
收录于话题
2024年10月25日Arxiv cs.CV发文量约92余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省39分钟浏览Arxiv的时间。
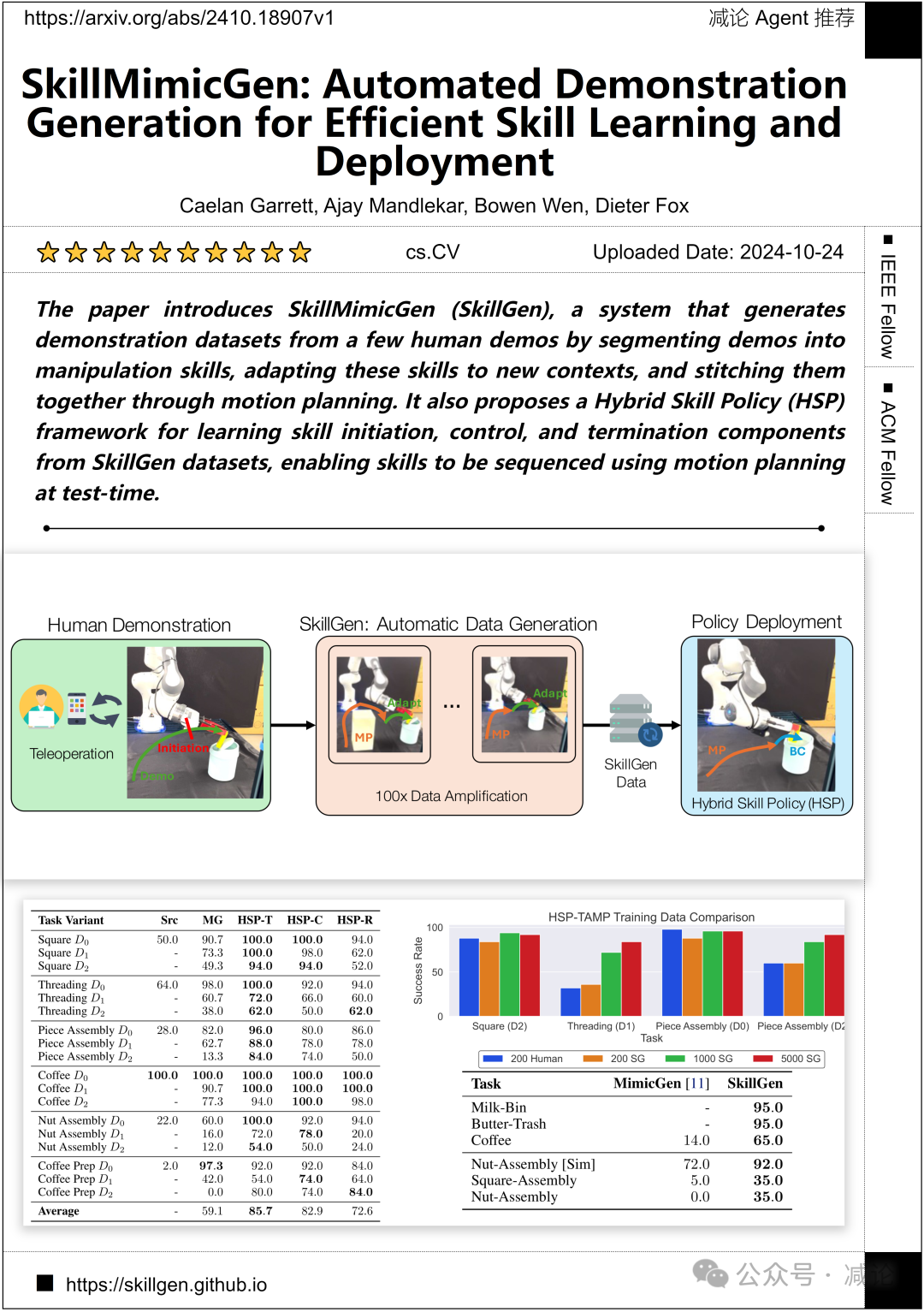

英伟达(NVIDIA)提出了SkillMimicGen(SkillGen)系统,该系统通过将演示分割成操作技能,并将这些技能适应新的环境,通过运动规划将它们拼接在一起,从少量人类演示中生成演示数据集。此外,他们还提出了一个混合技能策略(HSP)框架,用于从SkillGen数据集中学习技能启动、控制和终止组件,使技能能够在测试时通过运动规划进行排序。
http://arxiv.org/abs/2410.18907v1
https://skillgen.github.io
