
DETR—>DETR3D—>Sparse4D: 长时序稀疏3D目标检测进化之路
一、DETR


DETR是第一篇将Transformer应用到目标检测方向的算法。DETR是一个经典的Encoder-Decoder结构的算法,它的骨干网络是一个卷积网络,Encoder和Decoder则是两个基于Transformer的结构。DETR的输出层则是一个MLP。它使用了一个基于二部图匹配(bipartite matching)的损失函数,这个二部图是基于ground truth和预测的bounding box进行匹配的。最终性能与Faster-RCNN持平。
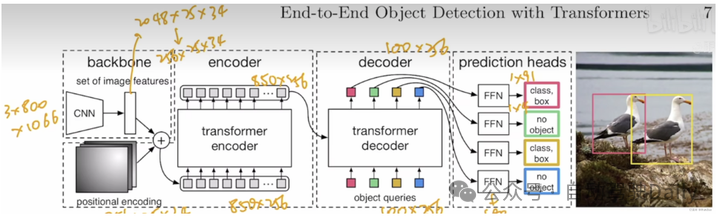
Backbone:
当我们利用卷积神经网络时,会有两个假设:
平移不变性:kernel 的参数在图像任何地方时一致的。局部性:要找某一个特征只需要在一个区域的周围检索,不需要全局观察。
而detr则是从0开始学起的,所以它的backbone采用经典的ResNet101网络对图像提取特征,为下面的Encoder获取先验知识。
流程如下:
(1)假设我的图像输入为:3 * 800 * 1066 (CHW)。
(2)通过CNN提取特征后,得到了 2058 * 25 * 34的feature map。
(3)为了减少计算量,下采样feature得到 256 * 25 * 34。
Encoder:
在这里需要把 数据转化为序列化数据,直接把hw合并,维度转化为 256 * 850.
在这里作者采用二维sin、cos的位置编码(通过实验各位置编码方法结果相差不大),具体公式本文不在展示。
Detr与Transformer相比,后者是直接在Encoder之前做 position encoder,然后在生成 qkv,然而Detr则是只对 key 与 query 编码。我认为key query 是负责取检索特征计算注意力分数,而value只负责提供对应位置的值,从而不需要位置编码。
把位置编码与feature结合的方式主要是add操作,所以我们要把位置编码的维度与feature的维度一致。其中我们的编码方式是根据feature的x、y两个方向的编码。
操作如下:
由于相应的feature map 的 H * W 为 25 * 34
(1)在H方向上为每个对应点赋予 128 * 25 * 34
(2)在W方向上为每个对应点赋予128 * 25 * 34
(3)add 成 256 * 25 * 34
(4)与feature map add
(5)把数据转化为序列化数据
(6)用 没有position的feature生成 V,有的生成KQ,执行attention
(7)通过Encoder后,feature map 与input一致,还是 256 * 850
Decoder:
decoder的输入主要有两个:
(1)Encoder的输出
(2)object queries
首先我们说一下object queries,在代码中,它的本质实际就是一个 learnable Embedding position。这里假设 初始化100(远远大于 num_classes)个object queries,每个的维度为256(方便与encoder输出矩阵乘法),所以它的维度为 256 * 100.
