
“Data Analysis in the Era of Generative AI”
数据分析在企业决策辅助、营销策略优化等方面有着至关重要的作用,但当前数据分析成本高,只有少数专家能进行深入分析。近年大模型和AIGC的快速发展极大的改变了人们的生活和工作方式,同时也简化了数据分析的流程,降低了数据分析的门槛。
那么AIGC时代的数据分析应该是什么样的呢?本文探讨生成式AI工具在数据分析中的潜力,列出AI系统可协助的任务及相关研究。讨论人机交互设计考虑,优化用户体验、工作流程及增强信任度,适用于其他领域的AI系统设计。


论文地址:https://arxiv.org/pdf/2409.18475v1
摘要
本文探讨AI工具在数据分析中的潜力,特别是设计考虑和挑战。大语言和多模态模型为数据分析工作流各阶段提供新机会,能将用户意图转化为可执行代码、图表和洞察。本文强调以人为本的设计原则,促进直观交互、建立用户信任、简化AI辅助分析工作流。讨论AI系统开发中的研究挑战,包括提升模型能力、评估与基准测试、理解最终用户需求。
简介
数据驱动决策在各行业和个人生活中至关重要,但当前数据分析成本高,只有少数专家能进行深入分析。民主化数据分析将使更多人能够独立分析数据,做出更明智的决策。数据分析是复杂的迭代过程,涉及任务制定、数据收集、探索性分析和可视化等多个步骤。分析师需要具备概念知识、工具使用和编程技能,且在不同工具间切换时面临较大开销。现有的交互式和自动化工具(如Tableau、Power BI、Alteryx等)在灵活性和易用性之间存在权衡。
生成式AI革命。大型语言和多模态模型(如ChatGPT、GPT-4等)能将高层用户需求转化为可执行步骤,降低用户学习新工具的门槛,提升数据分析的可达性和效率。
数据分析的特殊性。数据分析涉及多步骤的规划与探索,需处理多种模态(自然语言、结构化数据、代码、图像等),现有AI工具面临复杂性挑战,需整合多种工具以避免用户体验分散。数据分析过程通常是迭代的,用户需根据初步结果调整目标,现有AI工具的自然语言接口和静态模态可能不适合此需求,需创新人机协作界面。数据分析错误可能导致严重后果,强调AI系统的准确性和可靠性,需建立用户验证和调试输出的基础设施。
目标。探讨如何释放生成式AI在数据分析领域的潜力,提供AI和HCI从业者的设计空间视角,聚焦于需要进一步关注的领域。
GenAI在数据分析中的机会:
- 支持数据分析各阶段,包括数据查找、统计严谨性、假设探索与报告生成。
- LLMs在数据清理、转换和可视化中的应用已被广泛认可。
以人为本的设计考虑:
- AI工具的用户界面设计影响用户体验。
- 直观的意图指定方式(如颜色选择器)优于自然语言描述。
- 需提供额外界面以帮助用户理解和验证系统输出,减少意图指定的努力。
未来研究挑战:
