
前言,这几天在学习《2024年中国智能算力行业白皮书》,其中有个章节重点介绍了大模型和所需算力的关系,可以通过AI大模的参数量、Token数以及训练时间来具体评估所需的算力(包括训练和推理两个维度),今天引用材料里的内容和简单做个分享,文章的最后会分享该白皮书的获取方式,欢迎自取!
一、AI大模型的关键参数
我们经常看不同大模型“规模”的介绍,比如LLaMA-65B、GPT3-175B、智谱 的GLM-130B,其中的这个“大B”是英文十亿Billion的缩写,65B就是指大模型参数量有650亿,现在大模型的训练还有一个因素很关键就是“训练时长”,大模型公司肯定希望时间越短越好,但所需的算力消化越大。下图展示了几个常见大模型的参数量、训练时长和所需的GPU卡的规模。
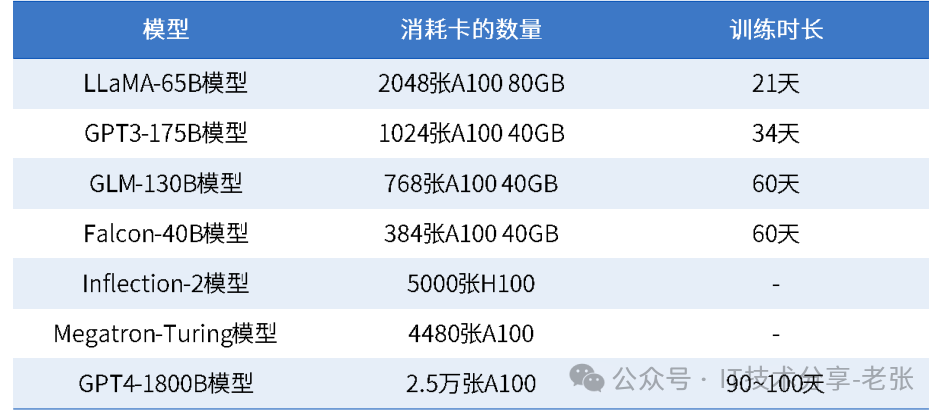

二、根据AI大模型参数量&时长计算训练所需算力
根据大模型客户的需求计算出所需的算力大小,进而计算出所需GPU的集群规模(卡数),在智算中心整体方案设计时需要进行考虑。公式如下:

1、第一个公式,可以用模型的参数量、Token量和相关系数相乘再除以训练所需时长得出理论的算力需求量,
2、第二个公式,通过算力需求的大小与单卡算力的实际性能表现相除得出GPU的卡数,从而可以推算出GPU服务器的集群规模。
下面举了两个例子,一个是以GPT-3为例,按照30天训练时间、A100的GPU卡进行训练可以得出所需GPU的卡数为865.6张,第二个是以GPT-4为例如果采用A100进行训练,时间100天的话,则大概需要2.3w张。

二、根据AI大模型参数量&Token数据计算推理所需算力
大模型的训练的目的是为了“推理”,推理是大模型落地的核心,很多机构预测未来几年推理市场的规模要逐渐超过训练,目前很多客户大量采购4090的八卡机也是做推理相关的应用。如何根据大模型参数量以及推理所需的token情况计算所需“推理算力”也同样重要,下面是三个公式;

1、公式一:需要先根据模型的访问量、平均提问数量以及每次提问的Token量计算出推理所需的单日总Token数。
2、公式二:根据单日总的Token数和模型参数量以及系数相乘后再除以每天的秒数得出每秒推理是算力需求。
3、公式三:再根据每秒是算力需求和单卡GPU的所能发挥的理论性能相除得出GPU卡的数量。
下面是以ChatGPT的推理为例进行的计算,具体计算后得出推理需要A100的数量约为1万张。

当然以上内容仅供参考,和我们国内实际的训练、推理所用的GPU卡并不相同,现在训练更多的是用H100、H200,推理更多的是用4090等,我们需要结合实际情况进行计算评估。
如果你也行想获取《2024年中国智能算力行业白皮书》资料,需要先关注公众号“IT技术分享-老张”后,并在信息栏的聊天框里输入“20241101”,可自动获得资料的百度网盘下载链接!
—-老张会持续通过公众号分享前沿IT技术,创作不易,大家多多点赞和关注!