体来说,对于任意u = (u1,…, uL)T,首先将空间协方差矩阵划分为块矩阵:
然后,利用条件多元高斯分布的公式,计算Xt(·)的后验均值和方差。具体公式如下:
通过这种方法,可以高效地采样Xt(·),并计算ELBO。
4.3 初始化、训练和预测
本文使用ADVI技术训练变分参数的后验,通过计算ELBO相对于参数的梯度。训练过程包括迭代更新变分分布参数和训练参数,直到ELBO收敛。具体步骤如下:
-
更新变分分布参数μtr和Str,以及其他变分参数,包括印度自助过程Z和加载权重矩阵A的参数。 -
更新序列深度学习框架H中的可训练参数,通过ELBO相对于ΣX的梯度。
预测过程通过迭代生成未来时间步的预测序列。具体公式如下:
其中,和分别表示观测和因子的预测均值,和分别是Z和A的后验均值,Σn+1,1:n是1 × n矩阵,表示时间步n+1与前n个时间步的协方差。
5. 实验
5.1 数据集
本文将DF2M应用于四个真实世界的高维函数时间序列数据集:
-
日本死亡率数据集:包含1975年至2017年日本47个县的年龄特定死亡率数据,共43个观测值。 -
能源消耗数据集:包含2012年12月至2013年1月伦敦选定家庭的每半小时测量的能源消耗曲线,共55个观测值。 -
全球死亡率数据集:包含1960年至2010年不同国家的年龄特定死亡率数据,共50个观测值。 -
股票日内数据集:包含2017年S&P 100成分股票的高频价格观测数据,共45个交易日,每十分钟记录一次价格和累计日内回报轨迹。
每个数据集经过预处理并转换为适当的格式进行分析。
5.2 实验设置和指标
为了评估模型的预测准确性,本文将数据分为训练集和测试集,使用训练集训练模型参数,并在测试集上进行预测。计算平均绝对预测误差(MAPE)和平均平方预测误差(MSPE)来评估模型性能。具体公式如下:
其中,M = Kp(n2 – h + 1)。
在DF2M的实现中,本文集成了三种先进的深度学习模块:LSTM、GRU和自注意力机制。具体模型包括DF2M-LIN、DF2M-LSTM、DF2M-GRU和DF2M-ATTN。这些模型通过线性变换或深度学习模块生成输出,并通过核函数进行预测。
5.3 实证结果
本文的主要目标是提高深度学习模型(如RNN或变换器)的解释性,同时保持或提高预测准确性。实证结果表明,DF2M在解释性和预测准确性方面优于传统深度学习模型。
解释性:首先,最大的因子在拟合模型中的时间动态显示出清晰和光滑的动态,可以用于解释时间变化的原因并进行稳健的预测。其次,时间协方差矩阵显示出不同数据集的强自相关性,特别是前三个数据集,而股票日内数据集显示出较弱的自相关性。
预测准确性:与标准深度学习模型相比,DF2M框架在所有四个数据集上的MSPE和MAPE均表现更好。具体来说,DF2M-LSTM模型在能源消耗和全球死亡率数据集上表现出色,而DF2M-ATTN模型在日本死亡率数据集上表现最佳。在股票日内数据集上,DF2M-LIN模型表现优于DF2M-LSTM和DF2M-GRU,这可能是因为金融数据中长期依赖性不明显,马尔可夫模型更适合捕捉其动态。
综上所述,DF2M通过结合可解释的结构和LSTM及注意力机制的非线性,显著提高了模型的整体性能。
6. 相关工作
在频繁主义统计方法中,已有多种方法用于高维函数时间序列分析,如基于主成分的降维、因子模型和分段变换。然而,这些方法通常假设线性和马尔可夫时间动态。本文首次提出了能够处理非线性和非马尔可夫动态的贝叶斯模型。
7. 结论
本文提出了DF2M,一种新颖的深度贝叶斯非参数方法,用于发现高维函数时间序列中的非马尔可夫和非线性动态。DF2M结合了印度自助过程、因子模型、高斯过程和深度神经网络的优势,提供了一个灵活而强大的框架。实证结果表明,DF2M在预测性能方面优于相应的标准深度学习模型。然而,本文的一个潜在局限性是依赖于简单的空间核,忽略了观测空间内的复杂关系。未来研究可以进一步探索这一领域。
论文及代码下载见星球
QuantML星球内有各类丰富的量化资源,包括数百篇论文代码,QuantML-Qlib框架,研报复现,研报分享项目等,星球群内有许多大佬,包括量化私募创始人,公募jjjl,券商研究员,顶会论文作者,github千星项目作者等,星球人数已经500+,欢迎加入交流
我们的愿景是搭建最全面的量化知识库,无论你希望查找任何量化资料,都能够高效的查找到相关的论文代码以及复现结果,期待您的加入。