这里说个番外~,为什么object queries是一个 learnable position Embedding 呢?,我们知道,初始化要先通过一个Embedding层后才能输入后面的注意力层,而这个embedding层我们可以把它理解为全连接层,权重矩阵为w,这里的w是就是代码中用来学习object query的“learnable position embedding”,代码如下:
self.query_embed = nn.Embedding(num_queries, hidden_dim)
模型通过学习会把它图像分成100个区域,每个queries负责关注特定的区域。到这里你会发现:Object queries充当的其实是位置编码的作用。

这里要着重说明一下,DETR的核心是Decoder,Decoder的核心是这100个输入的可学习向量,Decoer训练的过程可以理解成就是训练这100个query向量的过程。
非常有意思的一点在于,在作者的源码中,这100个可学习query向量都被初始化为0,然后加上位置编码作为输入,在此基础上对这100个向量进行学习。
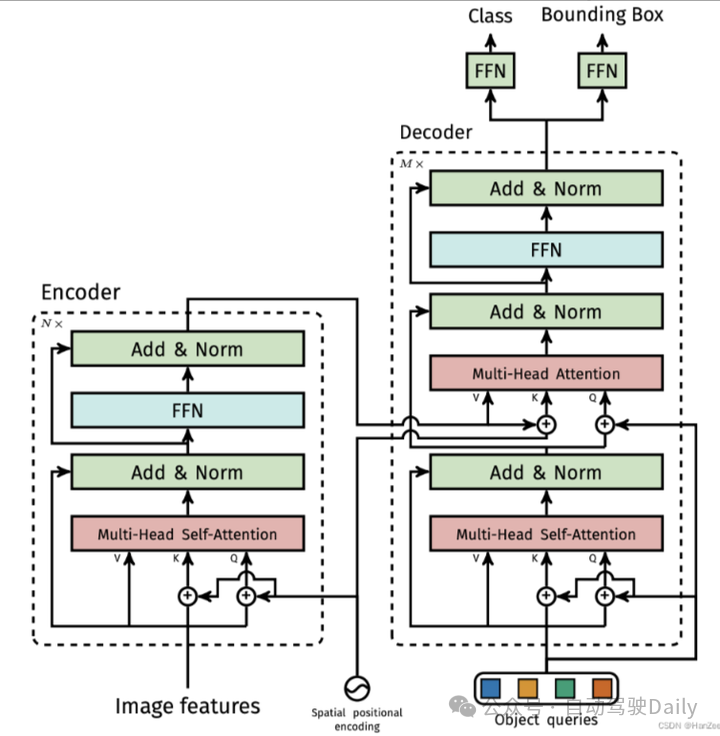
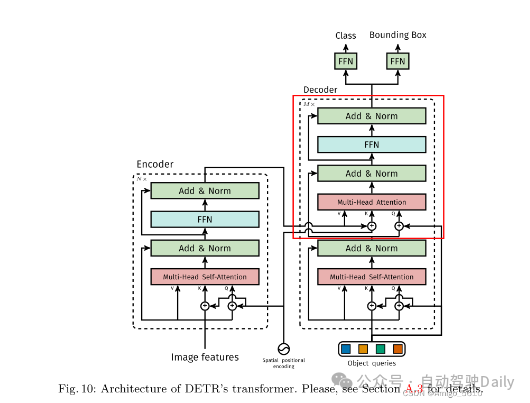
另一个值得注意的点是,论文中提到的Decoder部分是M层的,但事实上,这M层的decoder只有一部分被重复了M次(图5红框部分);
出框最后的一步也是最常规的一步,通过添加FFN检测头来进行预测,这里是做两个预测,一个是物体出框预测(四个值,中心点坐标x, y, 以及框的width, height),一个是物体类别预测。
在得到预测后,这100个预测框会和Ground Truth框一起通过匈牙利算法进行匹配(Bipartite 匹配)。
给定一个二分图G,在G的一个子图M中,M的边集{E}中的任意两条边都不依附于同一个顶点,则称M是一个匹配。求二分图最大匹配可以用匈牙利算法。
可参考:二分图最大匹配问题与匈牙利算法的核心思想 | 始终 (liam.page)
与VIT的区别:
总体上我认为,DETR和ViT非常类似,都是针对于图像的任务,一个是图像分类,一个是目标检测,二者区别主要在于将图像序列化的方式不同(当然,毕竟这二者是不同任务,后处理部分也肯定是不一样的,但是可以看到的是,后处理部分使用的都是很常规的分类或检测手段,因此这里不纳入本文的考虑)。
基本思想:
(1)将图片切分为一个个的16×16的patch;
(2)这个部分是用来获取每一个patch的Embedding,这里包含两个小步骤:
i. 将16×16的patch展平;
ii. 将得到的256长度的向量,映射为Transformer所需要的长度;
NB:很明显,这里可以通过线性层进行映射,也可以通过设置卷积核的方式直接得出Embedding
(3) 位置编码与第二部中获得的Embedding相加;
(4) 也就是直接向TRM encoder的输入与输出,将得到的多个维数为768的向量的第一个作为分类输入,使用常规的多分类方法进行分类。
