
2024年10月18日Arxiv cs.CV发文量约130余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省59分钟浏览Arxiv的时间。


苏黎世联邦理工学院和图宾根大学的研究团队提出了DepthSplat方法,通过跨任务交互连接高斯喷洒和深度估计,以提高两个任务的性能。
http://arxiv.org/abs/2410.13862v1
https://haofeixu.github.io/depthsplat/

香港中文大學、浙江大學、上海人工智能實驗室的研究團隊提出了VLM-Grounder框架,利用視覺語言模型(VLMs)進行基於2D圖像的零樣本3D視覺定位。該框架動態拼接圖像序列,採用定位和反饋方案來找到目標物體,並使用多視角集成投影來準確估計3D邊界框。
http://arxiv.org/abs/2410.13860v1
https://github.com/OpenRobotLab/VLM-Grounder
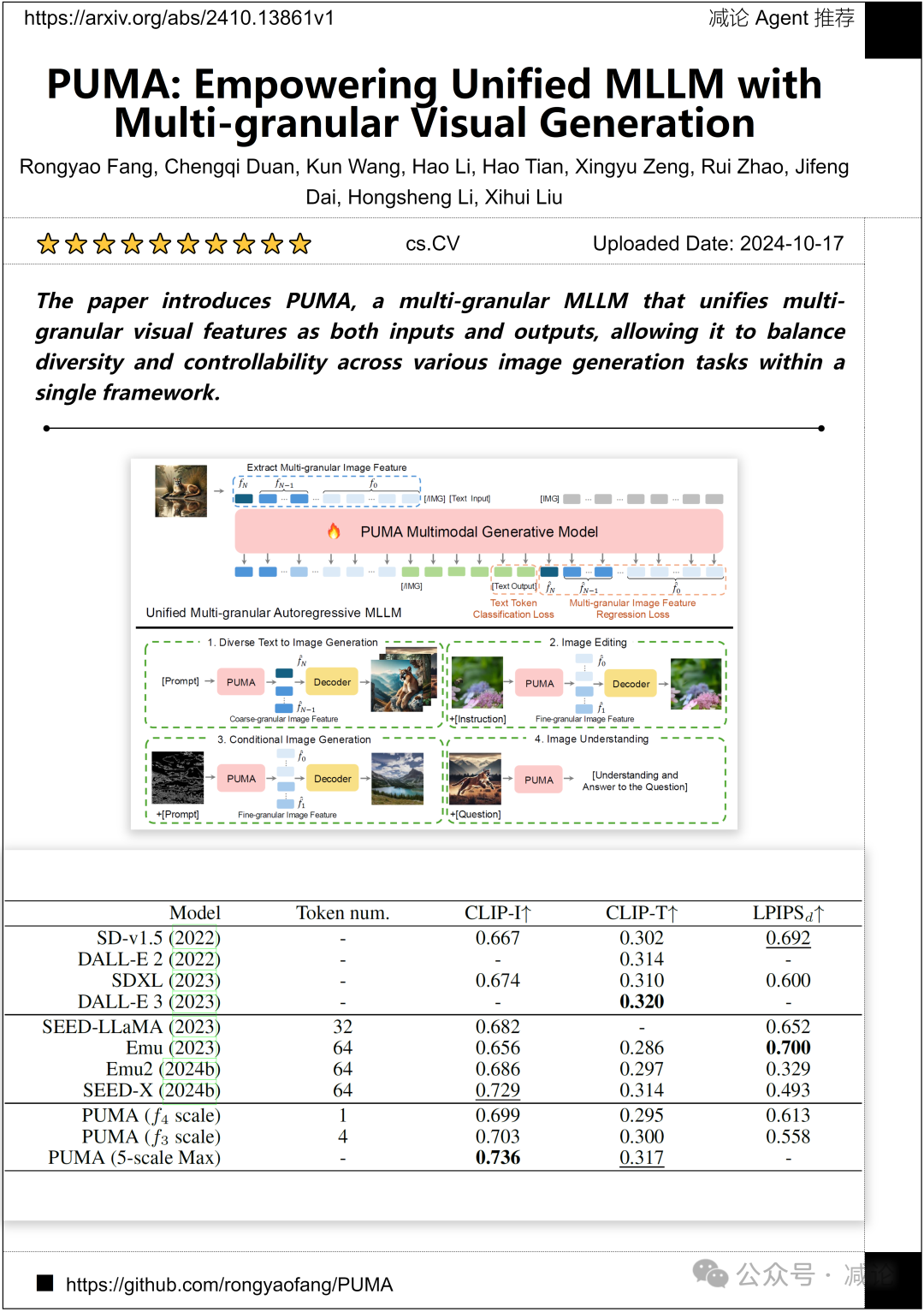
香港中文大學、香港大學以及上海人工智能實驗室的研究人員提出了一种新的方法。他们介绍了PUMA,一种多粒度MLLM,它能够将多粒度视觉特征统一为输入和输出,从而在单一框架内平衡各种图像生成任务中的多样性和可控性。
http://arxiv.org/abs/2410.13861v1
https://github.com/rongyaofang/PUMA

香港理工大学、瑞士洛桑联邦理工学院和中国科学技术大学的研究团队提出了一种名为Fundus2Video的方法。该方法是一个自回归生成对抗网络(GAN)模型,能够从单色眼底图像生成动态荧光血管造影(FFA)视频。研究表明,Fundus2Video在疾病诊断和血管分割等下游任务中表现出高保真度和强大性能。
