
“Hierarchical Reinforced Trader (HRT): A Bi-Level Approach for Optimizing Stock Selection and Execution”


现代投资组合理论(MPT)通过计算预期收益和协方差矩阵来优化投资组合,旨在最大化收益或最小化风险,但实施复杂。深度强化学习(DRL)在自动化股票交易中展现出潜力,但面临维度诅咒、交易动作惯性和投资组合多样性不足等挑战。
本文提出一种新策略:分层强化交易者(HRT),采用双层分层强化学习框架。HRT结合基于近端策略优化(PPO)的高层控制器(HLC)进行股票选择,和基于深度确定性策略梯度(DDPG)的低层控制器(LLC)优化交易执行。
HRT在2021和2022年表现优于DDPG和PPO模型,2021年Sharpe比率为2.7440,2022年上半年Sharpe比率为0.4132,显示出较低的回撤和良好的风险管理。

论文地址:https://arxiv.org/pdf/2410.14927
摘要
深度强化学习(DRL)在自动化股票交易中展现出潜力,但面临维度诅咒、交易动作惯性和投资组合多样性不足等挑战。本文提出一种新策略:分层强化交易者(HRT),采用双层分层强化学习框架。
HRT结合基于近端策略优化(PPO)的高层控制器(HLC)进行股票选择,和基于深度确定性策略梯度(DDPG)的低层控制器(LLC)优化交易执行。实证分析显示,HRT在牛市和熊市条件下的夏普比率高于单一DRL模型和标准普尔500基准。
本方法有效应对了维度诅咒、交易动作惯性和投资组合多样性不足等挑战,为复杂市场中的盈利和稳健交易算法设计提供了新思路。
简介
现代投资组合理论(MPT)通过计算预期收益和协方差矩阵来优化投资组合,旨在最大化收益或最小化风险,但实施复杂。
马尔可夫决策过程(MDP)将股票交易建模为MDP,使用动态规划解决,但在实际市场中状态空间庞大,限制了可扩展性。
深度强化学习(DRL)利用深度神经网络解决MDP的可扩展性问题,Liu等人使用深度确定性策略梯度(DDPG)发现更优交易策略。
DRL存在以下挑战:
- 维度诅咒:随着股票数量增加,计算复杂性和样本效率下降,导致训练不稳定,当前研究多限于少量资产。
