
本文来自ray summit 2024上 vllm现状及roadmap分享,带大家一起回顾vllm发展历史、过去一年的发展及接下来Q4规划。
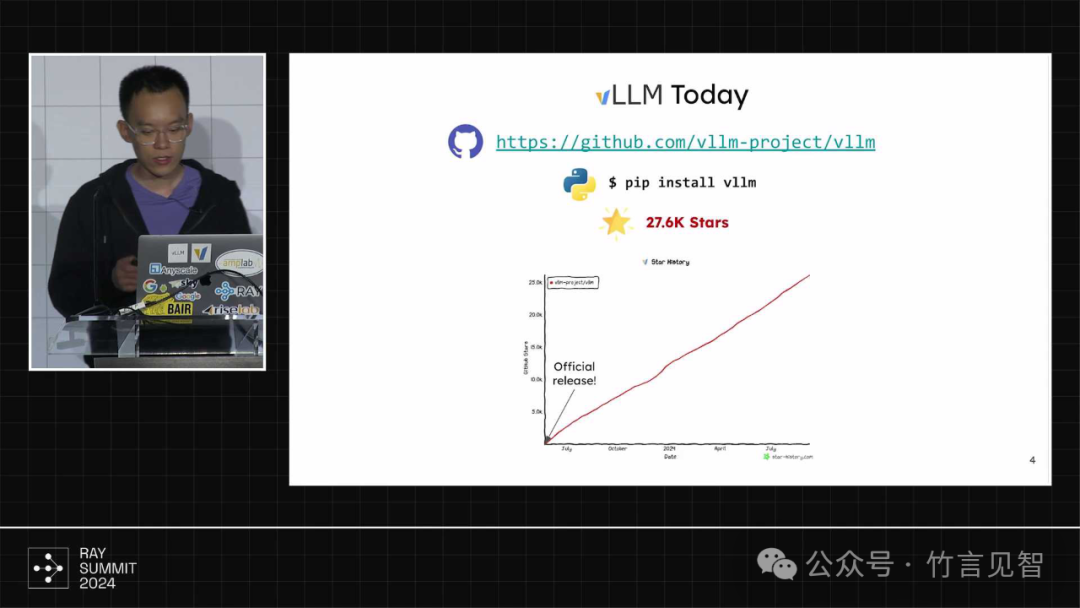
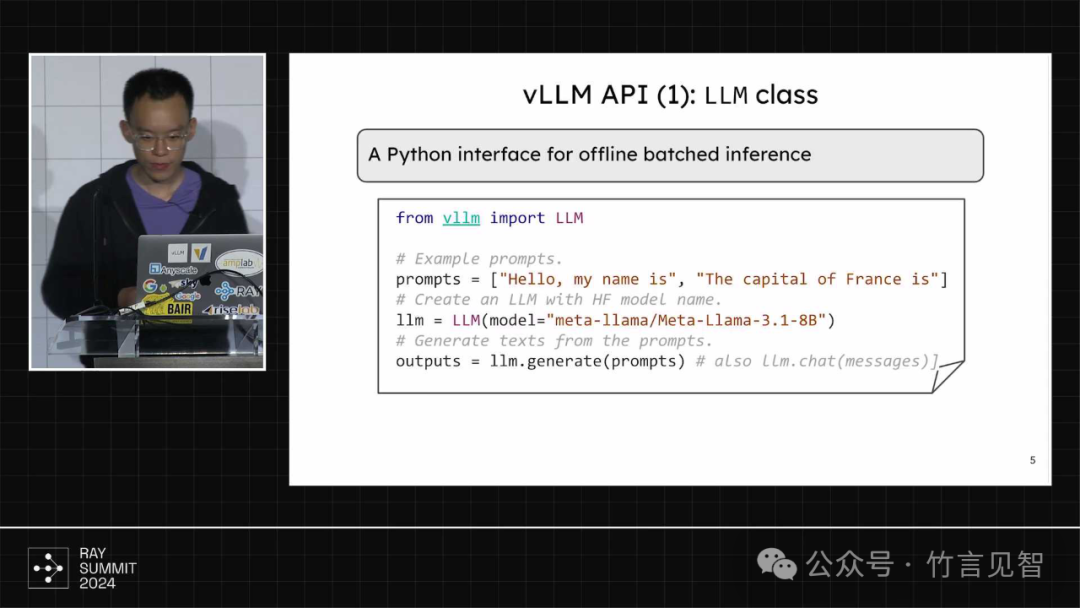
vllm的目标是构建最快、最易使用的开源大模型推理服务引擎,最初起源可追溯到22年8月,用于解决大模型推理慢速问题。23年2月提出了pagedattention概念,并于23年4月提交相关论文。在社区帮助下快速迭代发展,成为最受欢迎的LLM服务引擎之一。
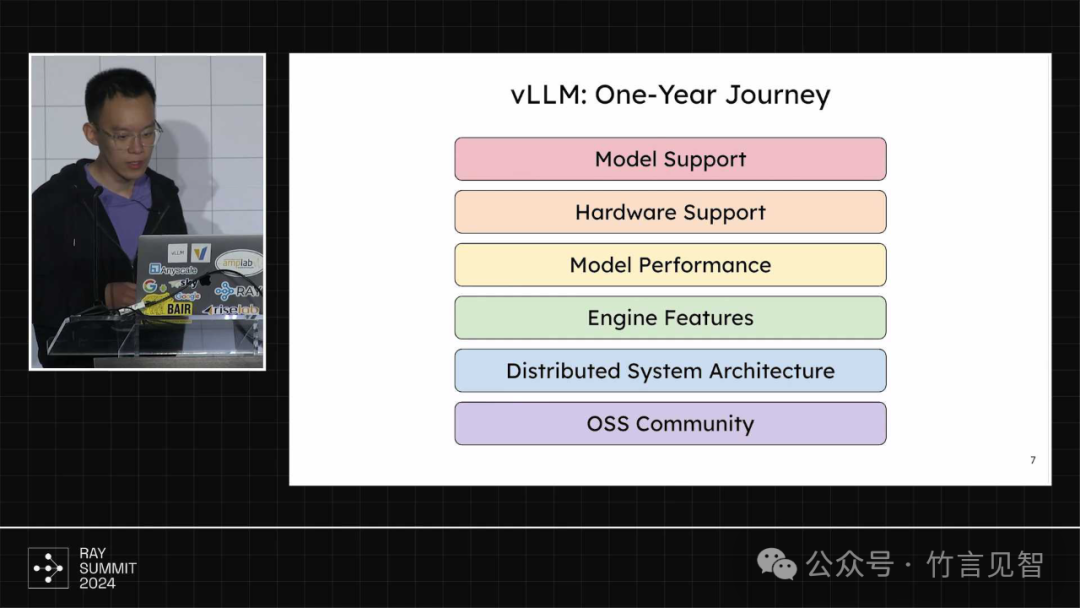
过去一年的工作内容
-