http://arxiv.org/abs/2410.13242v1
https://github.com/Michi-3000/Fundus2Video
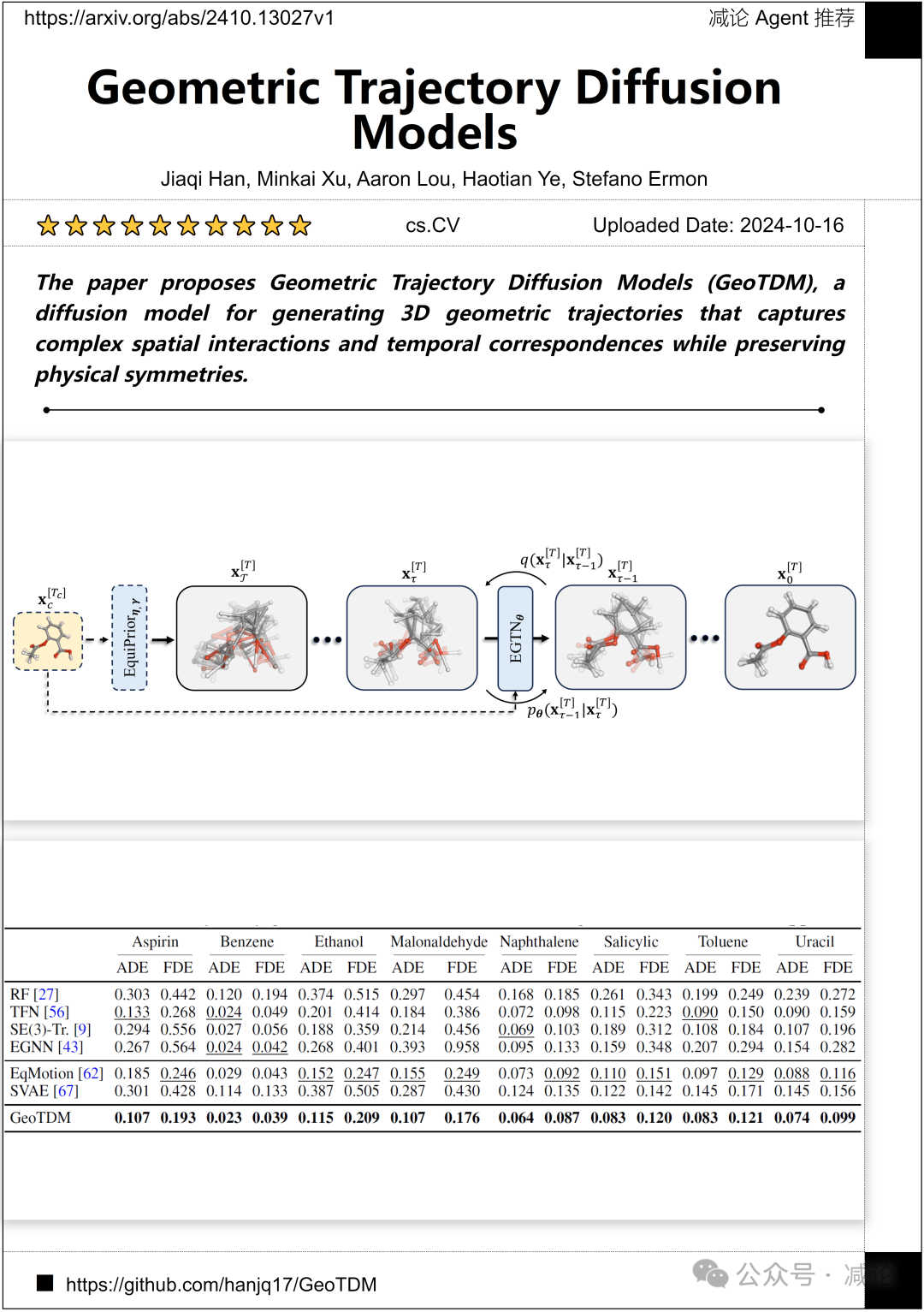
斯坦福大学的研究团队提出了几何轨迹扩散模型(GeoTDM),这是一种用于生成3D几何轨迹的扩散模型,能够捕捉复杂的空间相互作用和时间对应关系,同时保留物理对称性。
http://arxiv.org/abs/2410.13027v1
https://github.com/hanjq17/GeoTDM
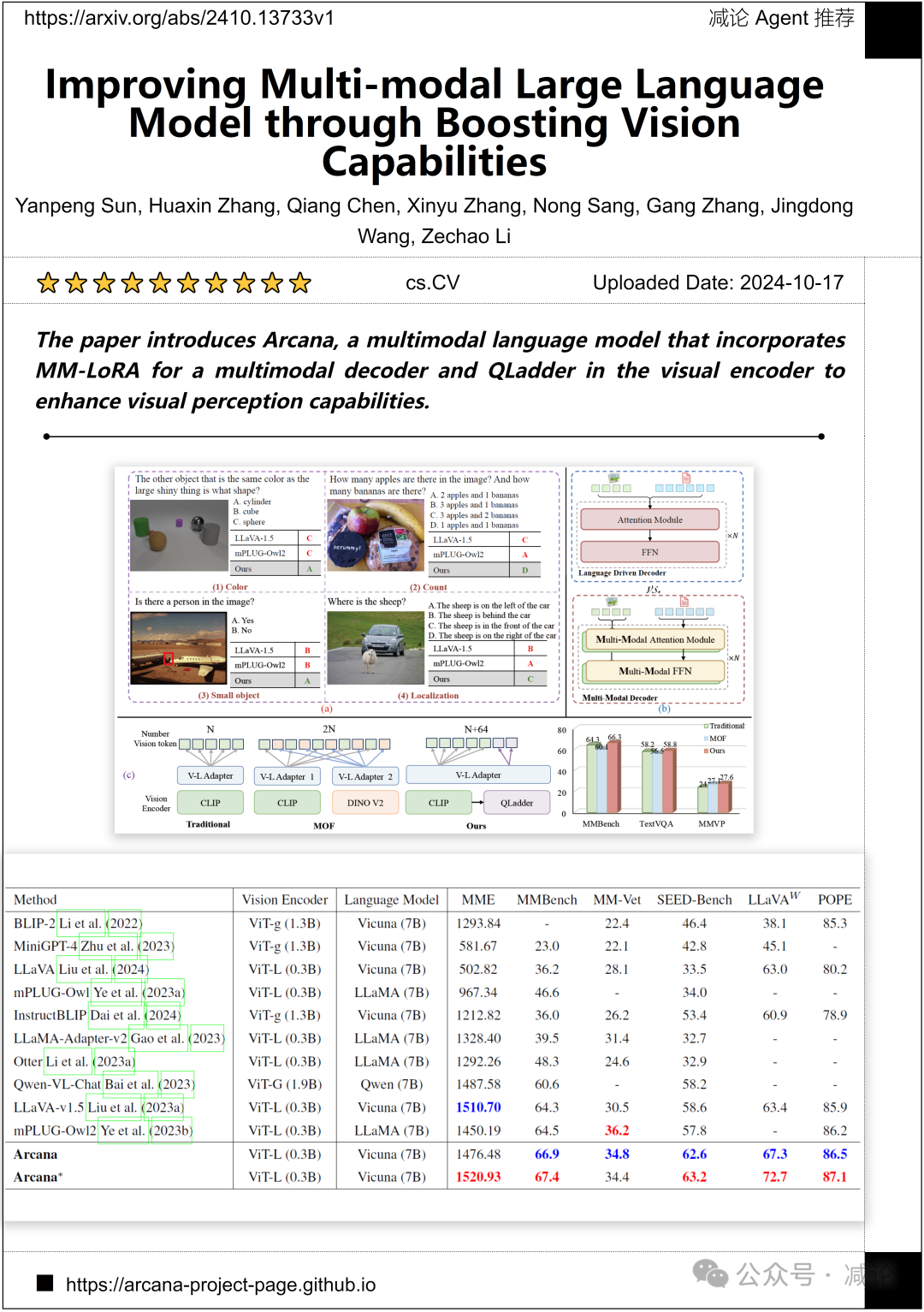
南京理工大学、百度VIS和华中科技大学的研究团队介绍了Arcana,这是一个多模态语言模型,结合了MM-LoRA用于多模态解码器和QLadder用于视觉编码器,以增强视觉感知能力。
