
SAM介绍
主要内容
原文地址:
本研究介绍一种低成本、高通用性的正则化方法——Sharpness Aware Minimization(SAM),从优化器的角度提升模型的泛化性能。 林晓明 何康等,公众号:华泰证券金融工程华泰金工 | SAM:提升AI量化模型的泛化性能
本研究介绍了Sharpness Aware Minimization(SAM)优化器,这是一种低成本、高通用性的正则化方法,旨在从优化器的角度提升量化模型的泛化性能。通过在GRU基线模型上应用SAM优化器及其改进版本,研究表明SAM优化器能显著提升模型预测因子的多头端收益,并构建的指数增强组合业绩显著优于基线模型。核心观点如下
-
SAM优化器通过追求“平坦极小值”增强模型鲁棒性。
-
SAM优化器能降低训练过程中的过拟合,提升模型的泛化性能。
-
SAM优化器能显著提升AI量化模型表现。
1. SAM优化器与模型泛化性能
-
正则化方法的重要性
正则化方法通过改造损失函数或优化器、对抗训练、扩充数据集、集成模型等手段,使模型训练过程更加稳健,避免模型对训练数据的过拟合。
使模型更 “平滑” 结合多个模型
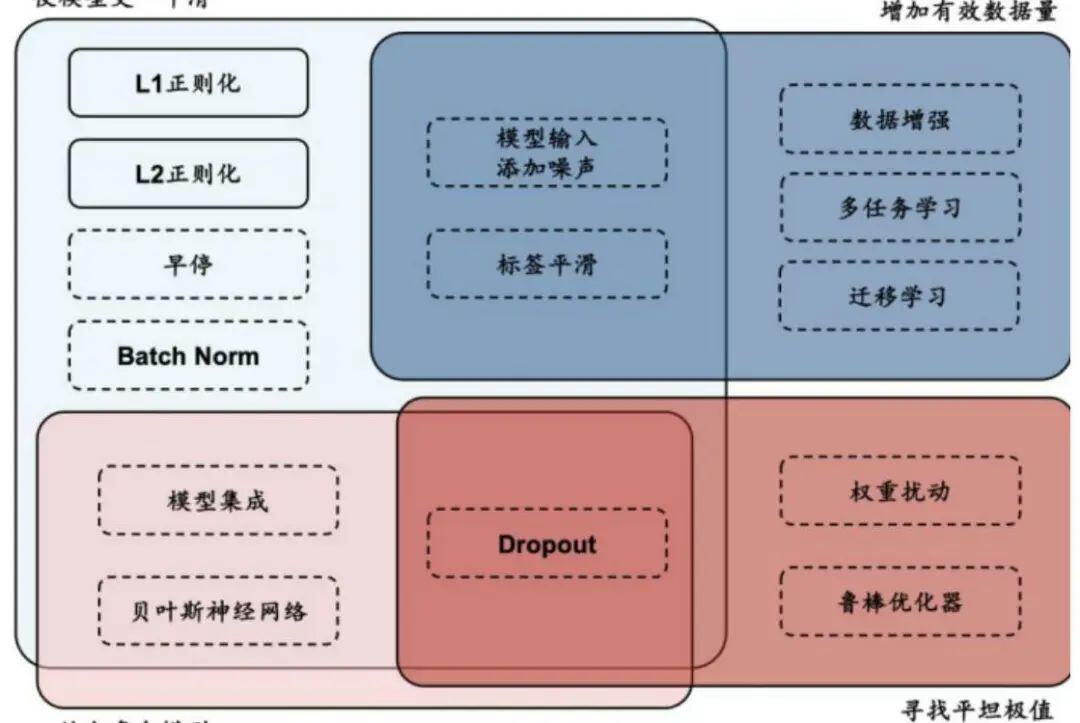

-
传统优化器的局限性
传统优化器如SGD、Adam等在梯度下降时易落入”尖锐极小值”,导致模型对输入数据分布敏感度高,泛化性能较差。

-
SAM优化器的原理
SAM优化器将损失函数的平坦度加入优化目标,不仅最小化损失函数值,同时最小化模型权重点附近损失函数的变化幅度,使优化后模型权重处于一个平坦的极小值处,增加了模型的鲁棒性。
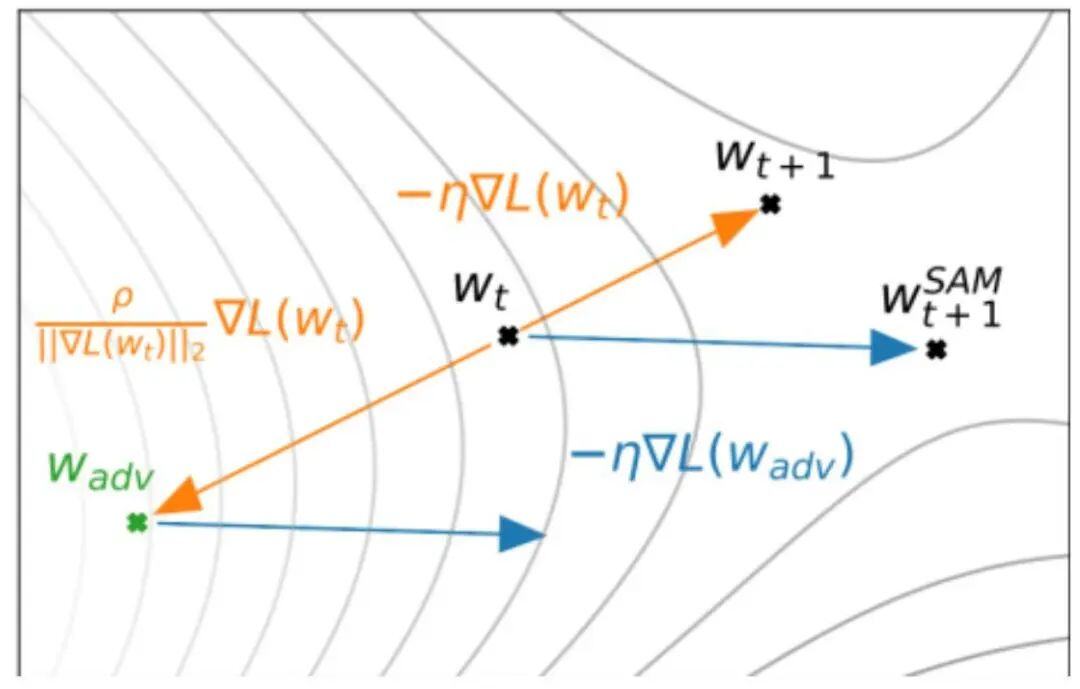
2. SAM优化器的改进
-
ASAM:提出了与参数尺度无关的自适应锐度,能够更好地衡量泛化边界。
-
GSAM : 定义Surrogate Gap作为优化目标,对梯度垂直方向的分量进行梯度上升,避免对扰动损失的影响。
-
GAM:引入了一种更强的平坦度度量,同时优化参数的零阶平坦度(损失函数平坦度)以及一阶平坦度(梯度平坦度)。 -