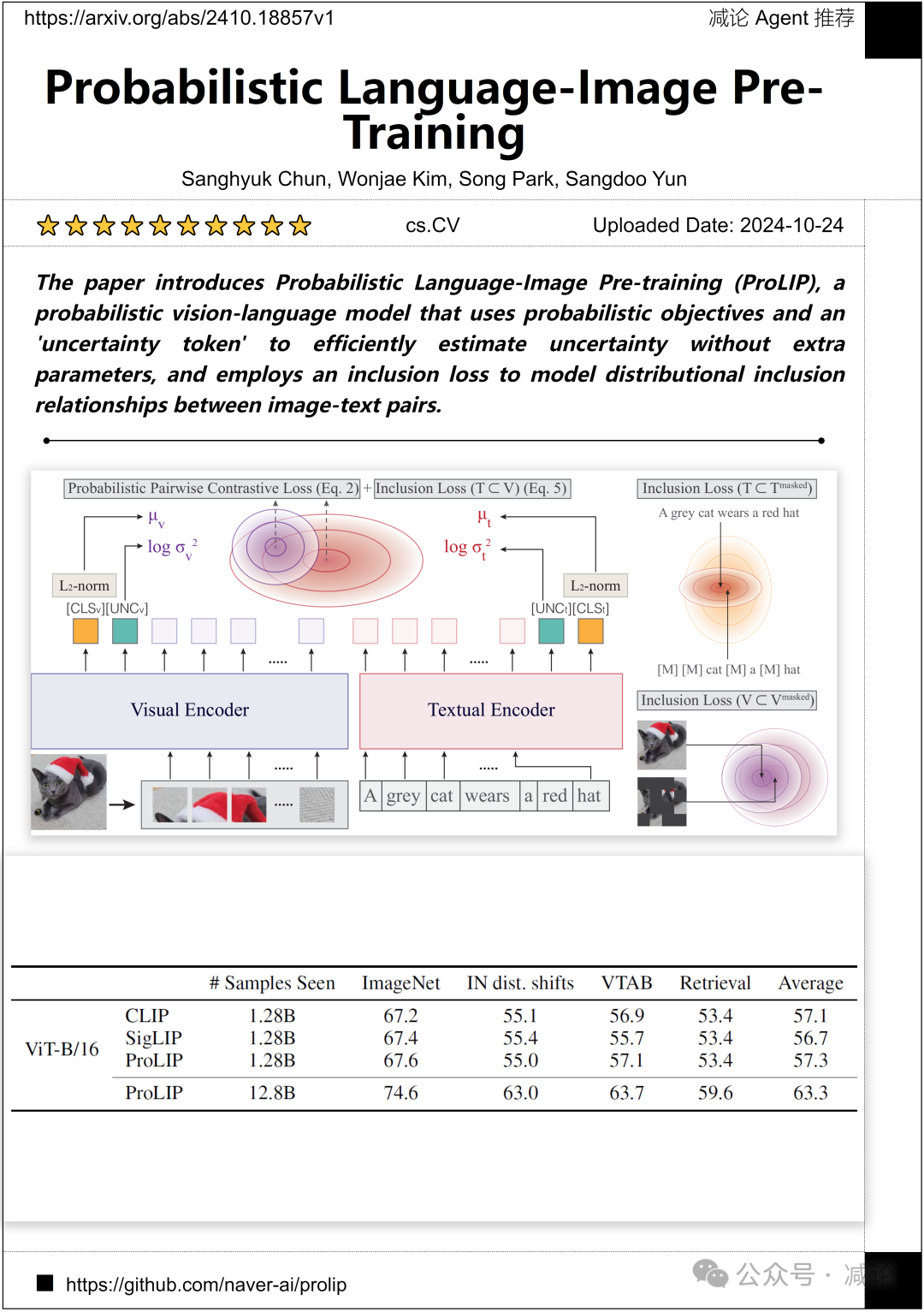
NAVER AI Lab团队介绍了概率语言–图像预训练(ProLIP)方法,该方法利用概率目标和一个“不确定性标记”来高效估计不确定性,而无需额外参数,并采用包含损失来建模图像–文本对之间的分布包含关系。
http://arxiv.org/abs/2410.18857v1
https://github.com/naver-ai/prolip

南洋理工大学和苏黎世联邦理工学院的研究团队介绍了VINE,一种利用预训练扩散模型在图像中嵌入更不可察觉和更稳健水印的方法,并在训练过程中引入模糊失真作为替代攻击,以增强对图像编辑的稳健性。
http://arxiv.org/abs/2410.18775v1
https://github.com/Shilin-LU/VINE