模型支持,支持几乎所有llm和vlm模型且效率非常高,包括LLama系列模型/Mixtral系列模型/LLava多模态/状态空间模型/reward模型等
-
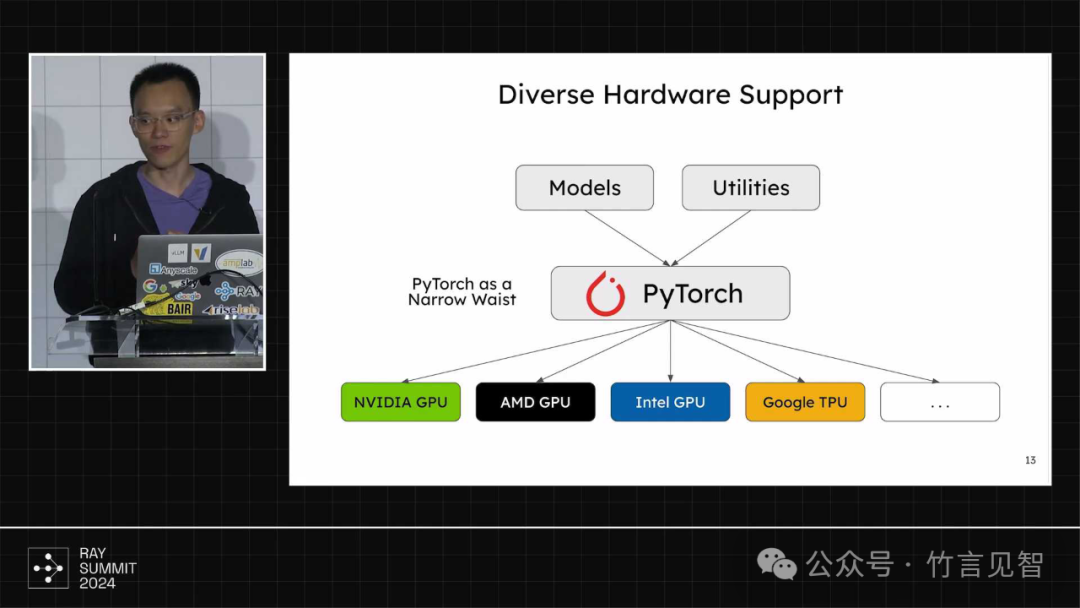
硬件支持,支持主流的xPU,如nvidia GPU/amd GPU/Intel GPU/Google TPU等
-
模型性能优化
-
深层次的 cuda kernel优化,如计算时异步数据传输/优化内存访问(精度精度-高效数据类型-减少数据传输量)/增加并行度等优化allreduce通信。利用cutlass库优化GEMM,实现kernel fusion等功能,提供专门的flashatention kernel等
-
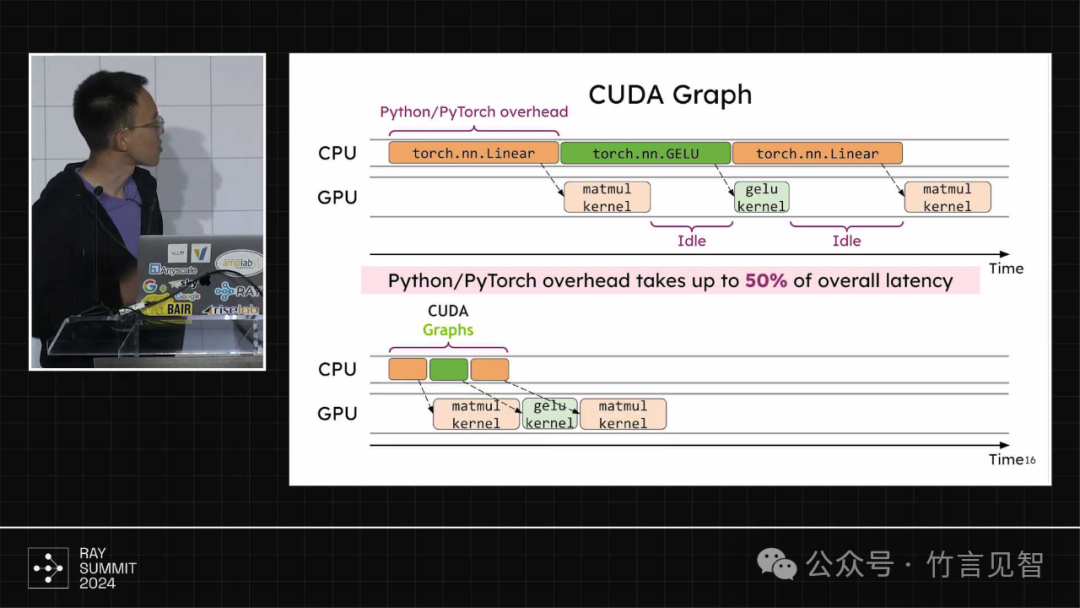
cuda图优化
-
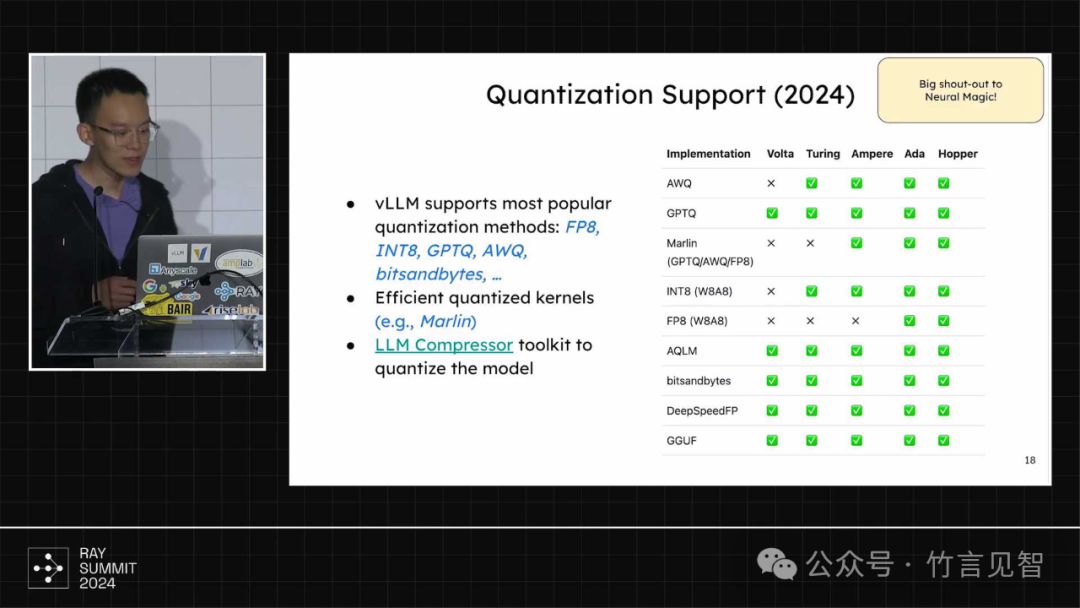
