
2024年10月30日arXiv cs.CV发文量约115余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省50分钟浏览arXiv的时间。
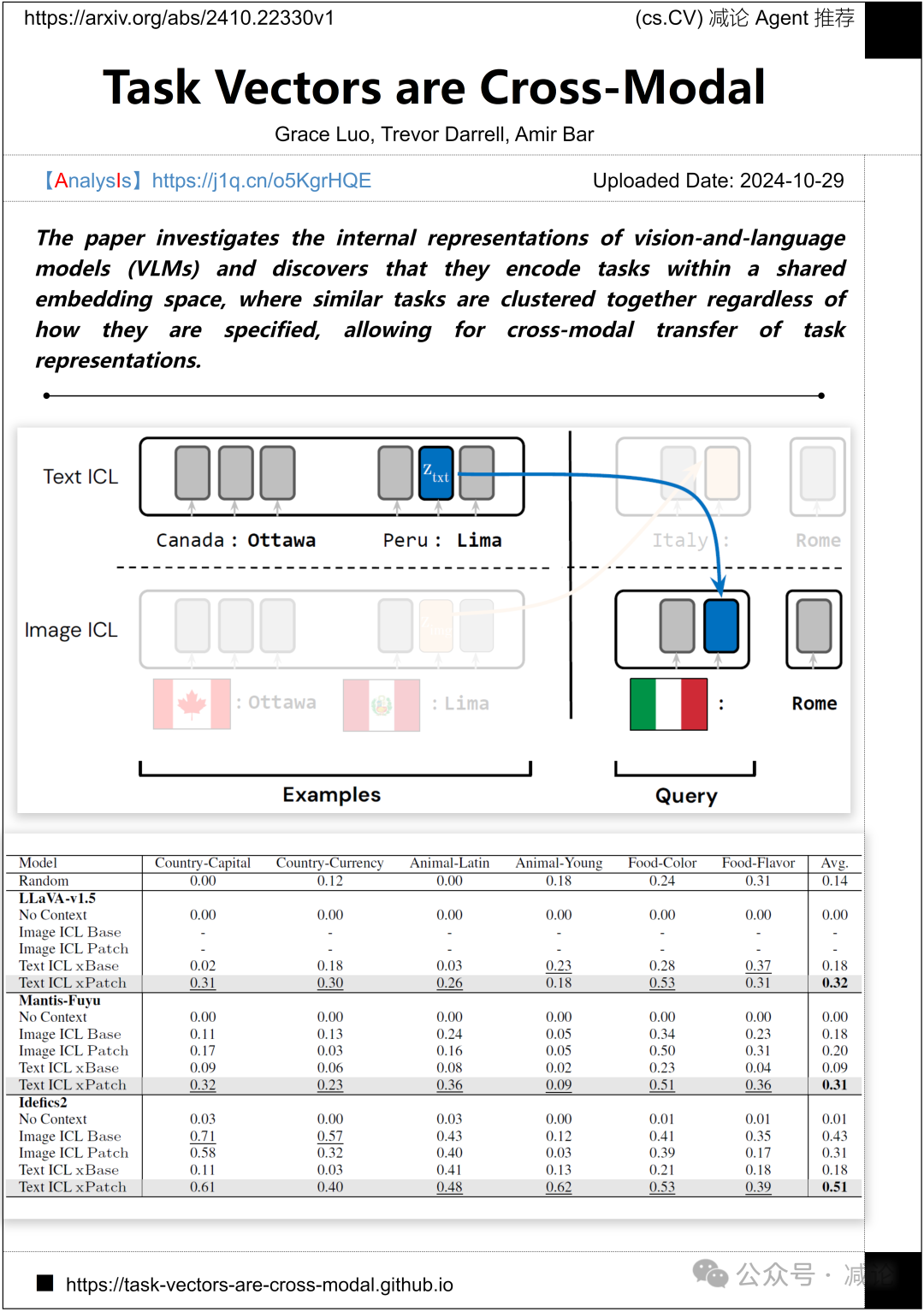

加州大学伯克利分校的研究人员提出了视觉与语言模型(VLMs)的内部表示研究,发现它们在共享嵌入空间中编码任务,无论任务如何被指定,相似的任务被聚集在一起,从而实现任务表示的跨模态转移。
【Bohr文献精读助手】https://j1q.cn/o5KgrHQE
【arXiv原文链接】http://arxiv.org/abs/2410.22330v1
【开源代码地址】https://task-vectors-are-cross-modal.github.io

华中科技大学原点智能团队介绍了一种名为Senna的自主驾驶系统。该系统集成了一个大型视觉语言模型(Senna-VLM)和一个端到端模型(Senna-E2E),用于结构化规划,实现从高层决策到低层轨迹预测的功能。