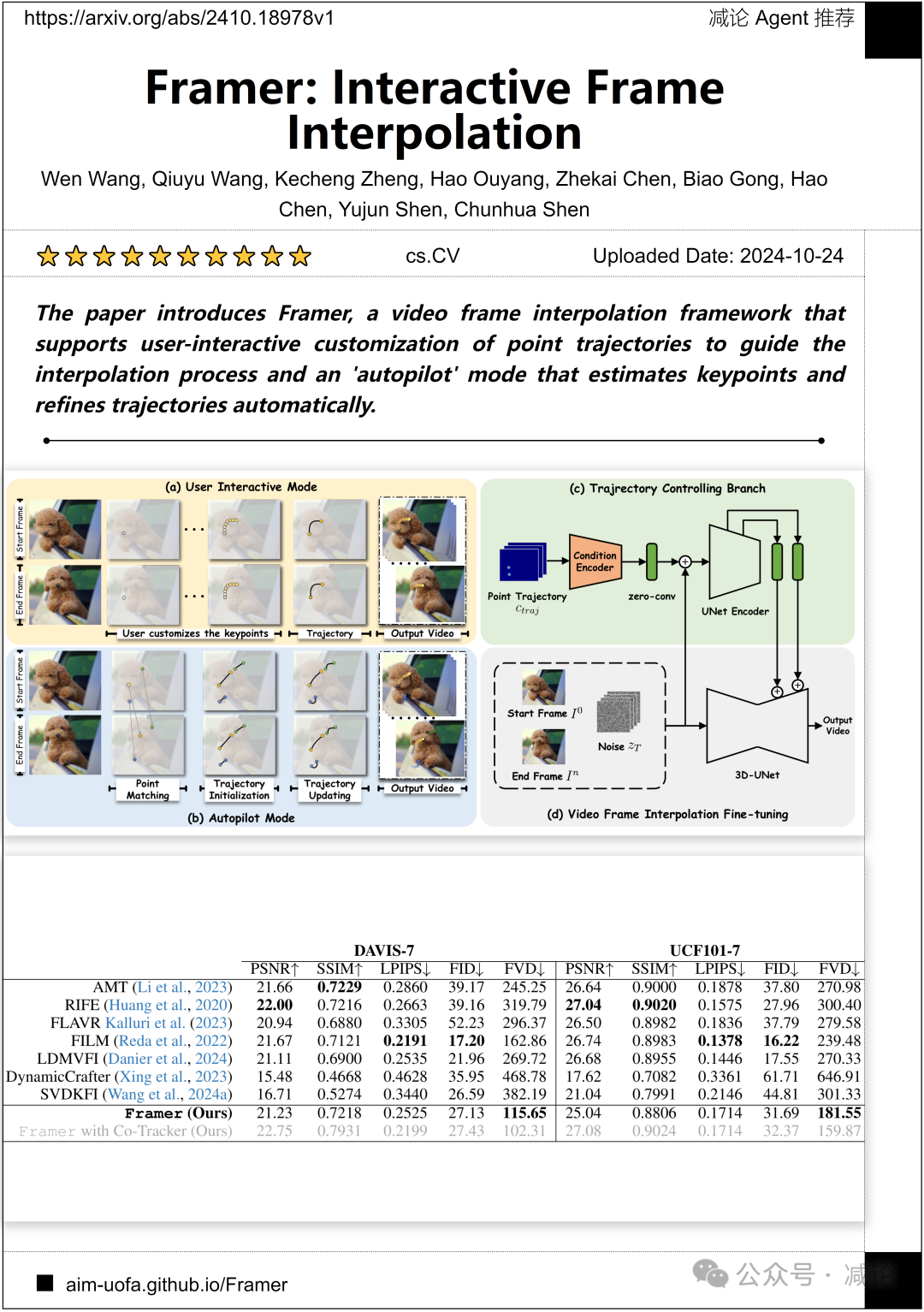
浙江大学, 蚂蚁集团 的研究团队提出了 Framer,一个视频帧插值框架,支持用户交互式定制点轨迹以引导插值过程,并具有“自动驾驶”模式,可以自动估计关键点并优化轨迹。
http://arxiv.org/abs/2410.18978v1
aim-uofa.github.io/Framer

中国科学院自动化研究所、字节跳动公司、北京师范大学的研究团队提出了一个名为ChatSearch的数据集和一个名为ChatSearcher的生成式检索模型,用于一般对话式图像检索。该模型经过端到端训练,接受并生成交错的图像文本输入/输出,利用大型语言模型和动态更新的图像特征队列来实现这一目标。
http://arxiv.org/abs/2410.18715v1
https://github.com/joez17/ChatSearch
