
2024年10月16日Arxiv cs.CV发文量约126余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省55分钟浏览Arxiv的时间。


北京大学昆仑2050研究与天工智能团队介绍了Mixture-of-Head注意力(MoH)这一新颖架构,该架构将多头注意力与专家混合机制相结合,使每个标记可以选择最相关的注意力头部,提高推理效率而不增加参数数量。
http://arxiv.org/abs/2410.11842v1
https://github.com/SkyworkAI/MoH
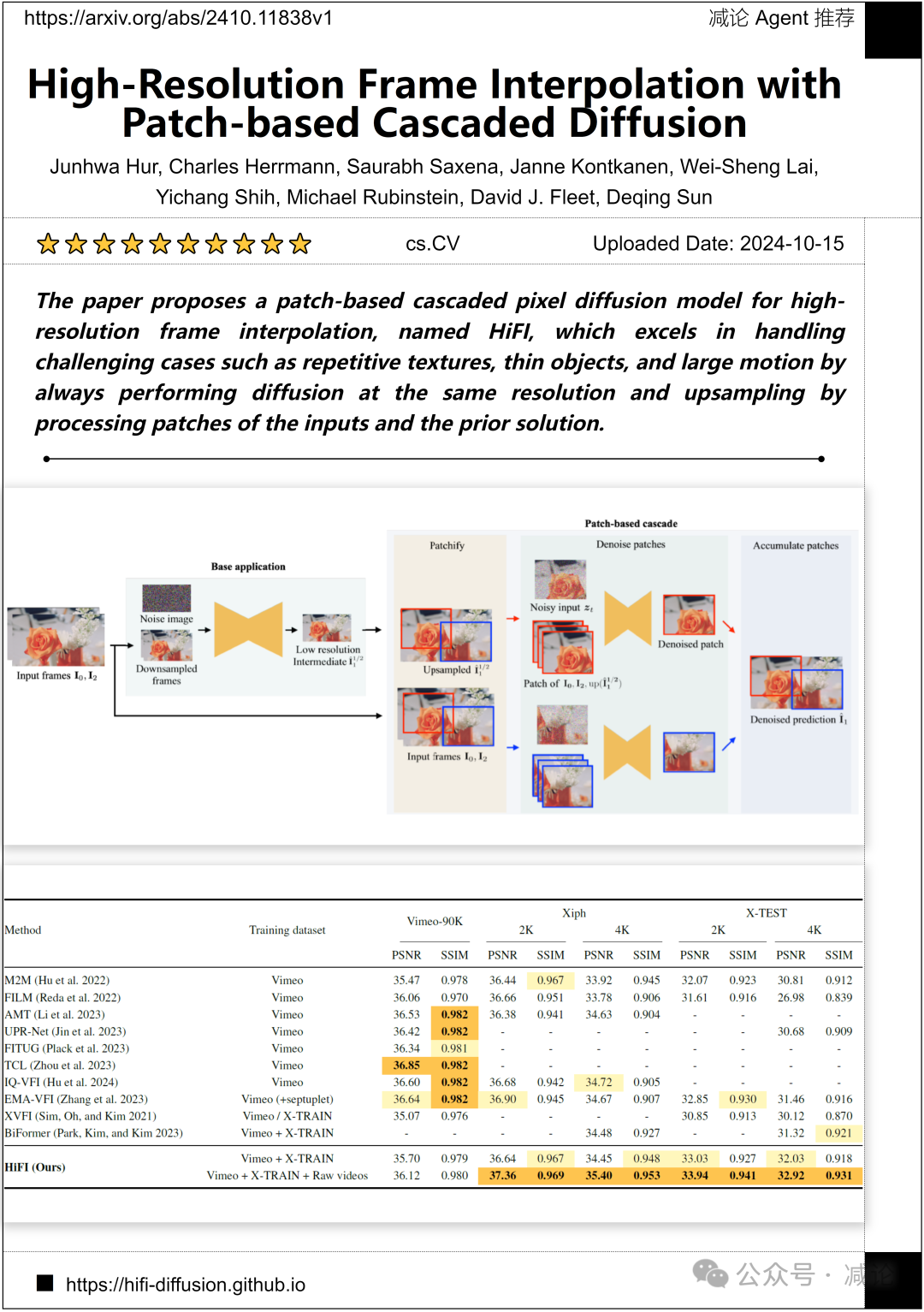