【Bohr文献精读助手】https://j1q.cn/poiFLlw7
【arXiv原文链接】http://arxiv.org/abs/2410.22313v1
【开源代码地址】https://github.com/hustvl/Senna
哈尔滨工业大学和合肥工业大学的太空人工智能团队提出了一种名为分类器得分匹配(CSM)的新算法。该算法消除了得分蒸馏采样(SDS)中的差异项,并利用确定性噪声添加过程来减少优化过程中的噪音,形成了用于高质量定制3D生成的TV-3DG框架的核心。
【Bohr文献精读助手】https://j1q.cn/nUuEtiD1
【arXiv原文链接】http://arxiv.org/abs/2410.21299v1
【开源代码地址】https://yjhboy.github.io/TV-3DG
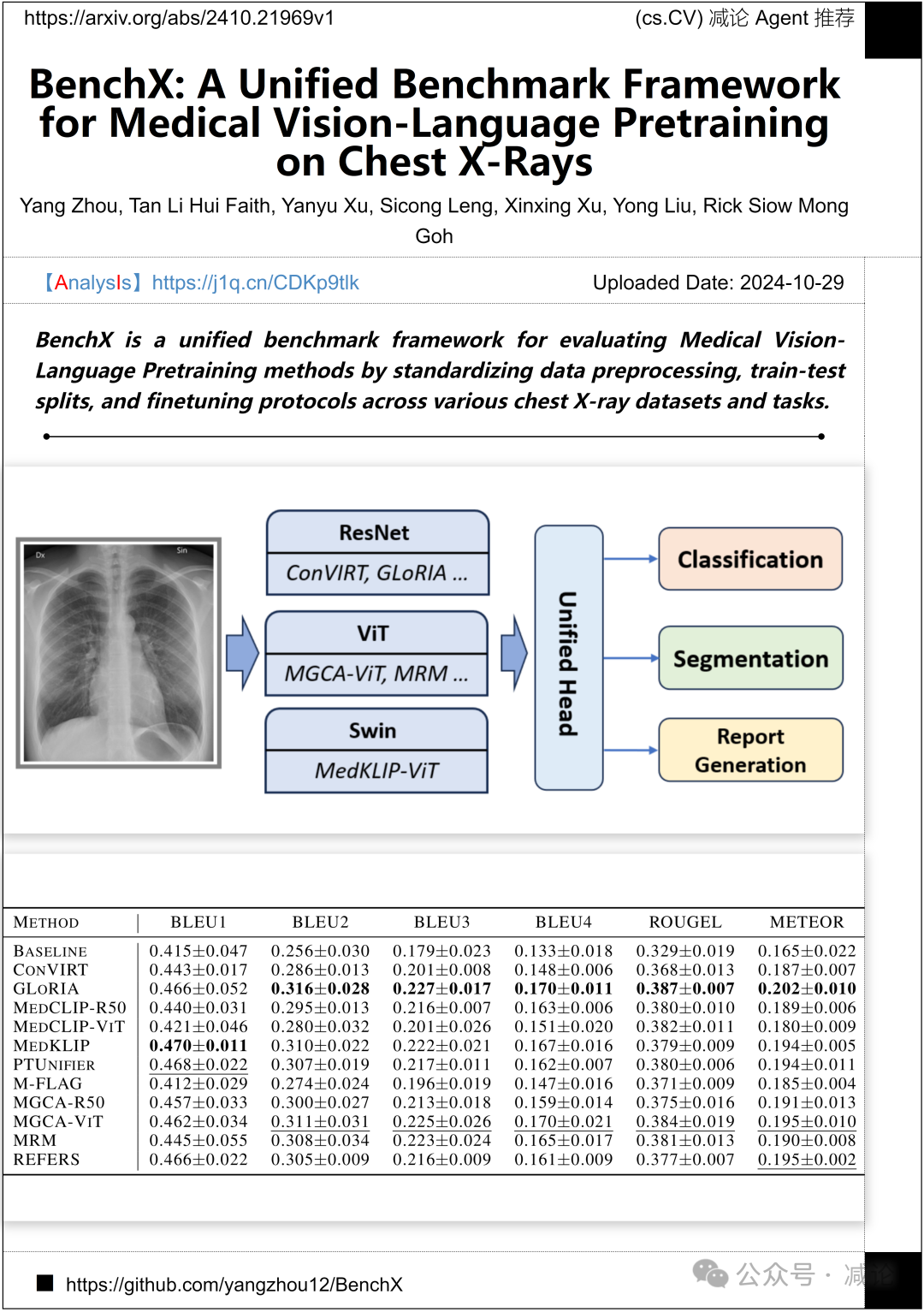