http://arxiv.org/abs/2410.13733v1
https://arcana-project-page.github.io

中国科学技术大学的研究团队提出了D-FINE,一个实时目标检测框架,通过重新定义边界框回归任务,通过精细分布细化(FDR)和全局最优定位自蒸馏(GO-LSD)来增强DETR模型,实现了更好的定位精度和计算效率。
http://arxiv.org/abs/2410.13842v1
https://github.com/Peterande/D-FINE

香港大学的研究团队推出了一个统一的多模态框架,名为Janus。该框架在同一个transformer架构中解耦了多模态理解和生成任务的视觉编码,解决了这些任务对视觉编码器的冲突需求,增强了框架的灵活性和性能。
http://arxiv.org/abs/2410.13848v1
https://github.com/deepseek-ai/Janus

浙江大学和阿里巴巴集团的研究团队介绍了MuVi,一个用于视频到音乐生成的框架。该框架利用视觉适配器从视频内容中提取相关特征,并使用基于流匹配的音乐生成器生成与视频在语义和节奏上对齐的音乐。此外,MuVi还利用对比音乐–视觉预训练方案来增强同步性。
http://arxiv.org/abs/2410.12957v1
muvi-v2m.github.io

宁波东方理工大学、上海交通大学、中国科学技术大学的作者团队提出了MotionBank。这是一个大规模视频动作基准数据集,包含124万个动作序列和1.329亿帧。该数据集带有从运动特征自动生成的解耦基于规则的描述进行标注,旨在促进大规模动作模型的开发和基准测试,用于各种与动作相关的任务。
http://arxiv.org/abs/2410.13790v1
https://github.com/liangxuy/MotionBank
