
2024年10月17日Arxiv cs.CV发文量约96余篇,小编通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省40分钟浏览Arxiv的时间。


浙江大学提出了一项名为多语境视觉基础的新视觉基础任务,并推出了一个名为MC-Bench的数据集,用于评估MLLM在这一任务中的能力。
http://arxiv.org/abs/2410.12332v1
https://xuyunqiu.github.io/MC-Bench/

英伟达团队推出了一篇新论文,介绍了一个名为OCTAV的新型数据集和一个名为OMCAT的模型,以解决多模态大型语言模型在细粒度、跨模态时间理解方面的局限性。OCTAV侧重于跨音频和视频的事件转换,而OMCAT利用旋转时间嵌入(RoTE)来增强时间基准和时间锚定任务中的计算效率。
http://arxiv.org/abs/2410.12109v1
https://om-cat.github.io

上海人工智能实验室团队介绍了DocLayout-YOLO,这是一个通过利用大规模和多样化的文档布局数据集DocSynth-300K以及全局到局部可控感知模块(GL-CRM)来增强文档布局分析的系统。
http://arxiv.org/abs/2410.12628v1
https://github.com/opendatalab/DocLayout-YOLO
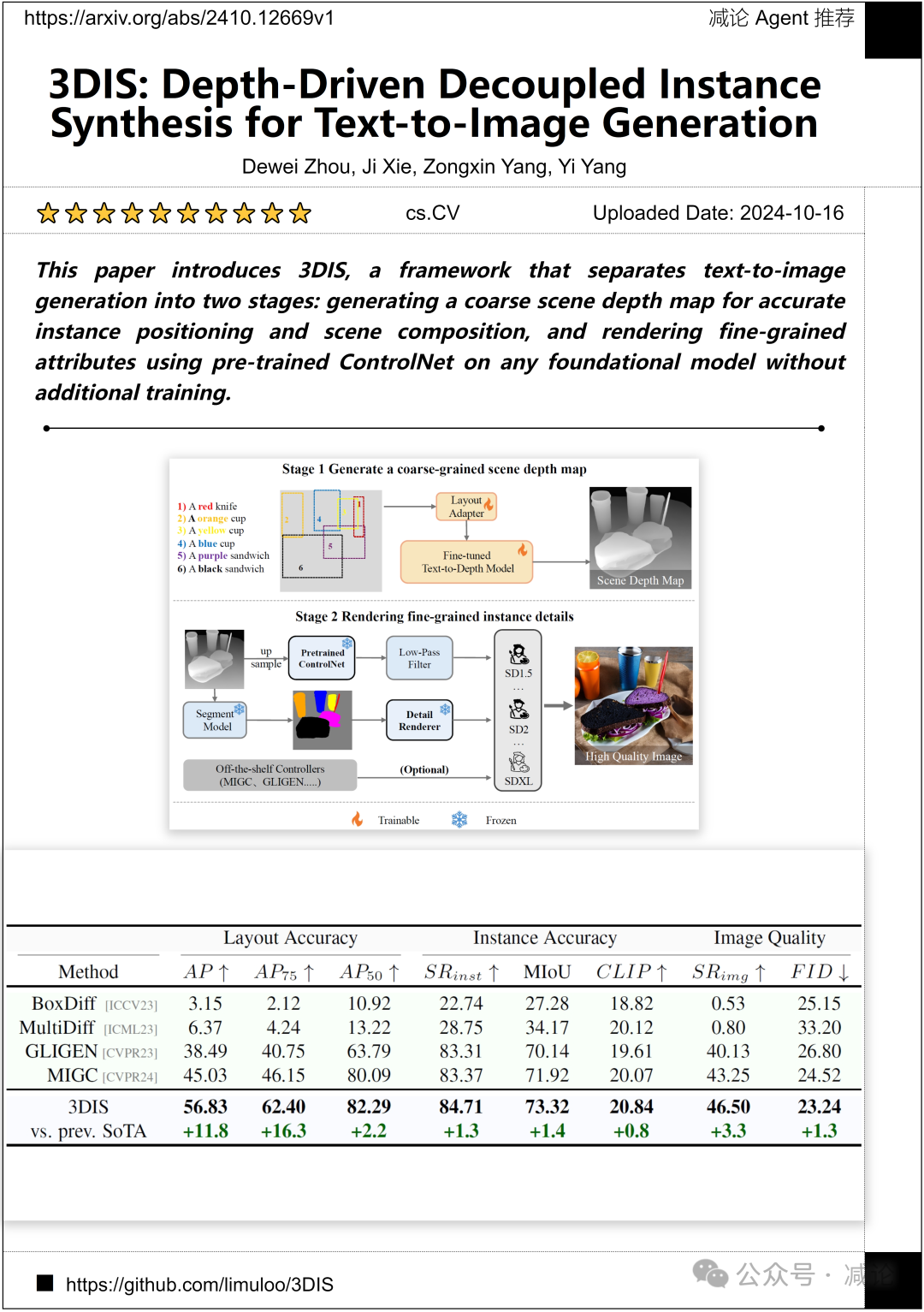
浙江大学的研究团队介绍了3DIS方法,该方法将文本到图像生成分为两个阶段:生成粗糙的场景深度图以实现准确的实例定位和场景组合,然后利用预训练的ControlNet在任何基础模型上渲染细粒度属性,无需额外训练。
http://arxiv.org/abs/2410.12669v1