- 提升现有模型能力,解决训练和评估数据稀缺问题。
- 确保系统可靠性与稳定性,进行用户研究以符合用户认知和实际需求。
背景
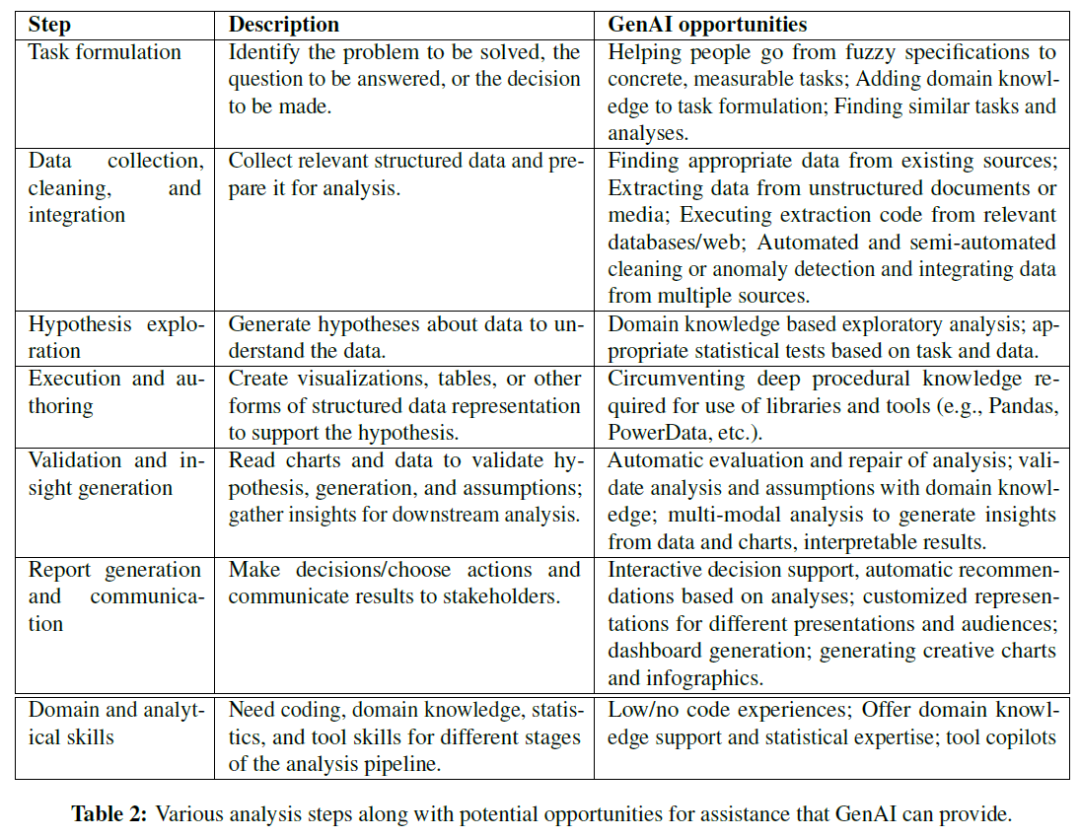
数据分析过程包括多个步骤,通常是迭代进行。首先是任务制定,明确问题并细化子任务(如全球趋势、国家排名等)。数据收集阶段涉及查询数据库、数据清洗和多源整合。探索阶段分析数据,生成描述性统计和可视化,形成假设。生成的可视化和数据需验证其可靠性,可能涉及统计分析和领域知识。最后,分析结果通过报告、仪表板或演示与利益相关者沟通,并根据反馈进行迭代。数据分析需要多种技能,包括领域知识、统计、编程和工具使用。该过程复杂且碎片化,需灵活运用不同工具和方法。文章未涵盖模型构建、自动化机器学习等主题,专注于探索性和迭代性。
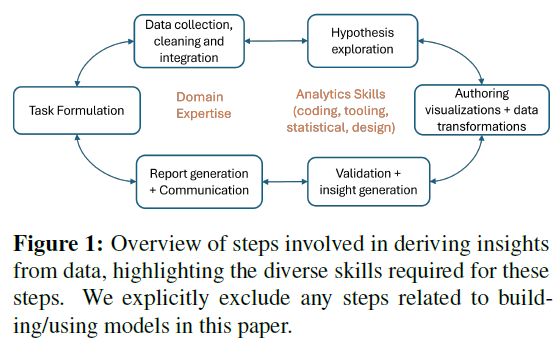
案例研究:用于可视化创作的AI工具的用户体验
数据可视化在数据分析的各个阶段中广泛应用,帮助分析师评估数据质量、探索数据关系、理解趋势和统计特征,并与受众沟通见解。尽管现代可视化工具降低了用户的专业要求,数据转换和图表设计仍然具有挑战性。LLM的出现促使AI驱动的可视化工具发展,降低了可视化创作的门槛。
本文通过示例任务比较用户体验:
- 传统编程工具
- 通过聊天界面与LLM直接交互
- LLM驱动的交互式数据分析工具
比较重点包括:初始意图的指定、AI输出的消费、编辑、迭代、验证AI输出及在更大数据分析上下文中的工作流程。
示例任务和传统经验
用户希望分析2000至2020年间五个CO?排放最高国家的可再生能源电力比例趋势。
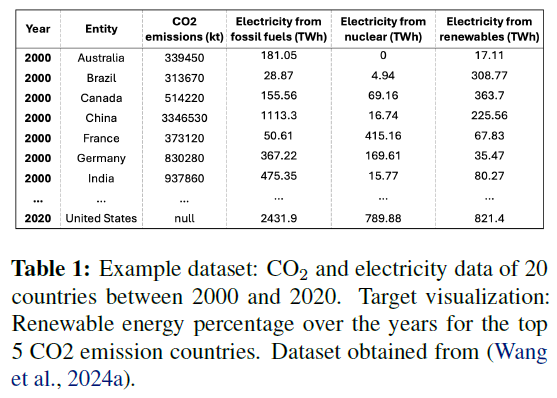
传统数据分析方法包括两个步骤:
- 数据转换:创建新列(如“可再生电力比例”),进行分组、求和和过滤,可能需要复杂的数据变换。
- 图表制作:选择合适的图表类型和编码来表示数据趋势。
数据转换可通过Excel公式或Python库(如Pandas)完成,图表可用Seaborn、Matplotlib或PowerBI、Tableau等工具制作。
传统方法提供用户完全控制,但对初学者和非编程用户学习曲线陡峭。
会话式LLM接口(带有GPT-4o和CodeInterpreter的ChatGPT)
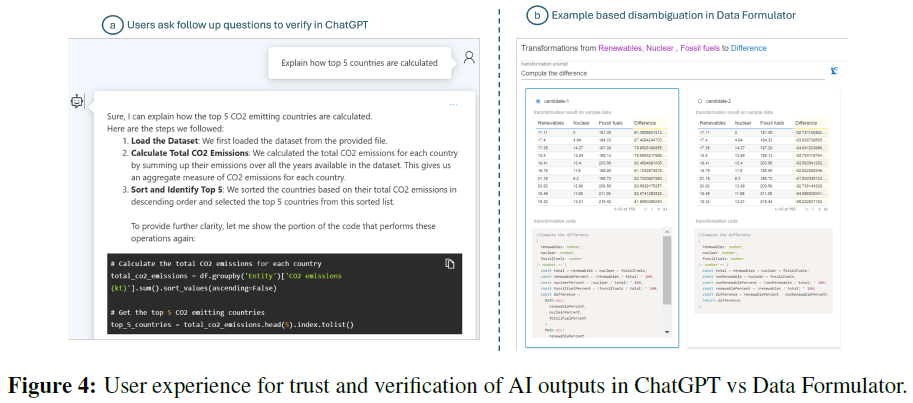
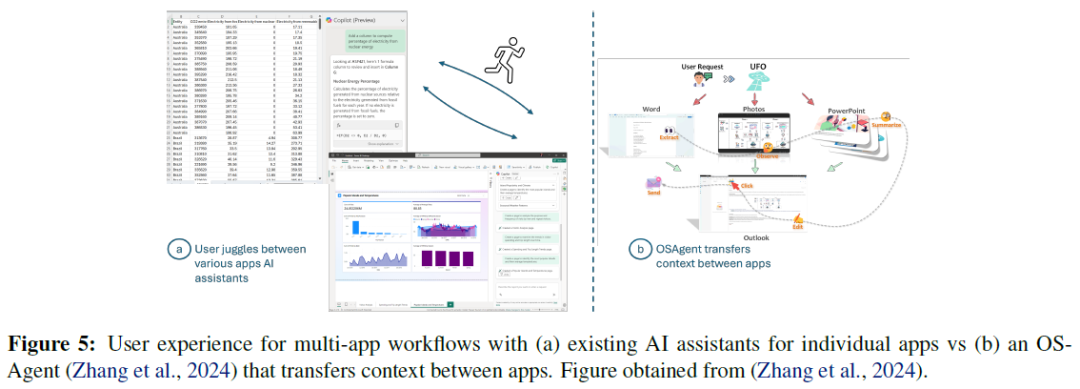
LLMs(如ChatGPT)简化了数据处理,用户通过自然语言命令加载数据并生成可视化,但多次模型调用导致等待时间长和失败风险增加。用户可以通过对话界面迭代可视化,但缺乏跟踪不同迭代的方式,可能导致上下文丢失和重新计算的需要。现有系统主要通过自然语言传达意图,限制了表达能力,某些操作(如颜色选择)更适合直接选择。用户可请求模型计算的解释,系统提供代码片段以增强用户信任。现有的AI助手(如Office Copilot)在不同工具间切换时效率低下,用户需手动传递上下文。