二、DETR3D
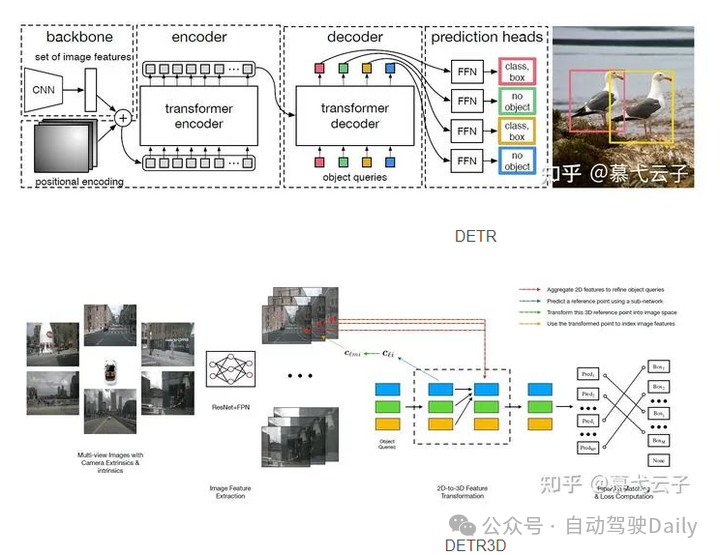
这是一篇多视角(多目)3D目标检测的工作,非LiDAR,也非单目,而且纯粹地基于nuScenes数据集。本质上,这就是一篇将DETR拓展到3D检测中的工作,所以重点在于,如何将DETR中bipartite loss的思想应用在3D任务上。
DETR的大致过程是提取图像特征→编码辅助输入→结合queries获得values→得到queries的检测结果,并做损失。DETR3D在此基础上,除了将bipartite loss拓展到了三维空间中,还另外引入了Deformable DETR的iterative bounding box refinement模块,即构建多层layer对query进行解码
set-to-set loss:
先来看最简单的部分,作者是如何把bipartite loss拓展到3D空间的。在文中,这个loss被称作是set-to-set loss,对于loss的研究,其实我们只要搞清楚预测与GT就可以了。
这里的pred是prediction set,GT则称作GT set 。
了使中间层也获得较好的学习效果,作者这里使用了一个常用的coarse2fine的手段,即在training阶段每层的loss都会被计算,但是在inference时只取最后一层作为输出。
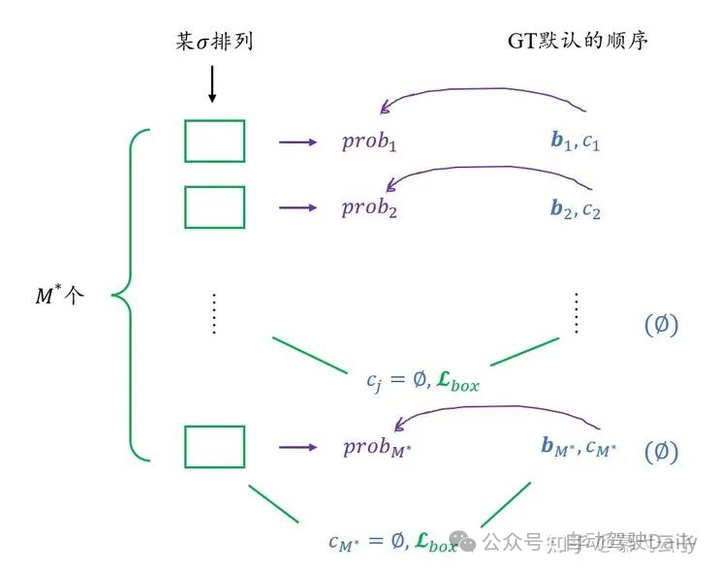
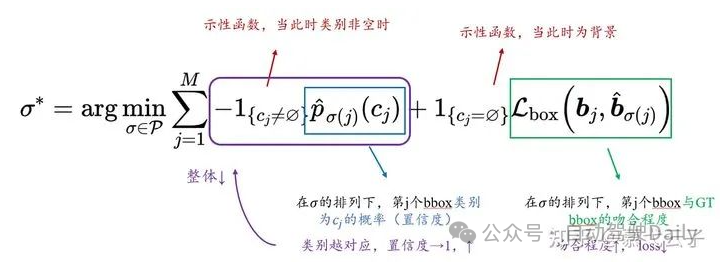
总而言之,这里的argmin鼓励我们找到一种预测的排列,使得anchor的顺序尽可能与GT匹配,当GT类别非空时寻找预测类标置信度最大者,当GT类别为空时寻找bbox最接近的。
这里又有问题了:
-
GT类别非空时,单纯看寻找预测概率最大似乎是不合理的吧。比如预测有两个同类bbox,如何确定谁排在前面、后面?这样就会出现bbox错位匹配的情况吧。我们看DETR里是怎么写的: ,DETR这里的matching loss,两个示性函数都是非空的啊喂,必须要在非空的时候加以bbox的约束才能避免出现错位的情况(即又要匹配的类别对,又要匹配的类别好),并且空集的时候在这里其实是不关注的。 -
也正是因为他把后面那个项的示性函数改成等于了,这就引申出一个问题,在padding空集的时候,你这里也需要padding bounding box了,而这怎么padding呢?在DETR当中是不必为补充的空集也补充一个bounding box,因为你无论怎么补充,你都无法指望预测的空bounding box匹配上你的补充,所以这一点也是比较令人迷惑的。
如果以上你听得一知半解,我们再来看找到排列之后的损失计算,就更能理解这种诡谲了:这里也基本是和DETR类似的,不考虑符号上使用上的区别,就只有示性函数中把不等号变成了等号这样严肃的区别,于是这就造成了:当类别非空时,你不做bounding box上的loss,而现在类别空了你反而来做bounding box的loss。所以我强烈怀疑应该是论文中两处都打错了,否则结果应该不会还能排到SOTA。不知道是不是因为arxiv版本挂错了,还是真的审稿人粗心不看公式。
