
2024年10月23日Arxiv cs.CV发文量约86余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省36分钟浏览Arxiv的时间。


澳大利亚国立大学、慶應義塾大学和南开大学的研究团队提出了一种多模态方法,通过引入多模态指导调整数据集(ColonINST)、多模态语言模型(ColonGPT)和多模态基准来促进结肠镜检查中的多模态研究。
http://arxiv.org/abs/2410.17241v1
https://github.com/ai4colonoscopy/IntelliScope
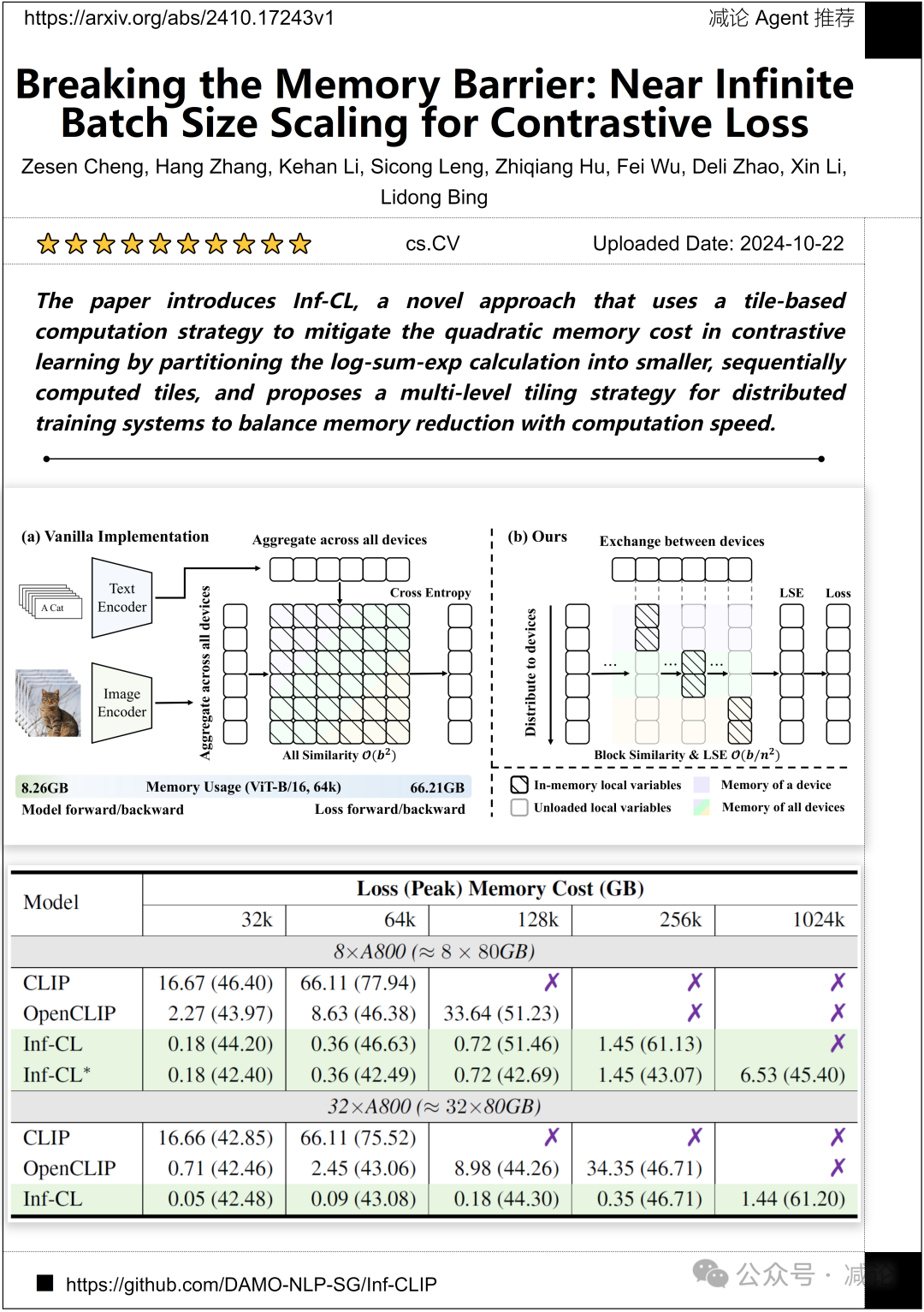
达摩院、阿里巴巴集团、浙江大学和南洋理工大学的研究人员提出了一种新颖的方法,名为Inf-CL。该方法使用基于瓦片的计算策略,旨在减轻对比学习中的二次内存成本。