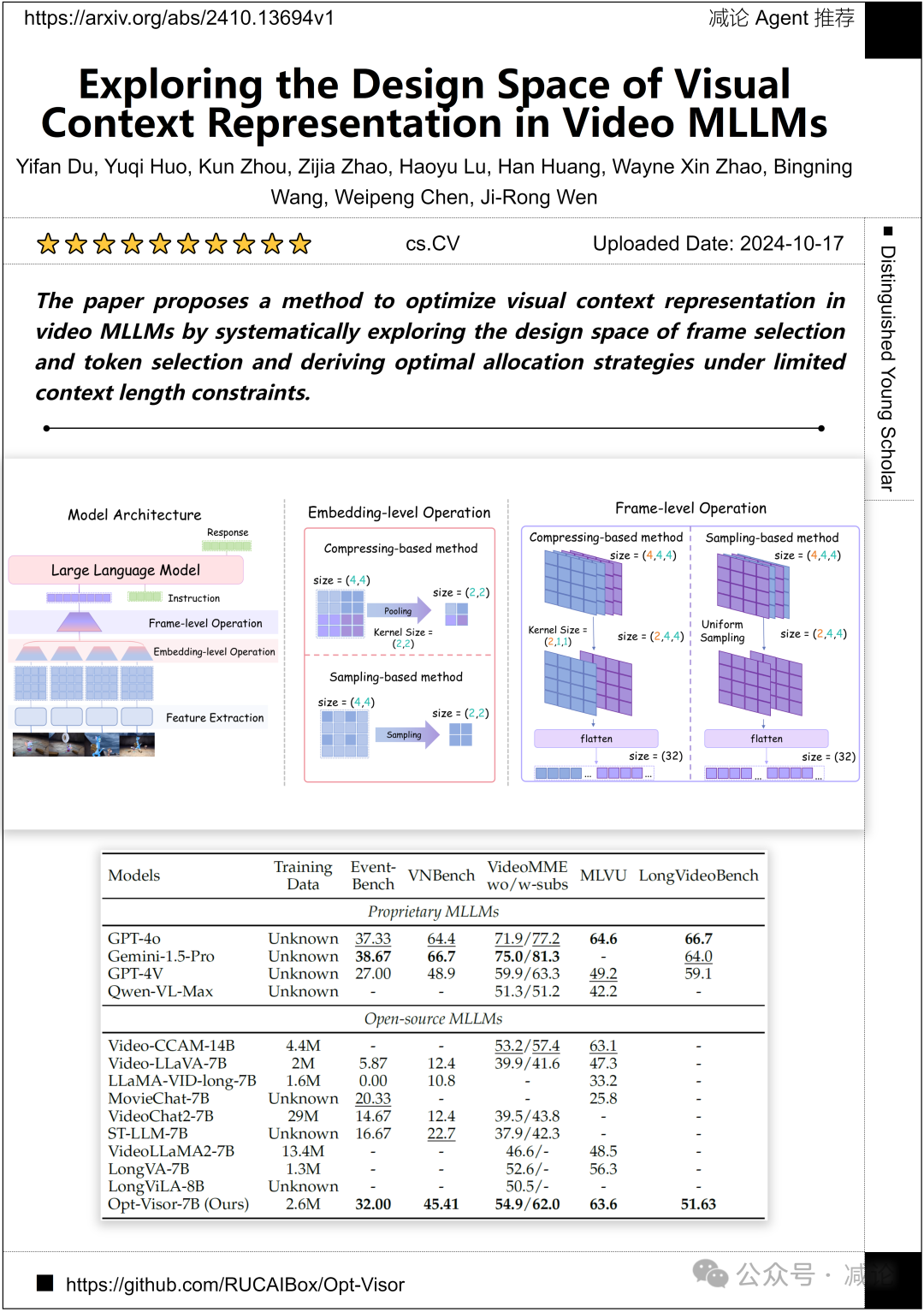
中国人民大学和百川公司的作者团队推出了一种方法,通过系统地探索帧选择和标记选择的设计空间,并在有限上下文长度约束下推导出最佳分配策略,以优化视频MLLMs中的视觉上下文表示。
http://arxiv.org/abs/2410.13694v1
https://github.com/RUCAIBox/Opt-Visor
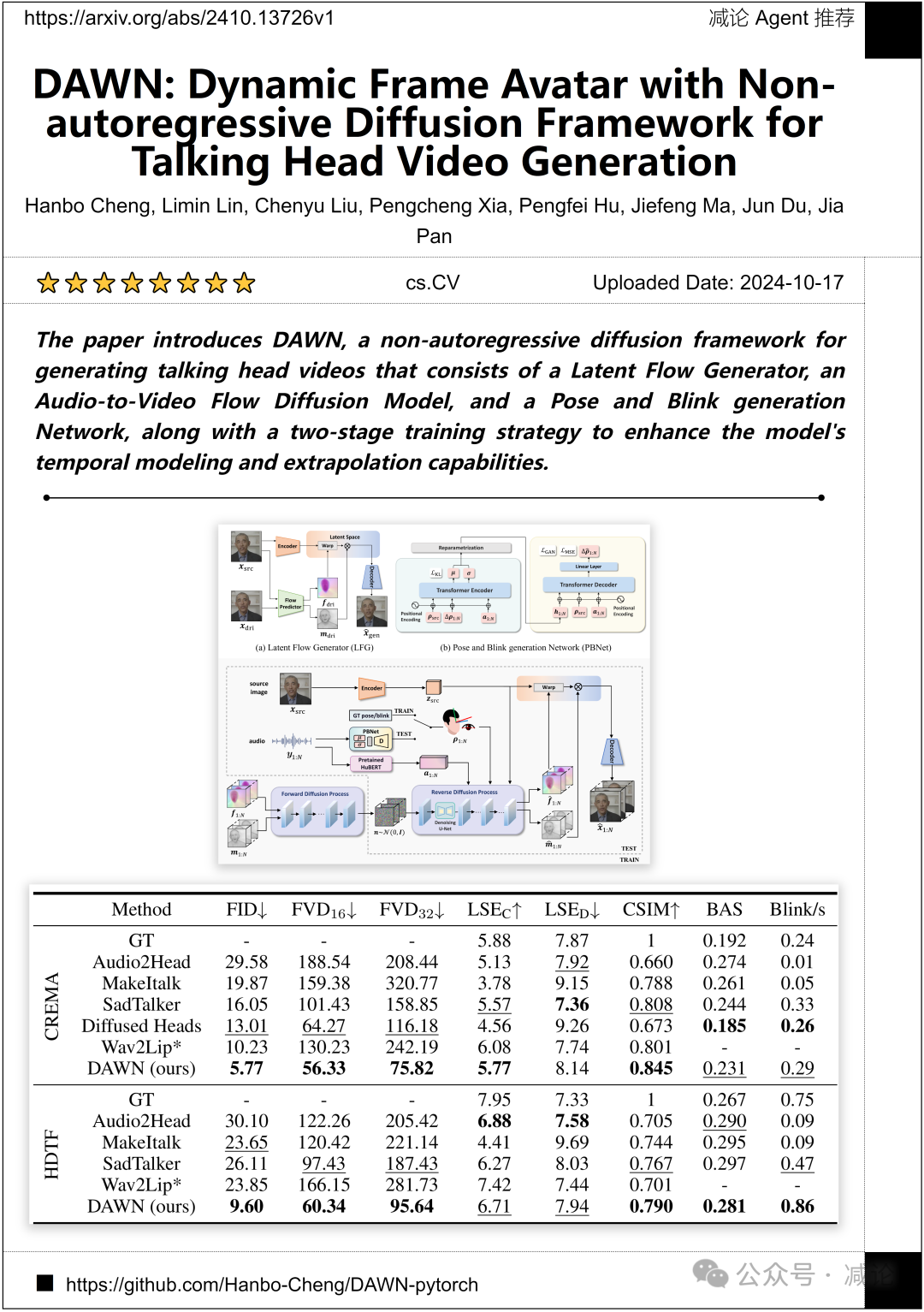
中国科学技术大学和讯飞研究院的团队提出了DAWN,一个用于生成说话头像视频的非自回归扩散框架。该框架包括潜在流生成器、音频到视频流扩散模型、姿势和眨眼生成网络,以及一个两阶段训练策略,以增强模型的时间建模和外推能力。
http://arxiv.org/abs/2410.13726v1
https://github.com/Hanbo-Cheng/DAWN-pytorch