新加坡国立大学高性能计算研究所的研究团队提出了BenchX,这是一个统一的基准框架,通过标准化数据预处理、训练–测试分割和微调协议,评估医学视觉–语言预训练方法在各种胸部X射线数据集和任务上的表现。
【Bohr文献精读助手】https://j1q.cn/CDKp9tlk
【arXiv原文链接】http://arxiv.org/abs/2410.21969v1
【开源代码地址】https://github.com/yangzhou12/BenchX
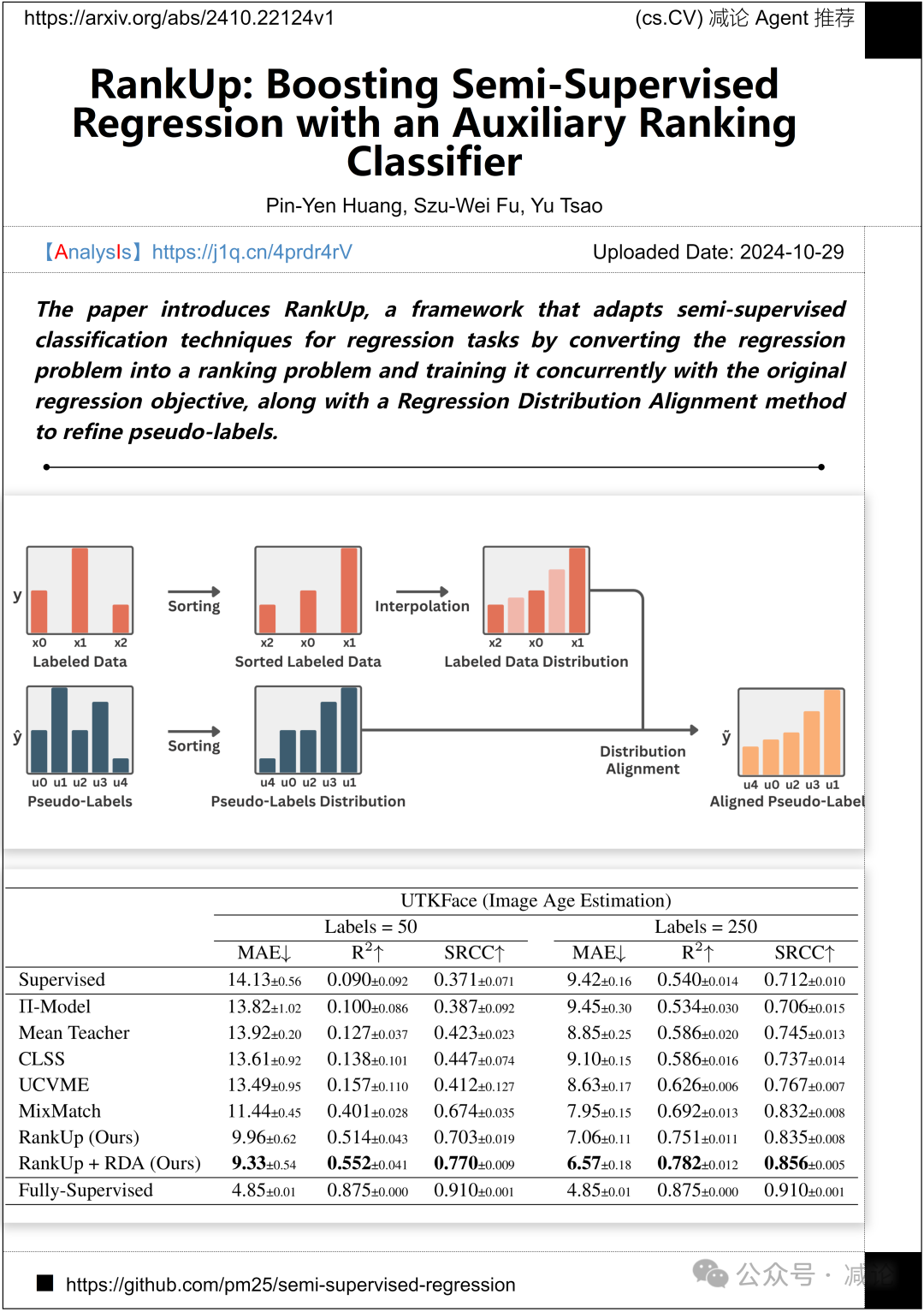
中央研究院和英伟达提出了RankUp,一个框架,通过将回归问题转换为排名问题,并与原始回归目标同时训练,以及一种回归分布对齐方法来改进伪标签,从而为回归任务调整半监督分类技术。
【Bohr文献精读助手】https://j1q.cn/4prdr4rV
【arXiv原文链接】http://arxiv.org/abs/2410.22124v1
【开源代码地址】https://github.com/pm25/semi-supervised-regression

