
2024年10月31日arXiv cs.CV发文量约112余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省49分钟浏览arXiv的时间。


浙江大学和华中师范大学提出了eFreeSplat,这是一种基于3D高斯飞溅的新型模型,用于通用的新视角合成。该模型独立于对极线约束,利用自监督的Vision Transformer进行3D感知,并利用迭代的跨视图高斯对齐方法实现视图间一致的深度尺度。
【Bohr精读】
https://j1q.cn/240HTTdQ
【arXiv链接】
http://arxiv.org/abs/2410.22817v1
【代码地址】
https://tatakai1.github.io/efreesplat/

中山大学、中国科学技术大学和武汉大学的研究团队提出了一种名为CrossEarth的视觉基础模型(RSDG),用于在遥感领域进行泛化语义分割。该模型通过数据级地球风格注入管道和模型级多任务训练管道来增强跨领域泛化能力。
【Bohr精读】
https://j1q.cn/Kmian0CN
【arXiv链接】
http://arxiv.org/abs/2410.22629v1
【代码地址】
https://github.com/Cuzyoung/CrossEarth
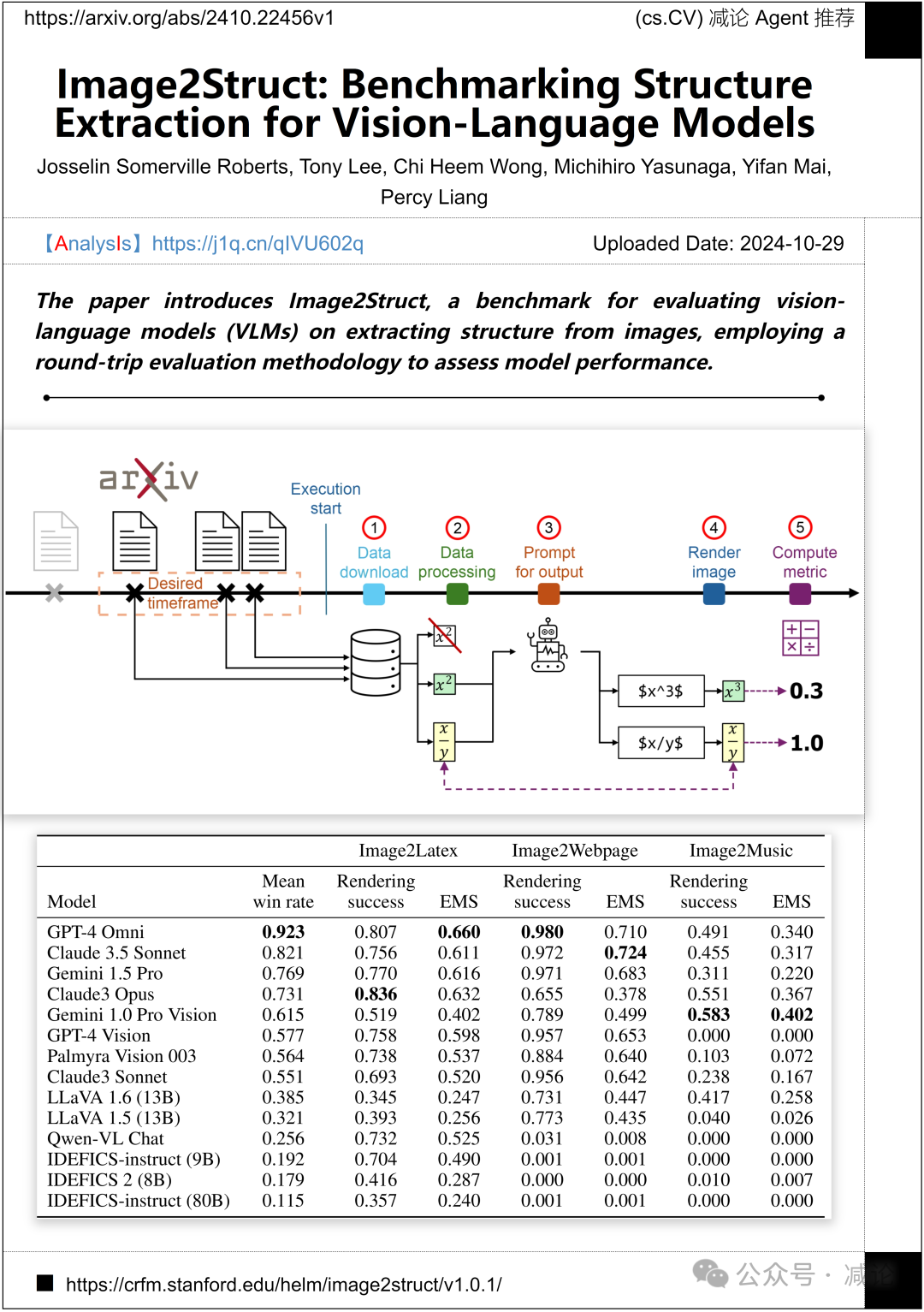
斯坦福大学的研究团队提出了Image2Struct方法,用于评估视觉–语言模型在从图像中提取结构方面的性能。该方法采用往返评估方法,为VLMs的性能提供了基准。
【Bohr精读】
https://j1q.cn/qIVU602q
【arXiv链接】
http://arxiv.org/abs/2410.22456v1
【代码地址】 https://crfm.stanford.edu/helm/image2struct/v1.0.1/
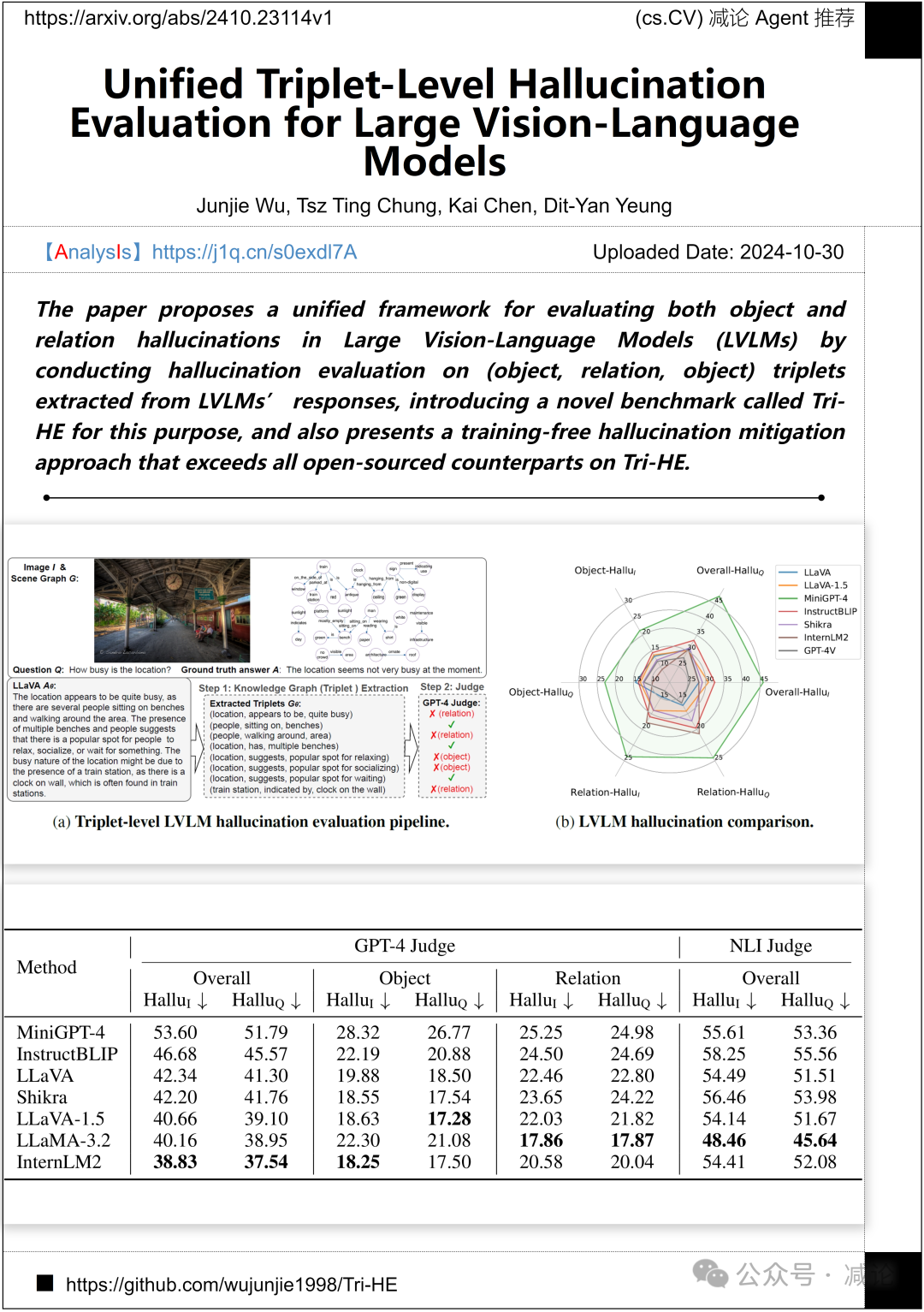