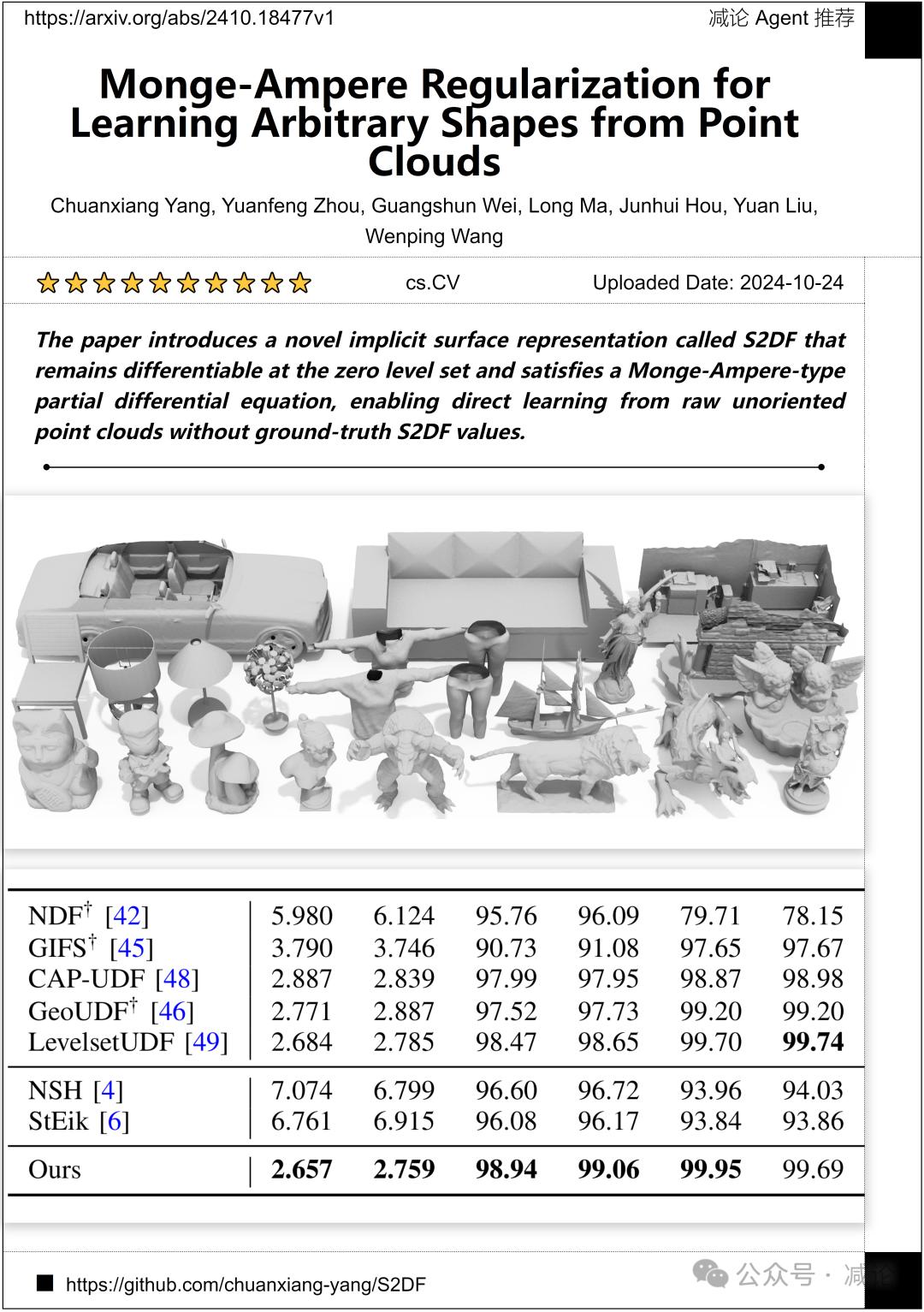
山东大学、香港城市大学和德克萨斯农工大学的研究团队提出了一种新颖的隐式表面表示方法,称为S2DF。这种方法在零级集上保持可微,并满足蒙日–安培类型的偏微分方程,实现了直接从原始未定向点云中学习,而无需地面真实的S2DF值。
http://arxiv.org/abs/2410.18477v1
https://github.com/chuanxiang-yang/S2DF
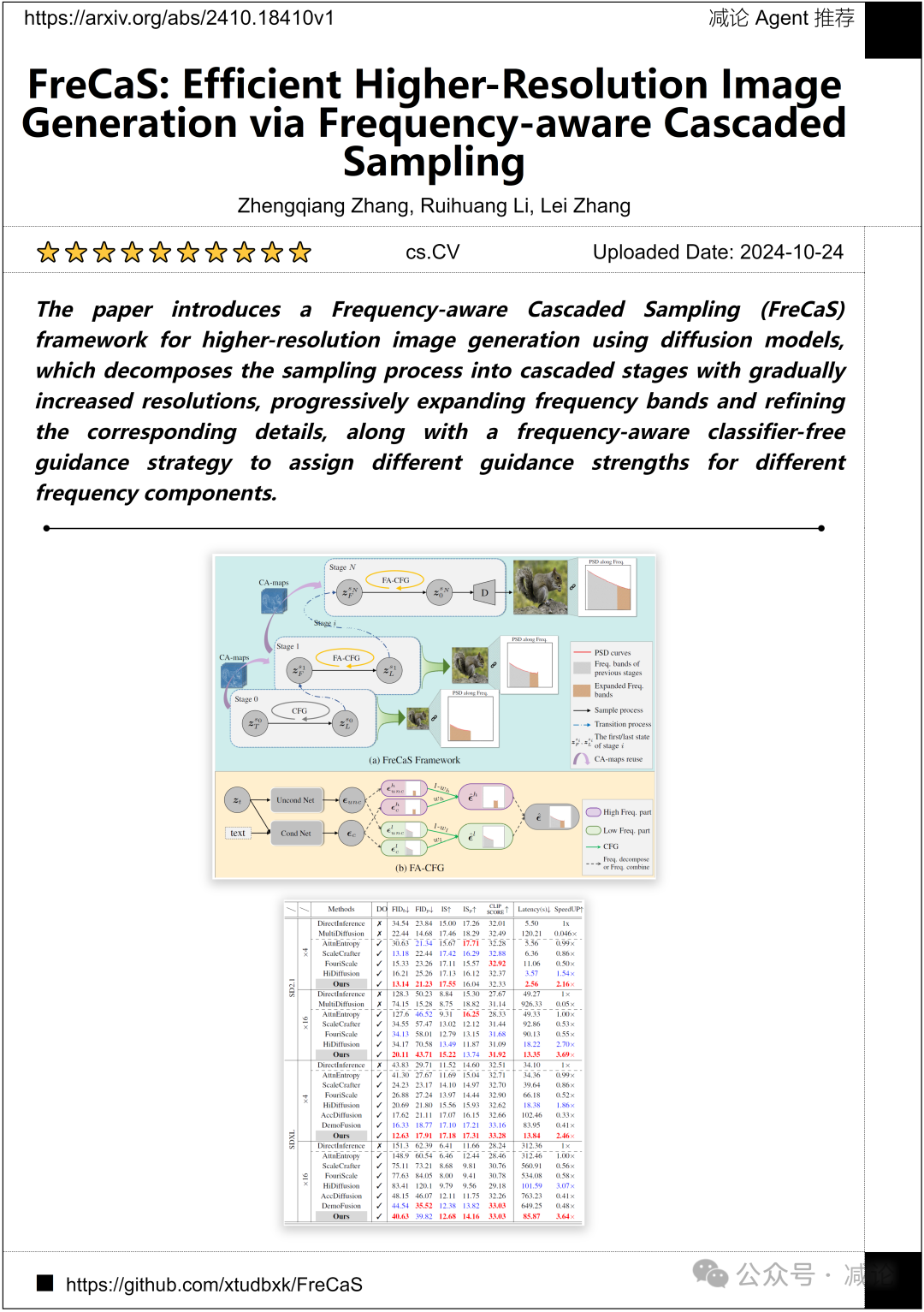
香港理工大学的研究团队提出了一种频率感知级联采样(FreCaS)框架,用于生成更高分辨率的图像。该框架将采样过程分解为级联阶段,逐渐增加分辨率,逐步扩展频率带并细化相应细节。同时,采用一种频率感知的无分类器引导策略,为不同频率分量分配不同的引导强度。