- 惯性效应:DRL代理可能重复先前的操作,未必选择当前最优行动,导致交易操作集中。
- 不足的多样化:DRL代理倾向于集中于少数股票,增加特定行业风险,降低风险缓解效果。
本文引入层次强化交易者(HRT),基于层次强化学习(HRL)框架,旨在提升股票交易策略。HRT由两个主要组件构成:
- 高级控制器(HLC):负责股票选择(买、卖、持有)。
- 低级控制器(LLC):优化选定股票的交易量。
HRT在S&P 500上测试,显示出比单独的DDPG和PPO方法更高的夏普比率。本研究首次阐明HRL框架与DRL代理结合的有效性。
相关工作
深度强化学习用于交易
深度强化学习(DRL)在股票交易自动化中取得显著进展,能够动态优化并识别复杂非线性模式。研究探索了多种DRL方法,如PPO、A2C、DDPG及其增强版TD3。集成策略表现优于单一DRL代理,扩展DRL以包含乐观或悲观强化学习显示出良好前景。增强状态表示和特征有助于代理更好地理解市场动态。自适应DDPG扩展和情感感知方法提升了模型的鲁棒性。结合情感分析和知识图谱进一步优化算法交易策略。
深度强化学习(DRL)在小规模状态和动作空间问题上表现良好,但在某些复杂问题上训练时间过长或效果不足。层次强化学习(HRL)通过将大问题分解为小子问题,采用高层和低层策略来优化决策。
HRL在交易领域的研究有限,但已有一些进展:Wang等人开发了一个层次化股票交易系统,高层策略负责资产配置,低层策略优化短期交易以降低成本。还存在针对高频交易和配对交易的HRL系统。
方法
概览
HRT(Hierarchical Reinforced Trader)代理通过层次强化学习(HRL)改进算法交易,分为高层控制器(HLC)和低层控制器(LLC)。HLC负责分析市场状况,决定买、卖或持有,并选择股票,采用近端策略优化(PPO)以处理离散动作空间。LLC根据HLC的策略,确定具体交易股数,使用深度确定性策略梯度(DDPG)处理连续动作空间,确保交易执行的稳定性。HLC与LLC协同工作,目标是最大化长期投资组合表现,HLC的决策影响LLC的操作,LLC的交易结果反馈给HLC。
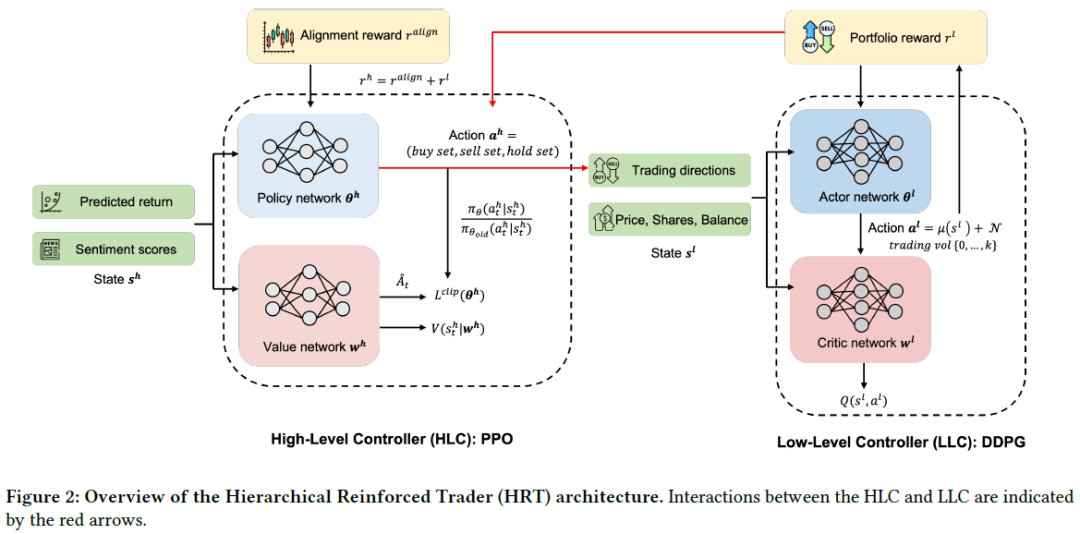