通过将对数–求和–指数计算划分为较小的、顺序计算的瓦片,并提出多级划分策略,用于分布式训练系统,以平衡内存减少和计算速度。
http://arxiv.org/abs/2410.17243v1
https://github.com/DAMO-NLP-SG/Inf-CLIP
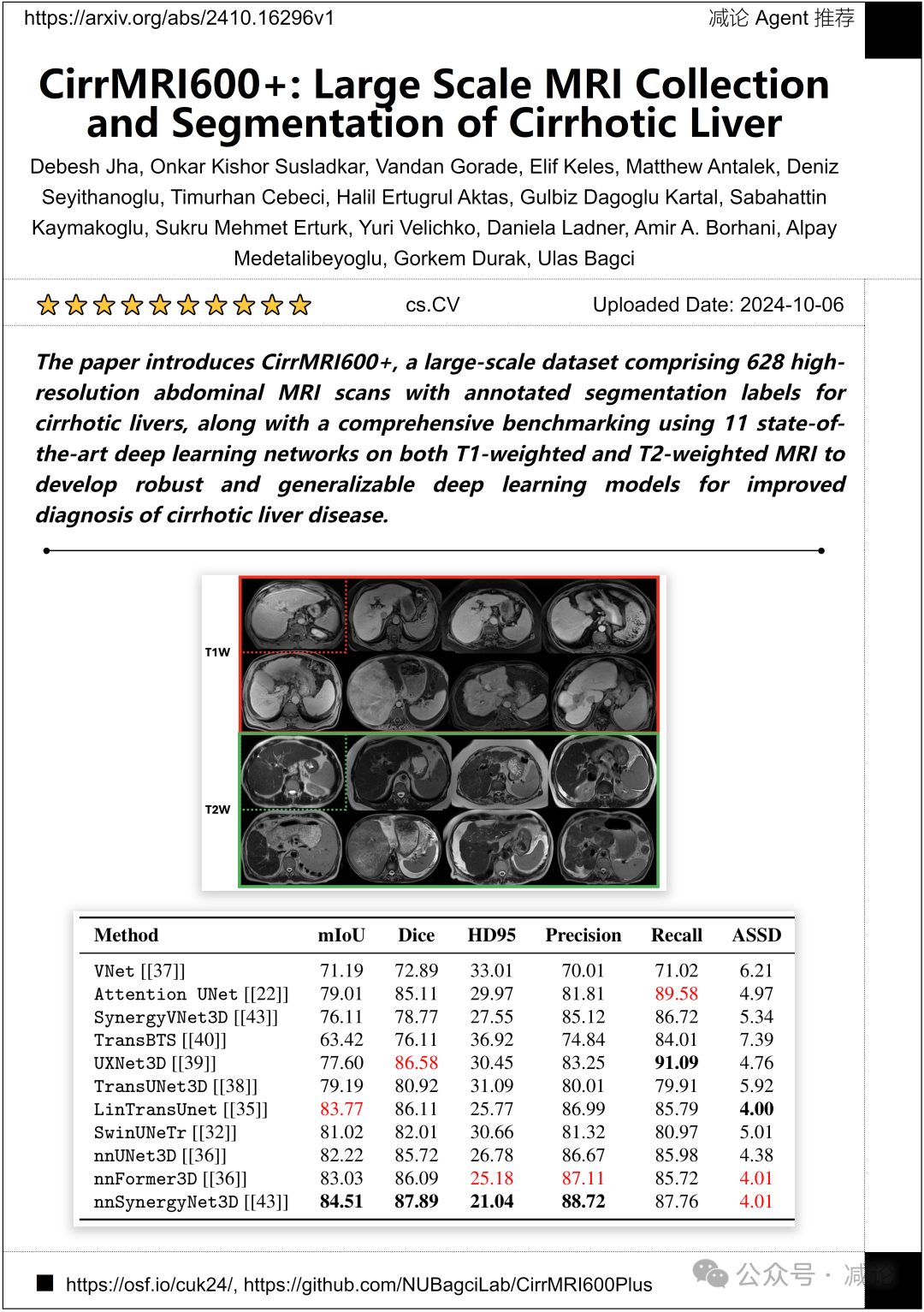
西北大学和伊斯坦布尔大学的研究团队介绍了CirrMRI600+,这是一个大规模数据集,包括628个高分辨率腹部MRI扫描,带有肝硬化肝脏的分割标签。他们使用11种最先进的深度学习网络在T1加权和T2加权MRI上进行全面基准测试,以开发出更可靠和通用的深度学习模型,用于改善肝硬化肝病的诊断。
http://arxiv.org/abs/2410.16296v1