argue: 如果以上推断成立,那么就算我们脑补修改一下这个loss,其实也有值得商榷的地方:我本来期待着他的loss至少是什么IoU loss之类的,结果就是简简单单的L1。在KITTI-object那边的工作中,其实涌现了很多类似mIoU loss等创新性的工作。这样不考虑parameters在3D空间中的实际的bounding box意义,而直接做L1 loss,这样的学习效果是否会好、是否合理?
2d-to-3d feature转换
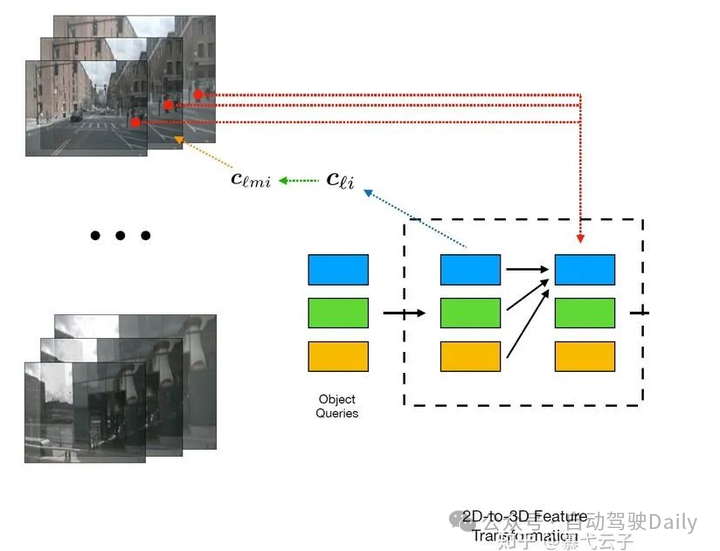
重点便在于如何解读这里的几条虚线了。起初,我是按照图例中给出的红色在最上、黄色在最下的顺序来解读的,以为是要先对特征进行操作,然后对query再加工提取,在feature space中去做loss……我还纳闷呢,明明人家说是在3D空间中做loss,这咋回事呢,而且transformer的黑色框框里,向右的黑色箭头也对不上啊……
纠结了好久才明白正确的理解方式是从蓝色开始看到红色,实际上所有虚线加起来的操作就是向右黑线……由于文中图例文字太小,这里按照虚线的顺序依次解读下以上的操作:
-
首先明确,object queries是类似DETR那样,即先随机生成 个bounding box,类似先生成一堆anchor box,只不过这里的box是会被最后的loss梯度回传的。 -
(蓝线)然后通过一个子网络,来对query预测一个三维空间中的参考点 (实际上就是3D bbox的中心)。通过角标我们可以看出,这个操作是layer-wise、query-wise的。这两个wise的概念参见下文的讨论。 -
(绿线)利用相机参数,将这个3D参考点反投影回图像中,找到其在原始图像中对应的位置。 -
(黄线)从图像中的位置出发,找到其在每个layer中对应的特征映射中的部分。 -
(红线)利用多头注意力机制,将找出的特征映射部分对queries进行refine。这种refine过程是逐层进行的,理论上,更靠后的layer应该会吸纳更多的特征信息。 -
(黑色虚线框之后)得到新的queries之后,再通过两个子网络分别预测bounding box和类别,然后就进入我们之前讨论的loss部分了。
这里一定要注意,从蓝线开始,就像deformable DETR一样,queries是划分为了多个layer输入的(去查了一下代码,这里应该是6个layer),这个layer和FPN得到的feature layer是不同的(所以为免歧义,我在前后文都称之为feature level了),feature的level是四层,所以总结一下是:每一个level的feature都应该对应输入每个layer的queries,所以实际上应该会有4*6=24个输入(当然实际运算要更复杂一些)。
总结
最后来总结,回答一下一开始提出的几个疑惑。
-
关于bipartite loss和使用特征的方式,在此就不再赘述了,诸多细节与疑惑均已在讨论中提出。 -