https://github.com/limuloo/3DIS

达摩院、阿里巴巴集团和南洋理工大学的研究团队提出了一个名为多模态之咒(CMM)的基准,用于评估大型多模态模型(LMMs)在整合语言、视觉和音频输入时的幻觉问题。他们通过对象级和事件级探测,将幻觉评估转化为二元分类任务,从而实现对LMM脆弱性的全面诊断,并确定幻觉的两个关键贡献者:对单模态先验的过度依赖和虚假的跨模态相关性。
http://arxiv.org/abs/2410.12787v1
Project Page: cmm-damovl.site, Github Repo: github.com/DAMO-NLP-SG/CMM

香港城市大學、武漢大學和韻智AI提出了HumanEval-V,这是一个用于评估大型多模态模型(LMMs)视觉理解和推理能力的基准。该论文通过代码生成任务,要求模型利用视觉上下文来解决Python编码问题。
http://arxiv.org/abs/2410.12381v1
https://github.com/HumanEval-V/HumanEval-V-Benchmark
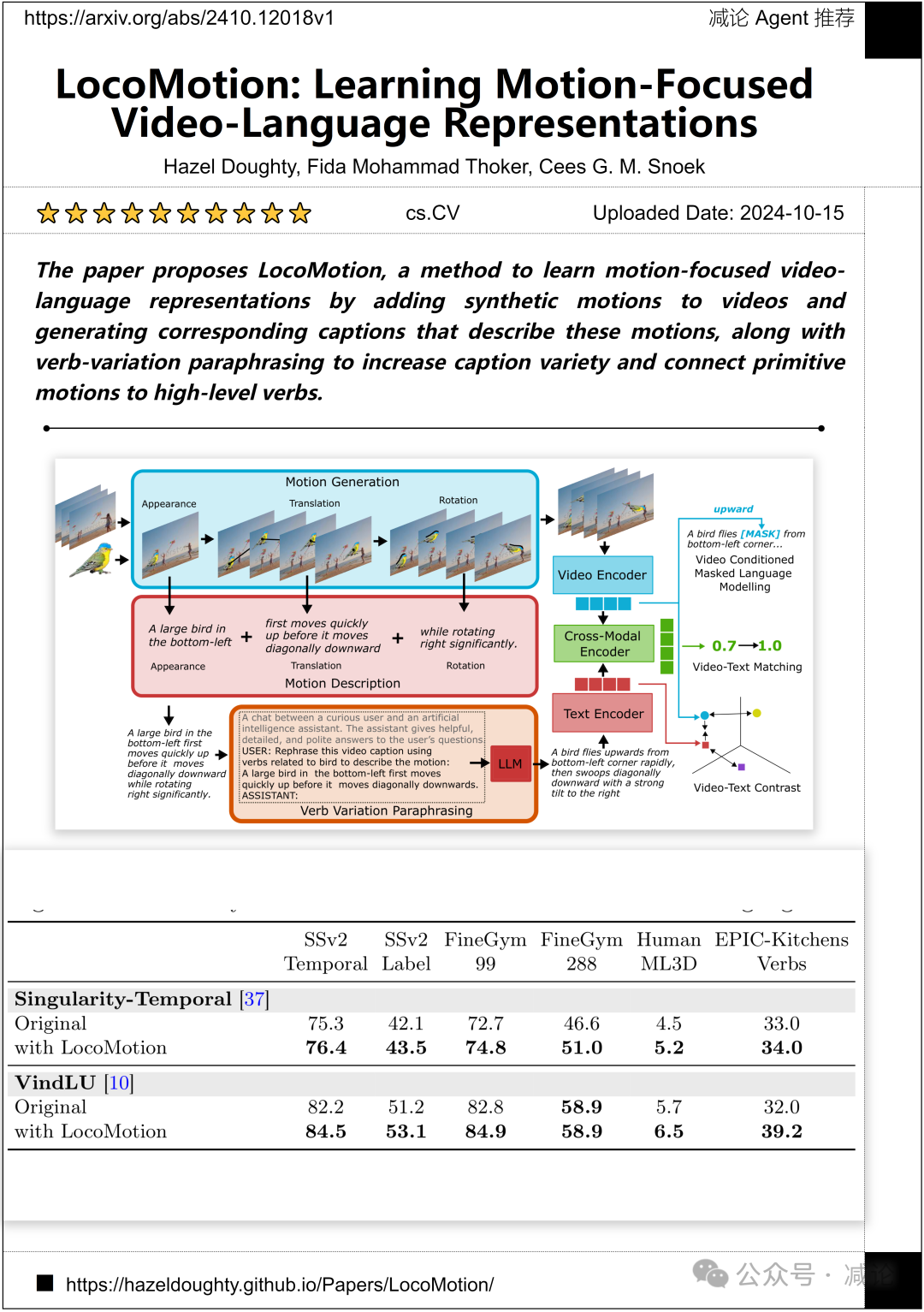
莱顿大学和阿姆斯特丹大学的研究团队提出了LocoMotion方法。该方法通过向视频添加合成动作并生成描述这些动作的相应字幕,以及动词变体释义来增加字幕多样性并将基本动作与高级动词联系起来,从而提供了一种以动作为重点的视频语言表示方法。
http://arxiv.org/abs/2410.12018v1
https://hazeldoughty.github.io/Papers/LocoMotion/

中国科学技术大学和浙江大学的研究团队提出了一种方法,通过引入一个具有区分性的图像分词器来稳定图像自回归建模的潜在空间,该分词器将来自自监督学习模型的特征表示离散化,从而提高了图像理解和生成任务的性能。