http://arxiv.org/abs/2410.18410v1
https://github.com/xtudbxk/FreCaS
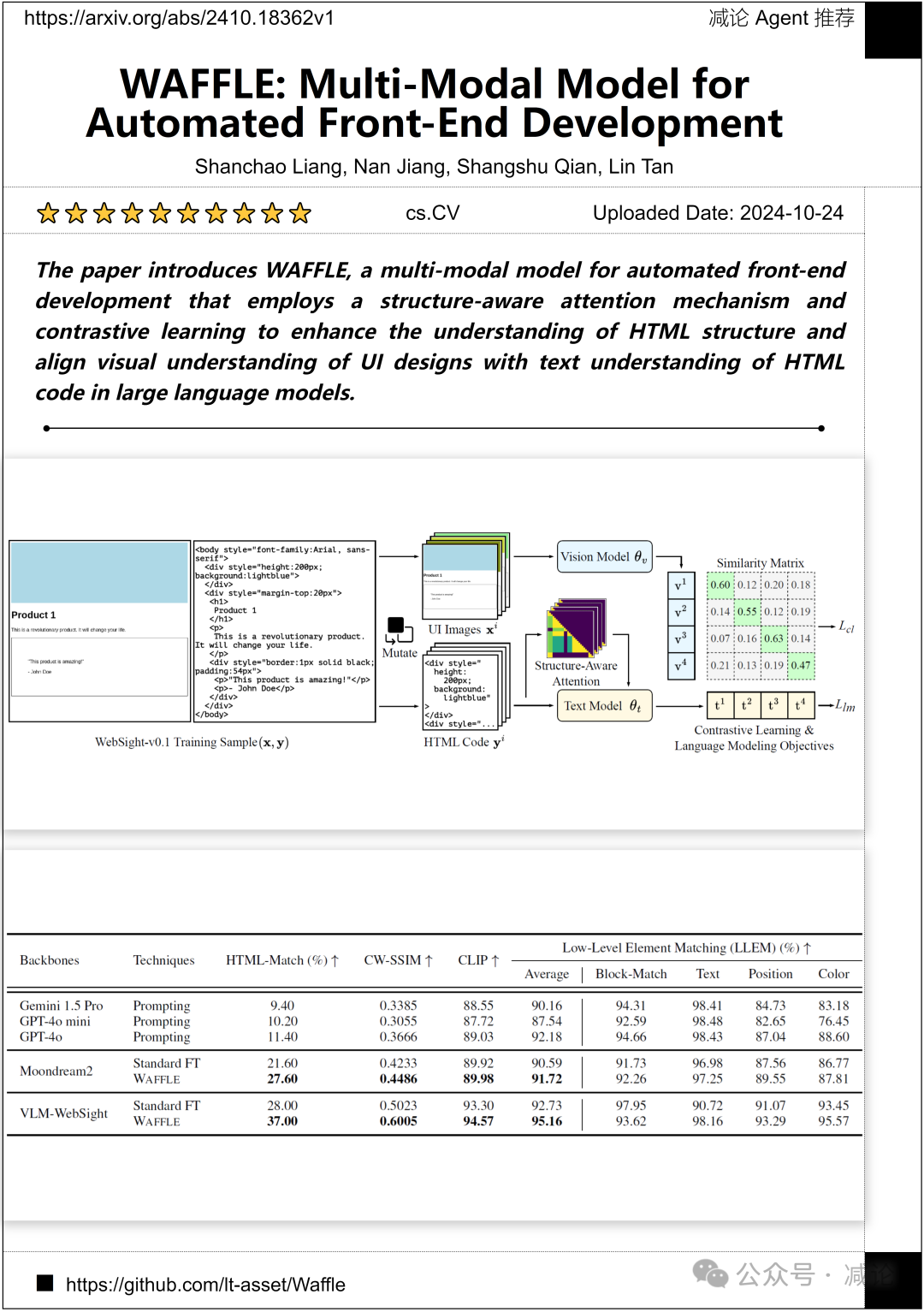
普渡大学 某某Fellow团队 提出了WAFFLE,这是一个多模态模型,用于自动化前端开发,它采用了结构感知注意机制和对比学习,以增强对HTML结构的理解,并将UI设计的视觉理解与大型语言模型中HTML代码的文本理解相一致。
http://arxiv.org/abs/2410.18362v1
https://github.com/lt-asset/Waffle

英伟达研究、厦门大学和南加州大学的团队提出了大空间模型(LSM)的框架。这个基于Transformer的方法可以将未经处理的RGB图像转换为语义辐射场,并且在单次前向传递中估计几何、外观和语义,从而实现自然语言驱动的场景操作。