FSAM:发现了SAM中全梯度成分对泛化性能的负面影响,并利用随机梯度噪声来提高泛化性能。
-
ESAM:提出了随机权重扰动和锐度敏感数据选择方法,提高SAM的效率。
-
SSAM:提出一种采用稀疏扰动的方法,通过掩码减少增强优化器的性能。
-
LookSAM:提出一种周期性计算内层梯度上升的算法,减少计算成本。
-
RST:提出RST优化器,在每个训练迭代中执行伯努利试验来随机选择使用基础优化器(如SGD) 还是SAM进行优化,节省计算成本。
3. 实验结果
-
模型收敛性:SAM模型在验证集上IC、IR指标下降幅度较缓,训练过程中指标最大值均高于基线模型,证明SAM优化器有效抑制了过拟合,提升了模型的泛化性能。
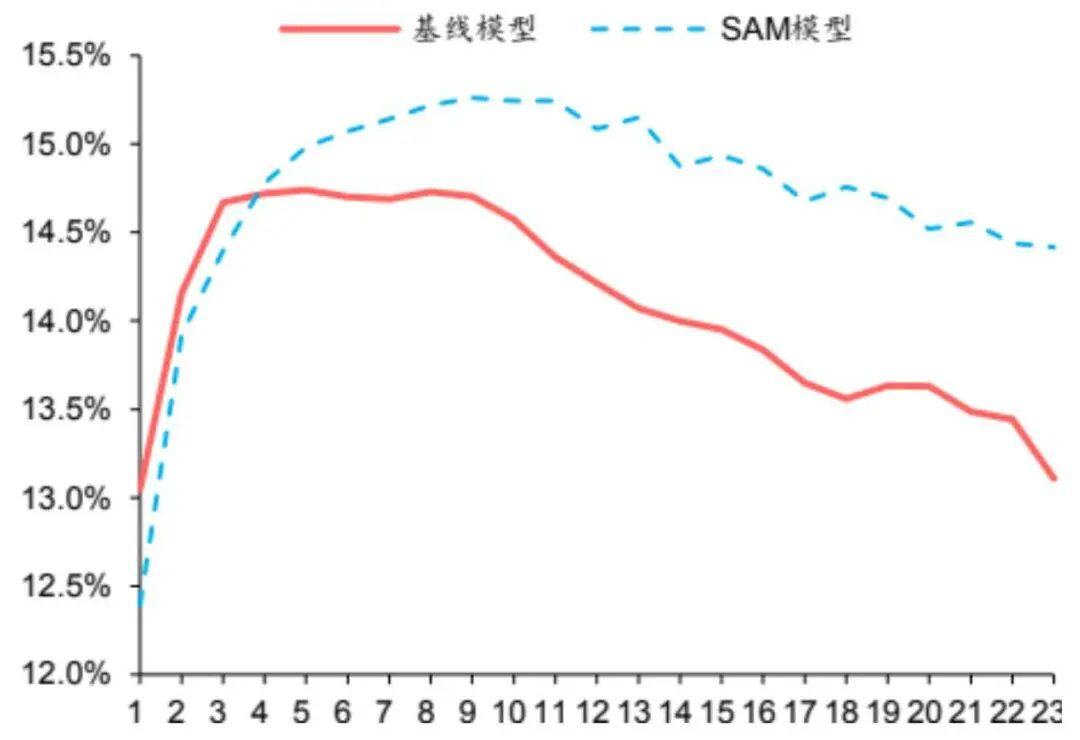
-
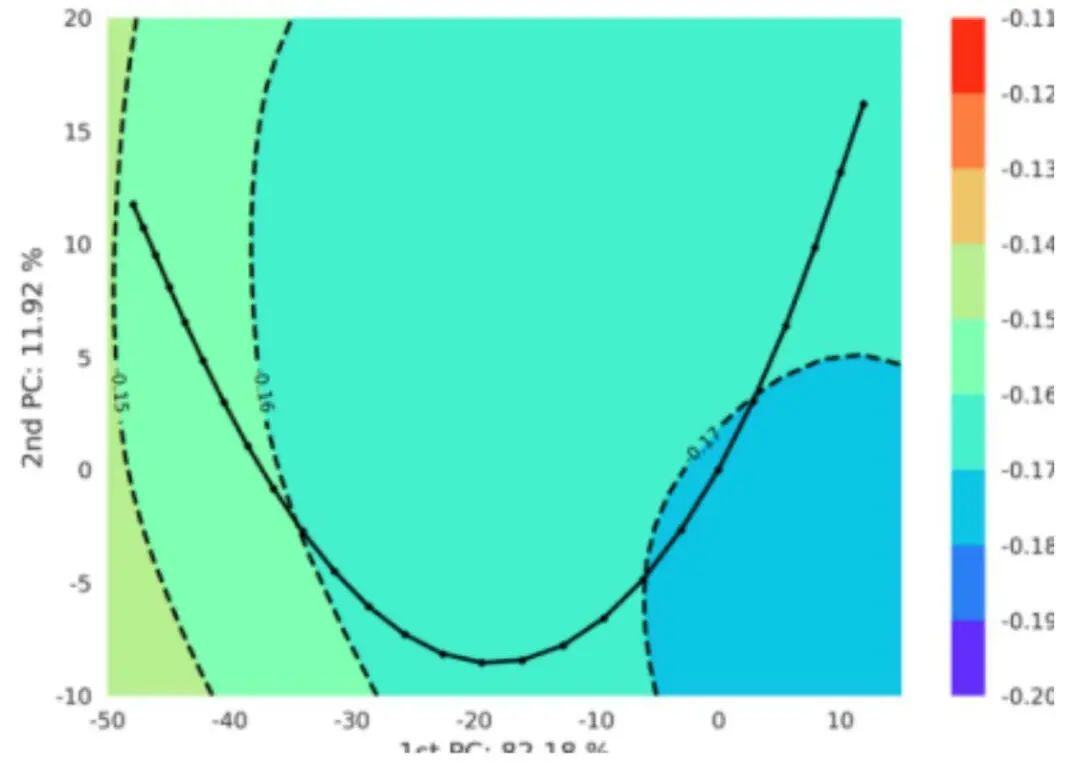
损失函数地形:SAM模型在训练集上损失函数地形相较基线模型更加平坦,测试集上损失函数值整体更低。