http://arxiv.org/abs/2410.12490v1
https://github.com/DAMO-NLP-SG/DiGIT

西北大学、联影智能和北卡罗来纳大学教堂山分校的团队提出了Order-Aware Interactive Segmentation(OIS)方法。该方法通过使用顺序图和顺序感知注意机制,以及物体感知注意力,将对象之间的相对深度信息融入交互式分割中,从而增强模型区分对象并提高分割准确性和效率的能力。
http://arxiv.org/abs/2410.12214v1
https://ukaukaaaa.github.io/OIS
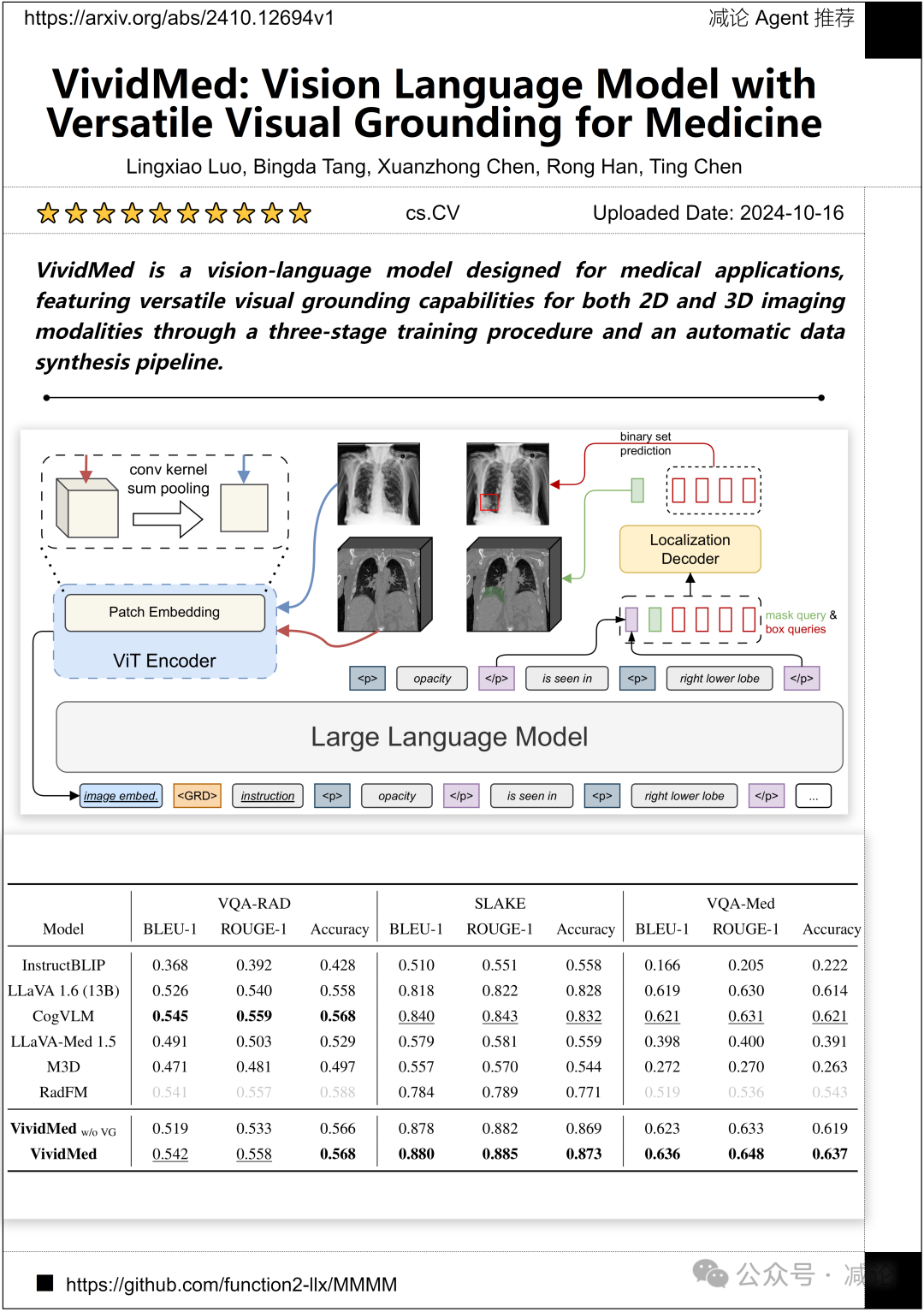
