
本文旨在解决加密货币交易中深度强化学习(DRL)的回测过拟合问题,并提出了一种实用方法来提高交易策略的可靠性和盈利能力。文章首先将回测过拟合的检测形式化为假设检验,然后训练DRL代理,估计过拟合的概率,并拒绝过拟合的代理,从而增加良好交易表现的可能性。在2022年5月1日至6月27日的测试期间(期间加密货币市场崩溃两次),研究表明,较少过拟合的深度强化学习代理比更多过拟合的代理、等权重策略和标准普尔DBM指数(市场基准)具有更高的回报,为实际市场部署提供了信心。
1. 引言
在加密货币市场中,设计盈利且可靠的交易策略至关重要。现有的深度强化学习方法在加密货币投资组合配置和交易执行方面显示出潜力,但面临三大挑战:市场的高波动性、历史市场数据的低信噪比以及市场的大幅波动。现有研究可能受到回测过拟合问题的影响,这是一个误报问题。研究者在回测过程中可能“幸运地”获得了一个过于乐观的代理(过拟合的代理)。本文提出了一种实用方法来解决回测过拟合问题,通过估计过拟合的概率来检测模型过拟合,并在概率超过预设阈值时拒绝该代理。
2. 相关工作
现有研究可分为三类:使用向前看方法的回测、使用交叉验证方法的回测和带有超参数调整的回测。向前看方法在单一市场情况下进行验证,容易导致过拟合。K折交叉验证方法假设训练和验证集来自独立同分布(IID)过程,这在金融市场中不成立。DRL算法对超参数非常敏感,导致DRL算法的性能变化很大。FinRL-Podracer等研究采用了云平台上的进化策略来训练交易代理,通过不同超参数的排名选择回报最高的代理。

3. 使用深度强化学习的加密货币交易
本章节详细介绍了如何将加密货币交易任务建模为马尔可夫决策过程(MDP),并构建了市场环境,以及训练交易代理的一般设置。
3.1 建模加密货币交易
作者将交易任务建模为MDP,其中包括状态(state)、动作(action)、奖励(reward)和策略(policy)四个要素。具体来说:
-
状态(State):由账户现金(bt)、持股(ht)、价格(pt)和特征向量(ft)组成。特征向量包括交易量、RSI、DX、ULTSOC、OBV和HT等六个技术指标。 -