LLM支持的交互式数据分析工具
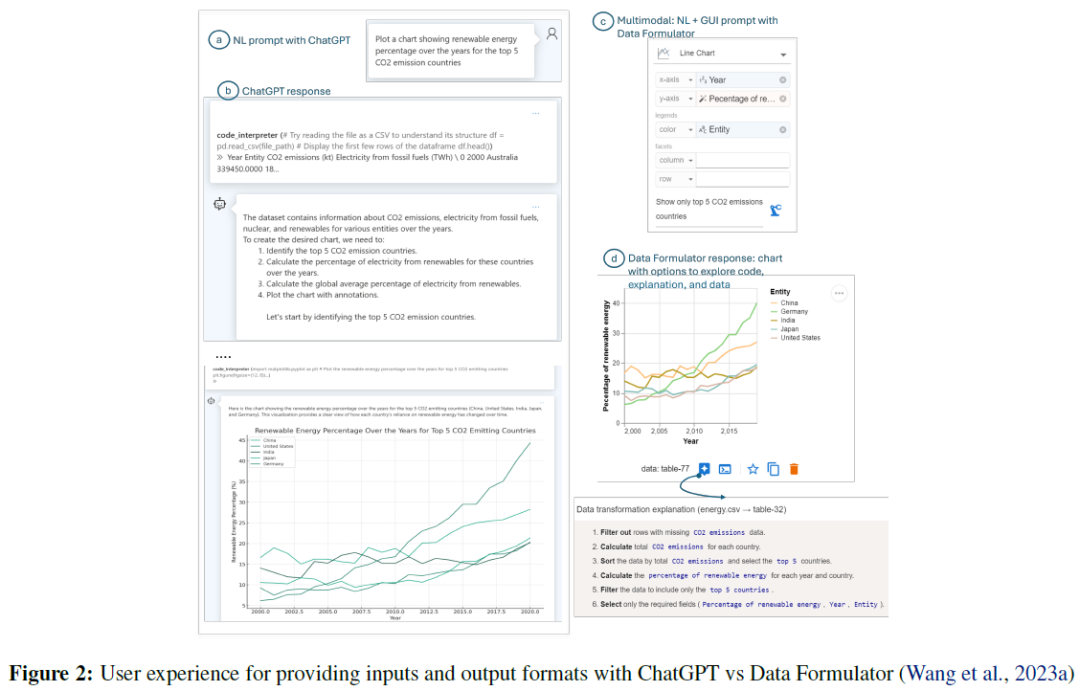
Data Formulator。采用多模态UI,用户通过字段编码和自然语言指定意图,LLM生成数据转换,创建新表并生成Vega-Lite图表,提升可控性和可靠性。

DynaVis。提供多模态UI,用户用自然语言指定图表编辑意图,动态生成小部件(如颜色选择器),仅在初始生成时调用LLM,允许用户即时反馈和多样化尝试。
Data Formulator2。扩展了Data Formulator,支持迭代探索,用户可修改现有可视化,系统重用代码和数据,组织用户交互历史为数据线程,便于管理分析会话。
信任机制。Data Formulator根据用户意图生成多个图表/转换候选,用户可检查代码和示例,帮助澄清和细化规格。
工作流整合。Data Formulator将数据转换和可视化创作整合为单一工具,简化工作流程。
UFO系统。结合GPTVision,观察和分析GUI,简化Windows OS应用间的操作,提升复杂任务的执行效率。
备注
AI可视化工具的设计显著影响用户创建所需可视化的能力。设计原则对可视化工具及其他数据分析阶段的AI工具至关重要。
AI系统在数据分析领域的机遇
AI系统可帮助用户应对数据分析工作流程中的复杂性,提升效率。分析过程的每个阶段面临独特挑战,包括复杂推理、迭代过程及多技能需求。目标是明确AI驱动工作流程的具体问题定义,识别可显著影响的子任务。将复杂问题拆解为子任务有助于用户评估AI系统的中间输出并进行必要的干预。
缩小技能差距:增强用户数据分析能力
数据分析需要多种技能,LLMs(大语言模型)可以帮助非专家用户克服技能障碍,提升数据分析能力。LLMs支持低代码/无代码体验,能根据用户的自然语言描述自动生成数据分析所需的代码,简化可视化等步骤。工具如LIDA、ChatGPT的代码解释器、Chat2Vis和ChartGPT等,能够根据自然语言生成数据清理、转换和可视化的代码。现有系统在数据处理和统计分析方面的应用仍有限,需提高可靠性并建立评估标准。LLMs可提供统计测试选择、避免常见误区的指导,提升用户的统计分析能力。
LLMs具备丰富的领域知识,能自动理解数据和任务,帮助用户解析数据集、生成特征和解释分析结果。AI助手(如BingChat、Office365 copilot等)降低了数据分析的入门门槛,提供自然语言界面和智能指导。当前工具的AI助手多为应用特定,需设计API和领域语言,LLM的指令理解能力至关重要。自动理解和利用现有工具的AI系统有助于扩展AI助手的应用范围。LLMs在编码、统计分析、领域知识和工具使用方面的能力,提升了用户的数据分析能力并降低了技能门槛。