multi-view体现在query对同一时刻的六张图像同时进行了学习,单就这一点而言其思路就是比较超前的。传统的Monocular方法都是单张图像输入输出、multiview方法大家考虑的也是时间序列上的长序列,而并没有拓展到多视角上。 -
关于注意力机制的问题,我们可以回忆一下,DETR令人震撼的地方其实是在于decoder attention可以关注到bounding box中的特征:
DETR decoder attention
而在这里,文中其实是没有给出什么可视化的效果,或者类似“all box predictions”这种grid可视化图。强行分析的话,我认为亮点反而可能在于,这种多目图像之间特征的求和(简单的1x1conv)并对query的refine,其实是替代了传统的多目匹配工作,使得这种3D-to-2D Queries可以有效跨越多目图像,更应该是本文的落脚点和关注之处。
总的来讲,还有很多疑惑,也还有很多可发展的地方。
三、Sparse4d
在自动驾驶视觉感知系统中,为了获得环绕车辆范围的感知结果,通常需要融合多摄像头的感知结果。比较早期的感知架构中,通常采用后融合的范式,即先获得每个摄像头的感知结果,再进行结果层面的融合。后融合范式主要的问题在于难以处理跨摄像头的目标(如大卡车),同时后处理的负担也比较大。而目前更加主流的感知架构则是选择在特征层面进行多摄像头融合。其中比较有代表性的路线就是这两年很火的BEV方法,继Tesla Open AI Day公布其BEV感知算法之后,相关研究层出不穷,感知效果取得了显著提升,BEV也几乎成为了多传感器特征融合的代名词。但是,随着大家对BEV研究和部署的深入,BEV范式也逐渐暴露出来了一些缺陷:
i.感知范围、感知精度、计算效率难平衡:从图像空间到BEV空间的转换,是稠密特征到稠密特征的重新排列组合,计算量比较大,与图像尺寸以及BEV特征图尺寸成正相关。在大家常用的nuScenes 数据中,感知范围通常是长宽 [-50m, +50m] 的方形区域,然而在实际场景中,我们通常需要达到单向100m,甚至200m的感知距离。若要保持BEV Grid 的分辨率不变,则需要大大增加BEV 特征图的尺寸,从而使得端上计算负担和带宽负担都过重;若保持BEV特征图的尺寸不变,则需要使用更粗的BEV Grid,感知精度就会下降。因此,在车端有限的算力条件下,BEV 方案通常难以实现远距离感知和高分辨率特征的平衡;
ii.无法直接完成图像域的2D感知任务:BEV 空间可以看作是压缩了高度信息的3D空间,这使得BEV范式的方法难以直接完成2D相关的任务,如标志牌和红绿灯检测等,感知系统中仍然要保留图像域的感知模型;
实际上,我们感兴趣的目标(如动态目标和车道线)在空间中的分布通常很稀疏,BEV范式中有大量的计算都被浪费了。因此,基于BEV的稠密融合算法或许并不是最优的多摄融合感知框架。同时特征级的多摄融合也并不等价于BEV。这两年,PETR系列(PETR, PETR-v2,StreamPETR) 也取得了卓越的性能,并且其输出空间是稀疏的。在PETR系列方法中,对于每个instance feature,采用global cross attention来实现多视角的特征融合。由于融合模块计算复杂度仍与特征图尺寸相关,因此其仍然属于稠密算法的范畴,对高分辨率的图像特征输入不够友好。