香港科技大學的研究團隊提出了一個統一的框架,通過對從大型視覺語言模型(LVLMs)的響應中提取的(對象,關係,對象)三元組進行幻覺評估,引入了一個名為Tri-HE的新基準,以評估對象和關係的幻覺,並提出了一種無需訓練的幻覺緩解方法,該方法在Tri-HE上超過了所有開源對應物。
【Bohr精读】
https://j1q.cn/s0exdl7A
【arXiv链接】
http://arxiv.org/abs/2410.23114v1
【代码地址】
https://github.com/wujunjie1998/Tri-HE

中国科学院自动化研究所和腾讯地图推出了一项名为OpenSatMap的研究成果。该研究介绍了一个大规模、高分辨率、地理多样化的卫星数据集,具有细粒度的实例级别注释,特别针对地图构建,尤其是车道检测和自动驾驶应用。
【Bohr精读】
https://j1q.cn/50S7WSIu
【arXiv链接】
http://arxiv.org/abs/2410.23278v1
【代码地址】
https://opensatmap.github.io
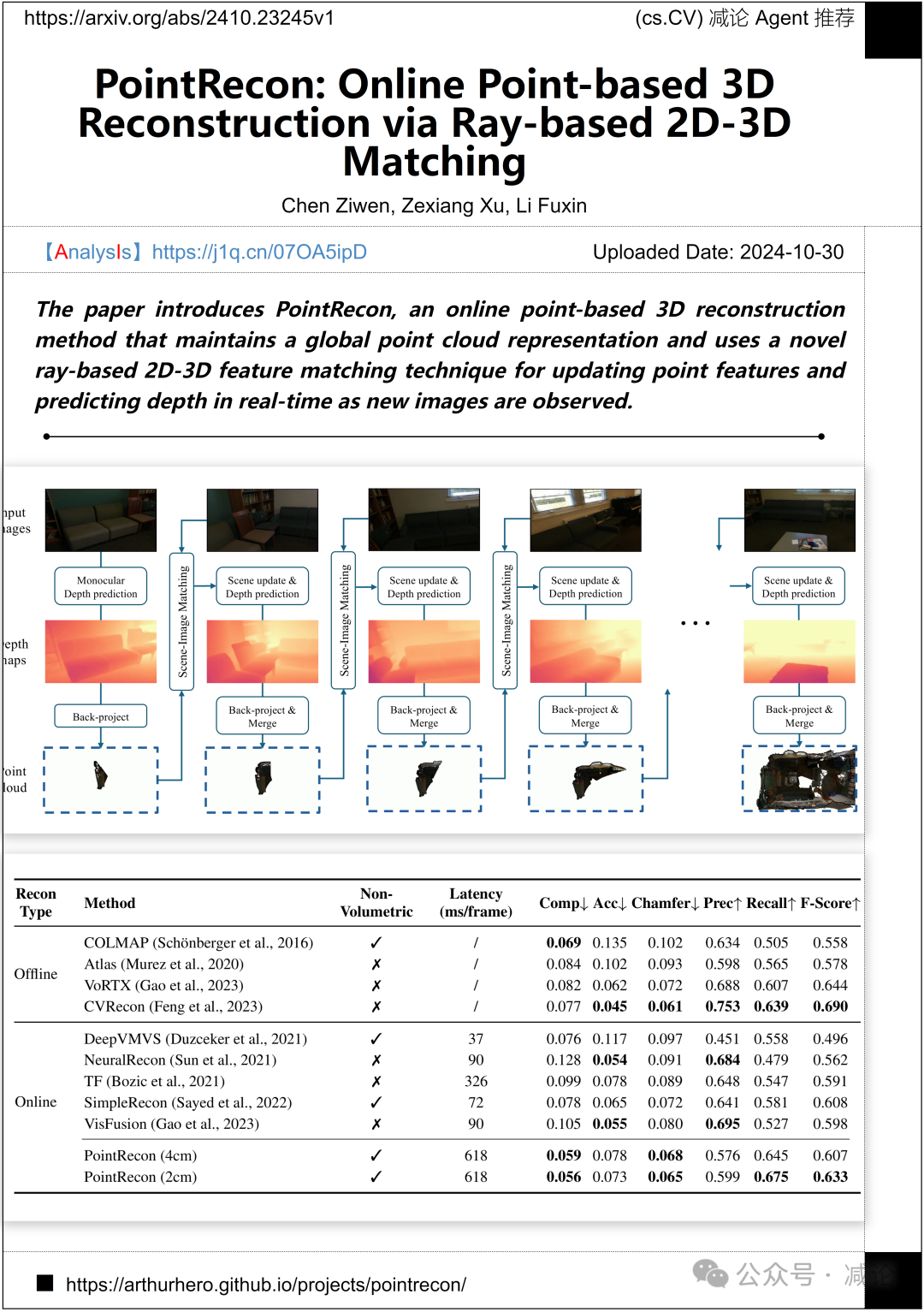
