
本文介绍了一种先进的序列到序列模型,用于预测整个多级限价单簿(LOB),包括价格和交易量。核心贡献是提出了一种复合多变量嵌入方法,能够捕捉时空关系。实证结果表明,该方法在保持LOB结构的同时,实现了最低的预测误差,优于其他方法。
1. 引言
限价单簿(LOB)是记录特定金融工具所有未完成买卖订单的数字记录。它包含每个订单的价格和数量信息,以及订单放置的时间。LOB的动态性质要求快速处理和分析大量信息。LOB数据具有复杂的多变量时间序列结构,其中不同档位、类型和特征相互关联。准确捕捉每个属性的影响对LOB的有效预测建模至关重要。此外,时间序列预测的另一个挑战是数据的非平稳性。本文提出的方法通过复合多变量嵌入和注意力机制,解决了这些问题。
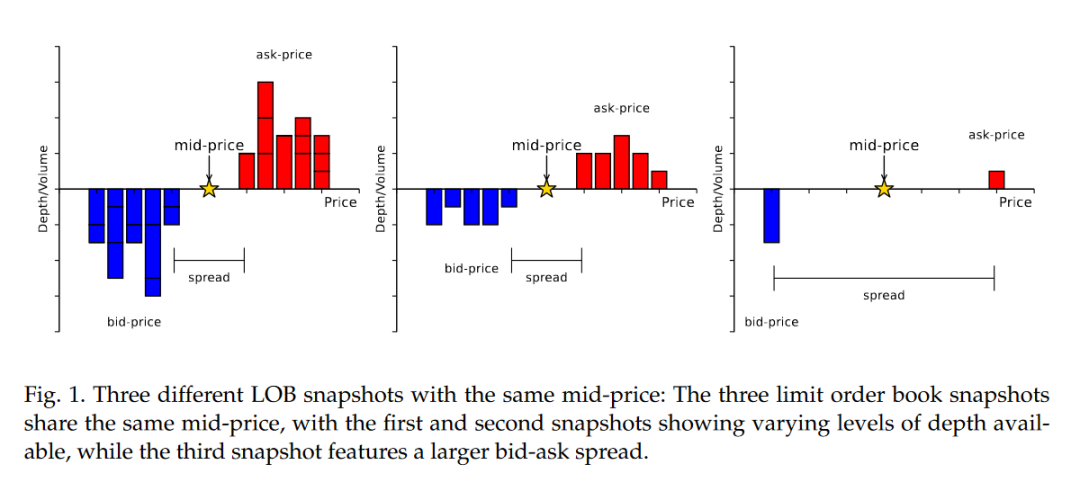

2. 数据
研究基于LOBSTER数据集,该数据集提供了苹果(AAPL)、谷歌(GOOG)、英特尔(INTC)、微软(MSFT)和亚马逊(AMZN)五家科技公司股票的实时限价单簿(LOB)数据。