清华大学, 苏黎世联邦理工学院, 深圳大学 提出了 IntLoRA 方法。该方法使用整数低秩参数来调整量化扩散模型,实现高效的微调、存储和推理,同时保持模型性能。
【Bohr文献精读助手】https://j1q.cn/r5xsyEy2
【arXiv原文链接】http://arxiv.org/abs/2410.21759v1
【开源代码地址】https://github.com/csguoh/IntLoRA
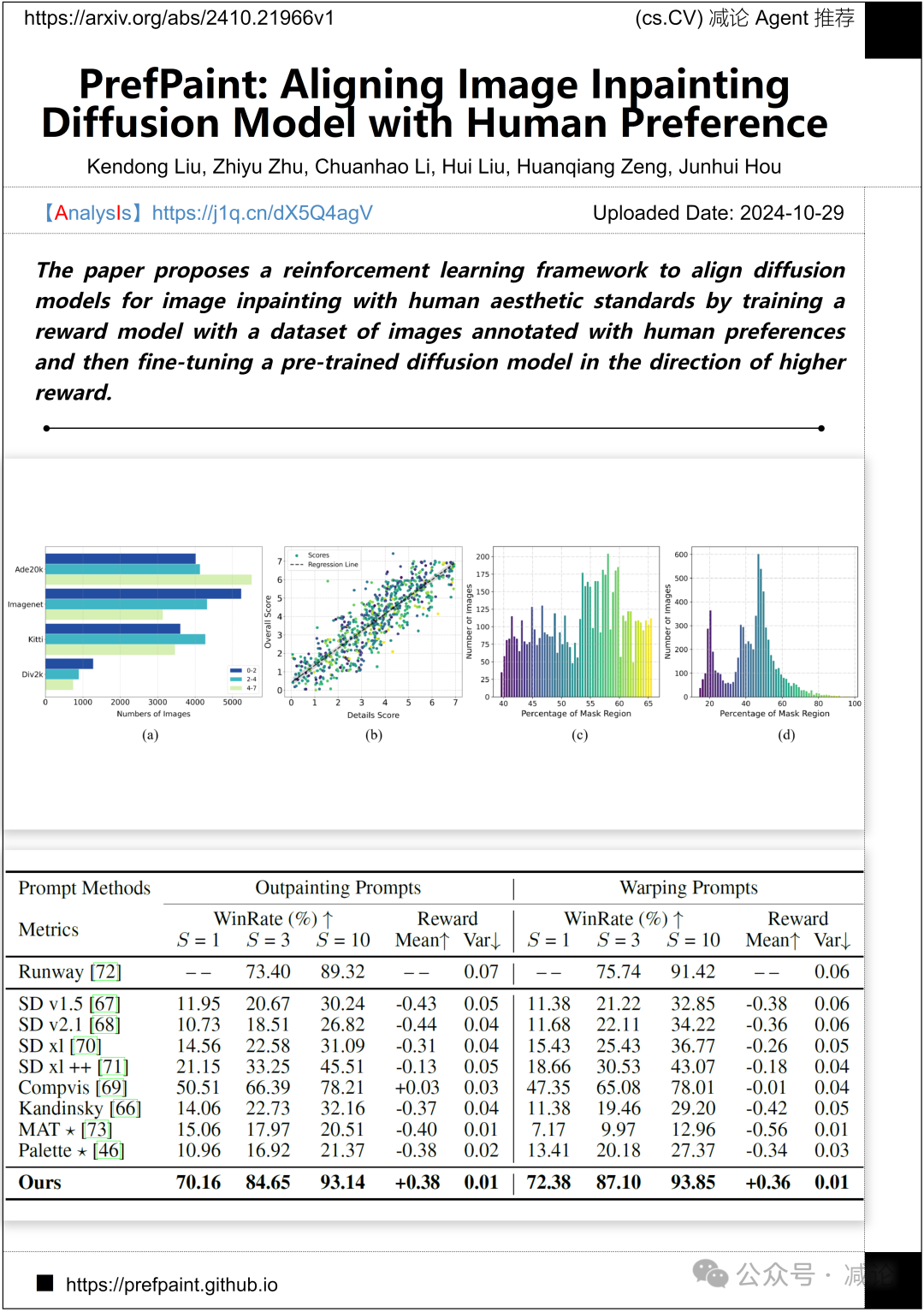
香港城市大學、耶魯大學和華僑大學的研究团队提出了一个强化学习框架,通过训练一个奖励模型,使扩散模型与人类审美标准对齐,然后在更高奖励的方向上微调预训练的扩散模型。
【Bohr文献精读助手】https://j1q.cn/dX5Q4agV
【arXiv原文链接】http://arxiv.org/abs/2410.21966v1
【开源代码地址】https://prefpaint.github.io
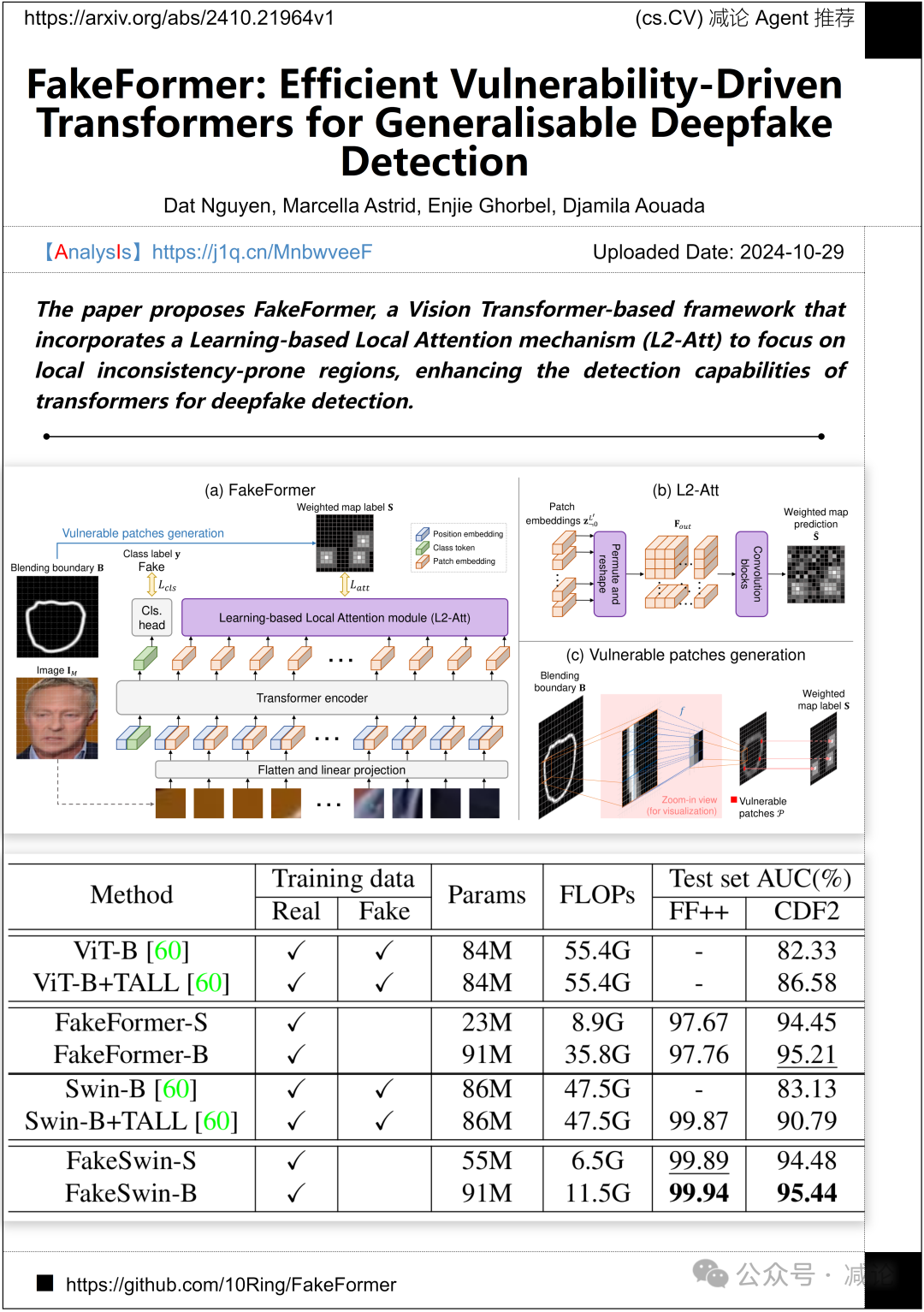