谷歌、多伦多大学、矢量研究所的研究团队提出了一种基于补丁的级联像素扩散模型,用于高分辨率帧插值,命名为HiFI。该模型在处理具有挑战性情况(如重复纹理、细小物体和大运动)方面表现出色,始终以相同分辨率执行扩散,并通过处理输入和先前解决方案的补丁来进行上采样。
http://arxiv.org/abs/2410.11838v1
https://hifi-diffusion.github.io
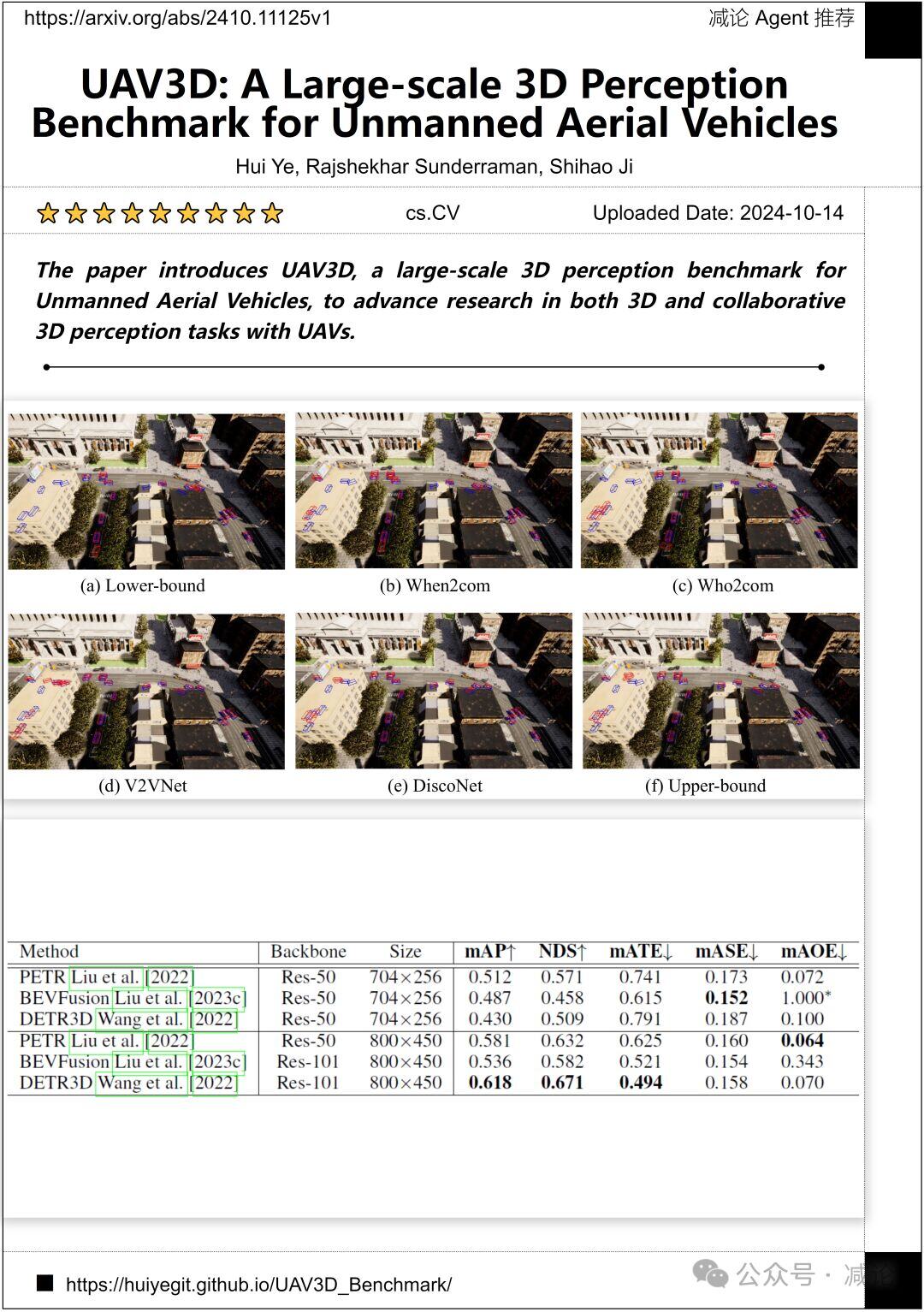
佐治亚州立大学和康涅狄格大学的研究团队介绍了UAV3D,这是一个针对无人机的大规模3D感知基准,旨在推动无人机在3D和协作3D感知任务方面的研究。