https://osf.io/cuk24/, https://github.com/NUBagciLab/CirrMRI600Plus

南京理工大学和SeetaCloud团队推出了一篇论文,介绍了MPDS数据集,该数据集包含373k+图像文本对,专为电影海报生成而设计。同时,他们提出了一种多条件扩散框架,用于利用该数据集生成个性化电影海报。
http://arxiv.org/abs/2410.16840v1
https://anonymous.4open.science/r/MPDS-373k-BD3B

东京大学和卡内基梅隆大学的研究团队介绍了JMMMU方法,用于评估大型多模态模型在专家级别、文化特定任务上的表现,包括文化无关和文化特定子集。
http://arxiv.org/abs/2410.17250v1
https://mmmu-japanese-benchmark.github.io/JMMMU/
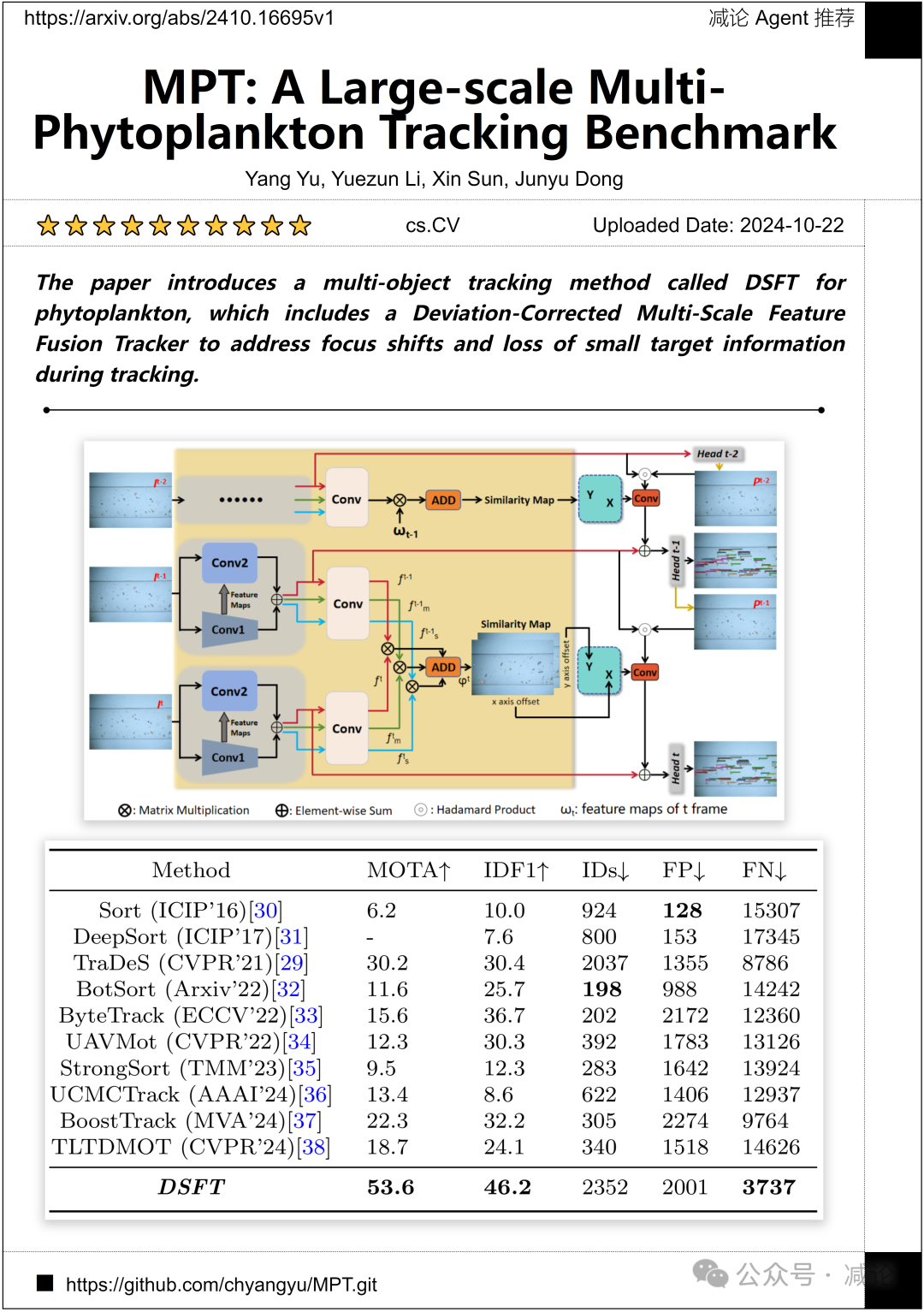
中国海洋大学和澳门城市大学提出了一种名为DSFT的多目标跟踪方法,其中包括一个修正偏差的多尺度特征融合跟踪器,以解决跟踪过程中的焦点转移和小目标信息丢失问题。
http://arxiv.org/abs/2410.16695v1
https://github.com/chyangyu/MPT.git
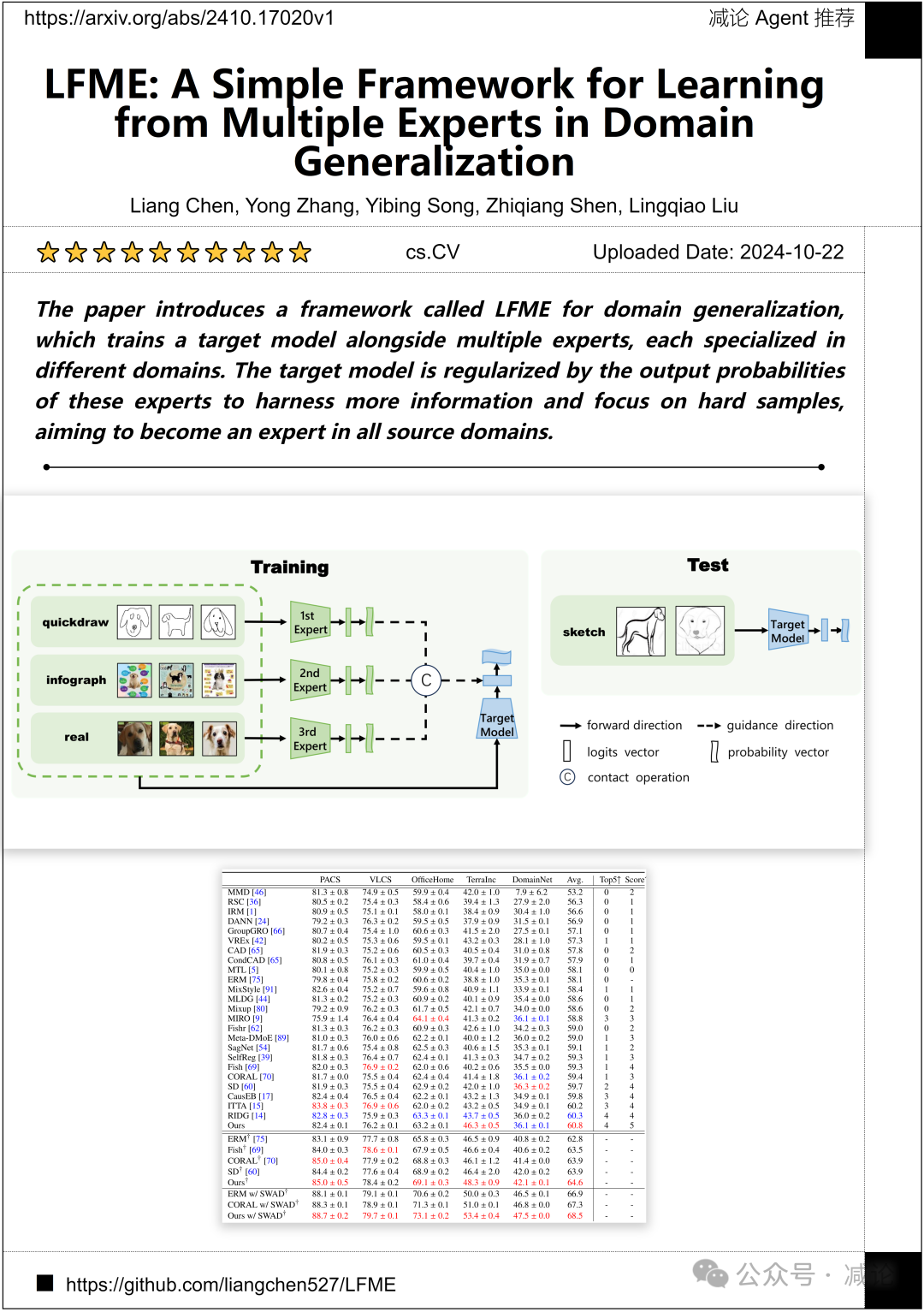
迪拜人工智能大学,美团点评,阿德莱德大学的研究团队提出了一个名为LFME的框架,用于领域泛化。该框架在训练目标模型的同时,还与多个专家一起工作,每个专家专门针对不同的领域。目标模型通过这些专家的输出概率进行正则化,以获取更多信息并专注于难样本,旨在成为所有源领域的专家。
http://arxiv.org/abs/2410.17020v1