卢森堡大学和突尼斯曼努巴大学的研究团队提出了FakeFormer,这是一个基于Vision Transformer的框架,它结合了一个基于学习的局部注意机制(L2-Att),用于聚焦于局部易出现不一致的区域,增强了transformer在深度伪造检测方面的检测能力。
【Bohr文献精读助手】https://j1q.cn/MnbwveeF
【arXiv原文链接】http://arxiv.org/abs/2410.21964v1
【开源代码地址】https://github.com/10Ring/FakeFormer
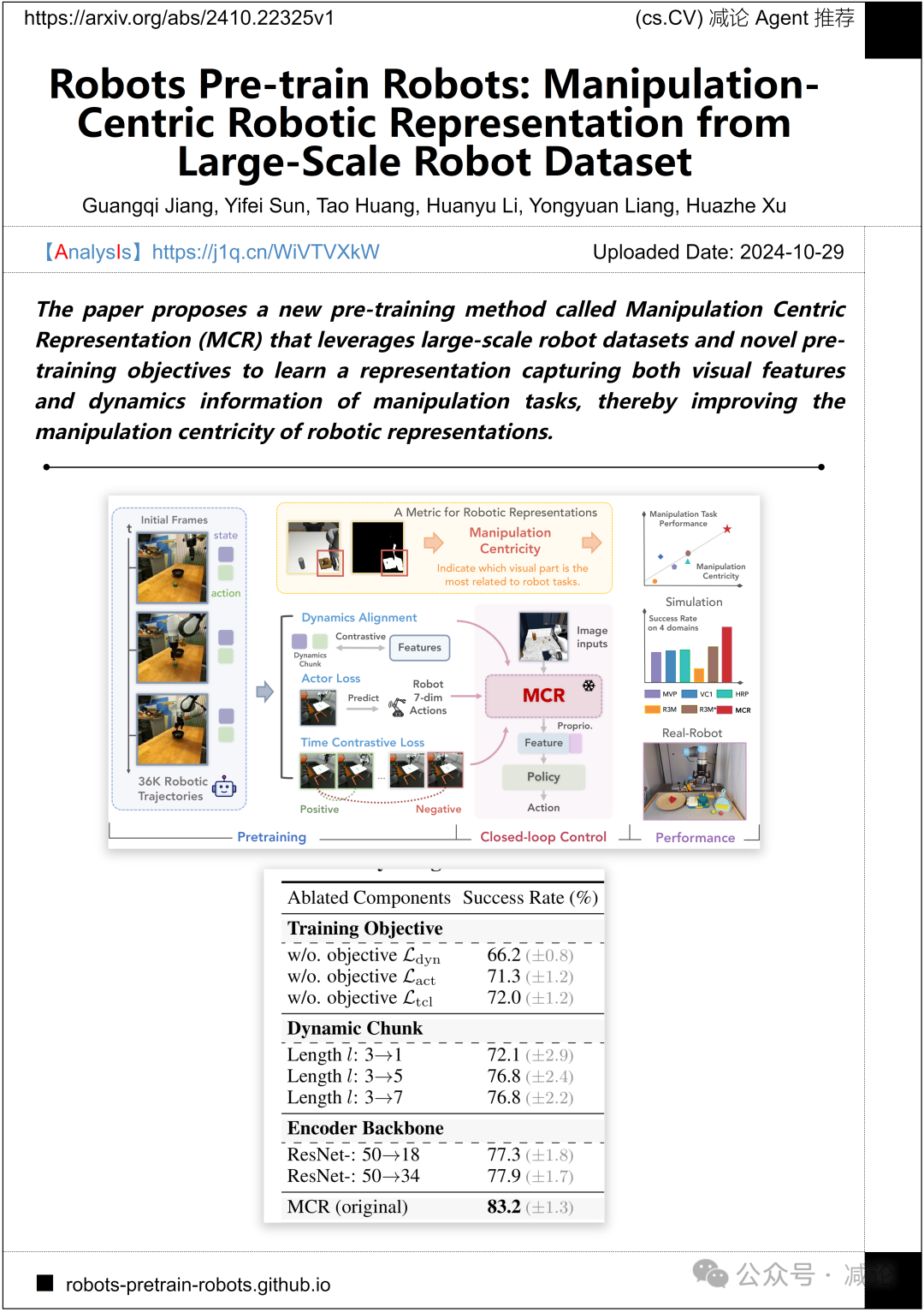
加州大学圣地亚哥分校、同济大学、清华大学的研究团队提出了一种名为操纵中心表示(MCR)的新的预训练方法,利用大规模机器人数据集和新颖的预训练目标,学习捕捉操纵任务的视觉特征和动态信息的表示,从而提高机器人表示的操纵中心性。
【Bohr文献精读助手】https://j1q.cn/WiVTVXkW