数据涵盖了2012年6月21日的完整交易日,从早上9:30开盘至下午4:00收盘,每只股票捕获了约30万至60万个订单簿快照,时间分辨率达到毫秒级别。
2.1 高频动态和时空关联
研究指出,LOB数据的高频特性使得传统的金融模型假设不再适用,因为这些假设通常基于更长的时间范围。本文通过分析AMZN股票在不同时间窗口内的最佳买卖价格的滚动平均值,展示了时间分辨率对数据理解的重要性。此外,研究还讨论了LOB的时空结构,揭示了市场参与者的互动如何动态影响订单簿的价格和交易量。
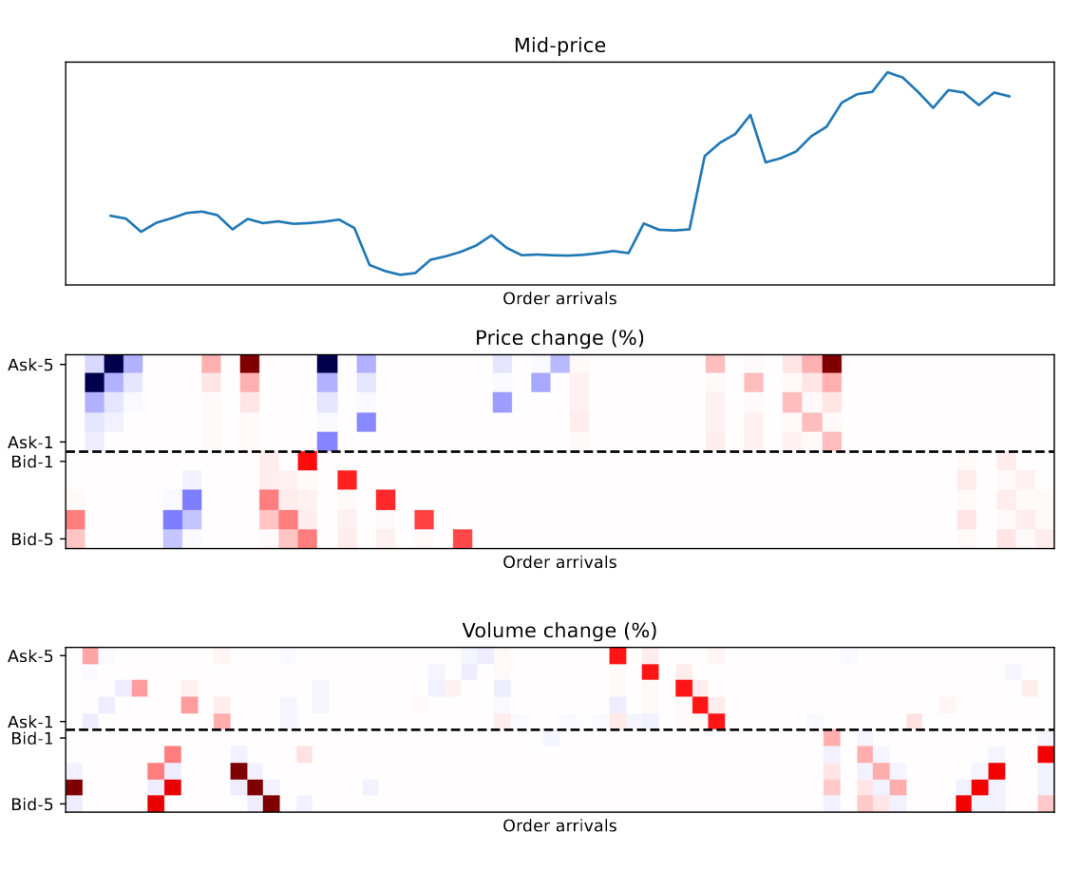
2.2 数据结构和准备
为了支持模型开发,研究对LOB数据进行了格式化和转换。每个订单簿快照被表示为一个向量,包含时间戳和每个价格档位的买卖价格及交易量。研究固定了订单簿的档位数为5,并对所有股票的数据进行了合并,创建了一个包含100个维度的数据集,每个维度代表一个股票的买卖价格和交易量。数据集被划分为训练、验证和测试集,比例为6:2:2。