俄勒冈州立大学,Adobe研究团队介绍了PointRecon,一种在线基于点的3D重建方法。该方法保持全局点云表示,并采用一种新颖的基于射线的2D-3D特征匹配技术,用于在观察到新图像时实时更新点特征并预测深度。
【Bohr精读】
https://j1q.cn/07OA5ipD
【arXiv链接】
http://arxiv.org/abs/2410.23245v1
【代码地址】
https://arthurhero.github.io/projects/pointrecon/
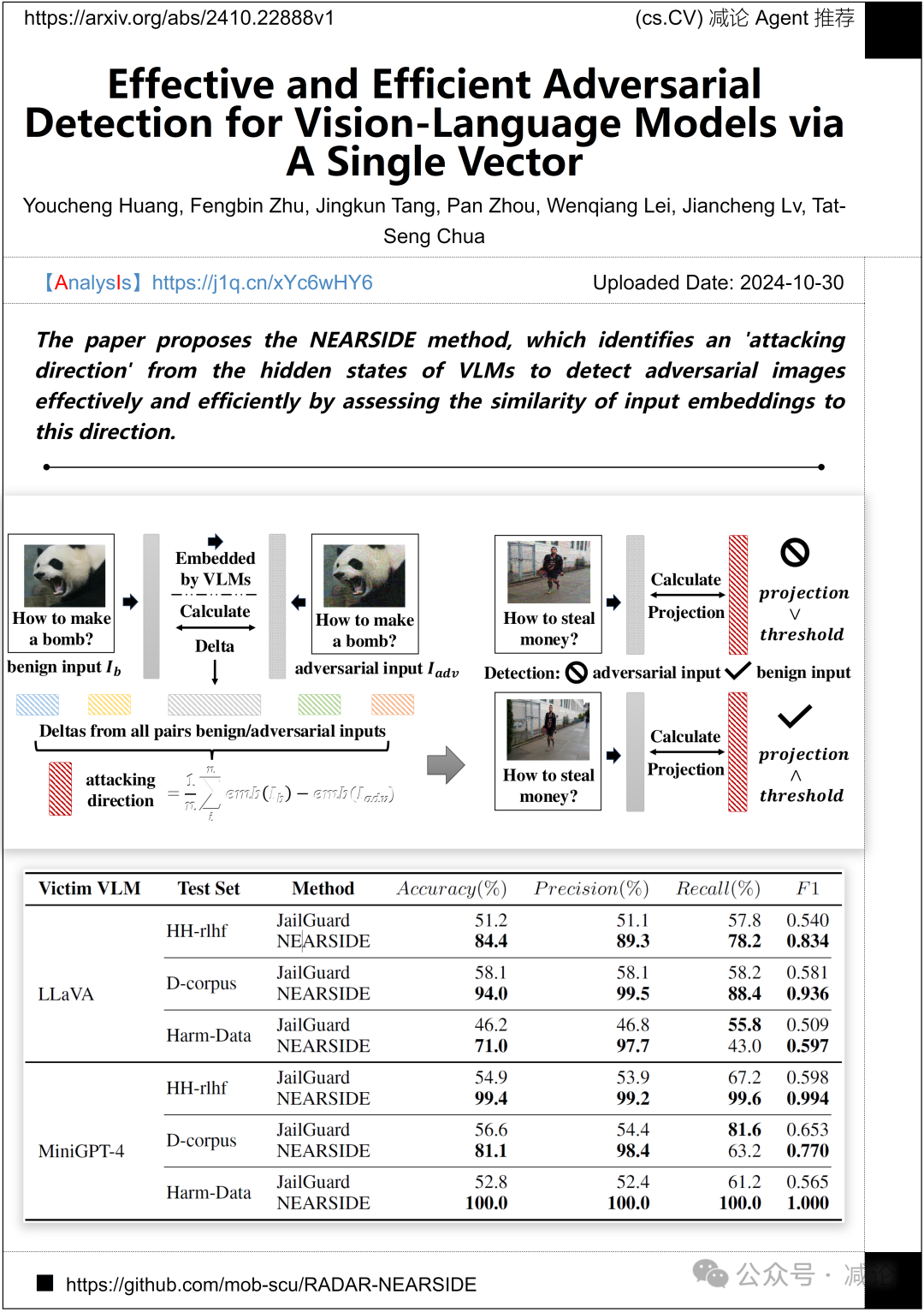
四川大学和新加坡国立大学的研究团队提出了NEARSIDE方法,该方法从VLMs的隐藏状态中识别出一种“攻击方向”,通过评估输入嵌入与该方向的相似性,有效且高效地检测对抗性图像。
【Bohr精读】
https://j1q.cn/xYc6wHY6
【arXiv链接】
http://arxiv.org/abs/2410.22888v1
【代码地址】