高层控制器(HLC)负责股票选择,通过分析预测的前向收益和情绪分数来决定买卖或持有的股票。
状态空间:由预测的前向收益(历史价格和交易量)和情绪分数(来自新闻或社交媒体)组成,经过交叉验证以提高准确性。
动作空间:HLC对每只股票的动作为买入(1)、卖出(-1)或持有(0),总动作空间为3^N(N为交易股票总数)。
奖励机制:结合实际价格变动和低层控制器(LLC)的反馈,使用sgn函数评估动作与实际收益的对齐程度,奖励机制包括对齐奖励和LLC奖励的线性组合。
奖励权重α初始权重接近1,随着时间推移逐渐减小,强调LLC的奖励。
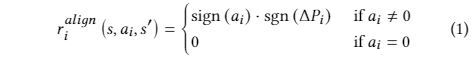
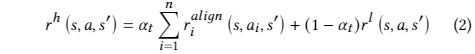
算法选择:采用近端策略优化(PPO)算法,限制策略更新以防止性能下降,使用剪切机制确保训练稳定性。

输出:经过训练后,HLC确定买卖或持有的股票子集,并将信息传递给LLC以优化交易量。
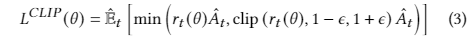
低级控制器用于执行交易
HLC决定买卖股票,LLC优化交易数量??,持有股票时不需LLC介入。
状态空间:状态空间????包括股票价格????、持股????、现金余额????及HLC的决策????。
动作空间:单只股票的动作空间为{0, 1, …, ??},??≤?max,归一化为[-1, 1]以简化多股票交易建模。
奖励函数:奖励????(??, ??, ??′)基于交易后组合价值变化,组合价值为??????+??。
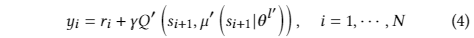
DDPG框架:LLC使用DDPG,每个时间步执行动作??,获得奖励??,存储交易记录以更新??值。
损失函数:通过最小化损失函数??(????)更新评论网络,计算目标与实际网络的差异。

算法实现:训练后得到连续向量,经过缩放和四舍五入确定买卖持有的具体动作。

HLC和LLC联合训练