数据分析过程不同阶段的潜在AI工作流
LIDA的目标探索模块通过生成基于数据的高层目标,帮助用户克服冷启动问题。生成的假设以三元组形式呈现:目标、可视化方式和信息价值的理由。LLMs可将模糊用户需求转化为具体可行的分析任务。InsightPilot利用LLM将模糊规格转化为具体分析行动。NL4DV工具包从自然语言查询中生成数据可视化的分析规格。
AI系统可通过借鉴现有数据分析示例,帮助用户制定和优化分析任务,类似于检索增强生成(RAG)和少量学习方法。AI可支持多元分析,降低数据分析偏见风险,提升透明度,早期系统Boba简化了这一过程。自动化假设探索面临假设空间指数膨胀的挑战,需结合领域知识与迭代探索。在明确目标后,AI可生成数据转换和可视化所需代码,相关研究已被广泛探讨。数据分析结果需经过仔细检查,以验证分析和提取洞察,视觉语言模型如GPT-V和Phi-3-Vision在此方面展现潜力。
LIDA利用LLM评估可视化生成代码,依据预设标准;ChartQA和PlotQA数据集测试LMM在图表问答中的表现。多种模型和方法用于利用LLM和LMM理解图表并提取见解,LLM在整合分析步骤以构建叙述中发挥重要作用。视觉模型的图表理解能力可用于自动迭代和优化假设,例如回归分析中拟合不同曲线。用户在验证AI输出中仍然扮演重要角色,提供高层次解释、代码和中间数据有助于解决AI误解和错误。数据发现是数据分析工作流中的关键问题,LLM通过自然语言查询提升数据湖中的数据检索能力。AI系统可与Web API交互,动态提取数据并组织成结构化表格,增强数据提取和知识综合能力。AI还可帮助数据清洗和整合来自不同来源的数据集,处理格式问题和不一致性。
LLMs可从非表格数据(如客户评论、会议记录、视频转录)中提取结构化数据,分析情感和趋势,提升数据分析效率。HeyMarvin平台通过半自动化转录和主题编码,深入挖掘用户需求,展示了将非结构化数据转为结构化数据的应用。AI系统可简化报告和仪表板的生成,减少开发需求,提升数据可视化的互动性和美观性。LLMs能根据不同受众和设备动态调整报告内容和格式,增强沟通效果。AI可生成互动和个性化的沟通工具,结合多种媒体形式和交互技术,提升用户体验。
基于人工智能的数据分析系统的人类驱动设计考虑
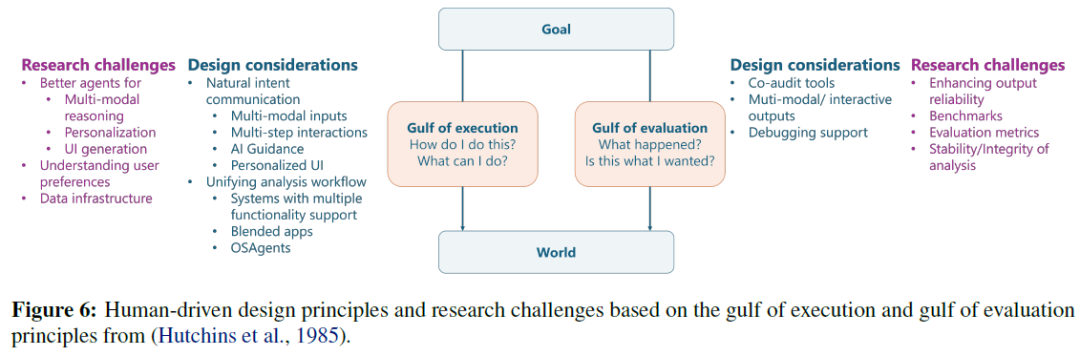
AI系统在数据分析流程中的用户体验受设计考虑影响,存在执行和评估的挑战。GenAI改变了执行(如指定意图而非编写代码)和评估(理解AI生成代码和图表)。仍需关注执行和评估的差距,设计应以用户为中心,减少这些差距。
增强用户-AI交互:实现自然意图交流