http://arxiv.org/abs/2410.11125v1
https://huiyegit.github.io/UAV3D_Benchmark/
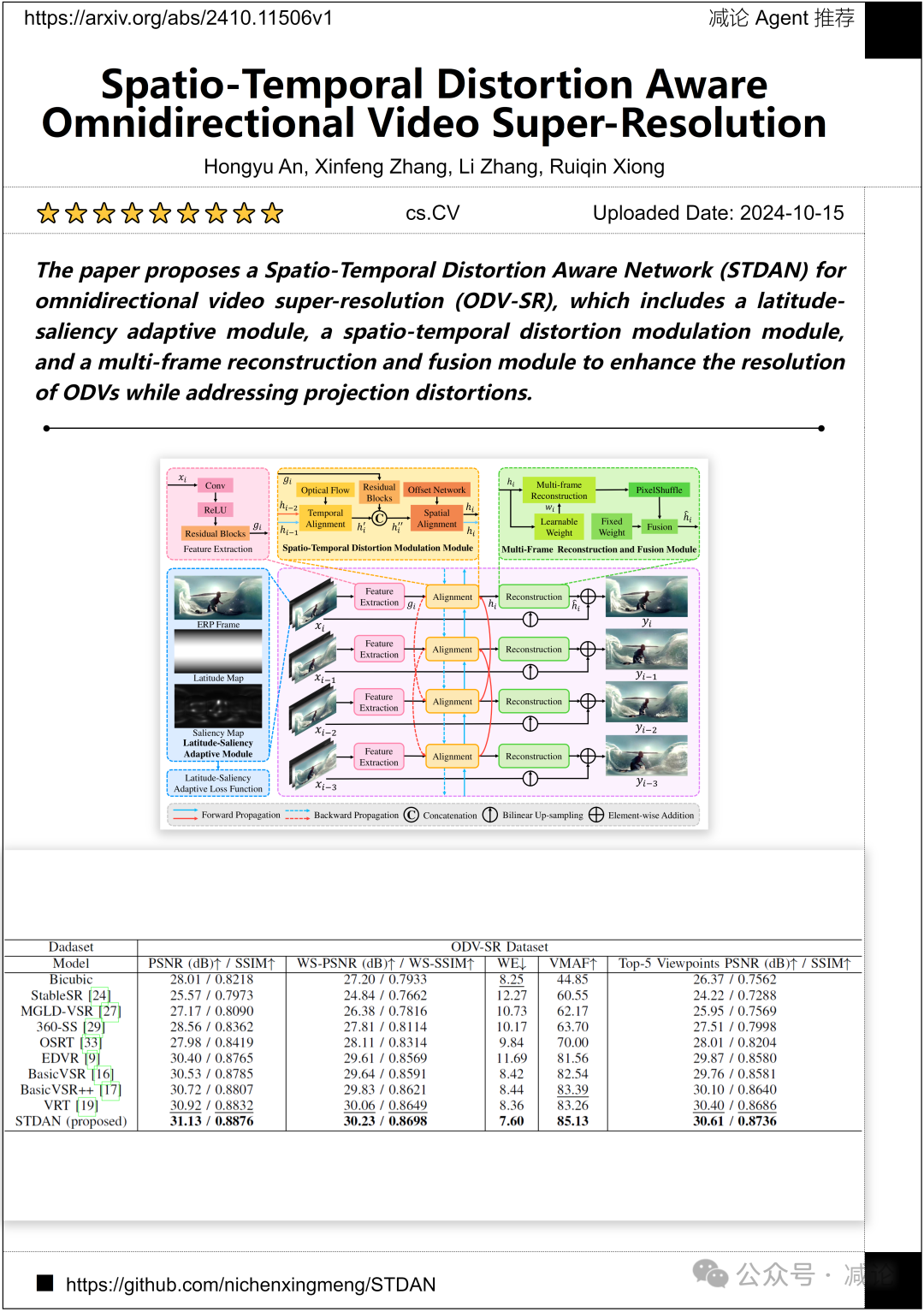
中国科学院大学的研究团队提出了一种空时畸变感知网络(STDAN)用于全向视频超分辨率(ODV-SR)的方法。该方法包括一个纬度显著性自适应模块,一个空时畸变调制模块,以及一个多帧重建和融合模块,以增强ODV的分辨率同时解决投影失真问题。
http://arxiv.org/abs/2410.11506v1
https://github.com/nichenxingmeng/STDAN