支持主流的量化技术,FP8/INT8/GPTQ/AWQ等,并集成marlin kernel等
-
-
新特性
-
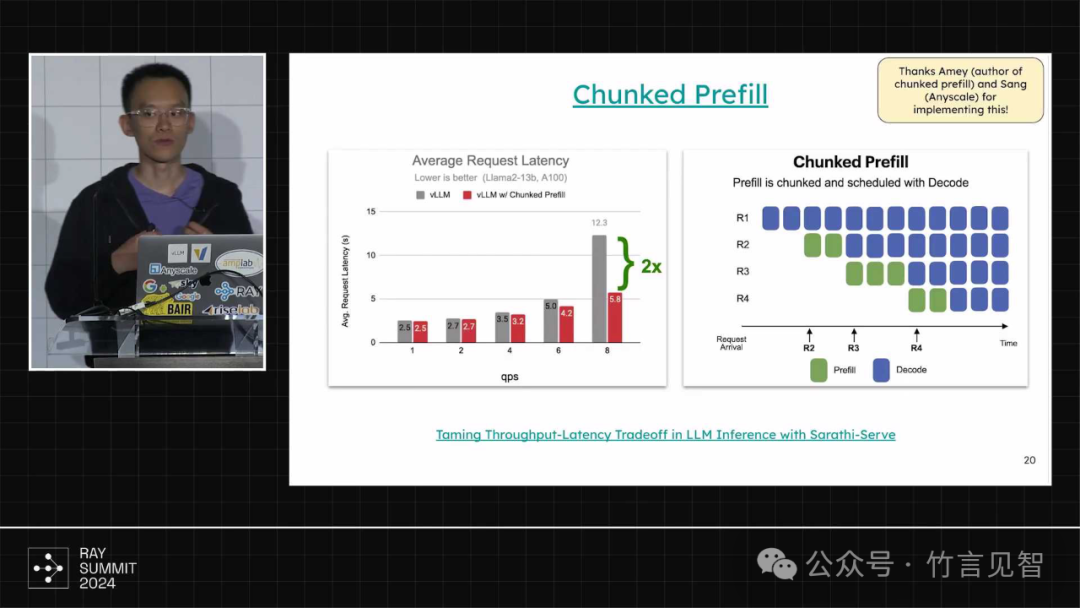
支持sarathiserver论文提出的chunked prefill
-
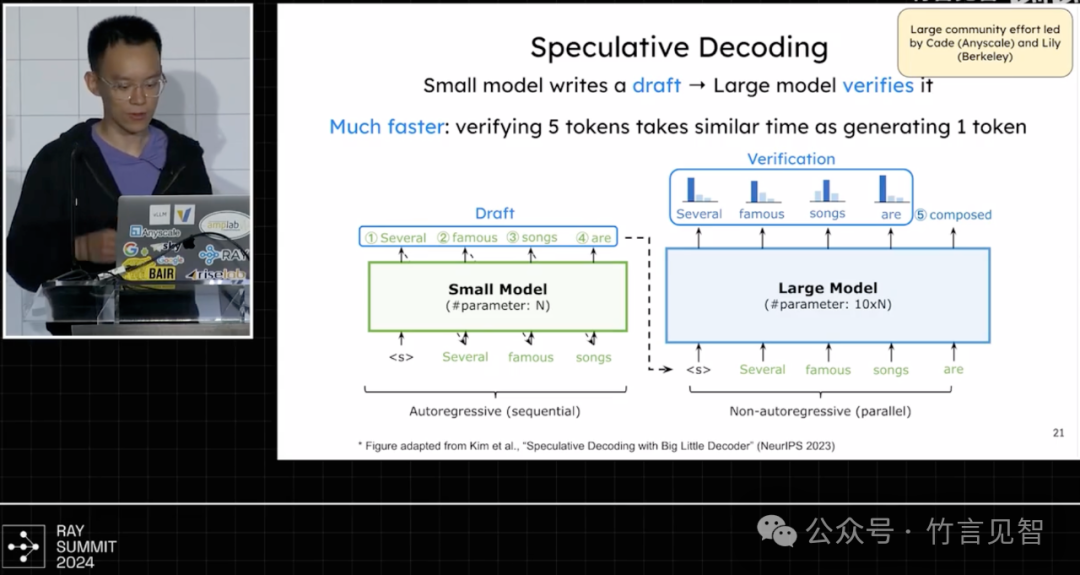
speculative decodin(draft-verification)/dynamic speculative deccoding(根据系统负载和推测精度动态调整长度)
-
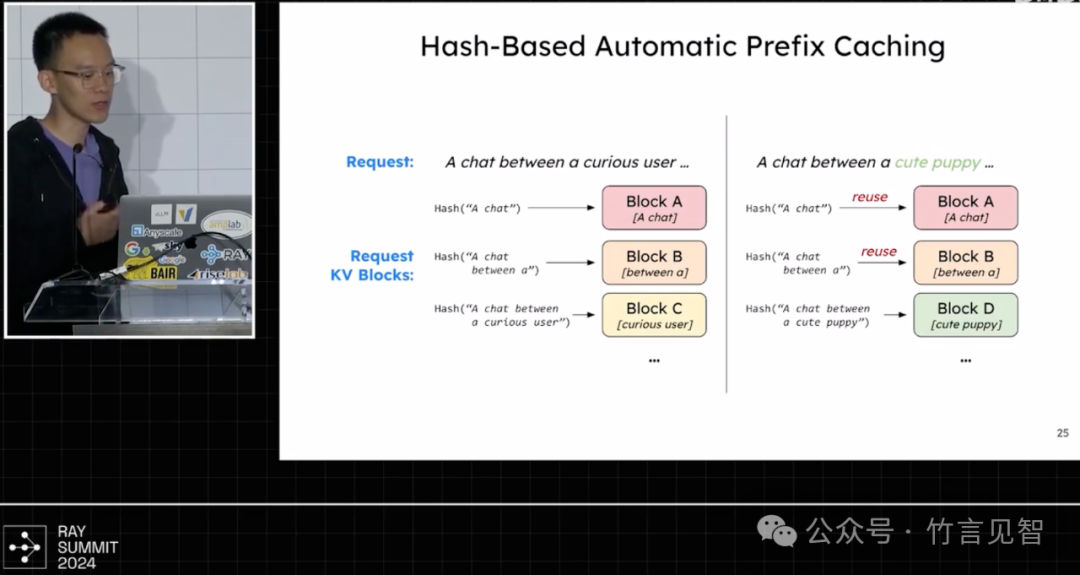
基于hash的自动前缀缓存,缓存system prompt及多轮对话,减少请求数据量,这与sglang中采用的radix树维护kv缓存不同,但都提高了缓存重用
