
收录于话题
RAG效果在很大程度上依赖于检索到的文档的相关性和准确性。传统的基于规则或语义相似性的文本分块方法在捕捉句子间微妙的逻辑关系上存在不足。
RAG流水线的概览,以及基于规则、相似性和PPL分割的示例。相同的背景色表示位于同一个块中。
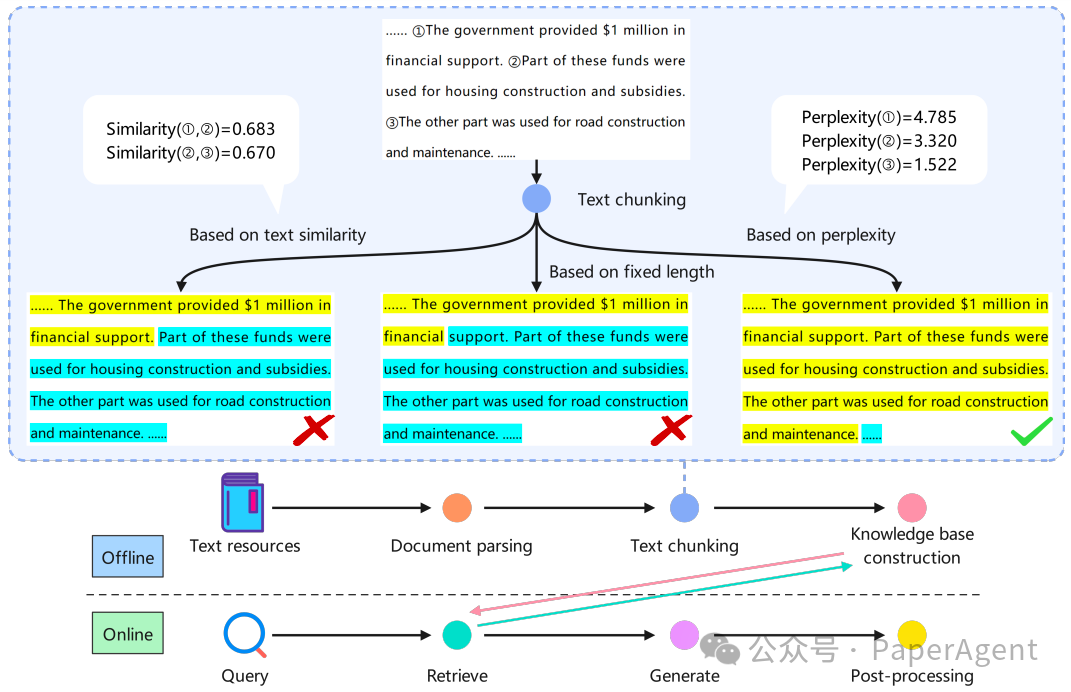

为了解决现有方法的局限性,提出了一种名为Meta-Chunking的概念,它在句子和段落之间定义了一种粒度:由段落内具有深层语言逻辑联系的句子集合组成,旨在增强文本分割过程中的逻辑连贯性。Meta-Chunking包括基于LLMs的两种策略:边际采样分块(Margin Sampling Chunking)和困惑度分块(Perplexity Chunking)。
整个元块分割(Meta-Chunking)过程的概览。每个圆圈代表一个完整的句子,句子的长度并不一致。垂直线表示在哪里进行分割。图底部的两侧揭示了边缘采样分割(Margin Sampling Chunking)和困惑度分割(Perplexity Chunking)。具有相同背景色的圆圈代表一个元块,它们被动态组合以使最终的块长度满足用户需求。

Meta-Chunking的工作流程:

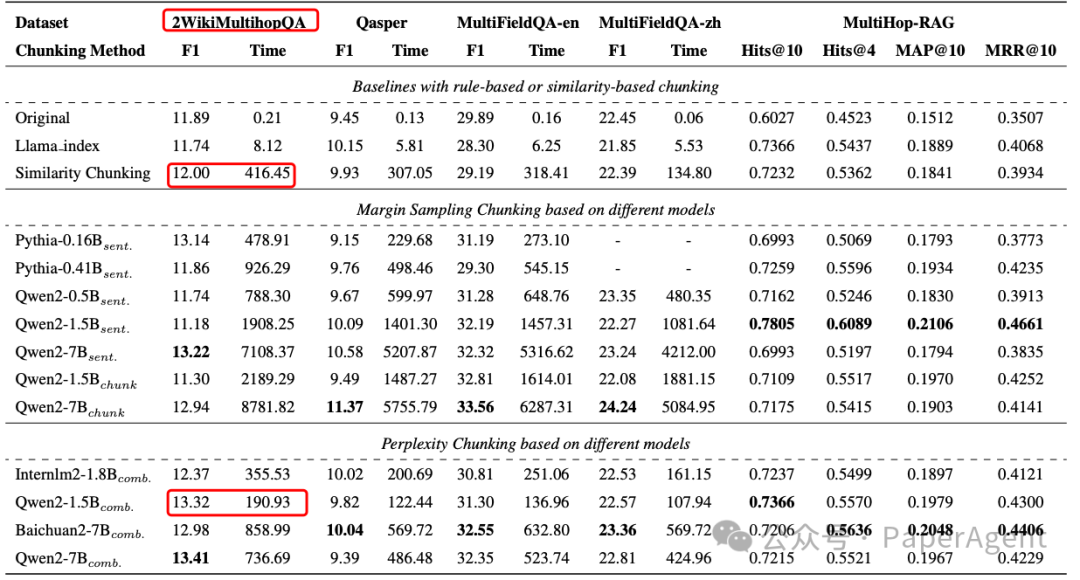

META-CHUNKING: LEARNING EFFICIENT TEXT SEGMENTATION VIA LOGICAL PERCEPTIONhttps://arxiv.org/pdf/2410.12788https://github.com/IAAR-Shanghai/Meta-Chunking.
?推荐阅读
欢迎关注我的公众号“PaperAgent”,每天一篇大模型(LLM)文章来锻炼我们的思维,简单的例子,不简单的方法,提升自己。