因此,我们希望实现一个高性能高效率的长时序纯稀疏融合感知算法,一方面能加速2D->3D 的转换效率,另外一方面在图像空间直接捕获目标跨摄像头的关联关系更加容易,因为在2D->BEV的环节不可避免存在大量信息丢失。这条技术路线代表性的方法是基于deformable attention 的DETR3D算法。然而从开源数据集指标来看,DETR3D的性能距离其他稠密类型的算法存在较大差距。为了Make 纯稀疏感知 Great Again,我们近期提出了Sparse4D及其进化版本Sparse4D v2,从Query构建方式、特征采样方式、特征融合方式、时序融合方式等多个方面提升了模型的效果。当前,Sparse4D V2 在nuScenes detection 3d排行榜来看,达到了SOTA的效果,超越了包括SOLOFusion、BEVFormer v2和StreamPETR在内的一众最新方法,并且在推理效率上也具备显著优势。本文主要介绍了Sparse4D 和 Sparse4D V2 方案的细节实践。
源码:https://link.zhihu.com/?target=https%3A//github.com/linxuewu/Sparse4D
https://link.zhihu.com/?target=https%3A//github.com/HorizonRobotics/Sparse4D

由于上述的这些原因,DETR3D 网络整体的学习能力偏弱,指标在当前显著弱于BEV 范式的方法。在Sparse4D-V1 中,我们主要通过instance 构建方式,特征采样、特征融合和时序融合等方面改进了现有的框架。
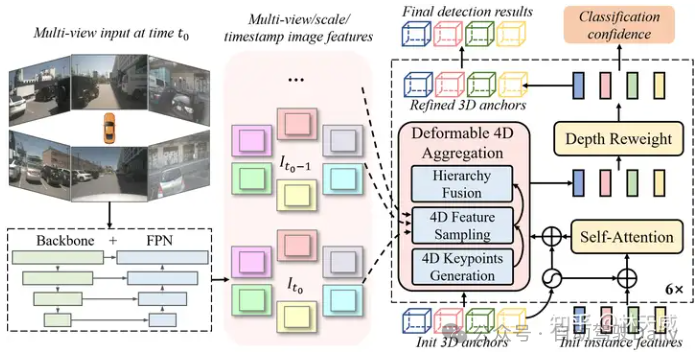
如图1所示,Sparse4D 也采用了Encoder-Decoder 结构。其中Encoder包括image backbone和neck,用于对多视角图像进行特征提取,得到多视角多尺度特征图。同时,我们会cache 多历史帧的图像特征,用于在decoder 中提取时序特征;Decoder为多层级联形式,输入时序多尺度图像特征图和初始化instance,输出精细化后的instance,每层decoder包含self-attention、deformable aggregation和refine module三个主要部分。
学习2D检测领域DETR改进的经验,我们也重新引入了Anchor的使用,并将待感知的目标定义为instance,每个instance主要由两个部分构成:

基于以上定义,我们可以初始化一系列instance,经过每一层decoder都会对instance 进行调整,包括instance feature的更新,和anchor的refine。基于每个instance 最终预测的bounding box,Sparse4D 中同样通过Bipartite 匹配的方式与真值进行匹配并计算损失函数。