清华大学的研究团队提出了VividMed,一个为医疗应用设计的视觉语言模型。通过三阶段训练流程和自动数据合成管道,VividMed具有适用于2D和3D成像模式的多功能视觉基础能力。
http://arxiv.org/abs/2410.12694v1
https://github.com/function2-llx/MMMM
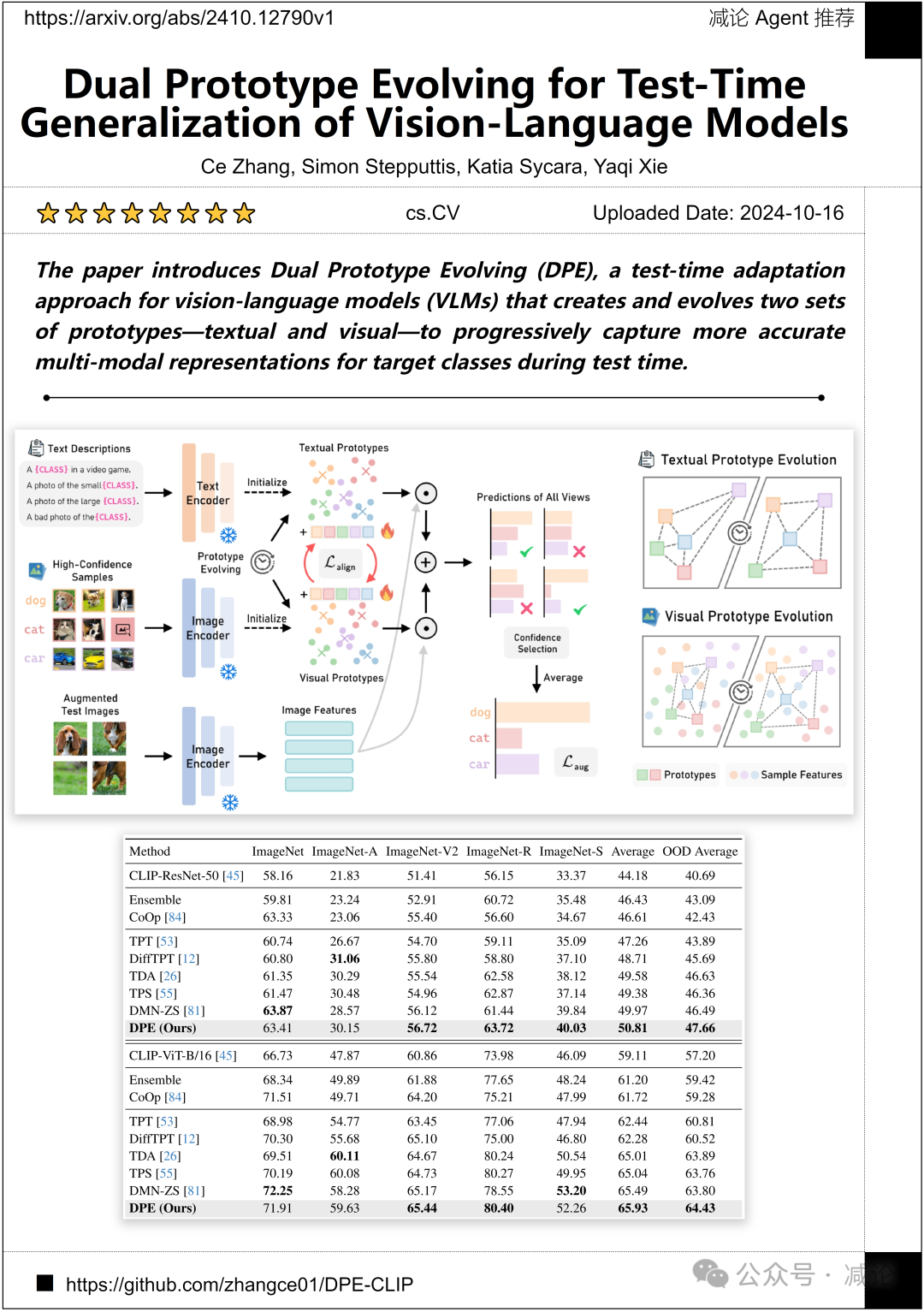
卡内基梅隆大学的研究团队介绍了双原型演化(DPE)方法,这是一种用于视觉–语言模型(VLMs)的测试时适应方法。该方法创建并演化两组原型——文本和视觉——以在测试时逐渐捕获更准确的多模态表示目标类别。
http://arxiv.org/abs/2410.12790v1
https://github.com/zhangce01/DPE-CLIP
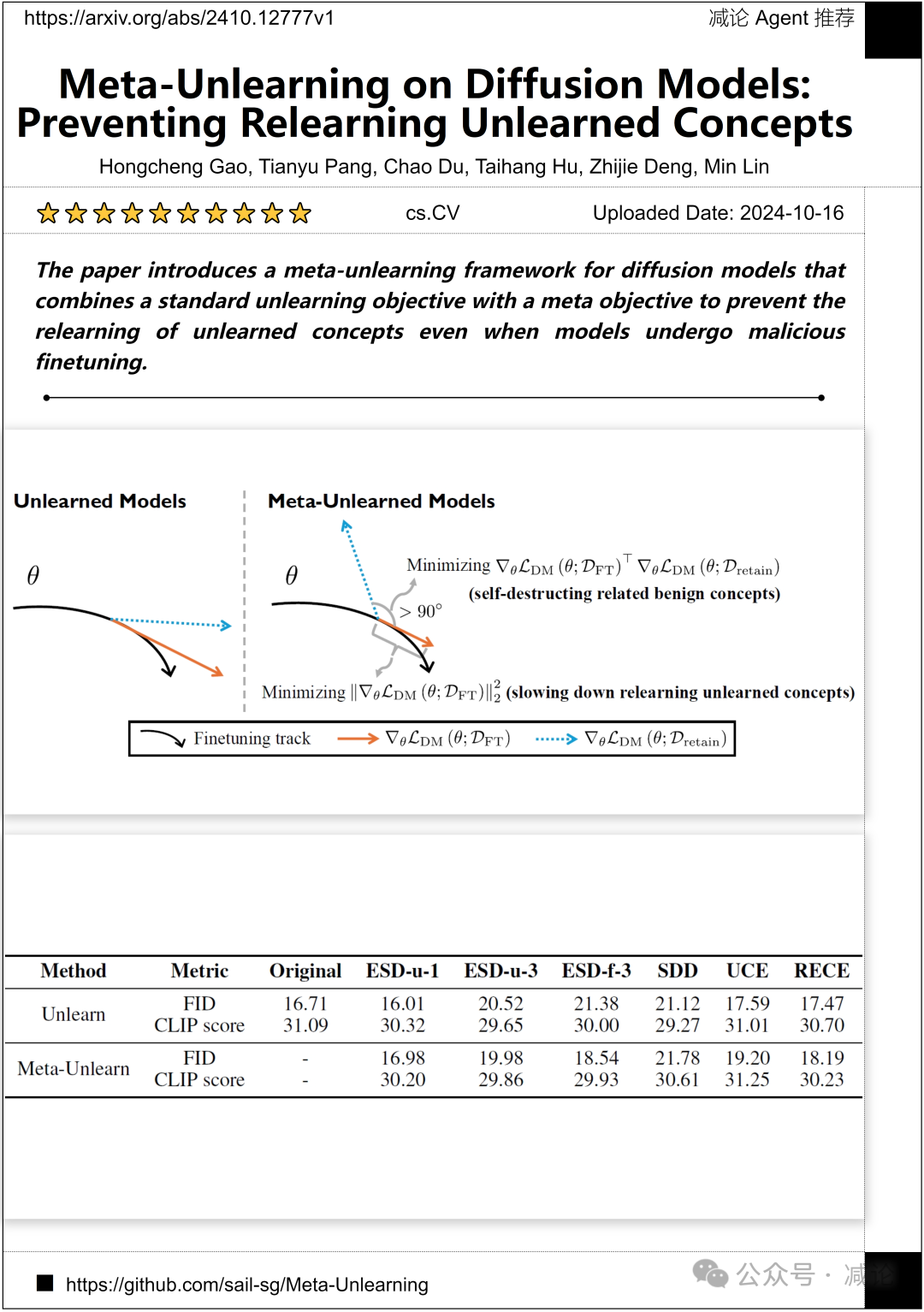