本文提出分阶段交替训练方法,先优化高层控制器(HLC),再训练低层控制器(LLC),确保策略与执行一致。HLC的准确交易方向对投资组合表现至关重要,错误方向会影响LLC的交易量优化效果。HLC的训练为LLC的有效执行奠定基础,二者通过反馈循环相互学习,提升整体效能。将LLC的奖励动态整合进HLC训练,利用线性组合与指数衰减,促进战略决策与执行能力的统一。

表现评估 股票数据预处理
研究对象为S&P 500,确保流动性并作为美国市场表现基准。训练期为2015年1月1日至2019年12月31日,验证期为2020年。2021年市场看涨,受经济复苏和美联储支持驱动;2022年市场看跌,因通胀、货币政策收紧和地缘政治紧张。模型在2021年和2022年不同市场条件下进行交易测试。数据来源于Yahoo Finance,包括OHLCV数据,日均成交量加权价(VWAP)由此得出。
高级控制器(HLC)状态空间通过计算股票日收益率,使用Transformer模型的编码器部分,连接到线性层。采用监督学习,使用Qlib提供的158个特征,设置10个交易日的回溯窗口。情感分析使用微调的FinGPT模型,基于LLaMA 2 13B模型进行指令调优。交易执行假设在市场开盘时进行,考虑市场对新闻的过夜反应。情感评分基于前一天24小时新闻的随机样本,评分系统为正面1、中性0、负面-1。
训练步骤
实验使用NVIDIA Tesla V100 GPU和FinRL库,确保与先前工作的可比性和开发效率。PPO-based HLC学习率设为3e-4,剪切参数为0.2;DDPG-based LLC学习率为1e-3,软更新参数??为0.005。两个控制器均使用2e5的重放缓冲区,批量大小256,折扣因子??为0.99,优化器为AdamW,总训练时长约30小时。投资组合初始资本为$1,000,000,交易成本为0.1%,每日再平衡。针对随机性因素,进行了十次独立实验,使用不同随机种子。
评估指标
- 累积收益:总和每日收益,反映总回报。
- 年化收益:计算公式为(1 + 累积收益)? – 1,便于不同时间框架比较。
- 年化波动率:公式为σ? × 252,标准化风险评估。
- 夏普比率:公式为(R? – R?) / σ?,衡量风险调整后的投资表现。
- 最大回撤:从峰值到谷值的最大百分比跌幅,评估投资组合的风险和抗跌能力。
结果