https://github.com/liangchen527/LFME
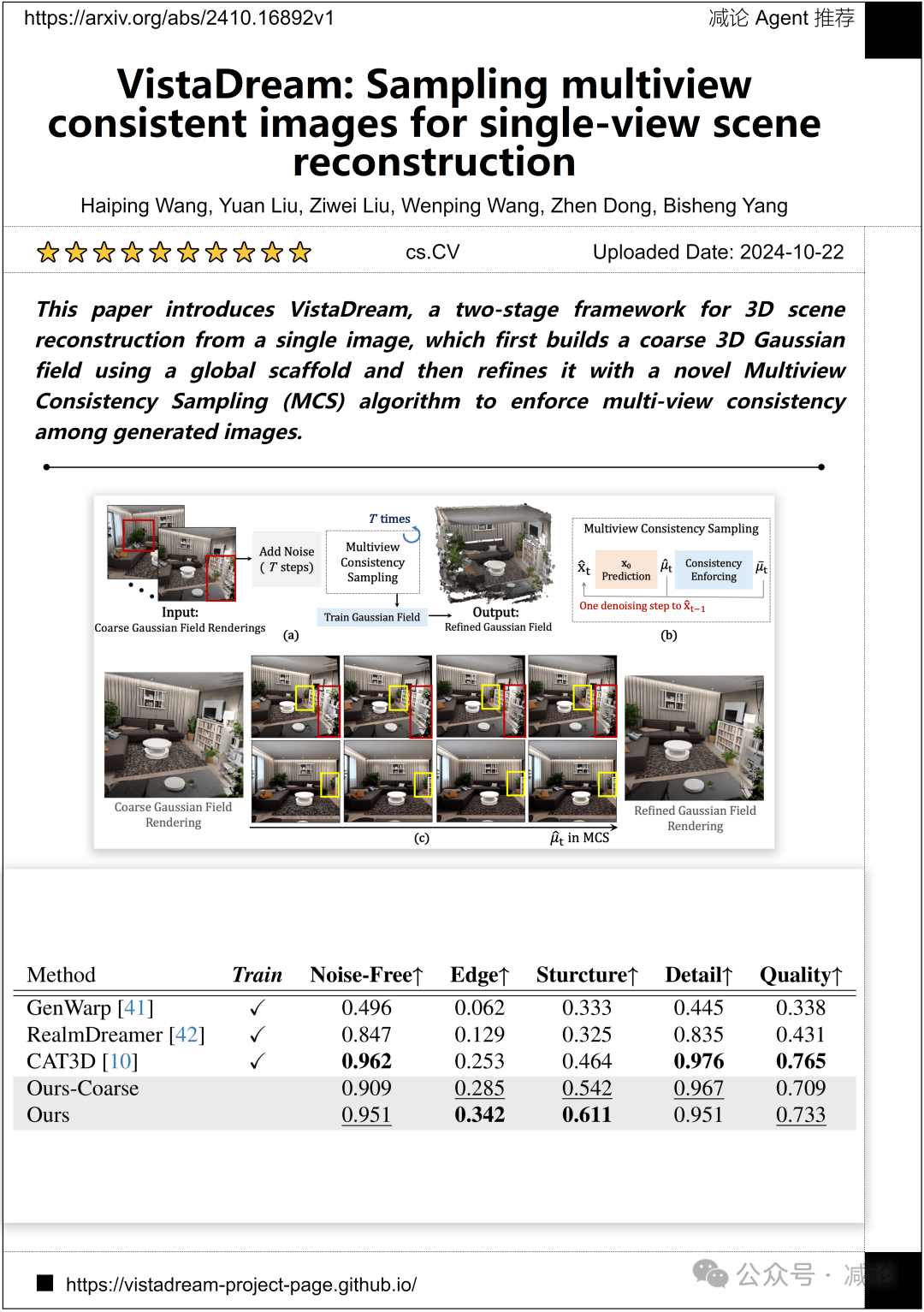
武汉大学、香港科技大学和德克萨斯农工大学的研究团队提出了VistaDream,一个用于从单个图像重建3D场景的两阶段框架。首先利用全局支架构建粗糙的3D高斯场,然后利用一种新颖的多视角一致性采样(MCS)算法对其进行优化,以强化生成图像之间的多视角一致性。
http://arxiv.org/abs/2410.16892v1
https://vistadream-project-page.github.io/
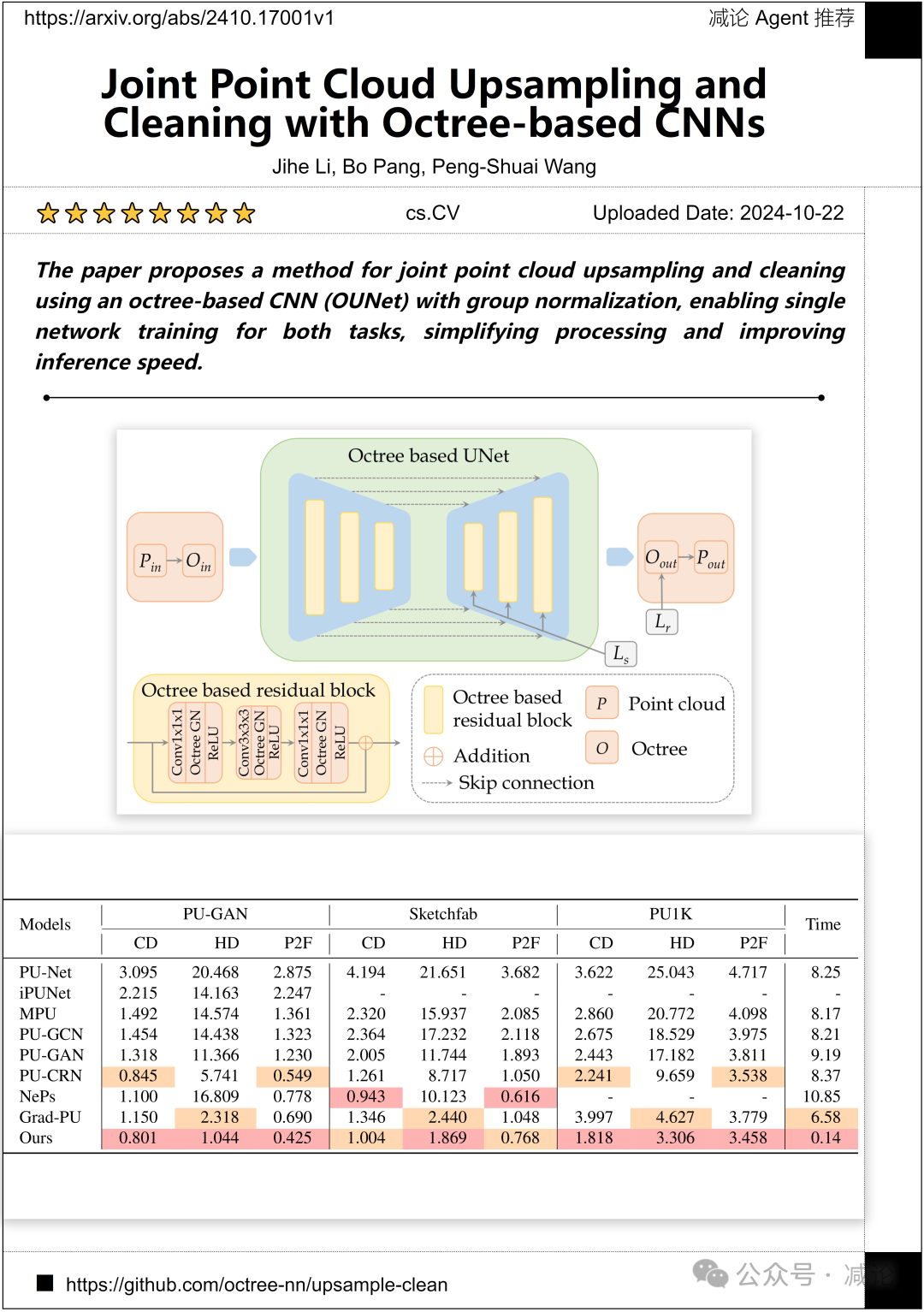
北京大学的研究团队提出了一种基于八叉树的CNN(OUNet)和组归一化的联合点云上采样和清洗方法,实现了两个任务的单一网络训练,简化了处理过程并提高了推理速度。