-
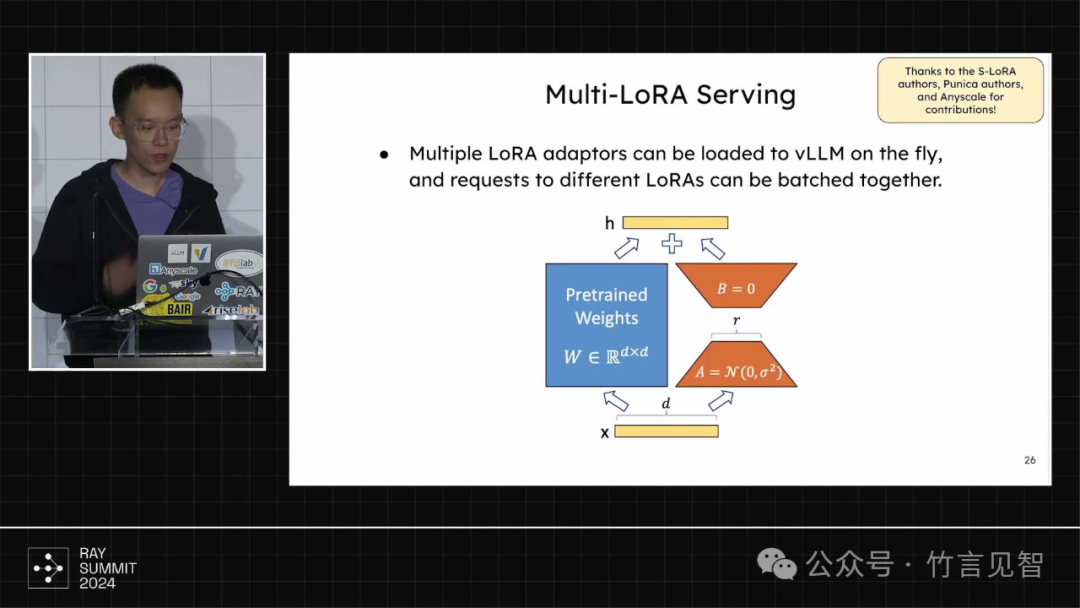
支持多个lora adapter及热加载
-
支持结构化输出等
-
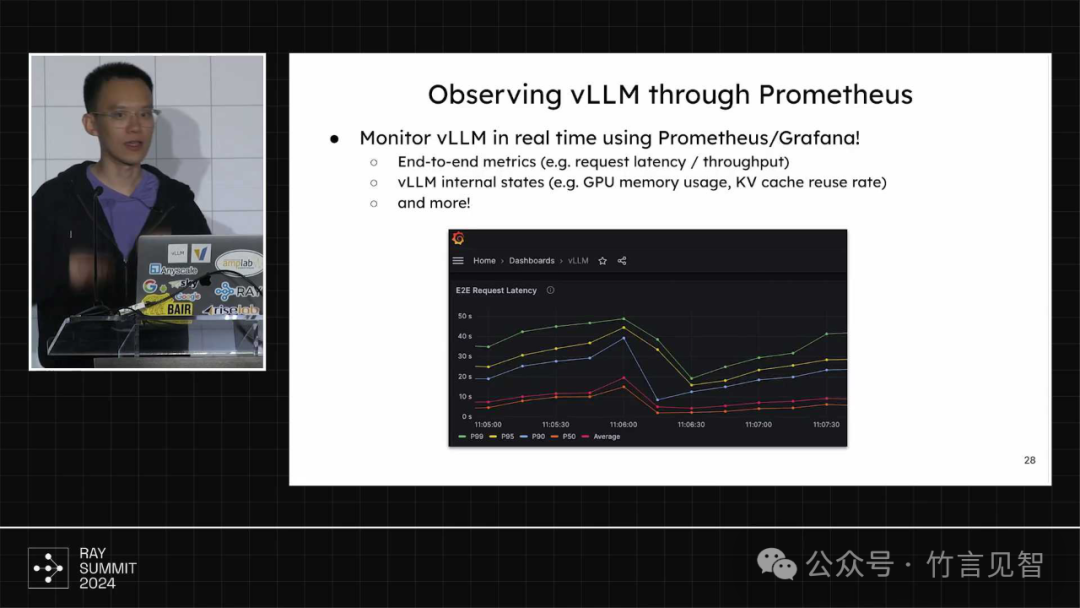
基于prometheus/grafana的实时监控,包括gpu内存使用/kvcache重用率/访问延迟吞吐等指标
-
-
分布式系统架构
-
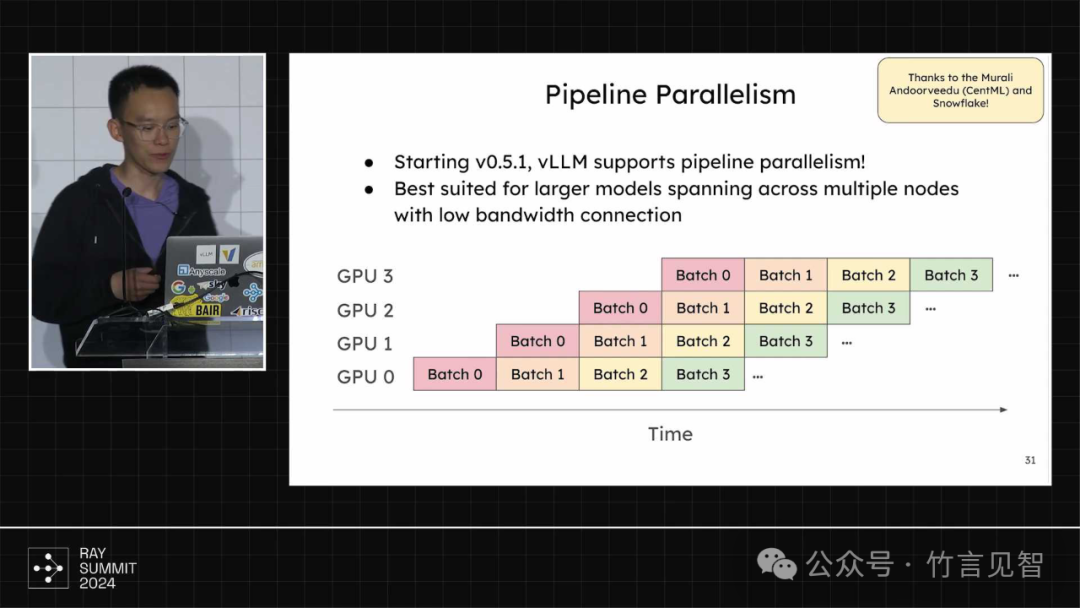
支持tensor并行/流水线并行等
-
多GPU/多节点支持
-
cpu offloading
-
动态批处理/流式输出
-
v0.6.0中最小化GPU负载功能,
-
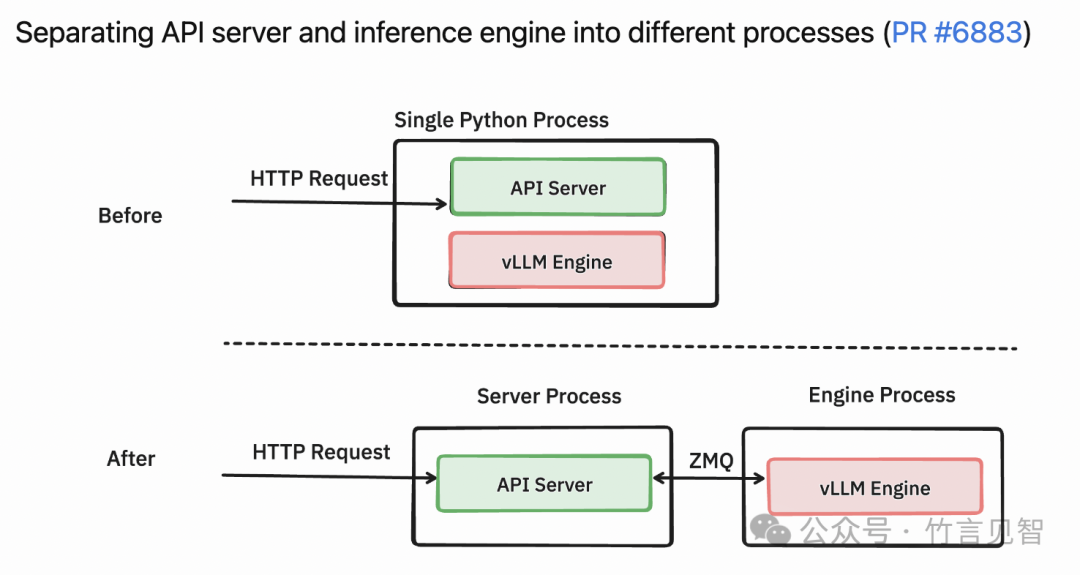