http://arxiv.org/abs/2410.18956v1
https://largespatialmodel.github.io

清华大学和加州大学伯克利分校的研究团队介绍了PixelGaussian,这是一个用于从任意视角进行3D高斯重建的新型框架。该框架具有级联高斯适配器(CGA),可以根据局部几何复杂性动态调整3D高斯的数量和分布,以及迭代高斯细化器(IGR),利用可变形注意力来优化高斯表示。
http://arxiv.org/abs/2410.18979v1
https://github.com/Barrybarry-Smith/PixelGaussian

上海交通大学上海人工智能实验室团队介绍了生成空间变换器(GST)方法。该方法通过对相机进行标记并将其纳入自回归模型的训练中,同时与图像一起进行训练,实现了空间定位和视图预测的联合处理,成为空间意识和视觉预测的桥梁。
http://arxiv.org/abs/2410.18962v1
https://sotamak1r.github.io/gst/

延世大学 SIGIL 团队介绍了一种用于多模态风格翻译的框架。该框架利用字形潜在引导增强图像生成模型,结合预训练的VAEs进行稳定的风格引导,并通过强化学习反馈的OCR模型优化可读字符生成。这项研究旨在提高跨语言视觉文本设计转移中的风格一致性和可读性。
http://arxiv.org/abs/2410.18823v1
https://huggingface.co/datasets/yejinc/MuST-Bench
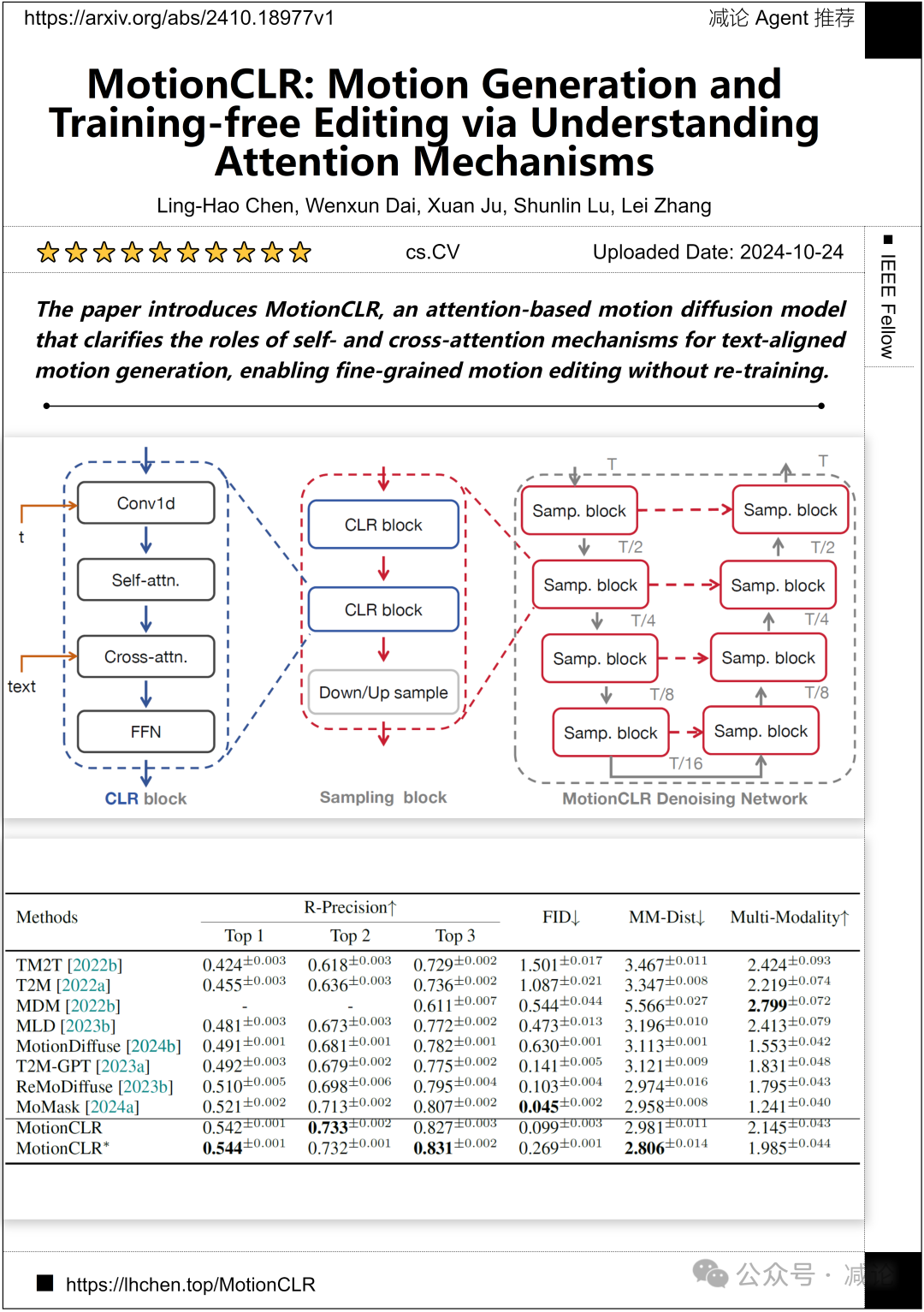
