GLM-4-Voice:情感语音

-
GLM-4-Voice-Tokenizer:
通过向 Whisper 的编码器部分添加向量量化来训练,将连续的语音输入转换为离散的标记。每秒的音频都转换为 12.5 个离散令牌。
link:https://huggingface.co/THUDM/glm-4-voice-tokenizer
-
GLM-4-Voice-9B:
基于 GLM-4-9B 的语音模态预训练和对齐,能够理解和生成离散化语音。
link:https://huggingface.co/THUDM/glm-4-voice-9b
-
GLM-4-Voice-Decoder:
支持流式推理的语音解码器,基于 CosyVoice 重新训练,将离散语音令牌转换为连续的语音输出。生成可以从 10 个音频令牌开始,从而减少对话延迟。
link:https://huggingface.co/THUDM/glm-4-voice-decoder
-
情感表达和共鸣:GLM-4-Voice可以模拟高兴、悲伤、生气、害怕等多种情绪,并用合适的语气进行回复,打破了传统TTS在情感表达上的僵硬局限。
-
调节语速:用户可以在对话中要求模型加快或放慢语速,满足不同场景下的需求。
-
灵活互动:支持随时打断和灵活输入指令,能够根据用户的实时指令调整语音输出的内容和风格。
-
多语言、多方言支持:目前支持中英文语音以及中国各地方言,尤其擅长粤语、重庆话和北京话。
-
视频通话功能:即将上线的视频通话功能,将实现既能看又能说的全方位交互体验。


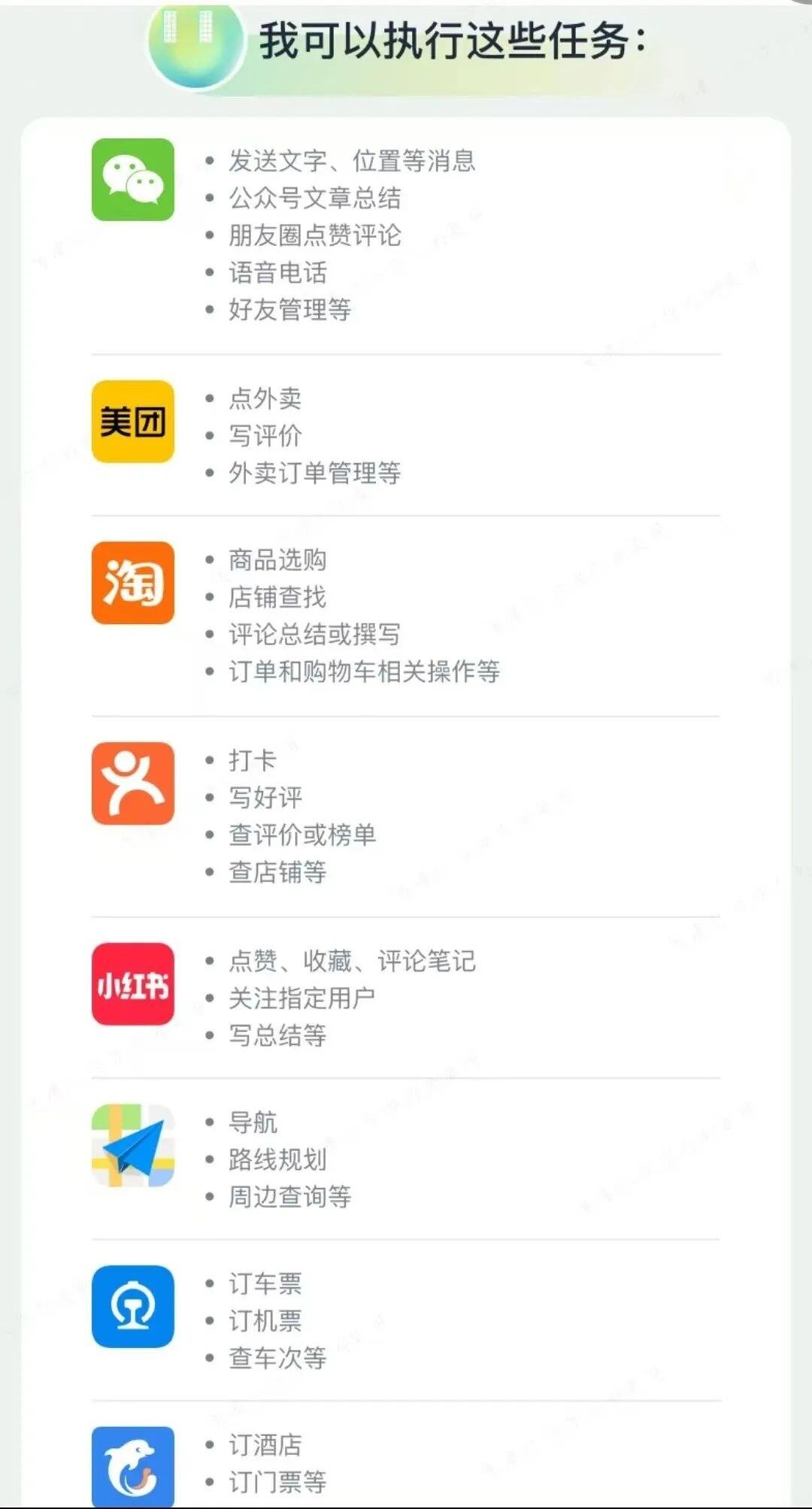
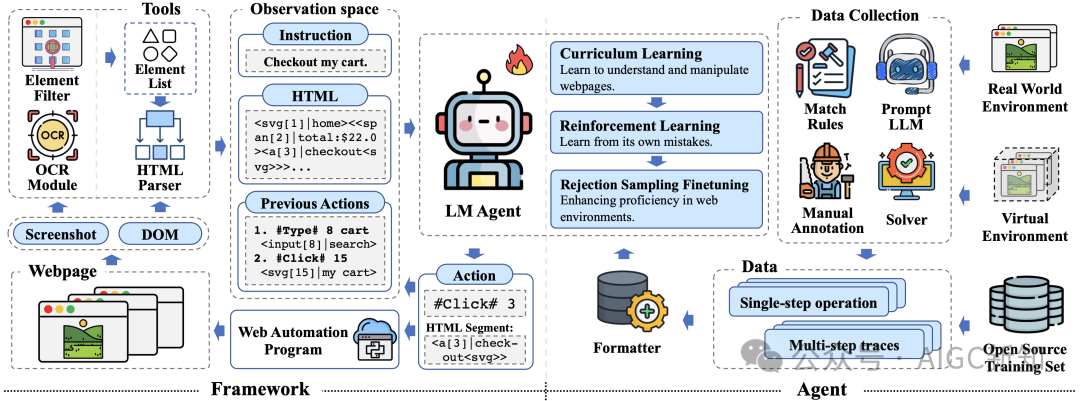
AutoGLM:AI的Phone Use时代
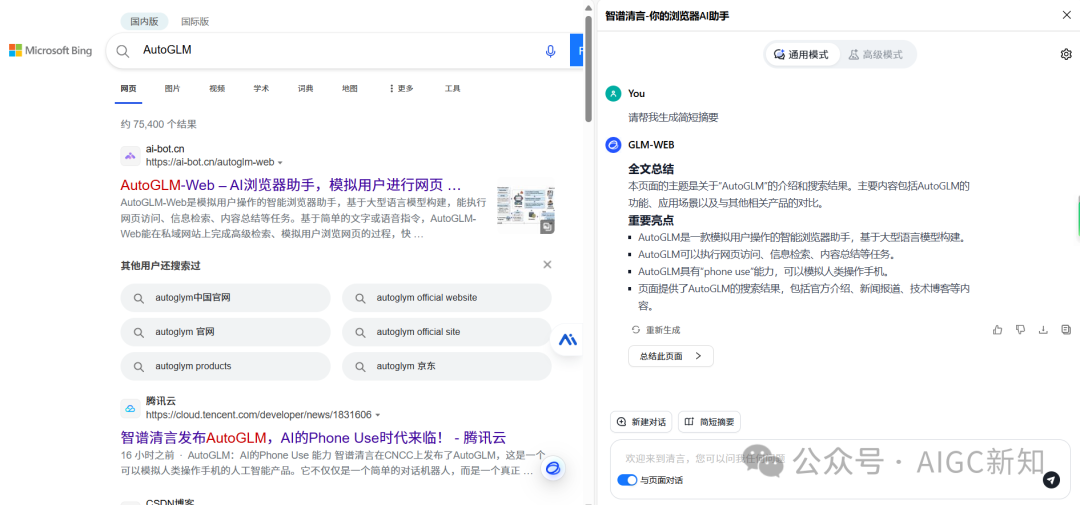
AutoGLM浏览器插件地址:
https://new-front.chatglm.cn/webagent/landing/index.html?channel=ads_news_lzwAutoGLM