包括APIserver与推理引擎分离到不同进程,通过ZMQ消息队列通信
-
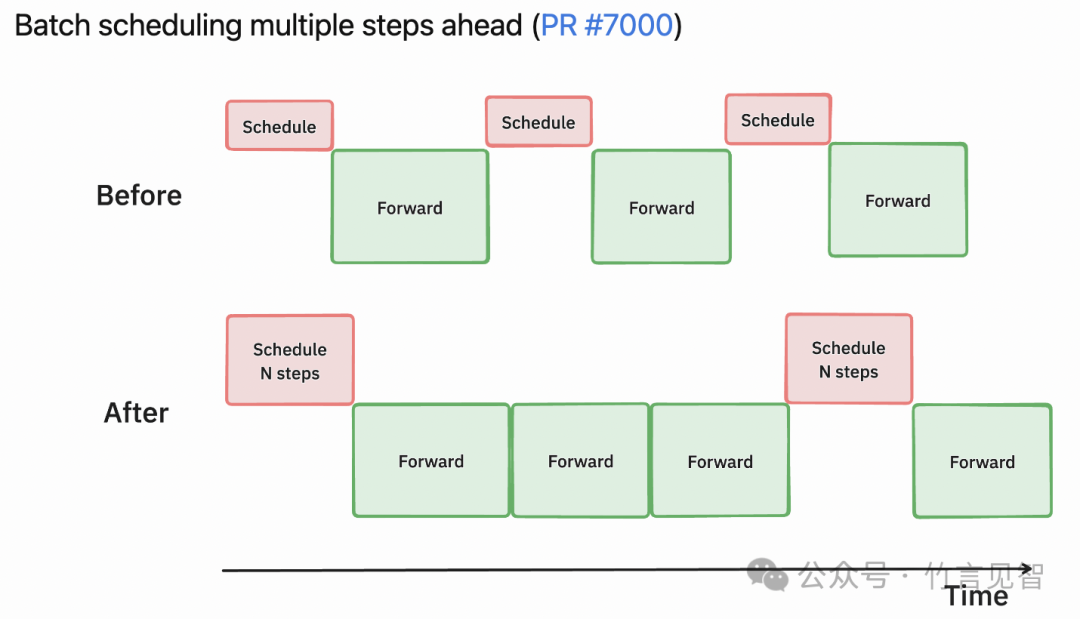
多步调度
-
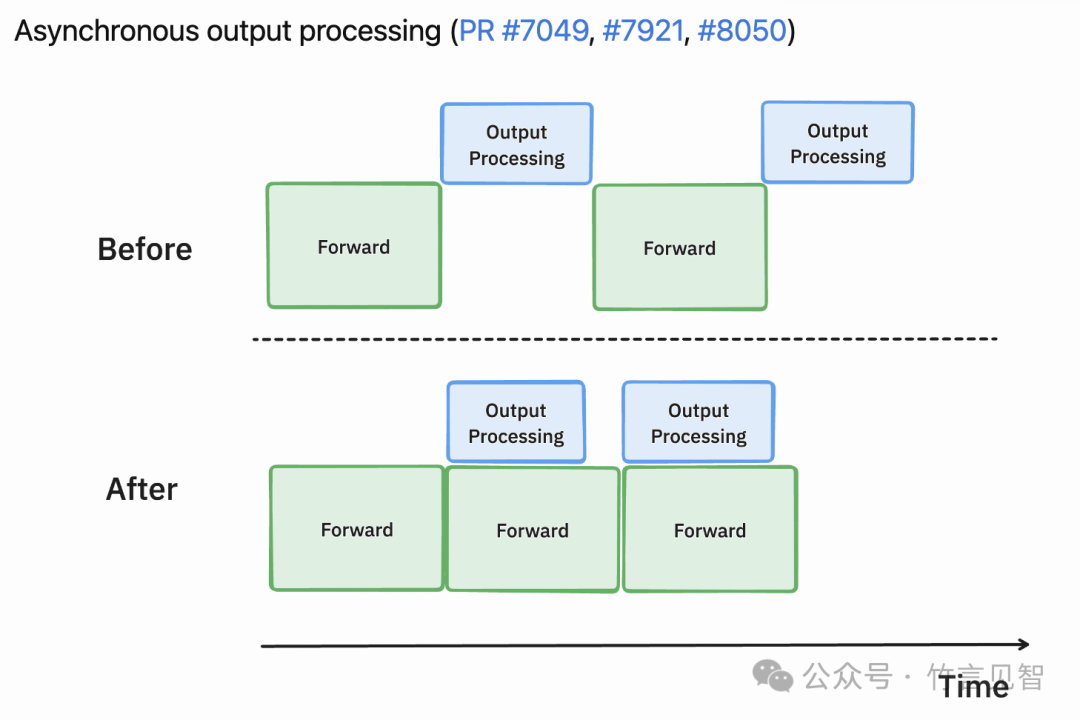
异步输出
-
-

-
-
oss社区
-
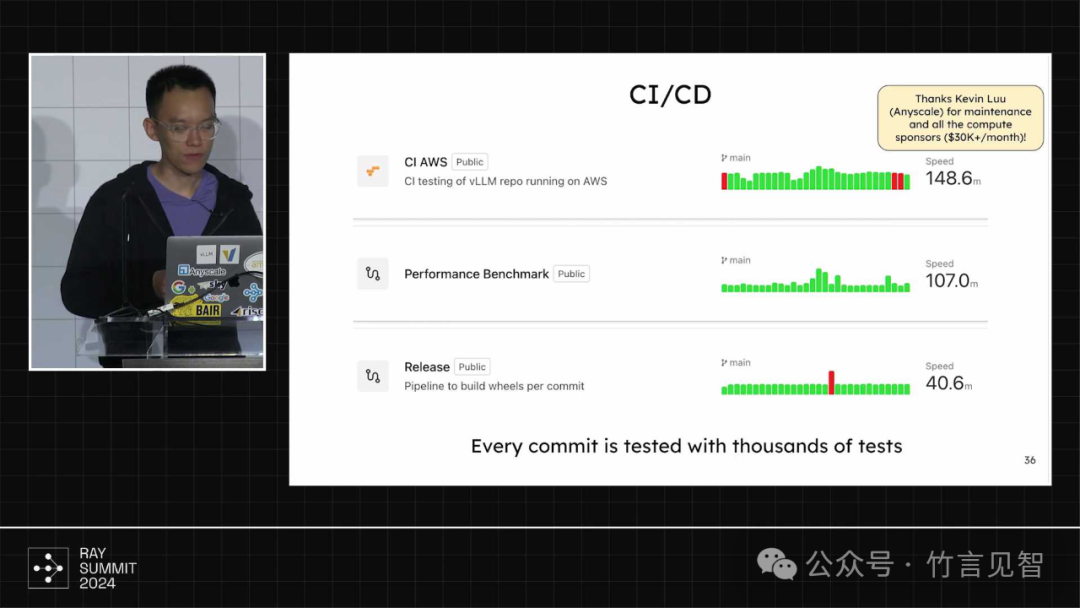
CI/CD集成,做到每个commit都通过上千个测试用例
-
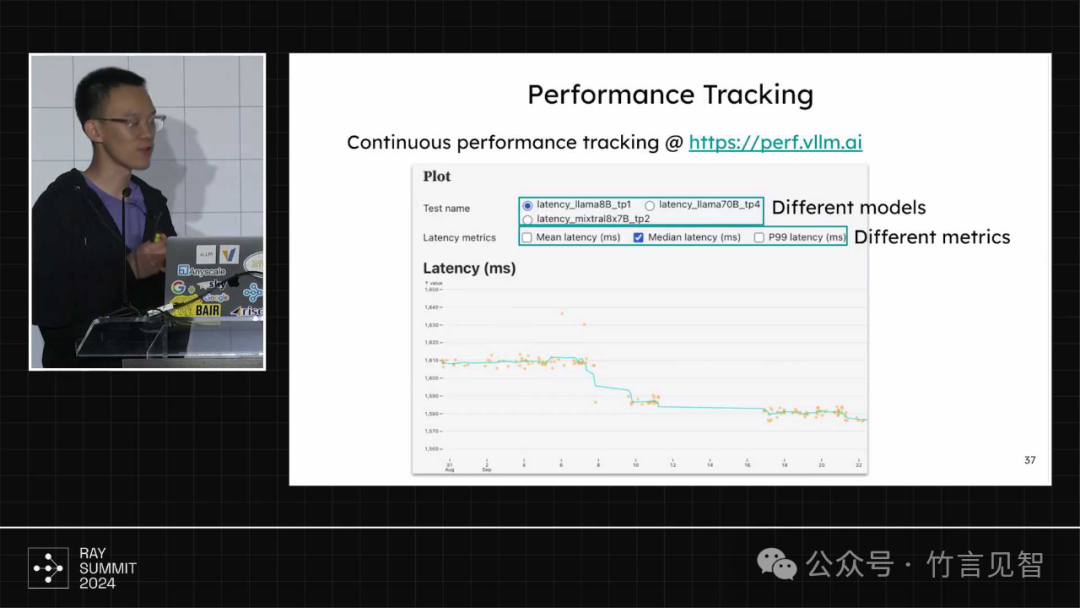
性能追踪,跟踪每次大的修改性能变化
-
加入linux foundation,每2个月的meetup及每2周的线上会议
-
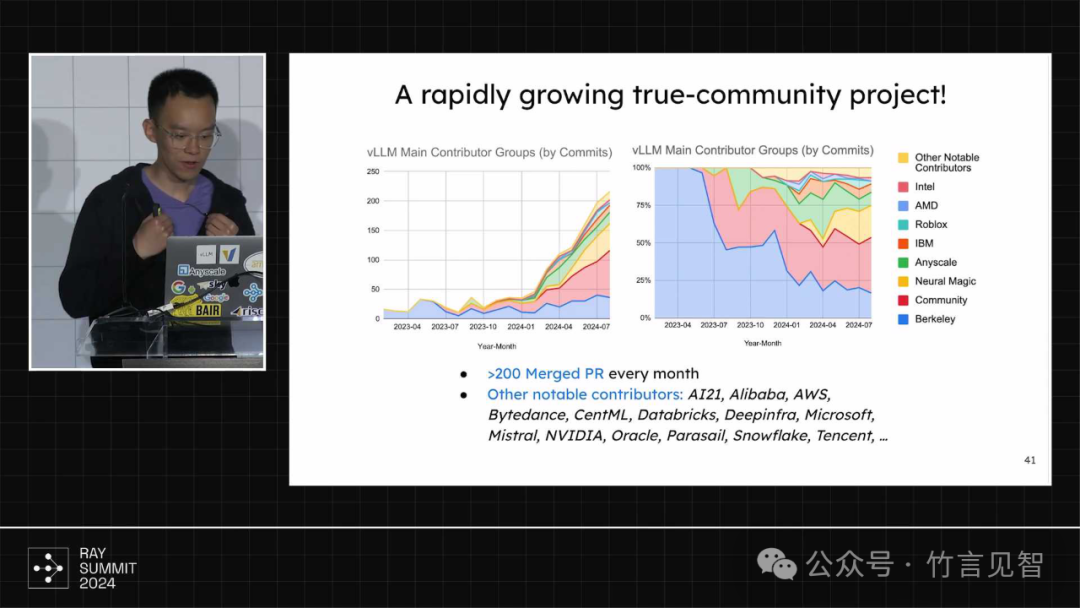