中国科学院大学海洋人工智能实验室和上海交通大学的研究团队提出了一个元遗忘框架,用于扩散模型。该框架将标准遗忘目标与元目标结合起来,以防止即使模型经历恶意微调,也不会重新学习已遗忘的概念。
http://arxiv.org/abs/2410.12777v1
https://github.com/sail-sg/Meta-Unlearning
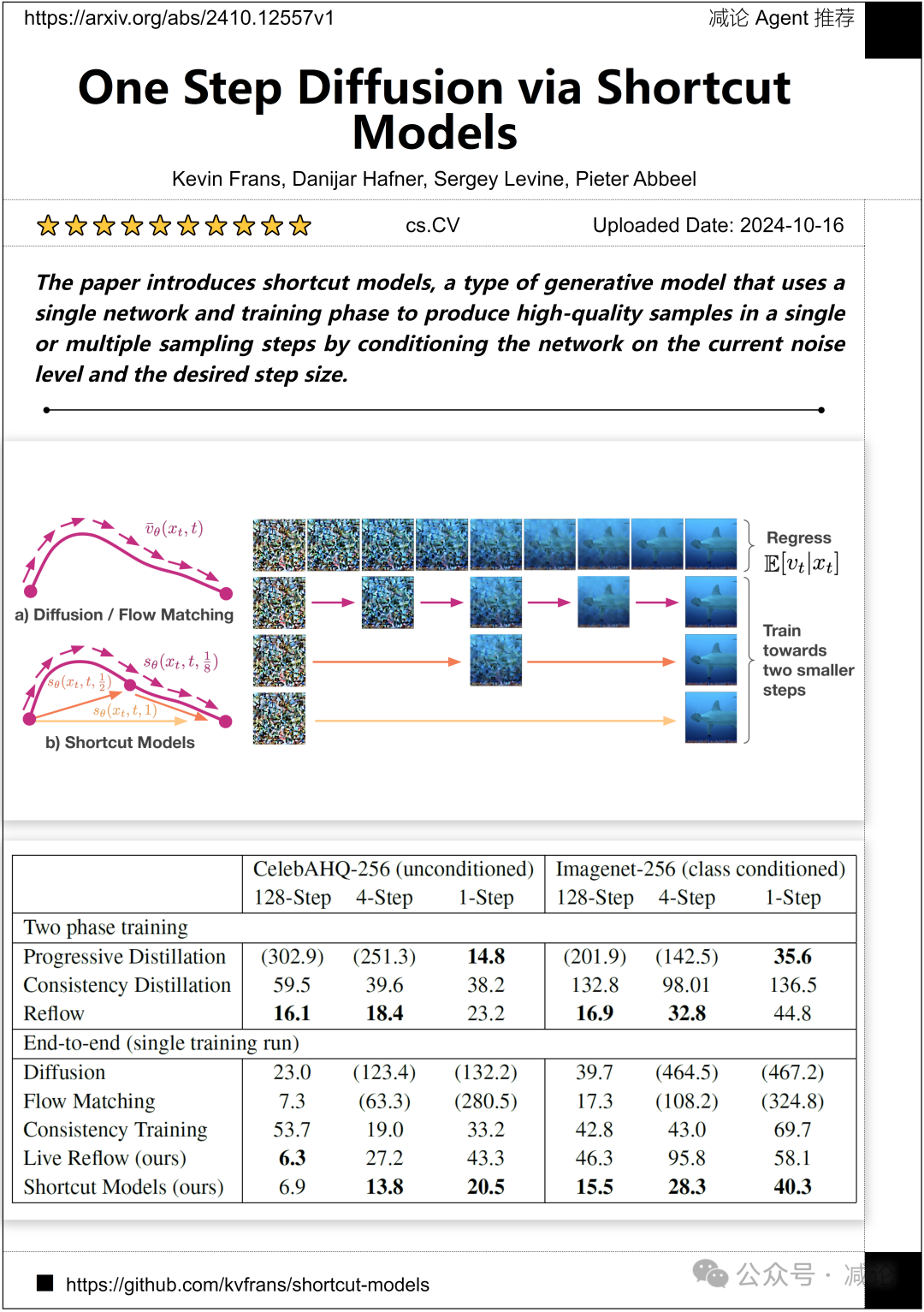
加州大学伯克利分校的研究团队介绍了快捷模型,一种生成模型,它使用单个网络和训练阶段,在当前噪声水平和所需步长的条件下,通过单个或多个采样步骤生成高质量样本。
http://arxiv.org/abs/2410.12557v1
https://github.com/kvfrans/shortcut-models
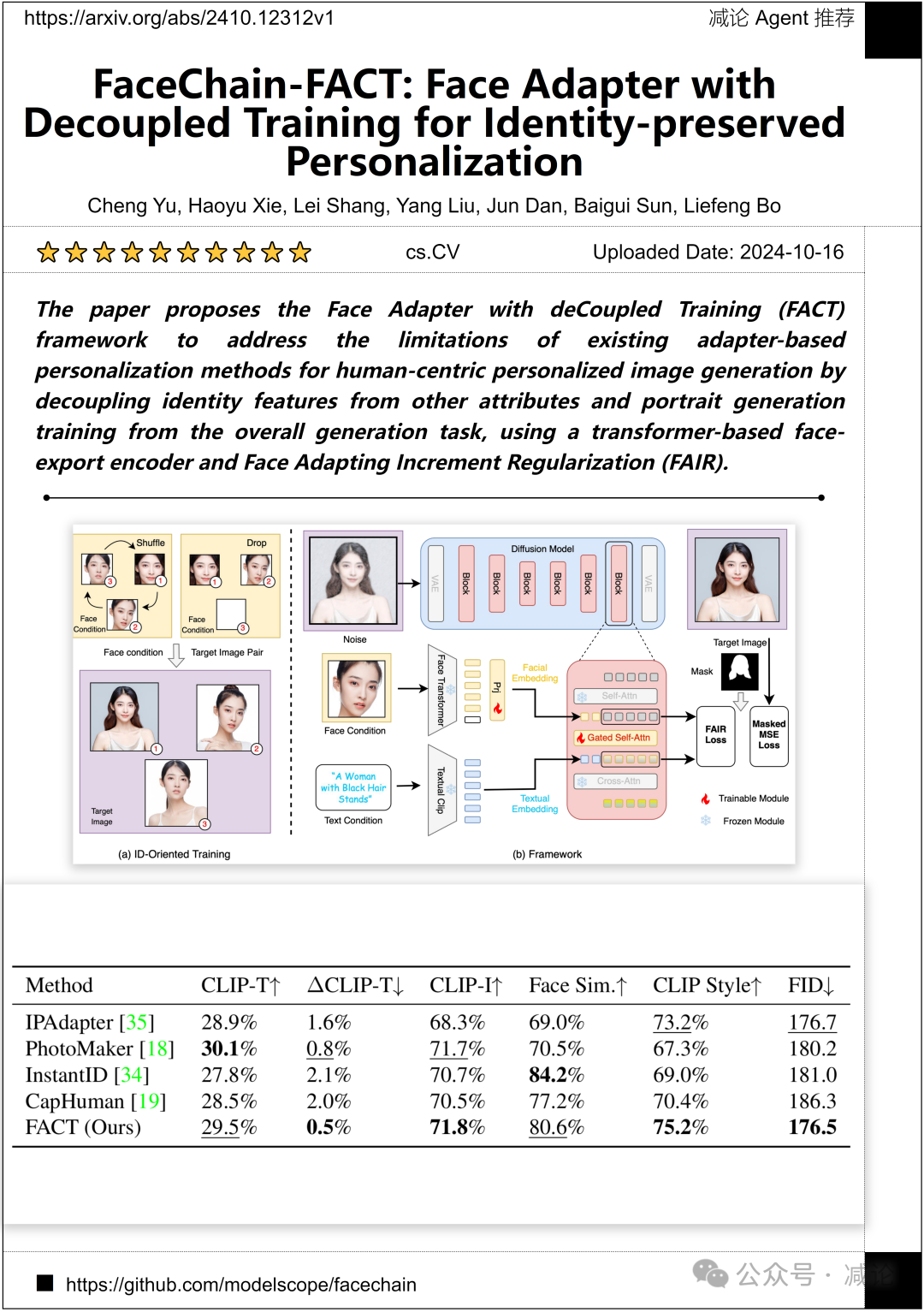
阿里巴巴集团研究团队提出了Face Adapter with deCoupled Training (FACT) 框架,该框架通过将身份特征与其他属性解耦以及将肖像生成训练与整体生成任务解耦,利用基于transformer的面部导出编码器和Face Adapting Increment Regularization (FAIR) 来解决现有基于适配器的个性化方法在以人为中心的个性化图像生成中的局限性。
http://arxiv.org/abs/2410.12312v1
https://github.com/modelscope/facechain

清华大学和微软研究提出了LiVO方法,通过优化价值编码器并使用偏好优化损失,实现对生成图像的语义和价值的控制,使文本到图像合成模型与人类价值观保持一致。
http://arxiv.org/abs/2410.12700v1
https://github.com/achernarwang/LiVO