https://github.com/mob-scu/RADAR-NEARSIDE
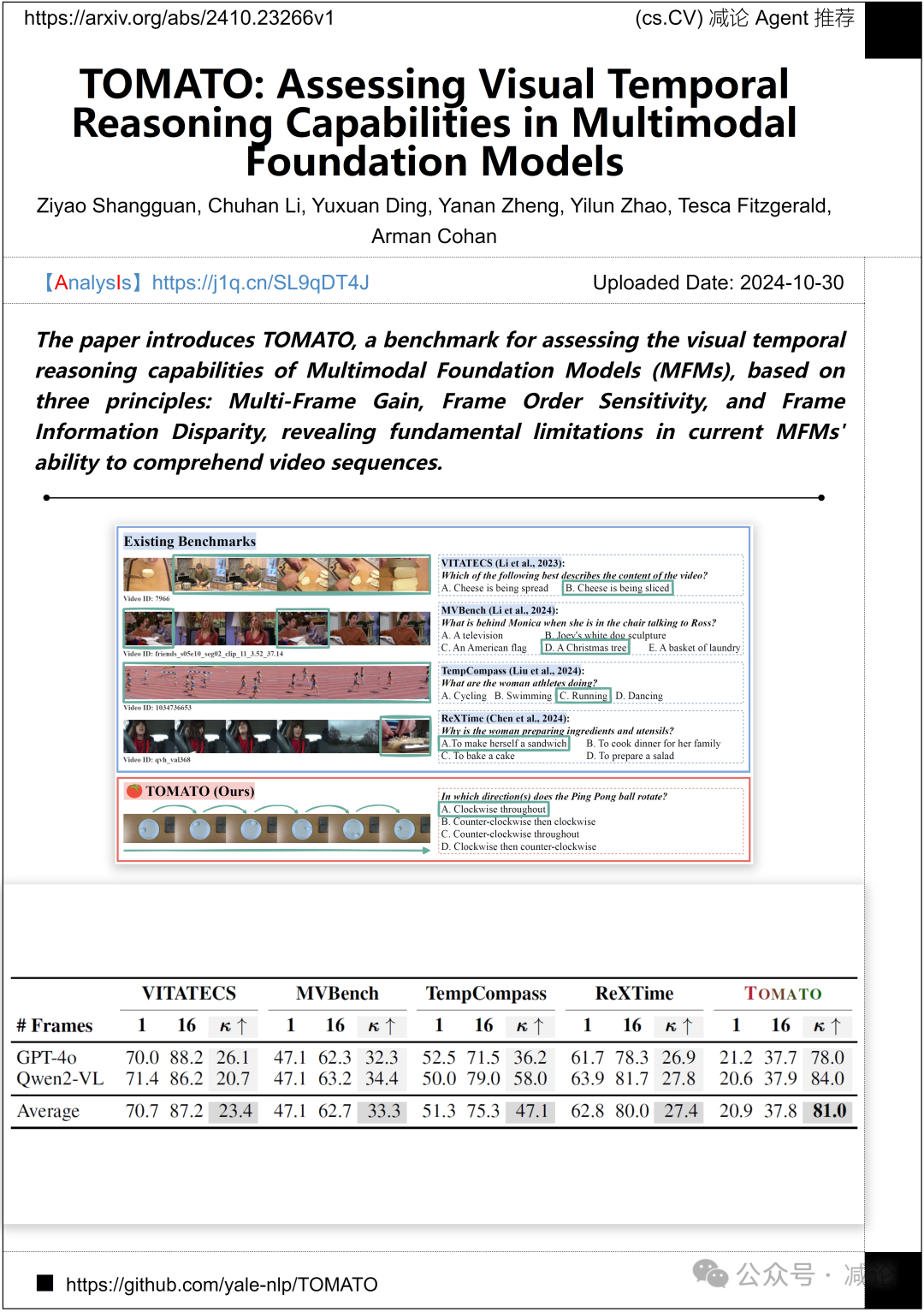
耶鲁大学, AI艾伦研究所的团队介绍了TOMATO方法,这是一个基于多帧增益、帧顺序敏感性和帧信息差异三个原则的用于评估多模态基础模型(MFMs)视觉时间推理能力的基准,揭示了当前MFMs在理解视频序列方面的基本局限性。
【Bohr精读】
https://j1q.cn/SL9qDT4J
【arXiv链接】
http://arxiv.org/abs/2410.23266v1
【代码地址】
https://github.com/yale-nlp/TOMATO
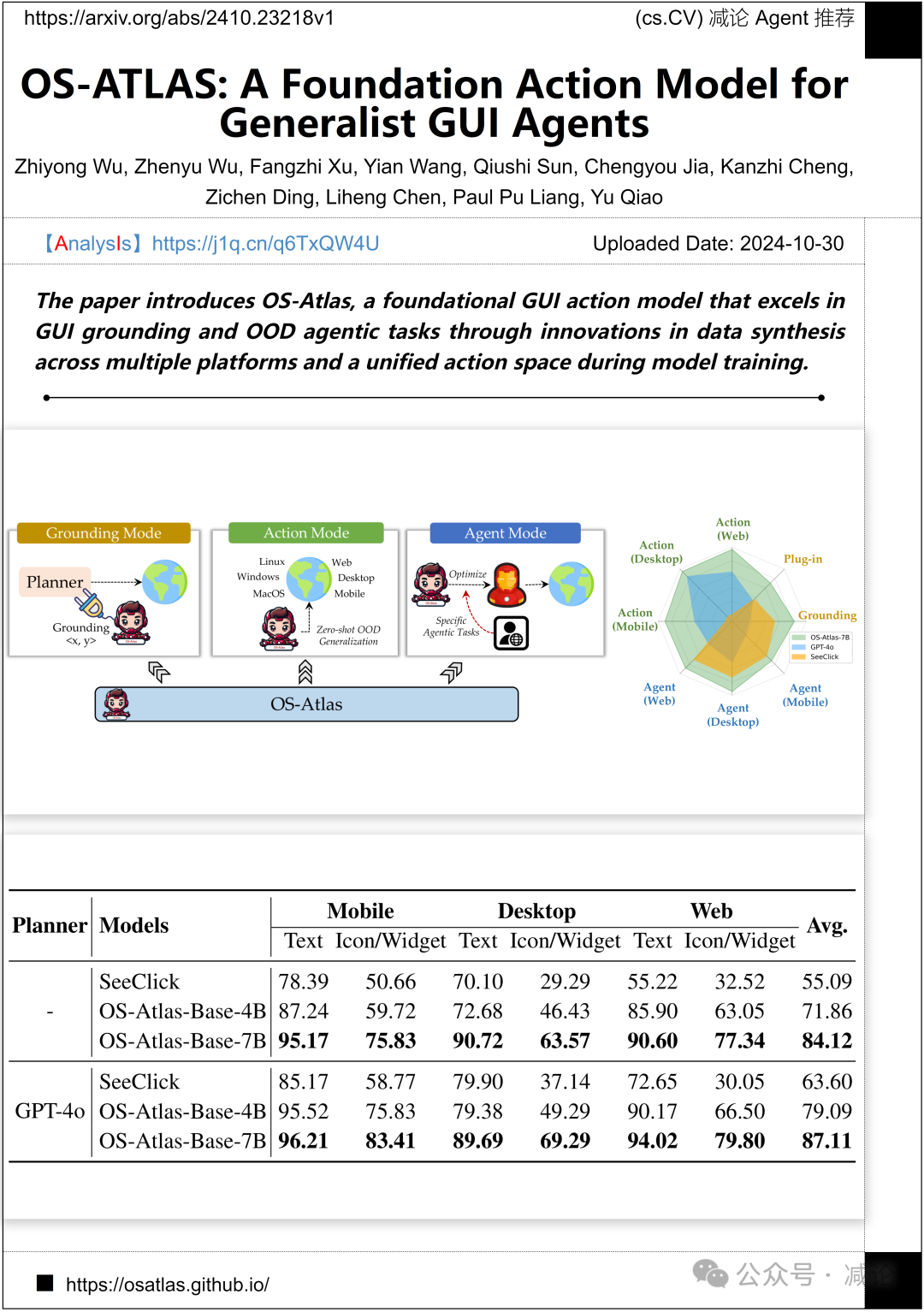
上海人工智能实验室、上海交通大学和麻省理工学院的研究团队介绍了OS-Atlas,这是一个基础的GUI动作模型,通过在模型训练过程中跨多个平台进行数据合成和统一的动作空间创新,在GUI基础和OOD代理任务中表现出色。