github社区活跃,560+的contributor,20+的commiter
-
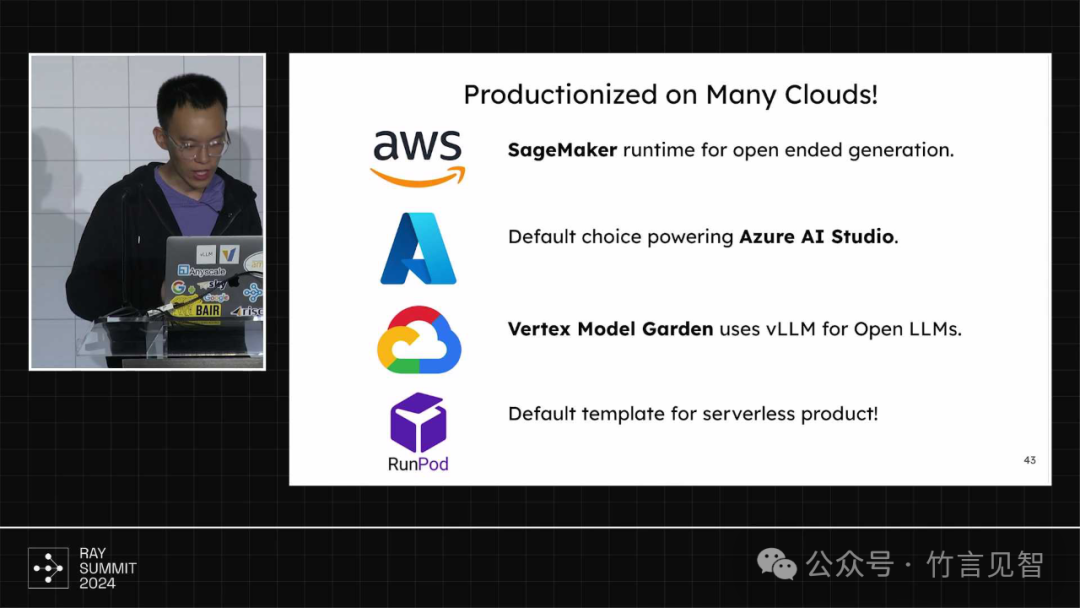
客户群体众多,包含众多科技巨头/云厂商等,在aws/azure/vertex等多个云端部署运行
-
-
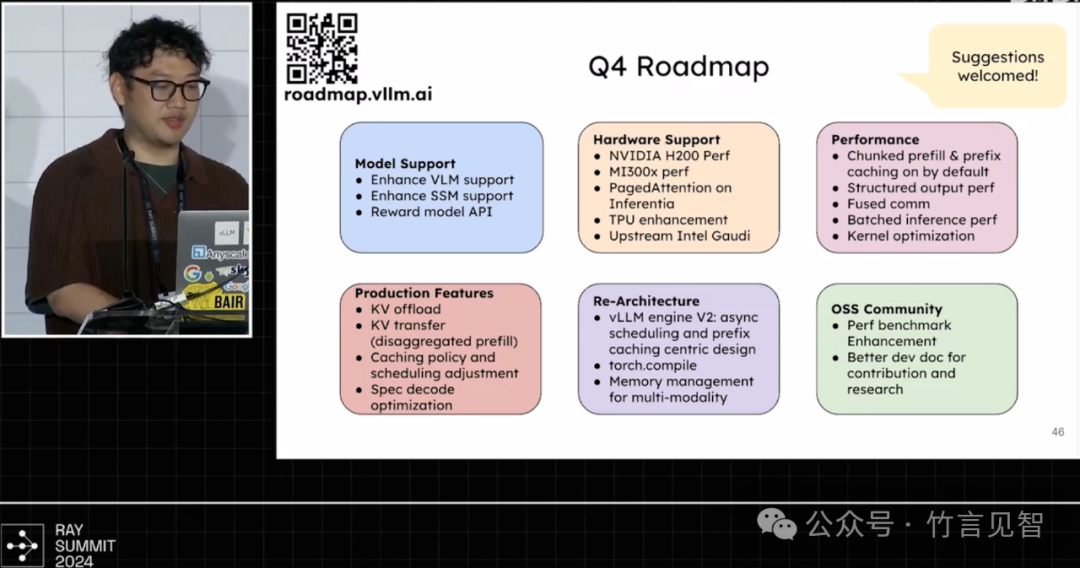
接下来的Q4计划
模型支持,继续支持VLM多模态模型/SSM状态模型-mamba/reward模型/whisper等
-
硬件支持,继续提升支持nvidia h200/mi300x/intel gaudi/google tpu等
-
性能提升
-
默认打开chunked prefill/前缀树/speculative decoding
-
结构化输出优化
-