依赖自然语言接口的AI数据分析系统对用户提出挑战,复杂意图表达困难。多模态输入(如鼠标、触控、音频、手势)可增强用户意图表达的清晰度。Data Formulator结合图形小部件和自然语言,简化用户意图指定。DirectGPT允许用户通过点击和高亮直接操作画布,提升交互体验。ONYX结合自然语言编程与演示,学习新语言表达。输入-输出示例(如编程示例)可用于数据转换,LLM能处理噪声。音频输入结合演示可增强用户交互。多步骤交互是人机交互的关键,用户需在分析过程中进行迭代。
线性交互形式包括基于聊天的交互和计算笔记本风格,能够聚合上下文和检查中间输出。非线性交互形式需要生成多个输出供用户选择或组合,支持回溯和分叉。数据线程(Data Formulator2)帮助用户管理分析会话,便于定位、精炼和探索替代方案。AI Threads 提升聊天机器人的上下文聚焦和对话连贯性。Sensescape 提供多层次抽象,支持在觅食和理解模式间无缝切换。Graphologue 将文本响应转化为图形图表,促进后续信息查询和问答任务。跟踪AI代理状态和用户规范对构建适当上下文至关重要,提示摘要技术可确保每个节点无状态且捕捉完整上下文。需要合适的用户界面以支持用户与AI代理的非线性交互。
用户与AI的交互设计包括三种方式:空白起始、AI推荐和混合主动性。空白起始提供最大灵活性,AI推荐则在用户不确定时提供指导。Lida示例通过加载数据集时展示潜在目标和相关可视化建议。AI助手可预填文档,用户可在此基础上编辑和完善。GenAI模型能分析数据集和用户行为,预测和推荐下一步或整个工作流程。用户交互从构建组件转向优化AI生成的建议,需支持探查机制。AI系统应提供用户提问、修改和解释其决策的接口。
DynaVis系统利用LLM动态生成UI小部件,用户可通过自然语言描述编辑任务(如“将图例位置改为左侧”)进行交互式修改。Stylette系统允许用户用自然语言指定设计目标,LLM推断相关CSS属性。PromptInfuser探索了使用提示创建功能性LLM基础UI原型。LLM还可用于生成UI设计反馈。扩展这些技术以生成个性化数据分析工具的用户界面,有望提升用户体验。
便于信任和验证:增强用户模型输出的可靠性
GenAI模型可能产生意外输出,用户需验证准确性,但验证过程不应增加过多认知负担。验证数据转换可能需代码审查,设计者应简化用户验证方式。Tankelevitch等(2024)建议在GenAI系统中整合元认知支持策略,以增强可解释性和可定制性。用户可通过图表、数据检查、代码理解和溯源分析等方式验证模型输出质量。Co-audit工具旨在帮助用户检查AI生成内容的质量。
代码解释与验证。采用自然语言或逐步可编辑的自然语言解释代码。生成多种图表以帮助用户理解差异。
检查工具。ColDeco提供电子表格界面,便于用户验证计算结果而无需查看代码。