动作(Action):DRL代理根据观察到的市场情况采取交易动作,动作at会改变持股ht。 -
奖励(Reward):定义为采取动作at后投资组合价值的变化,即r(st, at, st+1) = vt+1 – vt,其中vt是时间t的投资组合价值。 -
策略(Policy):是关于在状态st下采取动作at的概率分布π(at|st)。
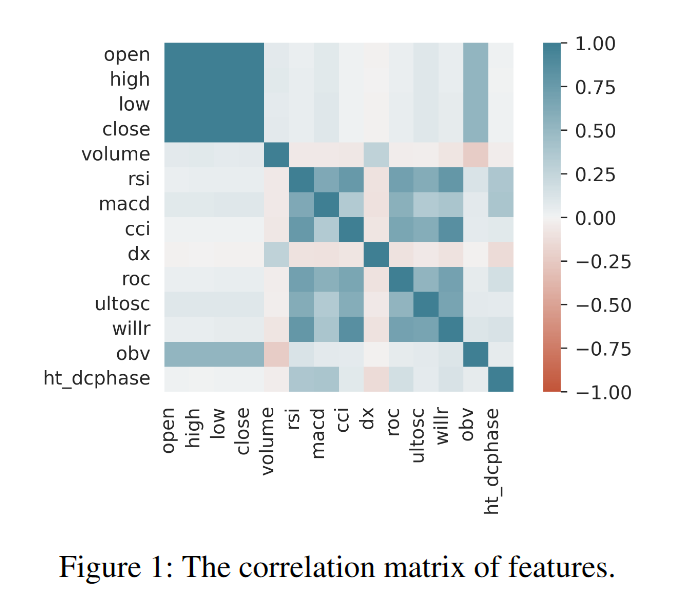
在特征选择上,作者通过计算特征间的皮尔逊相关系数来避免多重共线性,最终保留了六个技术指标作为特征向量ft的组成部分。此外,状态st中的pt选择了时间段[t, t+1]的收盘价。
3.2 构建市场环境
市场环境通过重放历史数据构建,遵循OpenAI Gym的风格。交易代理与市场环境进行多次交互,每个交互重放市场数据的时间序列。环境具有以下三个功能:
-
reset函数:将环境重置为初始状态s0,包括初始投资资本b0和零持股h0。 -
step函数:接受动作at并更新状态st到st+1,通过查找市场数据的时间序列来获取pt+1和ft+1,并更新bt+1和ht+1。 -
reward函数:计算r(st, at, st+1) = vt+1 – vt作为奖励,其中vt是时间t的投资组合价值。
此外,还考虑了交易成本、非负余额和风险控制等交易约束。
3.3 训练交易代理
交易代理通过学习策略π(at|st)来最大化折扣累积回报R = ∑∞t=0 γtr(st, at, st+1),其中γ是折扣因子。代理使用各种DRL算法进行训练,如TD3、SAC和PPO。训练过程中,超参数的选择对代理的交易表现有很大影响。因此,作者在训练阶段尝试了多组超参数,并选择了表现最佳的超参数集进行整体训练。
3.4 回测过拟合问题
回测使用历史数据模拟市场,评估代理的性能。然而,DRL代理通常会过度拟合单个验证集,从而对实际交易性能产生疑问。过拟合发生在DRL代理过度适应历史训练数据时,学习到的模式在未见状态下可能并不存在,从而损害了DRL代理的性能。
4. 解决回测过拟合的实用方法