【arXiv原文链接】http://arxiv.org/abs/2410.22325v1
【开源代码地址】robots-pretrain-robots.github.io
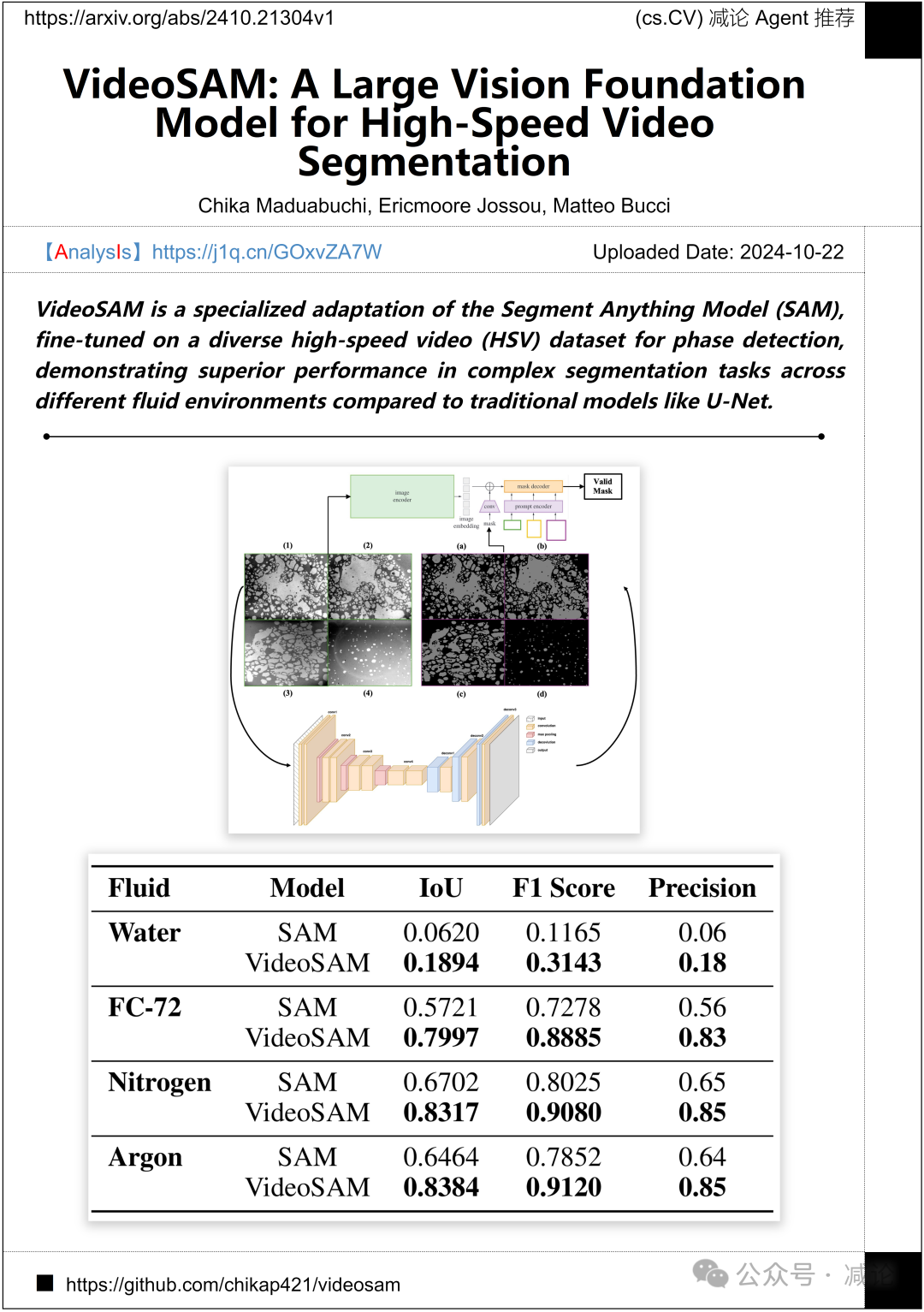
麻省理工学院的研究团队提出了VideoSAM方法,这是对Segment Anything Model (SAM) 进行了专门的调整,经过在多样化的高速视频(HSV)数据集上微调,用于相位检测,在复杂的分割任务中表现出比传统模型如U-Net更优越的性能。
【Bohr文献精读助手】https://j1q.cn/GOxvZA7W
【arXiv原文链接】http://arxiv.org/abs/2410.21304v1
【开源代码地址】https://github.com/chikap421/videosam

河内科技大学,名古屋大学,国立高级工业科学技术研究所的研究团队提出了一种名为CPDM的条件扩散模型,用于将CT转换为PET图像,通过注意力和衰减图来融入领域知识,引导扩散过程并提高生成的PET图像质量。