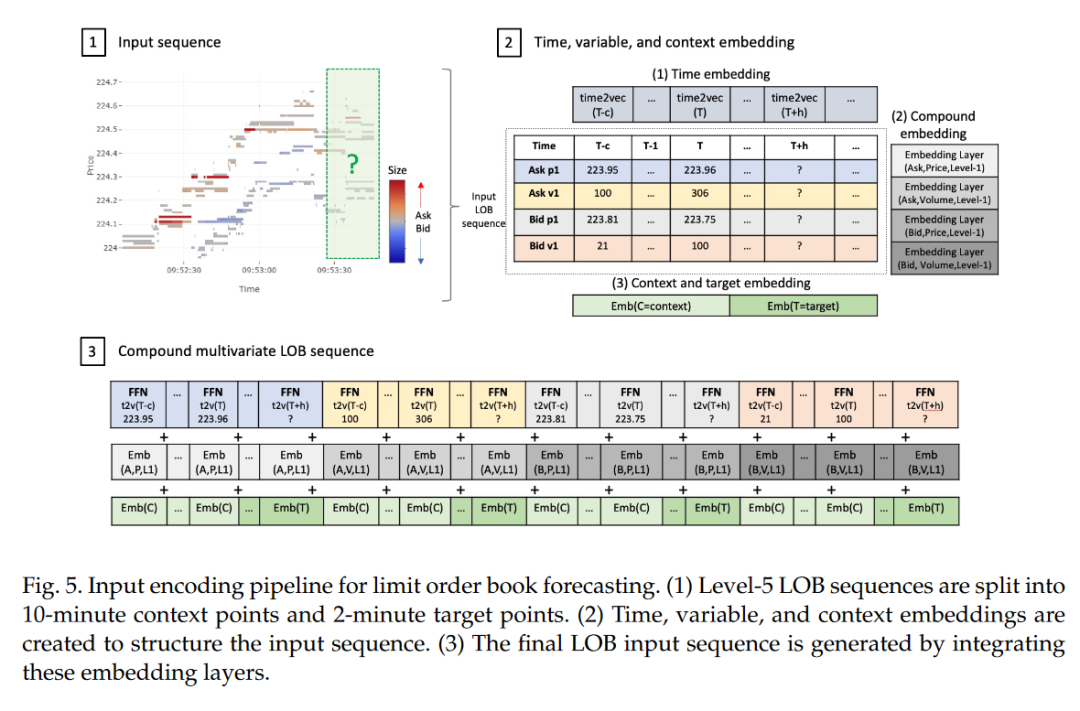
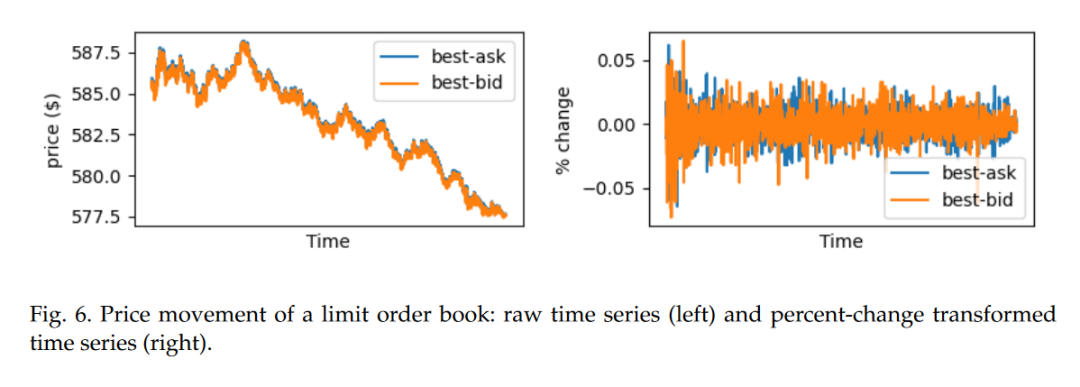
2.3 输入转换和缩放
在数据预处理阶段,研究采用了百分比变化转换和最小-最大缩放方法来处理LOB数据。百分比变化转换有助于实现价格序列的平稳性,而最小-最大缩放则确保了不同规模的变量不会对模型产生过大影响。这些转换有助于模型更好地学习和预测价格和交易量的变化。
3. 方法
3.1 复合多变量嵌入
本文提出的模型采用了复合多变量嵌入方法,该方法通过为LOB数据中的每个属性(如订单类型、价格档位、特征类型和股票)分配独立的嵌入层,然后将这些嵌入层组合和缩放,以捕捉数据中的时空关系和属性间的复杂依赖性。这种方法不仅减少了嵌入层的参数数量,而且通过整合多个嵌入层,有效地编码了LOB数据的结构信息。
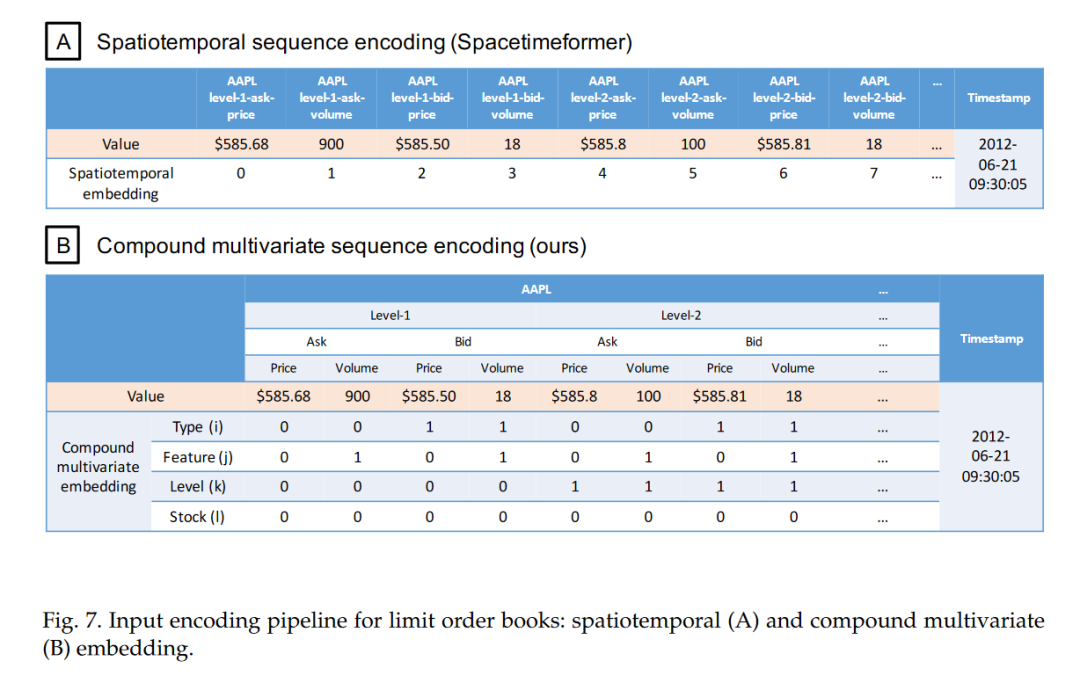