-
因子表现:SAM模型及其改进版本模型在单因子测试中TOP组收益率均高于基线模型,证明应用SAM优化器能有效改善预测因子多头端预测准确性,提升多头组表现。
-
指数增强组合业绩:SAM模型及其改进版本模型在三组指数增强组合业绩均显著优于基线模型。2016-12-30至20 24-09-30内,综合表现最佳模型为GSAM模型,单因子回测TOP层年化超额收益高于31%,沪深300、中证500和中证1000增强组合年化超额收益分别为10.9%、15.1%和23.1%,信息比率分别为1.87、2.26和3.12。2024年以来ASAM模型表现突出,三组指数增强组合超额收益均领先基线模型约5%。
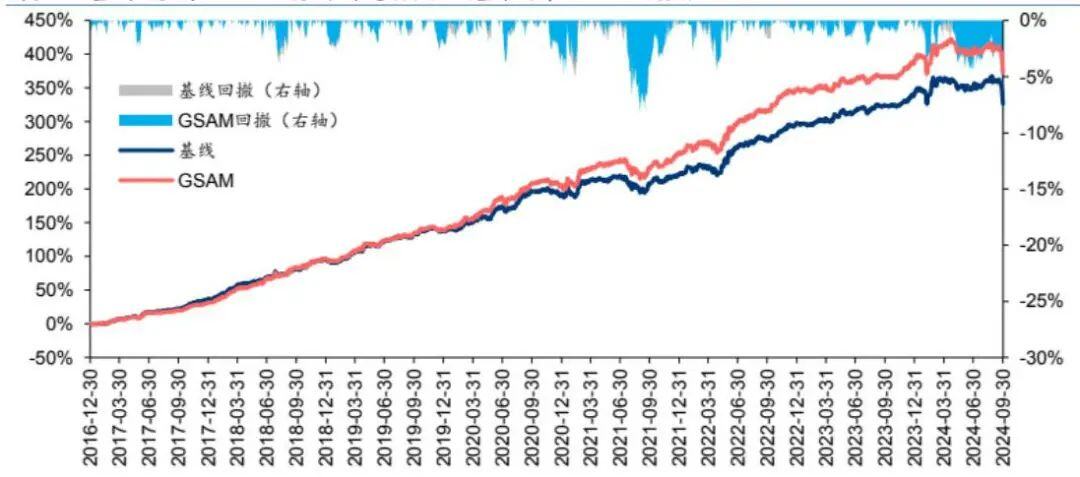
本研究通过实验验证了SAM优化器在提升AI量化模型泛化性能方面的有效性。SAM优化器通过追求”平坦极小值”,不仅增强了模型的鲁棒性,还能有效降低训练过程中的过拟合,显著提升模型的泛化性能 。基于SAM优化器构建的指数增强组合业绩显著优于基线模型,特别是GSAM模型和ASAM模型在长时间和短时间的回测中均表现出色。