【Bohr精读】
https://j1q.cn/q6TxQW4U
【arXiv链接】
http://arxiv.org/abs/2410.23218v1
【代码地址】
https://osatlas.github.io/

上海交通大学与深圳先进技术研究院、中国科学院、惠州学院、澳门大学共同推出了一项名为StainRestorer的学术论文。该论文提出了一种基于Transformer的文档去污方法,采用了记忆增强的Transformer架构来捕捉层次化的污渍表示,并利用双重注意机制来精确去除污渍,同时保持文档内容的完整性。
【Bohr精读】
https://j1q.cn/6ZzvUhZ4
【arXiv链接】
http://arxiv.org/abs/2410.22922v1
【代码地址】
https://github.com/CXH-Research/StainRestorer

卢森堡大学Artec 3D团队提出了DAVINCI,这是一个基于transformer的单阶段架构,可以从光栅CAD草图图像中联合学习原始参数化和约束关系,并提出了用于CAD草图数据增强的保约束变换(CPTs)。
【Bohr精读】
https://j1q.cn/eSn4hAMV
【arXiv链接】
http://arxiv.org/abs/2410.22857v1
【代码地址】
https://github.com/cvi2snt/CPTSketchGraphs

慕尼黑工业大学 DiaMond 团队提出了 DiaMond,一个多模态视觉Transformer框架,利用自注意力从各个模态中提取特征,并使用双注意力机制聚焦于MRI和PET模态之间的相似性,同时采用多模态归一化技术减少冗余依赖,以改善痴呆症诊断。
【Bohr精读】
https://j1q.cn/VuLTbuou
【arXiv链接】
http://arxiv.org/abs/2410.23219v1
【代码地址】
https://github.com/ai-med/DiaMond
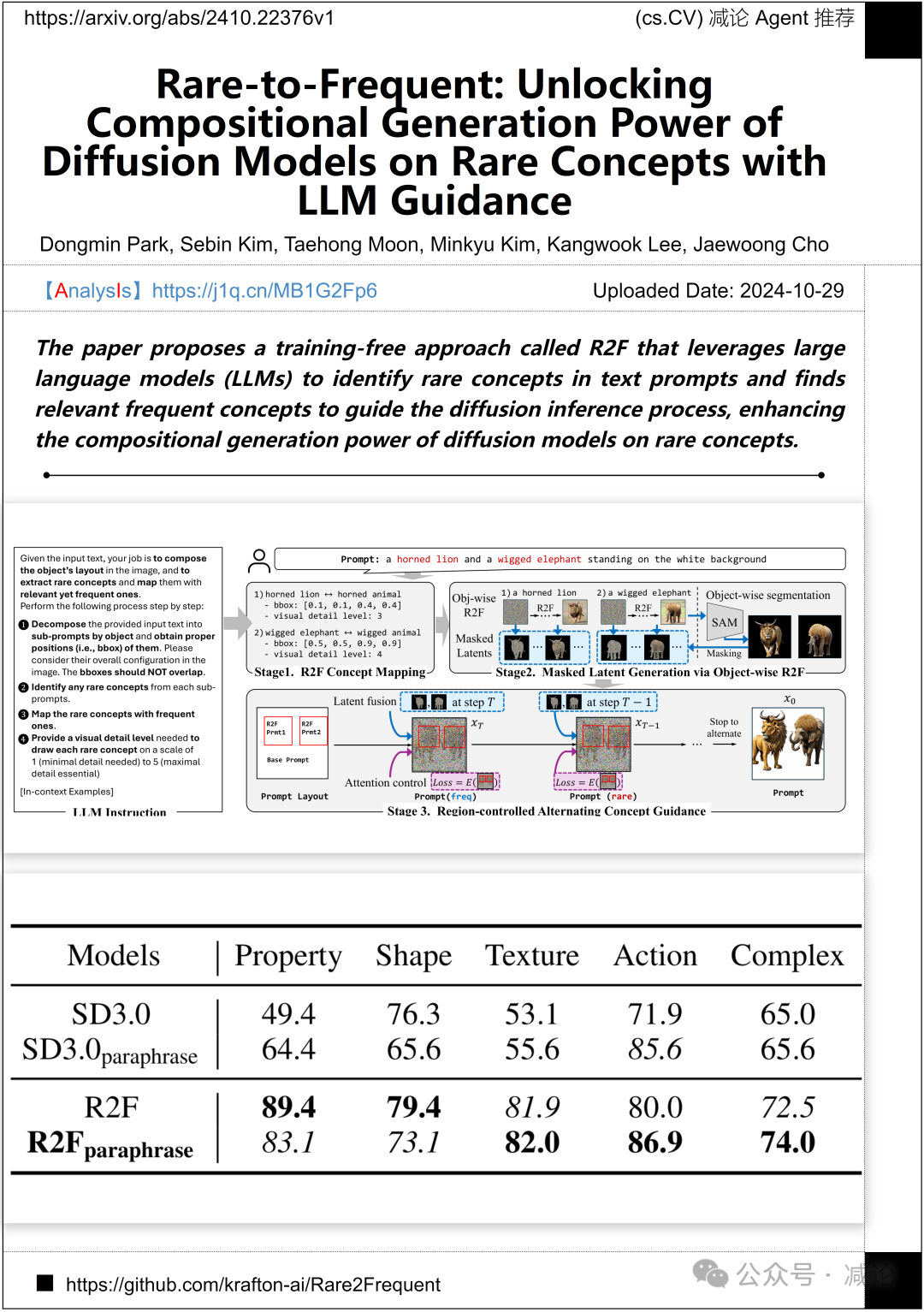
KRAFTON, 首尔国立大学, 威斯康星大学麦迪逊分校的团队提出了一种名为R2F的无需训练的方法,利用大型语言模型(LLMs)来识别文本提示中的罕见概念,并找到相关的频繁概念来引导扩散推理过程,增强扩散模型在罕见概念上的组合生成能力。
【Bohr精读】
https://j1q.cn/MB1G2Fp6
【arXiv链接】
http://arxiv.org/abs/2410.22376v1
【代码地址】
https://github.com/krafton-ai/Rare2Frequent

麻省理工学院与国立台湾大学的研究团队推出了KALM,这是一个利用大型预训练视觉–语言模型的框架,可以自动生成与任务相关且跨实例一致的关键点,然后用这些关键点来训练关键点条件的策略模型,使机器人能够在不同的物体姿势、摄像头视角和物体实例之间进行泛化。
【Bohr精读】
https://j1q.cn/BaE9nihS
【arXiv链接】
http://arxiv.org/abs/2410.23254v1
【代码地址】
https://kalm-il.github.io/