上海交通大学DeformPAM团队提出了DeformPAM方法,这是一个用于长时间跨度的可变形物体操作的数据高效学习框架。该方法利用偏好学习和奖励引导的动作选择,将任务分解为动作原语。通过3D点云和扩散模型建模动作分布,并利用人类偏好数据训练隐式奖励模型,在推理过程中选择最佳动作。
http://arxiv.org/abs/2410.11584v1
http://deform-pam.robotflow.ai

中国人民大学团队提出了即时预测调制(OPM)和即时梯度调制(OGM)策略,以解决多模态学习中不平衡和未优化的单模态表示问题。OPM通过在前馈阶段动态概率地丢弃主导模态的特征来削弱其影响,而OGM则基于监测到的模态间的判别性差异来在反向传播阶段减轻其梯度。
http://arxiv.org/abs/2410.11582v1
https://github.com/GeWu-Lab/BML_TPAMI2024

东北大学视觉计算团队介绍了一种视觉几何协作引导的可支配学习网络,利用从人–物互动中提取的交互亲和力来学习支配,并利用语义和几何线索将其转移到非互动对象,以消除歧义。
http://arxiv.org/abs/2410.11363v1
https://github.com/lhc1224/VCR-Net

安徽大学的研究团队提出了一种耦合知识蒸馏(CKD)框架,通过追求不同模态的共同风格并采用风格内容正交特征解耦方案来解决RGBT跟踪中的模态差距,以保留模态内容表示。
http://arxiv.org/abs/2410.11586v1
https://github.com/Multi-Modality-Tracking/CKD
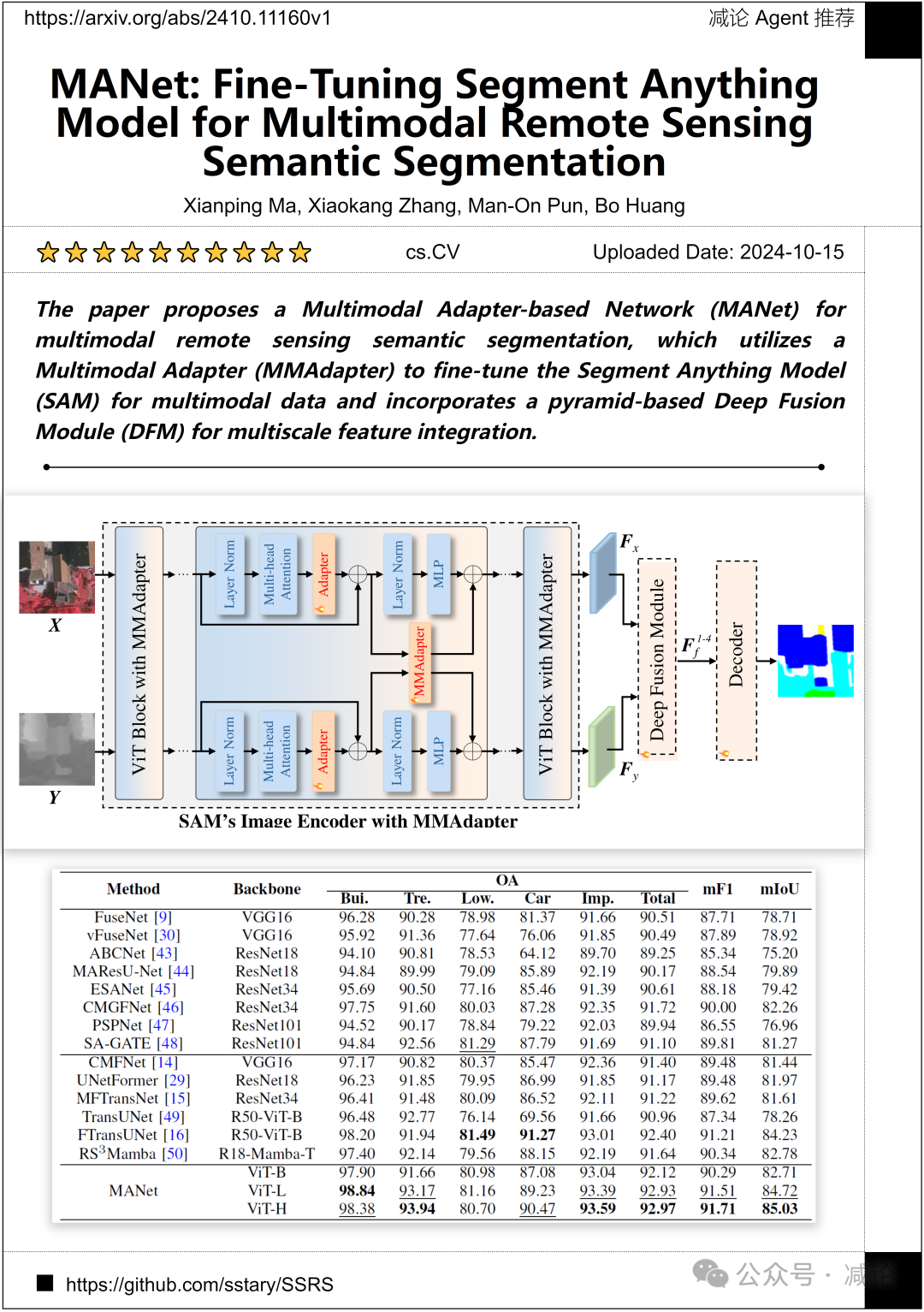
香港中文大學、武漢科技大學、香港大學的研究人員提出了一种基于多模态适配器的网络(MANet)用于多模态遥感语义分割。他们利用多模态适配器(MMAdapter)对Segment Anything Model(SAM)进行微调,以适应多模态数据,并结合基于金字塔的深度融合模块(DFM)进行多尺度特征融合。
http://arxiv.org/abs/2410.11160v1
https://github.com/sstary/SSRS