【Bohr文献精读助手】https://j1q.cn/wSN49N0o
【arXiv原文链接】http://arxiv.org/abs/2410.21932v1
【开源代码地址】https://github.com/thanhhff/CPDM

达姆施塔特工业大学的研究团队提出了NCA-Morph方法,这是一种医学图像配准方法,利用生物启发的神经细胞自动机(NCA)方法,在细胞和体素之间建立局部通信网络,实现比现有方法更少参数的最先进性能。
【Bohr文献精读助手】https://j1q.cn/gYED03Ii
【arXiv原文链接】http://arxiv.org/abs/2410.22265v1
【开源代码地址】https://github.com/MECLabTUDA/NCA-Morph
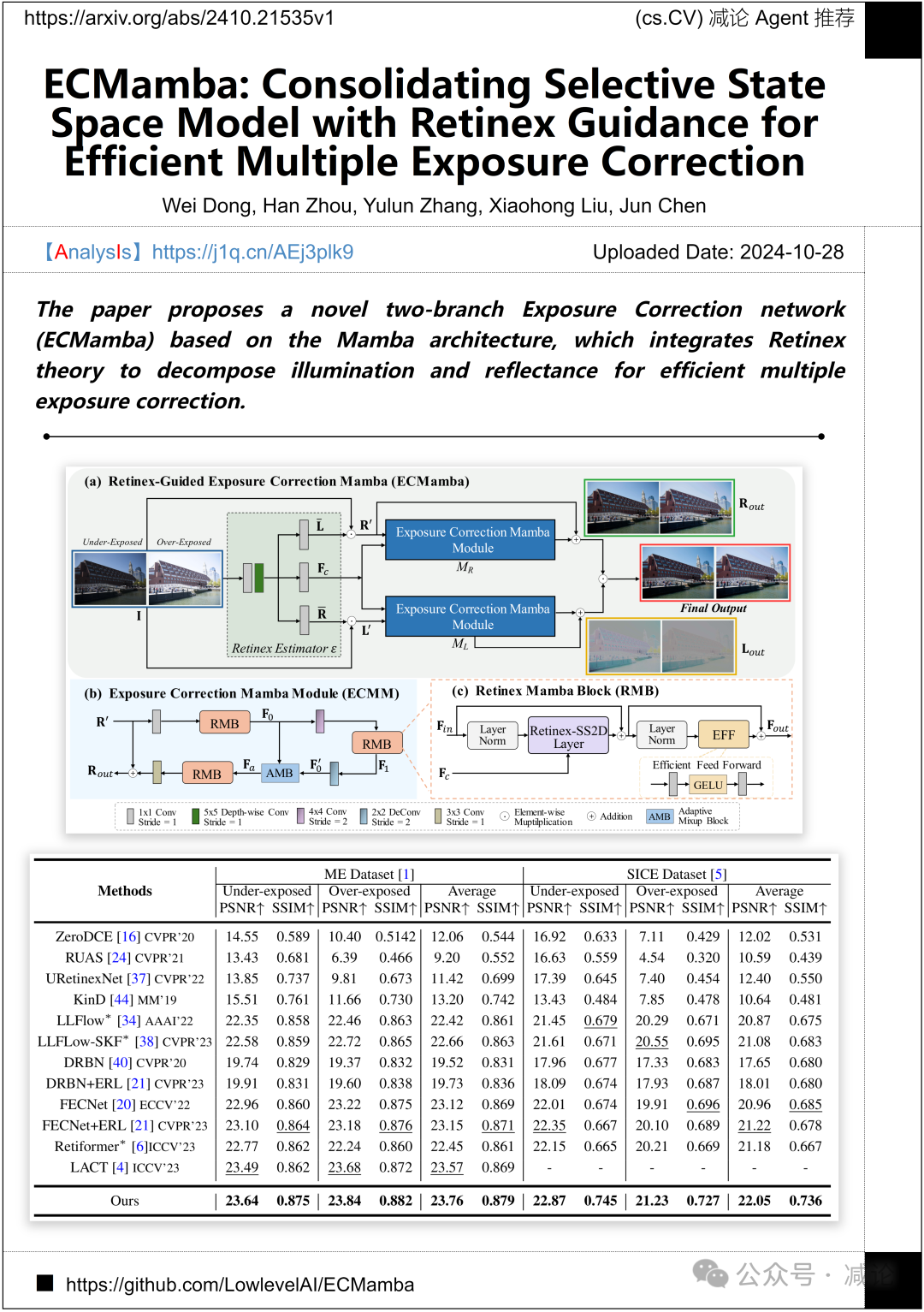
麦克马斯特大学和上海交通大学的研究团队提出了一种基于Mamba架构的新型双分支曝光校正网络(ECMamba),该网络整合了Retinex理论,用于有效地分解照明和反射,实现多曝光校正。
【Bohr文献精读助手】https://j1q.cn/AEj3plk9
【arXiv原文链接】http://arxiv.org/abs/2410.21535v1
【开源代码地址】https://github.com/LowlevelAI/ECMamba

天津理工大学、中国科学院大学的研究团队提出了一种文本引导的注意力零样本鲁棒性(TGA-ZSR)框架,用于增强视觉语言模型(如CLIP)的对抗鲁棒性,并同时保持对干净样本的性能。该框架包括一个注意力细化模块,用于将对抗性注意力图与干净的注意力图对齐,以及一个基于注意力的模型约束模块,用于保持模型在干净图像上的性能。
【Bohr文献精读助手】https://j1q.cn/ieJ4vyc1
【arXiv原文链接】http://arxiv.org/abs/2410.21802v1
【开源代码地址】https://github.com/zhyblue424/TGA-ZSR