数据来源分析。追踪输出数据的来源和变换过程。XNLI展示详细的可视化变换过程,支持用户调整错误。
多模态输出。结合文本和图像的多模态文档更易于理解,交互式图表和“假设分析”帮助用户快速验证结果。
调试支持。AI系统复杂,用户难以理解内部工作。设计实时可视化和支持中断的系统可提高用户信任。
AutoGen Studio。提供无代码界面,支持多代理协作的构建、调试和部署,展示代理间的消息和关键指标。
统一分析经验:简化数据工具和工作流程
当前数据分析工具多集中于自动化数据分析流程的某些步骤,用户需在多个工具间切换,增加了工作负担。未来AI模型和多代理AI系统有潜力改变整个数据分析流程,简化用户体验。统一多种功能于单一工具可减少上下文切换,提升调试和推理能力。例如,Data Formulator结合数据转换与可视化,LIDA整合数据总结、目标探索、图表创作和信息图生成。设计单一工具支持所有数据分析阶段可能不现实,需考虑混合应用和OSAgents等替代方案。
多智能体系统的开发使得将多种能力整合到单一工具中成为可能。这些系统由多个专门化的智能体组成,能够相互协作以完成复杂任务。在科学推理、软件工程和具身智能体等领域展现出潜力。软件工程领域的ChatDev系统模拟了多个AI“软件工程师”,如程序员、代码审查员、设计师和测试员,协作优化软件开发流程。这种架构结合高质量模型,有效识别和缓解软件缺陷,减少LLM的幻觉现象。
混合应用。现代应用如Microsoft Loop和Notion正创建一体化工作平台,允许多个工具和数据在单一界面中整合。针对数据分析领域,建议设计能够在分析流程中上下文化的AI工具,促进不同AI系统之间的协作与信息共享。
用户体验提升。通过AI系统与现有非AI系统的交互,用户可以在不同工具间无缝切换,提升体验。例如,Data Formulator工具可自动化数据转换,但不支持手动清理,结合Excel等工具可改善用户操作。
操作系统代理。使用“操作系统代理”或“自驾操作系统”可减少工具使用负担。UFO是一个基于GPT视觉的代理,能够观察和分析Windows应用的界面,执行用户的自然语言命令,实现跨应用的任务处理。
开发人工智能驱动的数据分析系统的挑战
研究挑战包括:
- 开发支持多模态、规划和个性化的新模型。
- 理解用户偏好。
- 创建数据基础设施以促进AI驱动的建议。
- 提升现有AI模型的可靠性。
- 建立系统基准和评估指标。
这些挑战在数据分析领域具有特定背景。
确保可靠性和信任