香港大学、商汤科技研究和德克萨斯农工大学的研究团队提出了一个与对齐平滑合作的时间一致性网络(TCN),以减少修复视频中的抖动和闪烁,同时保持基于图像的修复算法的质量。
http://arxiv.org/abs/2410.11828v1
https://wzhouxiff.github.io/projects/FIR2FVR/FIR2FVR

南京大学、香港中文大学、中国移动紫金创新研究院的研究团队提出了MMFuser,一个多层特征融合器,用于增强多模态大语言模型中的视觉表示。该方法整合了来自Vision Transformers的深层和浅层特征,利用语义对齐的深层特征作为查询,动态提取浅层特征中缺失的细节。
http://arxiv.org/abs/2410.11829v1
https://github.com/yuecao0119/MMFuser

香港城市大學、微軟GenAI团队提出了一种基于场景图的图像编辑框架,名为SGEdit。该框架集成了一个大型语言模型(LLM)和一个Text2Image生成模型,以实现对场景的高级、精确修改和创意重组。
http://arxiv.org/abs/2410.11815v1
https://bestzzhang.github.io/SGEdit

北京大学王选计算机技术研究所和重庆长安汽车股份有限公司的研究团队提出了一种雷达–摄像头多模态时间增强占用预测网络(TEOcc)。该网络利用具有长期和短期时间解码器的时间增强分支来学习时间占用预测,并采用共享占用预测头来改善3D占用预测任务性能。
http://arxiv.org/abs/2410.11228v1
https://github.com/VDIGPKU/TEOcc

汉堡大学, 鸿海研究院, 国立清华大学的研究团队推出了一项新的方法。他们介绍了PAVLM,这是一个结合了几何引导传播模块和大型语言模型隐藏嵌入的框架,旨在增强对点云的3D可负担性理解。该方法利用预训练的语言模型进行语义推理和指令跟随。
http://arxiv.org/abs/2410.11564v1
pavlm-source.github.io

Meta AI, 视觉几何组, 牛津大学 提出了CoTracker3,一个新的点追踪模型,它采用了更简单的架构和半监督训练协议,以比先前方法更少的训练数据实现了最先进的性能。
http://arxiv.org/abs/2410.11831v1
https://cotracker3.github.io

西江大学和图宾根大学的研究团队提出了一种方法,根据输入样本与不同领域的接近程度,自适应地在预训练解码器和微调解码器的权重之间进行插值,以使零-shot变压器模型能够在新领域上学习同时保留先前的知识。
http://arxiv.org/abs/2410.11536v1
https://github.com/dongjunhwang/dwi