http://arxiv.org/abs/2410.17001v1
https://github.com/octree-nn/upsample-clean

国立阳明交通大学和伊利诺伊大学厄巴纳–香槟分校的团队提出了SpectroMotion方法。该论文介绍了SpectroMotion,一种将3D高斯飞溅与基于物理的渲染和变形场相结合的方法,通过使用残差校正技术进行表面法线计算,使用可变形环境贴图适应时变光照条件,并采用粗到细的训练策略来重建动态镜面场景。
http://arxiv.org/abs/2410.17249v1
https://cdfan0627.github.io/spectromotion/
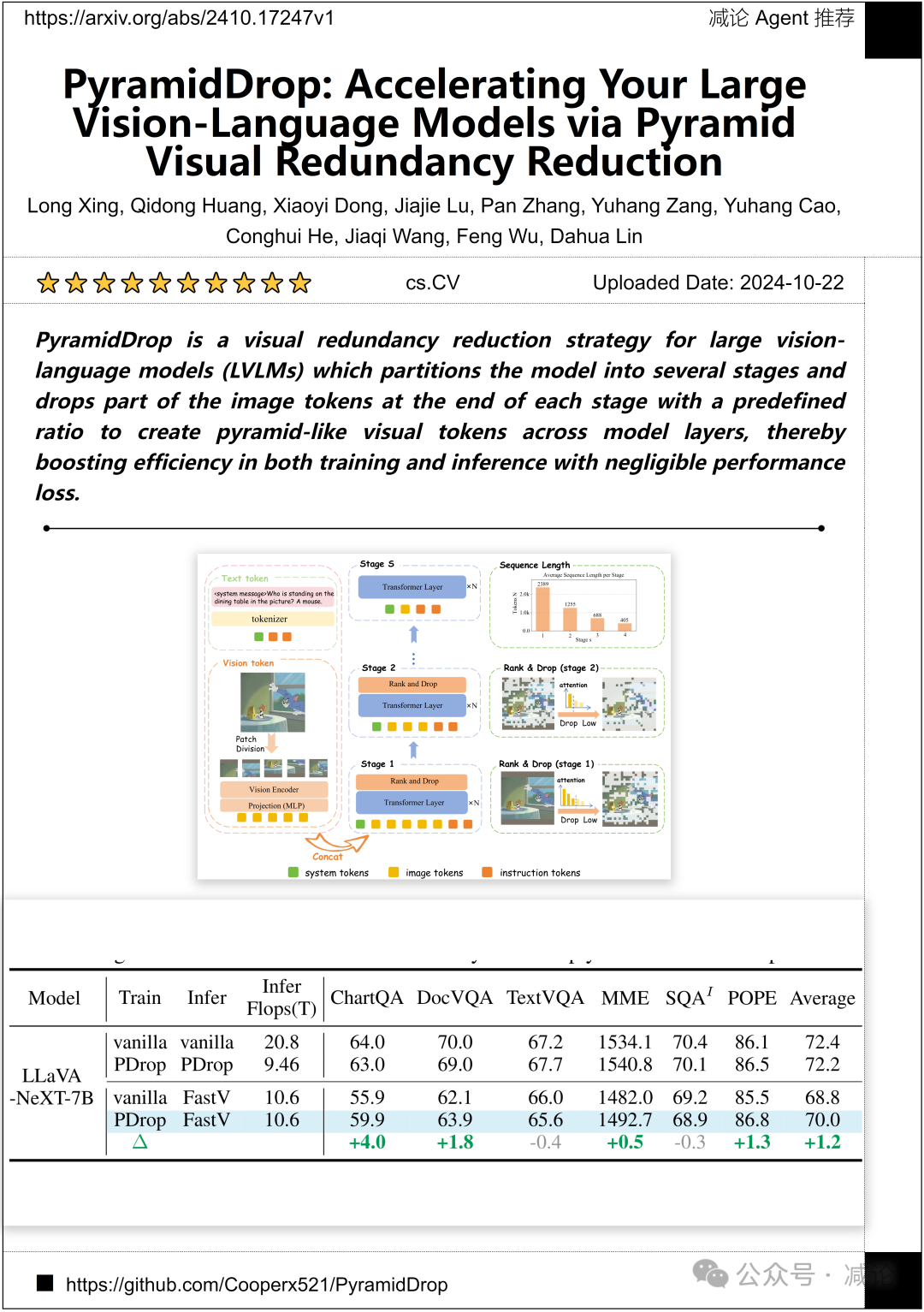