第四章详细阐述了作者提出的解决加密货币交易中深度强化学习(DRL)模型回测过拟合问题的具体方法。该方法的核心在于通过假设检验来识别并拒绝过拟合的代理模型,从而提高模型在实际交易中的泛化能力。
4.1 假设检验以拒绝过拟合代理
作者首先将回测过拟合的检测问题形式化为一个假设检验问题:
-
零假设 :过拟合概率 ,代理没有过拟合。 -
备择假设 :过拟合概率 ,代理过拟合。
这里, 是显著性水平,用于控制第一类错误(错误地拒绝零假设)的概率。作者根据Neyman-Pearson框架来设定 的值。
4.2 估计过拟合概率
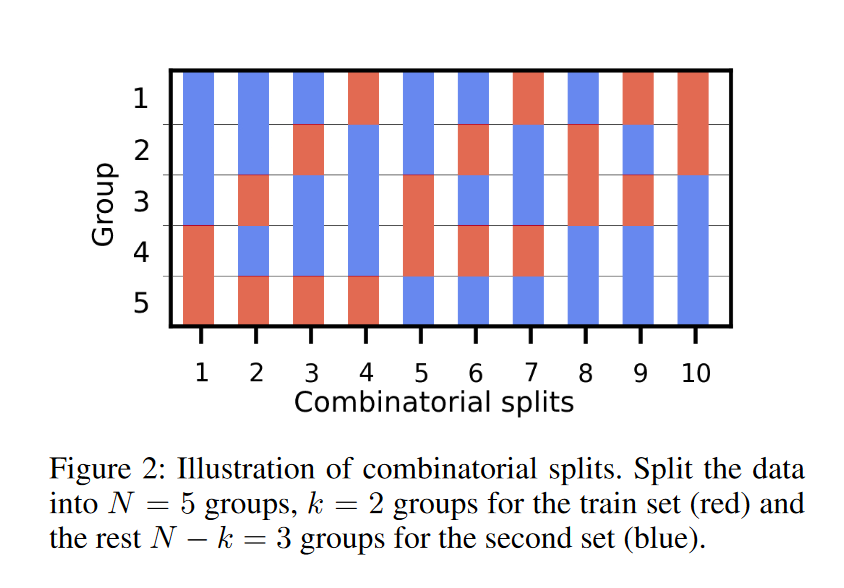
为了估计过拟合概率,作者采用了组合交叉验证方法。具体步骤如下:
-
训练-验证数据分割:将训练期间的数据分为 组,每组包含 个数据点作为验证集,其余作为训练集,形成 个不同的训练-验证数据分割。
-
超参数调整:在每个训练-验证数据分割中,使用一组新的超参数训练代理,并在验证集上评估其性能。
-
性能评估:对所有验证集的性能指标取平均值,得到每个超参数试验的平均性能指标 。
-
计算过拟合概率:将 次试验的平均性能指标堆叠成矩阵 ,然后基于矩阵 计算过拟合概率 。
-
将矩阵 分成多个子集,每个子集代表一个样本 。 -
对于每个样本 ,计算其在训练集(IS)和验证集(OOS)上的性能排名。 -
定义相对排名 和logit函数 ,用以衡量IS和OOS性能之间的一致性。 -
过拟合概率 通过计算logit函数的分布函数 来得到。
-
5. 性能评估
本章节旨在验证所提出的解决回测过拟合问题的方法是否能够提高交易代理在实际市场中的表现。研究者通过对比不同深度强化学习(DRL)代理的策略,评估了它们在历史数据上的表现,并与市场基准进行了比较。
5.1 实验设置
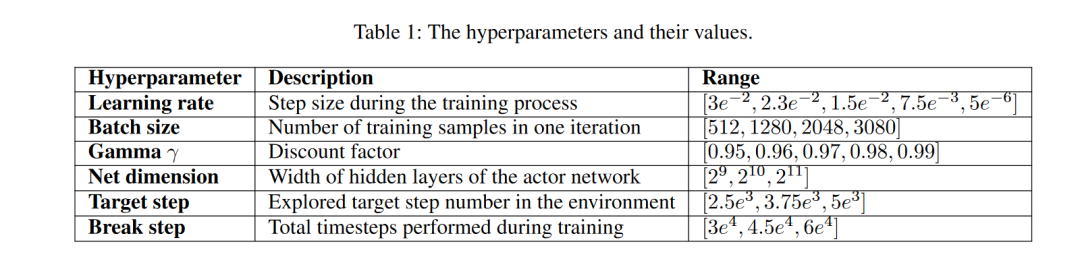
实验涉及10种高交易量加密货币,使用2022年2月2日至6月27日的五分钟级数据。数据被分为训练期和测试期,后者包含了两次市场崩溃。训练数据进一步被划分为多个组合交叉验证集,以估计过拟合概率。实验中调整了六个关键超参数,并进行了50次试验以确保选择的超参数集能够代表最优解。