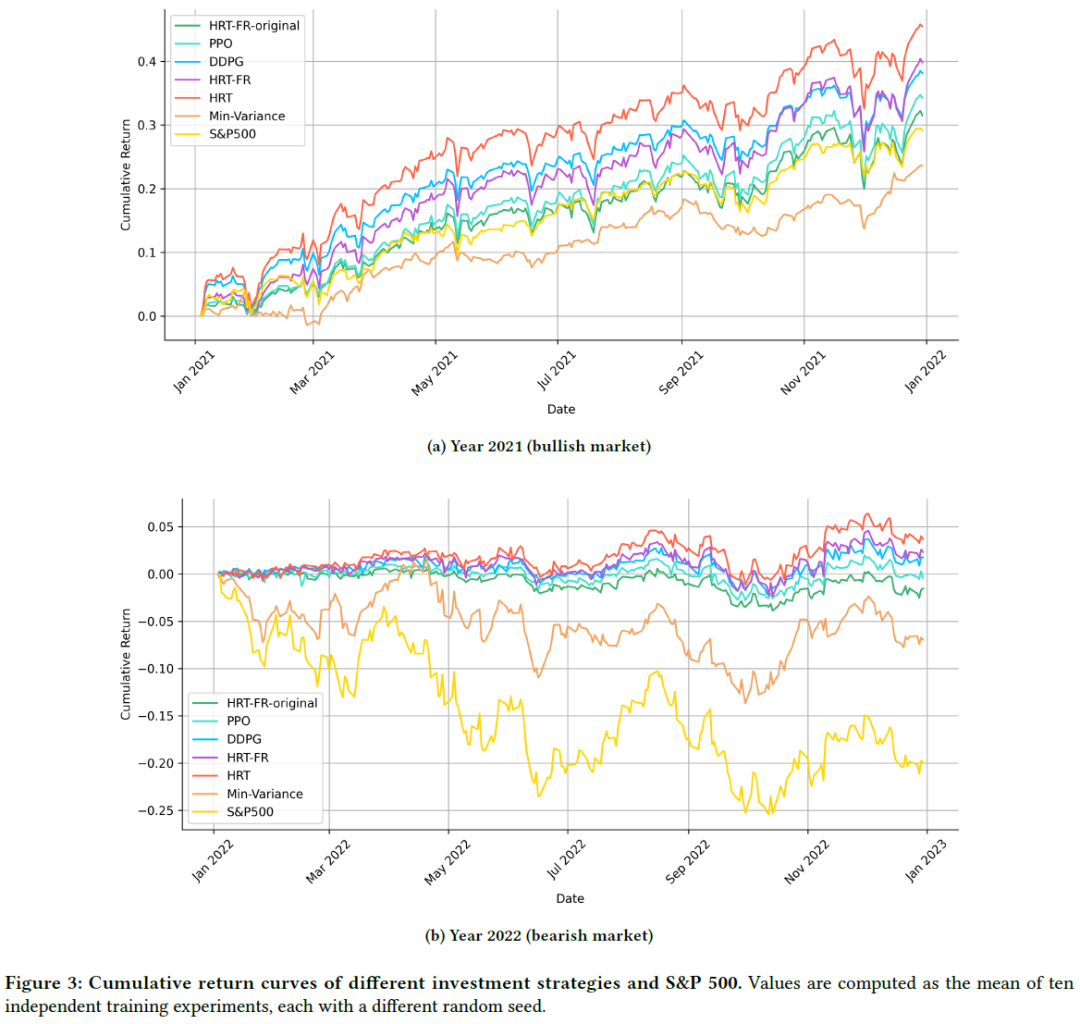
增强交易表现:HRT代理在2021和2022年表现优于DDPG和PPO模型,2021年Sharpe比率为2.7440,2022年上半年Sharpe比率为0.4132,显示出较低的回撤和良好的风险管理。HRT-FR未能超越标准HRT,HRT-FR-original表现最差,未能超越S&P 500。
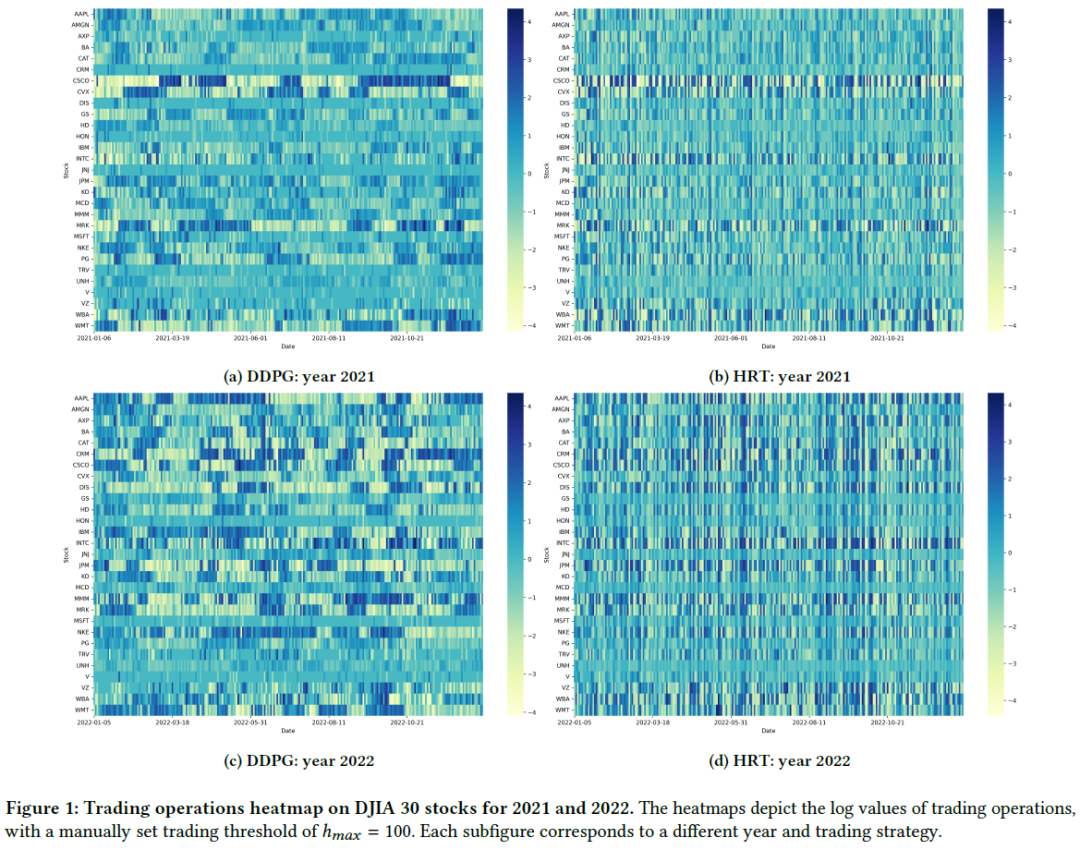
多股票交易中的DRL挑战:HRT通过将动作空间分为高层控制器(HLC)和低层控制器(LLC)来应对多股票交易的复杂性,简化决策过程。HRT在2021和2022年对道琼斯30只股票的交易显示出更频繁和多样化的交易趋势,归因于HLC的最新预测收益和情绪趋势驱动。
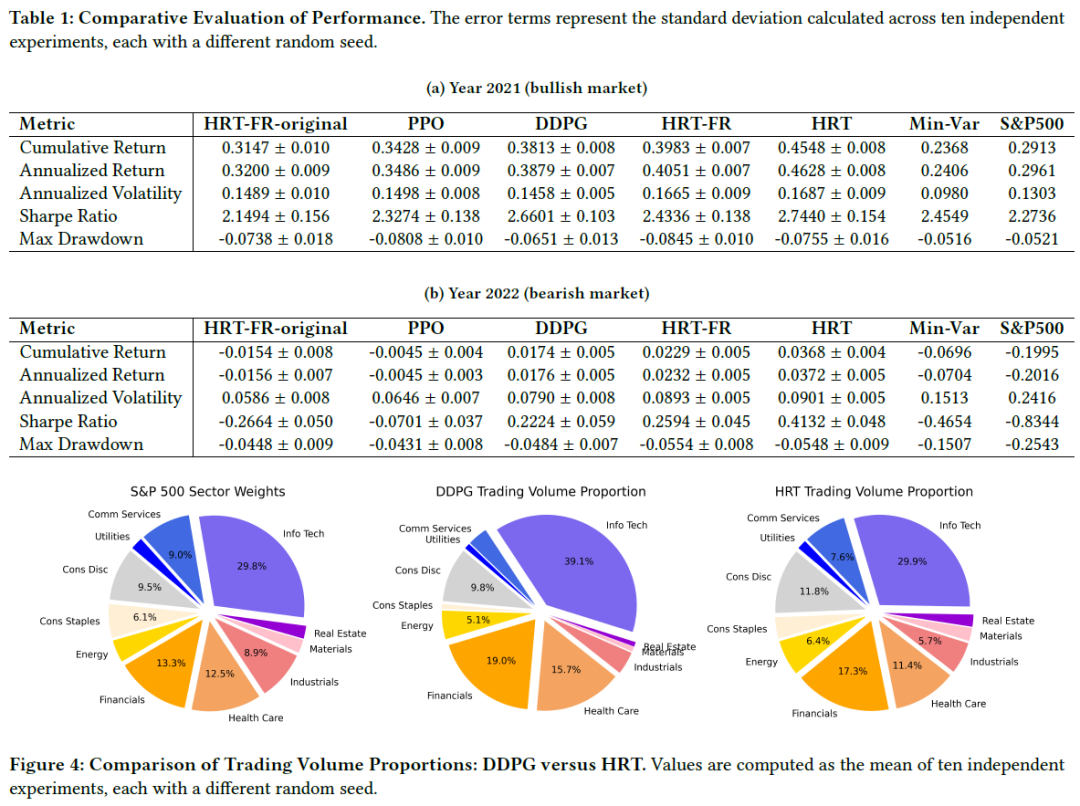
DDPG投资组合在行业交易量上与S&P 500的平均行业权重存在显著偏差,主要集中在信息技术、金融和医疗保健等行业,较少涉及消费品、房地产和公用事业。HRT系统的投资组合虽然也偏向主要行业,但与S&P 500的行业权重更为一致,显示出对市场估值和趋势的遵循。HRT投资组合的行业曝光度与市场分布相符,体现了更好的多样化,且其交易活动的多样性进一步支持了这一点。
总结
本文提出层次强化交易者(HRT)策略,通过高低层控制器提升交易表现。高层控制器(HLC)使用近端策略优化(PPO)选择交易方向,低层控制器(LLC)使用深度确定性策略梯度(DDPG)决定交易股数。引入分阶段交替训练算法,实现两部分的同步训练。
在实际S&P 500数据测试中,HRT代理在各种市场条件下实现正累计收益和强夏普比率,尤其在熊市中表现良好。HRT有助于减少动作和状态的维度,未来可考虑分开买卖动作以进一步缩小动作空间。HRT缓解了惯性或动量效应,增强了交易算法的盈利性和稳健性,适合多股票交易。
未来可将交易过程建模为部分可观测马尔可夫决策过程(POMDP),并研究自适应学习率及最新的深度强化学习模型。
我们致力于提供优质的AI服务,涵盖人工智能、数据分析、深度学习、机器学习、计算机视觉、自然语言处理、语音处理等领域。如有相关需求,请私信与我们联系。