kernel fusion,提供更高性能的kernel如flashattention3/flashinfer/flexattetion/triton等
-
稀疏kv框架及长上下文优化等
-
-
新特性
-
kv offloading到cpu/磁盘,kv迁移等
-
prefill/decoding的分离
-
前缀树缓存策略/调度策略优化
-
动态speculative decoding
-
-
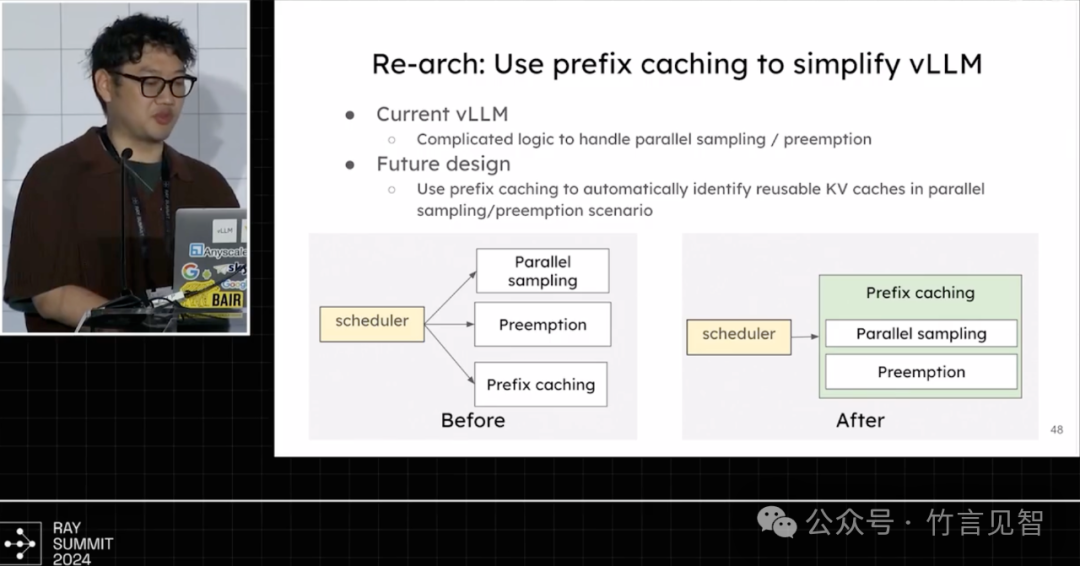
重构
-
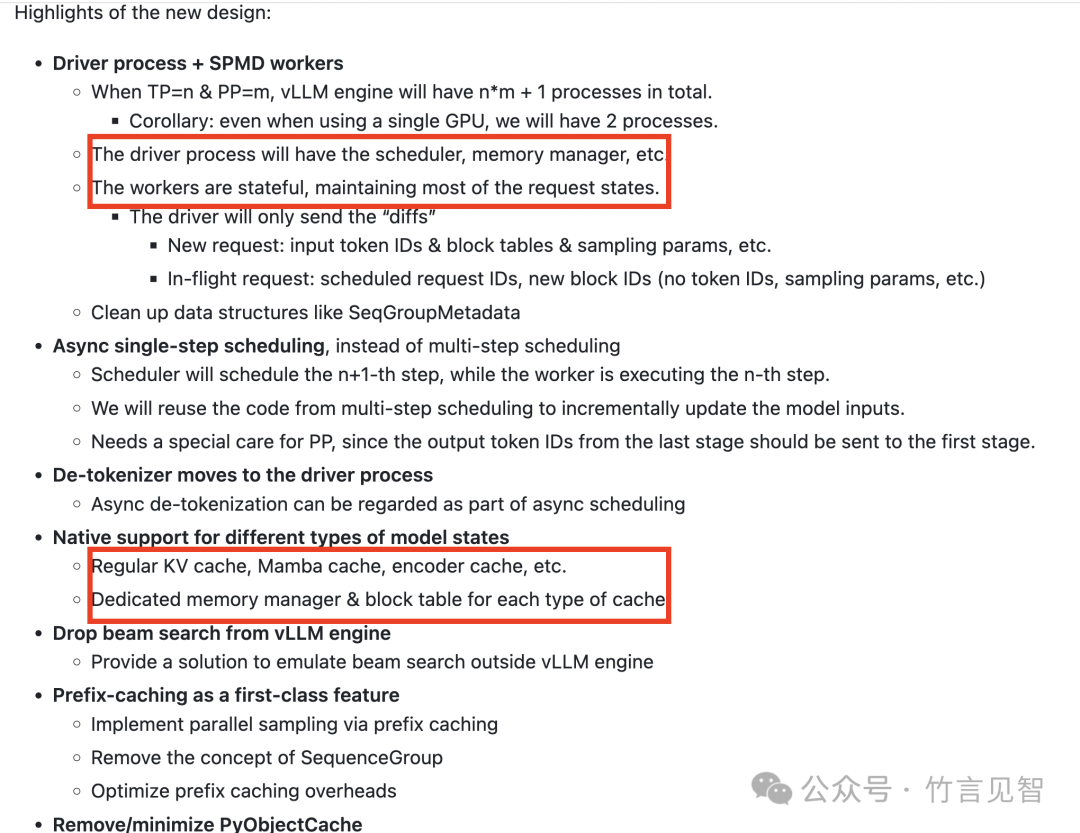
vllm enging v2.0,异步调度和以prefix caching为中心的设计
-
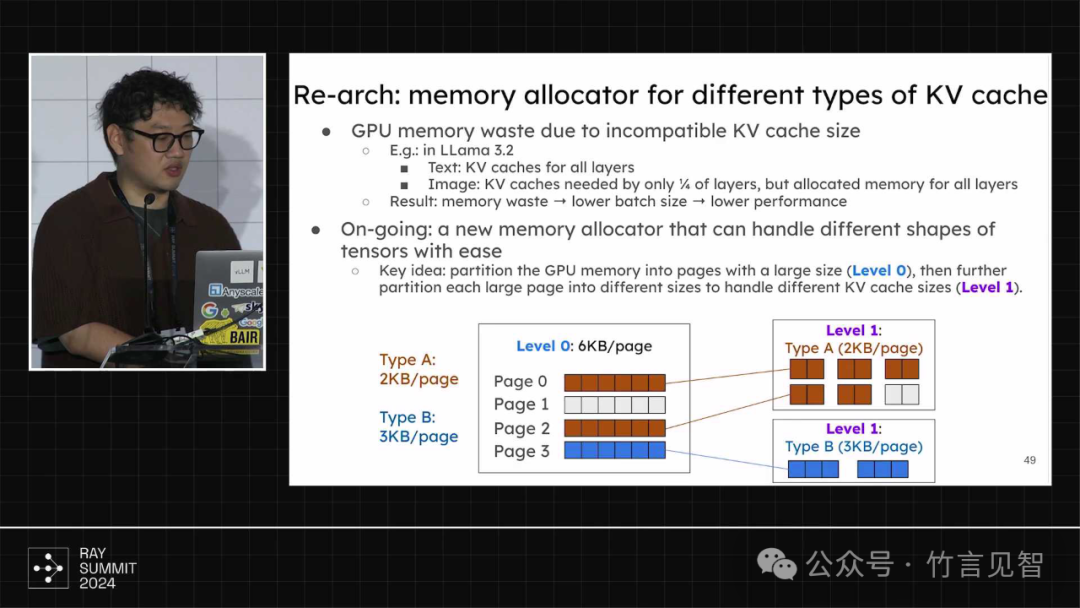
多模态内存管理,支持不同shape的tensor,提供类似多级缓存管理功能
-
原生支持torch.compile
-

-
oss社区,提高perf benchmark及文档优化等
之前相关的推理服务、推理分离式架构及vllm/sglang/flashattention/mamba等分享可回溯参考,
-
OSDI 2024系列-低延迟大模型推理服务1(sarathiserver)
-
OSDI 2024系列-ML调度1(动态lora适配器)
-
AMD最新AI端到端基础设施(mi325x GPU)






























更多资料:
https://blog.vllm.ai/2024/09/05/perf-update.html
https://github.com/vllm-project/vllm/issues/9006