5.2 比较方法和性能指标
研究者比较了传统DRL代理和不同超参数调整的DRL代理。选择了三种流行的DRL算法:TD3、SAC和PPO,并计算了每种算法在不同超参数设置下的过拟合概率。性能指标包括累积回报、波动性和过拟合概率。
实验将DRL代理的表现与等权重策略和标准普尔加密货币宽数字市场指数(S&P BDM指数)进行了比较。
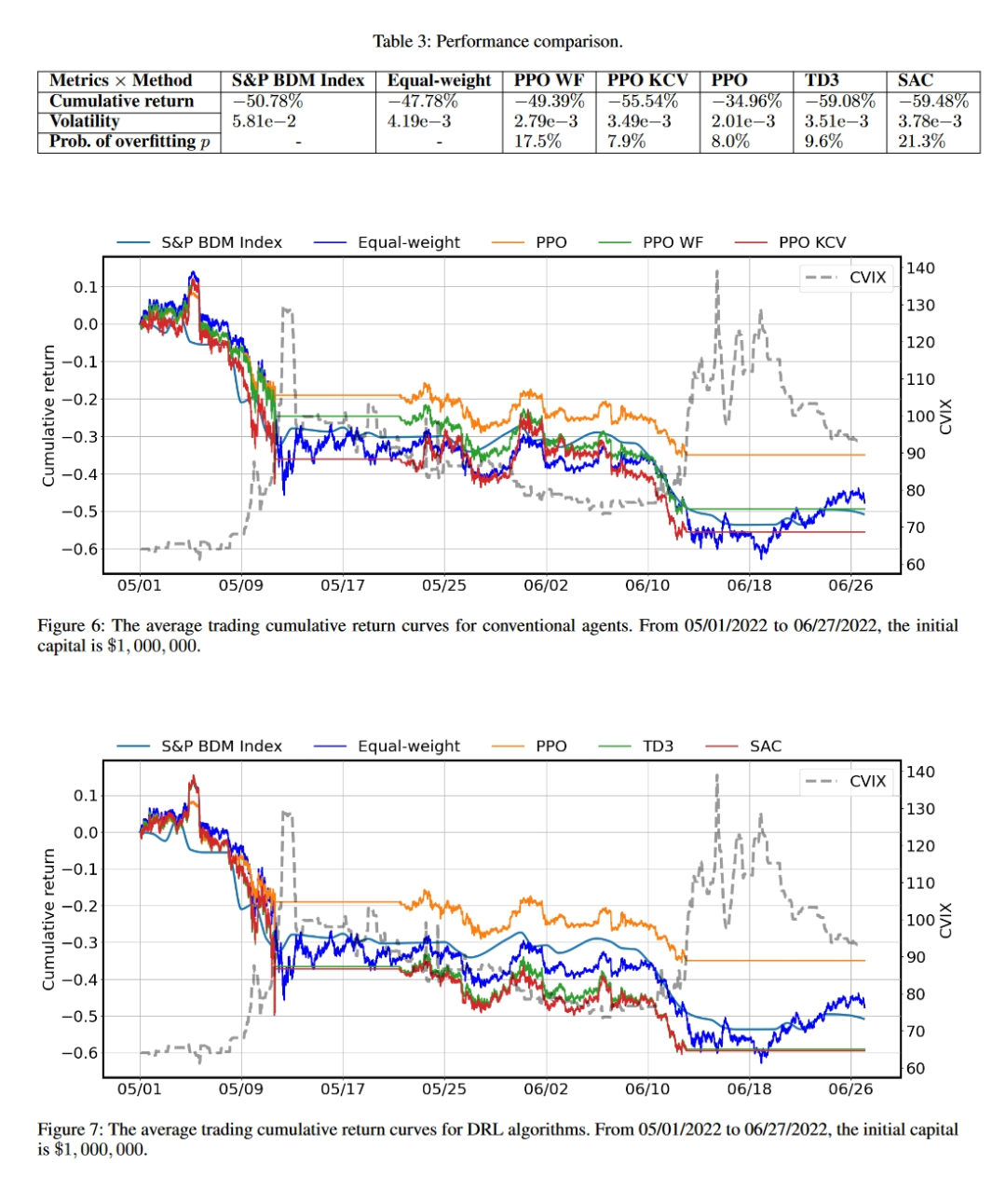
5.3 拒绝传统代理
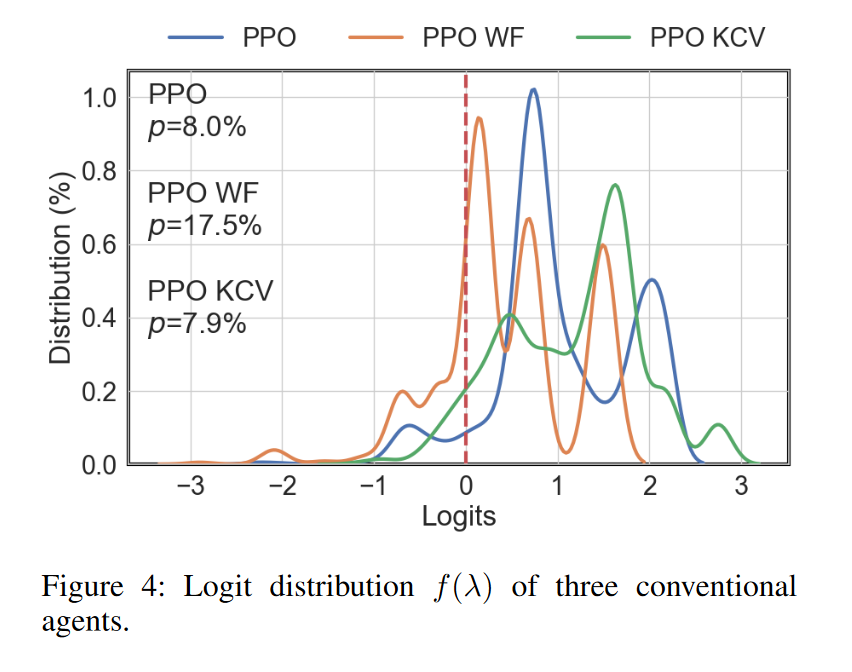
实验结果显示,使用向前看方法的传统代理具有较高的过拟合概率(17.5%),而使用K折交叉验证方法的代理过拟合概率较低(7.9%)。这表明简单的向前看方法容易导致过拟合。
5.4 拒绝过拟合代理
通过调整超参数,研究者发现SAC算法的过拟合概率最高(21.3%),而PPO算法的过拟合概率最低(8.0%)。这表明通过超参数调整可以降低过拟合风险。
5.5 回测表现
在市场波动性高的测试期间,PPO代理的表现优于其他DRL代理和市场基准。PPO代理在累积回报和波动性方面均表现出色,显示了较好的鲁棒性和盈利能力。
结论
本文提出了一种实用的方法来解决深度强化学习在加密货币交易中回测过拟合的问题。通过将回测过拟合的检测形式化为假设检验,并结合组合交叉验证方法,文章成功地估计并拒绝了过拟合的DRL代理。在2022年5月1日至6月27日的测试期间,使用10种高交易量加密货币进行的实验表明,选择的PPO代理在累积回报和波动性方面均优于传统的向前看方法和K折交叉验证方法,以及其他DRL代理和市场基准。
研究表明,通过精心设计的回测方法和超参数调整,可以显著提高DRL代理在实际市场中的表现。PPO代理因其较低的过拟合概率和较高的累积回报而被认定为最优的交易策略。此外,实验结果还表明,提出的回测方法能够有效地识别和拒绝过拟合的代理,从而提高了交易策略的可靠性和盈利能力。