中国科学技术大学、香港中文大学和上海人工智能实验室的研究团队提出了PyramidDrop方法,这是一种用于大型视觉–语言模型(LVLMs)的视觉冗余减少策略。该方法将模型分成几个阶段,在每个阶段末尾丢弃部分图像标记,以预定义的比例创建类似金字塔的视觉标记跨模型层,从而提高训练和推理的效率,同时几乎没有性能损失。
http://arxiv.org/abs/2410.17247v1
https://github.com/Cooperx521/PyramidDrop

北京大学、西湖大学、卡内基梅隆大学的研究团队提出了Score Implicit Matching(SIM)方法。该方法将预训练扩散模型提炼为一步生成器模型,而不会影响原始模型的性能。SIM基于这样一个思想,即可以高效计算扩散模型和生成器之间某些基于分数的差异的梯度,从而实现对差异的隐式最小化。
http://arxiv.org/abs/2410.16794v1
https://github.com/maple-research-lab/SIM

北京航空航天大学、字节跳动有限公司和中国医学科学院的研究团队介绍了AttriPrompter方法。该方法是一个用于零样本核检测的自动提示管道,通过视觉–语言预训练模型实现属性生成、属性增强和相关性排序,以及自训练知识蒸馏框架,解决高核密度问题。
http://arxiv.org/abs/2410.16820v1
https://github.com/AttriPrompter

北京邮电大学和清华大学的研究团队提出了一种名为AlignVSR的视觉语音识别方法。该方法利用音频–视觉跨模态对齐,采用全局和局部对齐的双层机制来增强从视觉到文本的推理能力。
http://arxiv.org/abs/2410.16438v1
https://github.com/liu12366262626/AlignVSR