浏览器插件包含通用搜索和高级搜索两个模块:
通用搜索包含生成摘要和总结页面,这个没啥说的。。
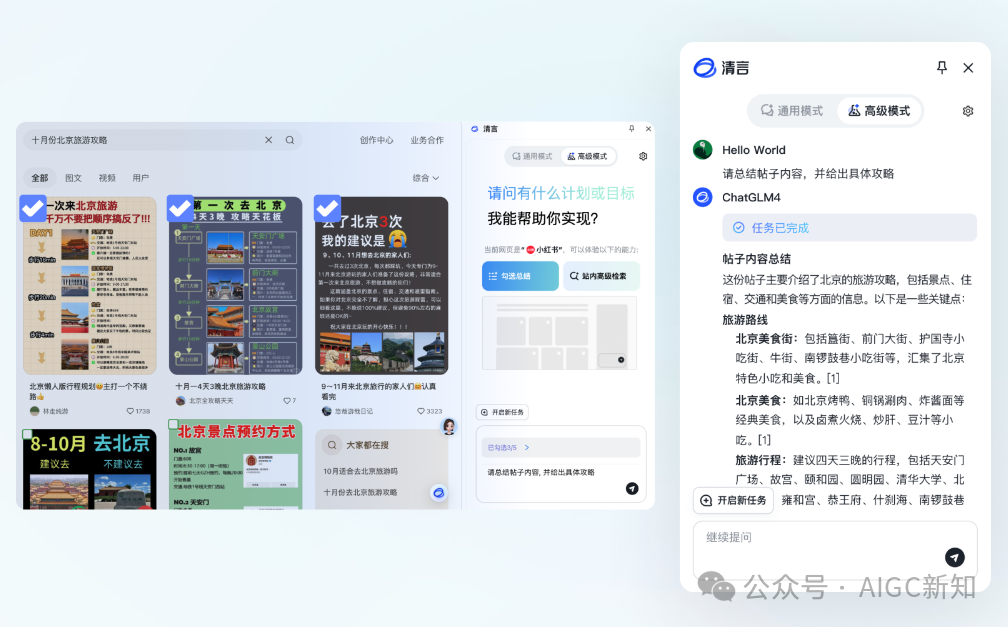
高级搜索,成功实现知网、知乎、小红书三个平台的功能适配。
在知网检索“2024年多模态大模型的最新研究进展”
在知乎检索“下半年AI的发展趋势”
在小红书站内检索相关小红书笔记(小红书的AI内容搜索是不是已经鸡肋了),请看VCR
炸裂!可以在小红书站内自动检索相关小红书笔记进行归纳总结,AI自动帮你去检索相关内容,你只需要输入关键词即可!!!
量子速读功能,可以选择需要阅读的小红书笔记,进行一键总结。

-
自主操作手机:AutoGLM能够根据用户的语音或文字指令,完成如订酒店、取消点赞、发送消息等任务。
-
多模态理解:能够理解图片、记录文字,并根据这些信息自动撰写内容。
-
跨应用操作:虽然目前还不支持跨应用操作,但未来几个月内将实现更广泛的软件操作。