清华大学、香港中文大学IEEE Fellow团队提出了MotionCLR,一种基于注意力的运动扩散模型。该论文澄清了自注意力和交叉注意力机制在文本对齐运动生成中的作用,实现了精细的运动编辑而无需重新训练。
http://arxiv.org/abs/2410.18977v1
https://lhchen.top/MotionCLR
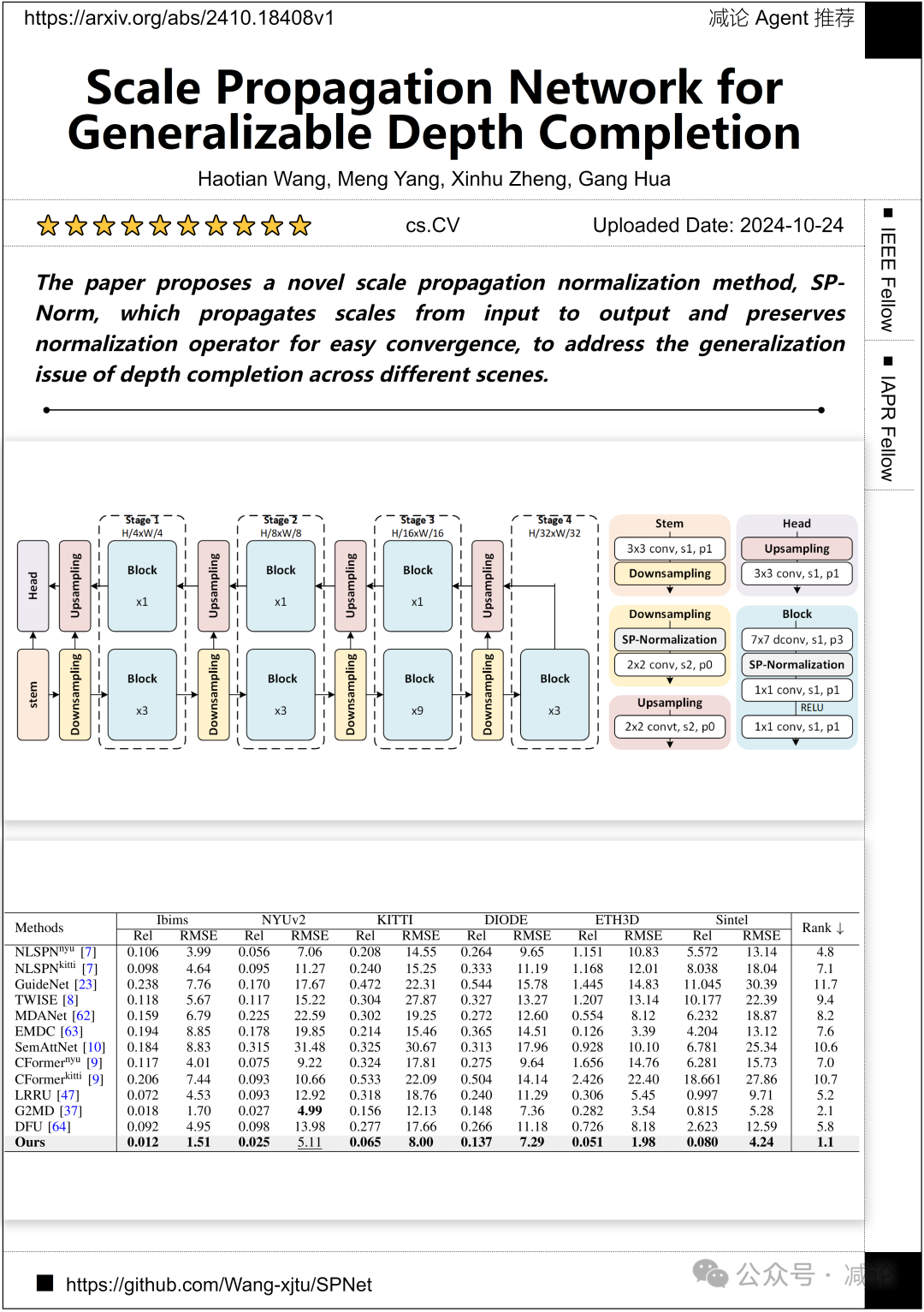
西安交通大学, 香港科技大学, 杜比实验室公司 提出了一种新颖的尺度传播归一化方法SP-Norm。该方法将尺度从输入传播到输出,并保留归一化运算符以便实现简单收敛,以解决深度完成在不同场景中的泛化问题。
http://arxiv.org/abs/2410.18408v1
https://github.com/Wang-xjtu/SPNet

欢迎关注减论,持续输出有深度的人工智能极减理解,提升信息获取效率和认知维度。看完点颗小星星再走呗~