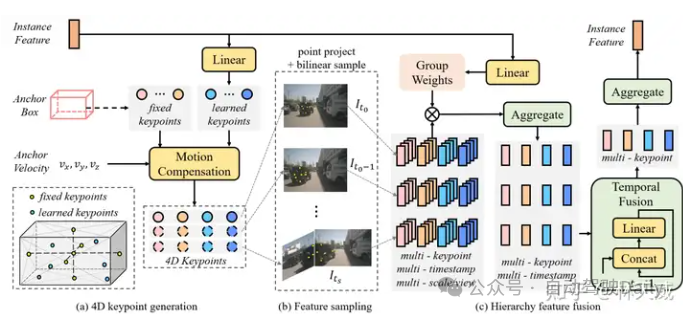
在Sparse4D 的decoder 中,最重要的是Deformable 4D Aggreagation 模块。这个模块主要负责instance 与时序图像特征之间的交互,如图3所示,主要包括三个步骤:
4D 关键点生成:首先,基于每个instance 的3D anchor信息, 我们可以生成一系列3D关键点,分为固定关键点和可学习关键点。我们将固定关键点设置为anchor box的各面中心点及其立体中心点,可学习关键点坐标通过instance feature接一层全连接网络得到。在Sparse4D 中,我们采用了7个固定关键点 + 6个可学习关键点的配置。然后,我们结合instance 自身的速度信息以及自车的速度信息,对这些3D关键点进行运动补偿,获得其在历史时刻中的位置。结合当前帧和历史帧的3D关键点,我们获得了每个instance 的4D 关键点。
4D 特征采样:在获得每个instance 在当前帧和历史帧的3D关键点后,我们根据相机的内外参将其投影到对应的多视角多尺度特征图上进行双线性插值采样。从而得到Multi-Keypoint,Multi-Timestamp, Multi-Scale, Multi-View 的特征表示;
层级化特征融合:在采样得到多层级的特征表示后,需要进行层级化的特征融合,我们分为了三层:
-
Fuse Multi-Scale/View:对于一个关键点在不同特征尺度和视角上的投影,我们采用了加权求和的方式,权重系数通过将instance feature和anchor embed输入至全连接网络中得到; -
Fuse Multi-Timestamp:对于时序特征,我们采用了简单的recurrent策略(concat + linear)来融合; -
Fuse Multi-Keypoint:最后,我们采用求和的方式融合同一个instance 不同keypoint 的特征
运动补偿:Sparse4D针对自车运动和instance运动都进行了补偿。目前,大多数算法仅显式考虑了自车运动。我们通过实验分析了运动补偿的作用,如下表所示。对于NDS指标来说,自车运动和他车运动分别带来了6.4%和0.7%的提升,他车运动补偿对检测精度无提升,但是对速度估计精度的提升非常显著(mAVE指标)
多层次特征融合:在deformable aggregation中,我们需要对多尺度、多视角和多关键点的特征进行融合。为了分析各个层级融合的重要程度,我们分别将各层的加权方式改为直接求和,可以看到多尺度的影响小于多视角,而多关键点的融合最为重要。此外,将三个层级的融合全部改为求和的形式,模型将难以收敛,指标也会显著降低
采样时序融合帧数:Spase4D v1中,采用多帧采样的方式实现时序融合,其中采样帧数对感知性能的影响显著。我们将帧数从0逐步增加至10,感知性能一直在稳步提升,说明长时序融合对检测性能有很大帮助。但是由于显存限制,我们仅验证到了10帧。
v2 v3可以参考
reference: Sparse4D系列算法:迈向长时序稀疏化3D目标检测的新实践