QuantML-Qlib 实现
SAM优化器的代码已经加入QuantML-Qlib,目前在qlib/utils/optim.py之中,包括GSAM和ASAM代码也已经加入。
接下来在GRU中使用SAM进行训练,对比传统ADAM的效果。由于SAM是一个两步训练过程,因此需要对模型代码进行修改,相关的代码在qlib/contrib/model/pytorch_gru_ts.py中,其他模型也可参考实现SAM优化器训练。
在config文件中加入:
optimizer: sam
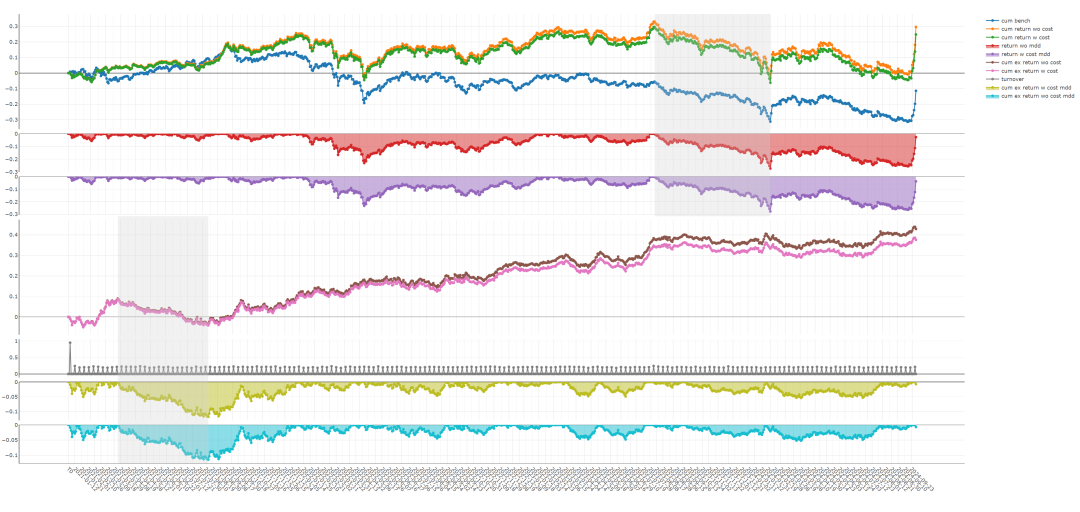
即可将优化器改为SAM,在中证500中进行测试。与ADAM相比,IC由0.063降为0.045。
回测效果如下:
ADAM:
SAM:
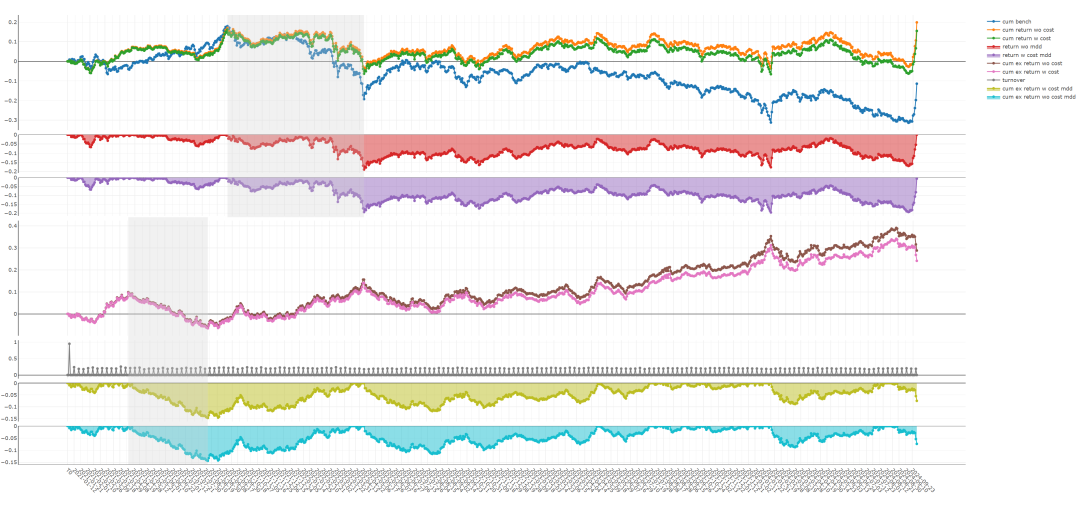
效果与研报结论有所出入,还需进一步测试。