AI模型存在多种问题,如幻觉、对提示敏感、指令执行失败、不确定性缺乏承认和偏见,尤其在数据分析领域表现明显。提高LLM输出的正确性可通过确保符合规范、使用外部知识(如API文档)和工具(如计算器)来减少错误。代码生成的准确性可通过验证代码与输入输出示例的一致性来提升,采用自我修复和自我排名机制也有助于提高准确性。处理模型失败的策略包括提供备用选项和智能请求用户额外信息,确保用户体验的流畅性。确保分析的稳定性和完整性至关重要,需评估输出的稳定性,避免因模糊意图、数据缺陷等导致的错误。通过多次输出采样和PCS框架评估结果的可信度,确保分析结果在输入和假设微扰下保持一致。在假设探索中,需关注可能被忽视的重要因素,主动探测模型以生成多种分析,进行合理性推理。确保整个AI驱动分析工作流的完整性比单个步骤的可靠性更具挑战性,需要新框架和主动探测策略的结合。
系统基准测试和评估指标
需要一个全面的基准套件,涵盖数据分析领域的多种数据源和任务,包括低级和高级任务。现有基准多集中于数据分析流程的特定步骤,如可视化、数据转换、机器学习和统计推理。现有基准(如DABench)主要测试代码生成和执行,任务往往简单,限制了对AI系统全面能力的评估。不同基准套件之间的评估指标和程序各异,导致AI系统比较困难。
现有基准往往针对特定模型能力,导致狭隘,未能全面反映真实数据分析的复杂性。需要开发多样化的基准,涵盖多轮分析、数据收集、数据修复和假设探索等挑战。建议建立集中数据源和任务的分类体系,以评估AI系统的覆盖范围和改进方向。缺乏涉及人类干预和开放式探索的基准,需模拟人类科学推理过程。需要开发会话基础的任务,捕捉用户在多个会话中的活动,评估个性化和上下文跟踪能力。基准应配备强有力的评估指标,尽管用户研究和遥测数据评估成本高,但离线指标有助于快速原型开发。
数据分析领域的输出(如图表、UI)难以评估,因为其主观性强,且支持多模态沟通和人机协作使离线评估更具挑战性。初步技术利用模型(如GPT-4、GPT-Vision)模拟人类评估多模态产物,并生成交互输入。设计评估指标时需考虑AI系统的部分正确性,避免小错误导致连锁反应。评估指标应涵盖多个性能维度,反映AI在任务分解、代码生成和特定可视化API使用等方面的表现差异。
AI输出的可信度不仅取决于正确性,还需提供解释和计算过程,以增强用户信任。评估模型时,应关注平均正确率和最坏情况,如模型幻觉的频率。需进行对抗性测试,评估模型在误导性提示下的表现。
需要在模型/智能体方面取得更多进展
需要在多模态、迭代和可信赖的AI系统方面取得进展,以实现数据分析领域的应用。LLM(如GPT-4)具有高推理成本,而较小模型(如Llama和Phi-3)输出不稳定,需改进小型语言模型以平衡效率与准确性。许多最新LLM未专门针对数据分析任务训练,尤其在R和VBA等语言上缺乏数据。LLM对UI交互的训练数据不足,无法生成个性化UI以提升用户体验。难以找到将高层用户意图映射到低层数据分析任务的训练数据,用户意图往往在最终代码中不明显。
微调方法:
- 针对特定数据分析能力的微调可解决训练数据不足的问题。
- 包括微调预训练的LLM以理解表格语义、生成领域特定代码、以及多代理系统的微调。
挑战:
- 缺乏监督数据,尤其在多代理工作流和新代码领域。
- 自动化生成地面真相数据的方法,如RLAIF,通过AI反馈提升模型性能。
个性化与持续学习:
- AI系统需从用户历史交互中学习,适应用户偏好。
- 应用记忆存储、用户数据共享和个性化推荐。
自我进化能力:
- AI系统可通过使用OfficeJS API学习改进,甚至创建新API以优化用户查询。
- 目标是减少复杂代码生成,提高可靠性。
多模态推理:
- 当前AI模型在理解图表和手势等非自然图像方面存在挑战,需通过多模态结合提升数据分析能力。
规划与探索:
- 数据分析是非线性过程,AI需具备层次规划和灵活适应能力,现有LLM在自主规划上表现不佳,需加强人机协作。
了解用户的偏好和能力
构建互动AI系统的关键在于理解用户偏好和能力,以提供顺畅直观的体验。研究分为形成性研究和总结性研究。用户偏好可指导系统设计,并可集成到AI系统中,根据用户行为和任务动态推断偏好。Data Formulator2研究表明,GUI + NL方法在传达意图上优于基于聊天的AI助手。DynaVis工具的研究发现,用户更喜欢AI生成的可操作小部件,而非直接由AI执行操作,但频繁变化的UI会增加认知负担。Gu发现用户的统计专业知识水平影响对AI建议的反应,部分用户觉得建议有帮助,另一些则觉得过于基础或难以理解。Gu的研究显示,用户需要程序导向的文档和数据文档来理解和验证AI辅助的数据分析。McNutt的研究发现,用户希望理解和控制提供给LLM模型的上下文,以确保输出的相关性和准确性。仍存在对用户偏好的理解空白,如如何根据用户历史和任务动态推断有效的交互方式和AI自主性。需要研究个性化UI元素的设计,以避免频繁变化带来的用户困扰,以及在多应用环境中的用户干预界面和信任验证问题。
数据基础设施
确保高质量数据表的可用性是AI系统分析用户建议的关键挑战。需要类似搜索引擎的基础设施来爬取、索引和排名网络数据表。需支持领域专家创建数据表API,并实现实时更新和有效管理企业及专有数据表。通过众包机制评估和排名数据表质量,以增强数据资源的可靠性和相关性。数据隐私和安全是重要考虑,需有匿名和聚合数据的机制。
总结
本文探讨生成式AI工具在数据分析中的潜力,列出AI系统可协助的任务及相关研究。讨论人机交互设计考虑,优化用户体验、工作流程及增强信任度,适用于其他领域的AI系统设计。强调研究挑战,包括提升AI模型在数据分析中的鲁棒性,开发基准和评估指标。提出模型进步需求,如持续学习、多模态推理和规划,利用多步骤、多模态交互数据分析场景作为基准。强调进行全面用户研究,以优化AI驱动的数据分析工具,帮助用户从复杂数据中提取可行见解。
我们致力于提供优质的AI服务,涵盖人工智能、数据分析、深度学习、机器学习、计算机视觉、自然语言处理、语音处理等领域。如有相关需求,请私信与我们联系。