嵌入过程包括时间嵌入,使用Time2Vec层将时间戳转换为频率嵌入,然后通过前馈层进一步捕捉时间模式。此外,还有上下文-目标嵌入,用于区分观测数据和预测目标。这些嵌入被送入基于注意力机制的编码器-解码器架构中,编码器使用自注意力模块捕捉局部和全局上下文,而解码器使用掩码注意力防止预测时访问未来信息。
3.2 训练
模型的训练聚焦于最小化预测误差,同时保持LOB的结构完整性。为此,本文定义了预测损失,主要关注第五档位价格和交易量的均方误差(MSE)。此外,为了确保模型输出遵循LOB的价格档位结构,本文引入了结构正则化器。结构正则化器通过惩罚违反价格档位顺序的预测来强制模型保持LOB的序数结构。总损失函数是预测损失和结构损失的加权和,其中权重决定了结构正则化的强度。
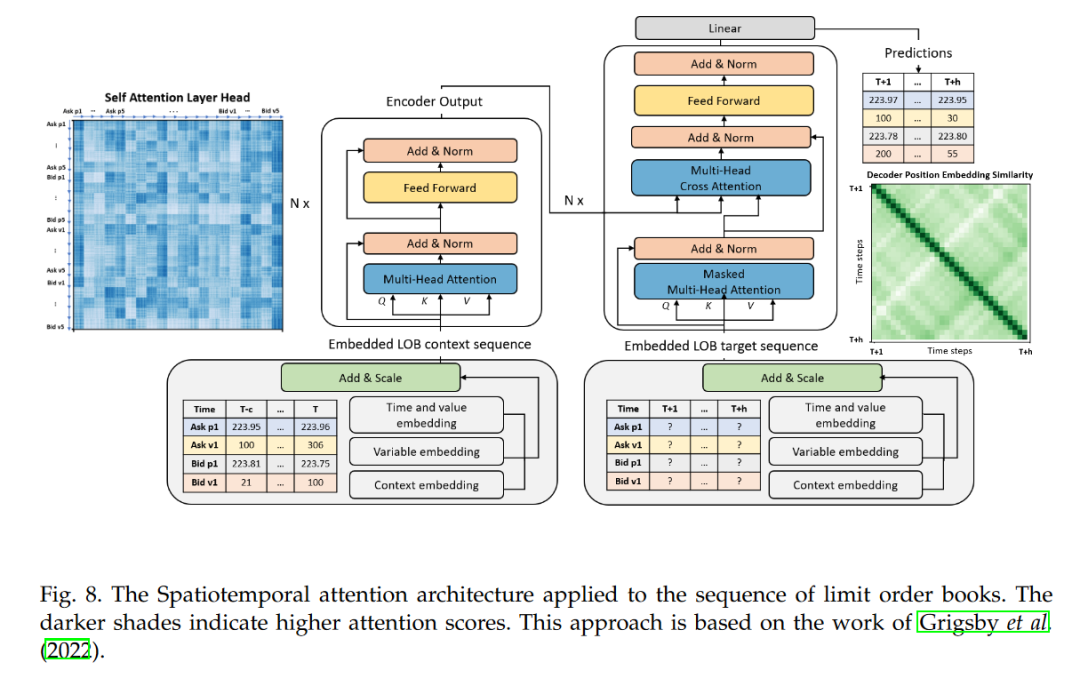
在训练过程中,模型采用了学习率衰减和季节性分解可逆归一化技术来提高性能。模型使用三头注意力模块进行训练,并在验证损失连续10个周期无改善时停止训练。测试时,选择与最低验证总损失相关的训练模型权重。
3.3 实验设置
实验中,模型的输入序列被组织为10分钟的上下文序列和2分钟的目标序列。这种设置允许模型基于最近的历史数据预测未来的价格和交易量变化。输入数据经过百分比变化转换和最小-最大缩放,以提高模型对非平稳时间序列的适应能力。
4. 结果
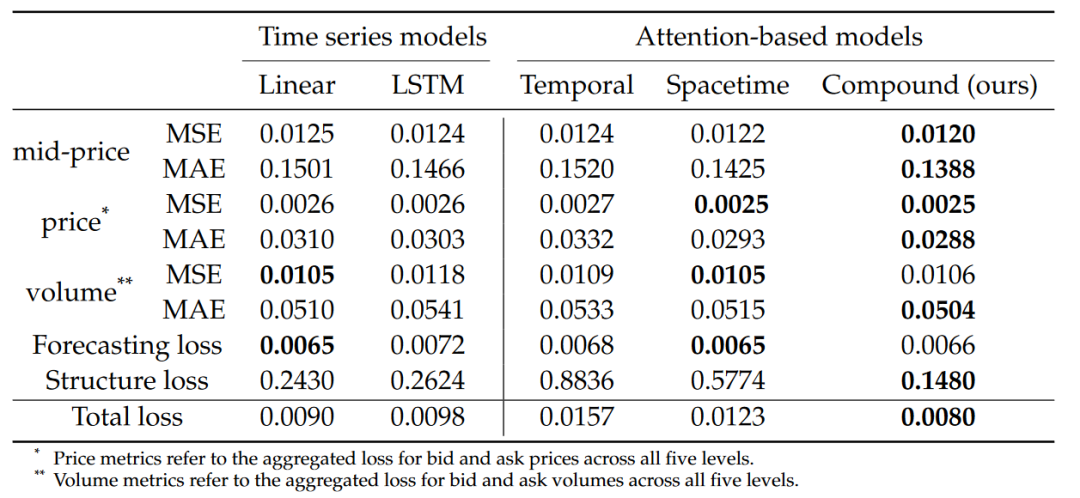
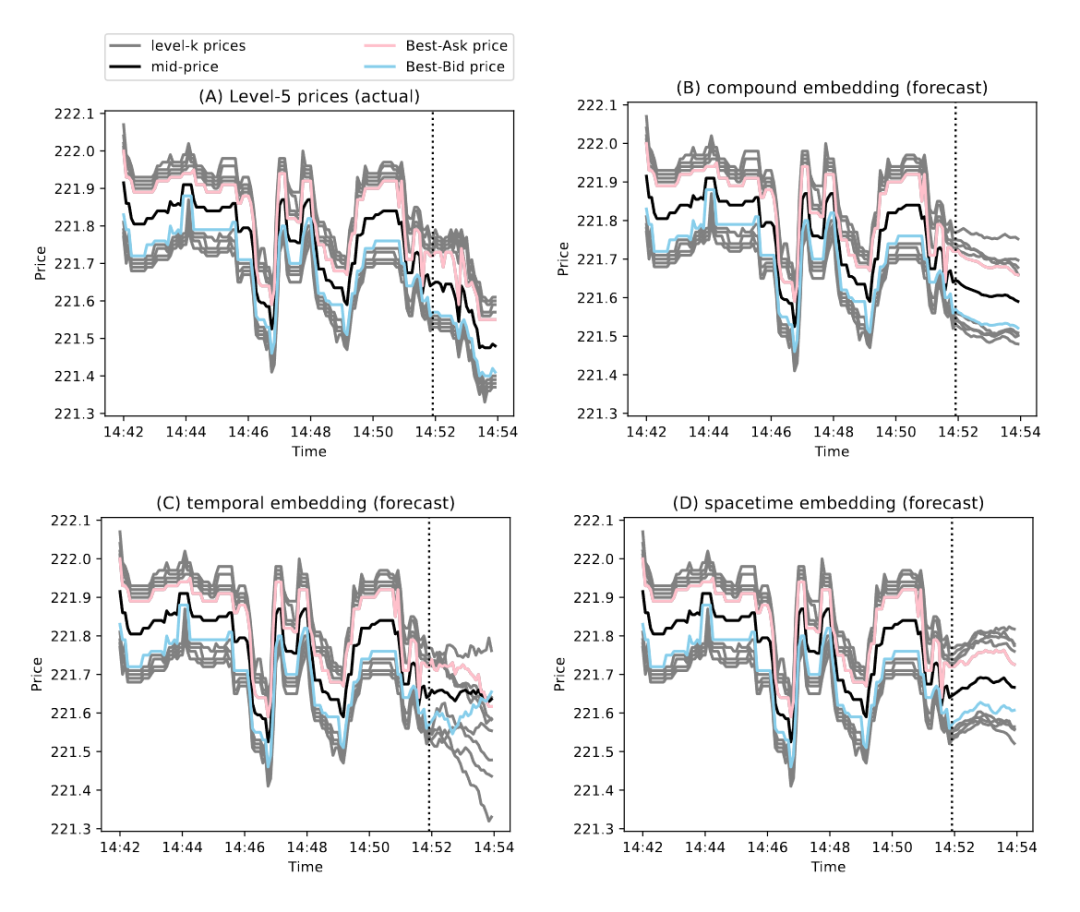
实验部分首先评估了不同输入数据转换方法对预测精度的影响,包括单独使用百分比变化转换、最小-最大缩放,以及两者的组合使用。结果显示,结合使用这两种转换方法能够在保持数据平稳性的同时,有效处理多变量数据中的尺度差异,从而在预测LOB的多级价格和交易量时达到最低的均方误差(MSE)和平均绝对误差(MAE)。在模型比较方面,本文模型在预测中点价格、各档位价格和交易量等指标上均优于线性自回归模型、LSTM网络、基于时间注意力的模型和空间时间注意力模型。特别是在结构损失的评估中,本文模型能够更好地保持LOB的价格档位序数结构,显示出较低的结构损失,这表明了模型在预测精度和结构保持方面的优越性能。此外,第四章还提供了预测结果的可视化展示,通过对比实际数据和模型预测的数据,直观地展示了模型预测的准确性。图表显示,本文模型能够紧密跟随实际价格和交易量的变化趋势,即使在市场波动较大的情况下也能保持较高的预测精度。
5. 讨论
本文的方法完全基于数据驱动,允许预测每个档位的多级价格及其相应的订单大小。这种多级视角扩展了我们的分析范围,超越了中点价格预测,其中实际应用往往受到限制。通过捕捉价格水平的细粒度结构,本文的模型更好地反映了实际市场动态,为订单执行提供了更可行的基础。
6. 结论
本研究解决了预测多级LOB数据的挑战,这一任务通常超出了传统时间序列预测模型的能力。主要贡献是开发和实施了一种复合多变量嵌入方法。这种方法有效地捕捉了LOB属性之间的复杂相互依赖性,包括订单类型、特征和档位。实证结果表明,本文的方法在保持LOB的序数结构的同时,实现了最低的预测误差,优于现有的多变量预测方法。